Flume介绍Flume是Apache基金会组织的一个提供的高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
当前Flume有两个版本,Flume 0.9x版本之前的统称为Flume-og,Flume1.X版本被统称为Flume-ng。
参考文档:http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.5.0-cdh5.3.6/FlumeUserGuide.htmlFlume-og和Flume-ng的区别主要区别如下: 1. Flume-og中采用master结构,为了保证数据的一致性,引入zookeeper进行管理。Flume-ng中取消了集中master机制和zookeeper管理机制,变成了一个纯粹的传输工具。 2. Flume-ng中采用不同的线程进行数据的读写操作;在Flume-og中,读数据和写数据是由同一个线程操作的,如果写出比较慢的话,可能会阻塞flume的接收数据的能力。Flume结构Flume中以Agent为基本单位,一个agent可以包括source、channel、sink,三种组件都可以有多个。其中source组件主要功能是接收外部数据,并将数据传递到channel中;sink组件主要功能是发送flume接收到的数据到目的地;channel的主要作用就是数据传输和保存的一个作用。Flume主要分为三类结构:单agent结构、多agent链式结构和多路复用agent结构。
单agent结构

多agent链式结构

多路复用agent结构

Source介绍Source的主要作用是接收客户端发送的数据,并将数据发送到channel中,source和channel之间的关系是多对多关系,不过一般情况下使用一个source对应多个channel。通过名称区分不同的source。Flume常用source有:Avro Source、Thrift Source、Exec Source、Kafka Source、Netcat Source等。设置格式如下:
Channel介绍Channel的主要作用是提供一个数据传输通道,提供数据传输和数据存储(可选)等功能。source将数据放到channel中,sink从channel中拿数据。通过不同的名称来区分channel。Flume常用channel有:Memory Channel、JDBC Channel、Kafka Channel、File Channel等。设置格式如下:
Sink介绍Sink的主要作用是定义数据写出方式,一般情况下sink从channel中获取数据,然后将数据写出到file、hdfs或者网络上。channel和sink之间的关系是一对多的关系。通过不同的名称来区分sink。Flume常用sink有:
Hdfs Sink、Hive Sink、File Sink、HBase Sink、Avro Sink、Thrift Sink、Logger Sink等。
设置格式如下:
.... 其他对应sink类型需要的参数
Flume中常用的source、channel、sink组件
1.2.2.1 source组件
| Source类型 |
说明 |
| Avro Source |
支持Avro协议(实际上是Avro RPC),内置支持 |
| Thrift Source |
支持Thrift协议,内置支持 |
| Exec Source |
基于Unix的command在标准输出上生产数据 |
| JMS Source |
从JMS系统(消息、主题)中读取数据,ActiveMQ已经测试过 |
| Spooling Directory Source |
监控指定目录内数据变更 |
| Twitter 1% firehose Source |
通过API持续下载Twitter数据,试验性质 |
| Netcat Source |
监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
| Sequence Generator Source |
序列生成器数据源,生产序列数据 |
| Syslog Sources |
读取syslog数据,产生Event,支持UDP和TCP两种协议 |
| HTTP Source |
基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
| Legacy Sources |
兼容老的Flume OG中Source(0.9.x版本) |
1.2.2.2 Channel组件
| Channel类型 |
说明 |
| Memory Channel |
Event数据存储在内存中 |
| JDBC Channel |
Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| File Channel |
Event数据存储在磁盘文件中 |
| Spillable Memory Channel |
Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
| Pseudo Transaction Channel |
测试用途 |
| Custom Channel |
自定义Channel实现 |
1.2.2.3 sink组件
| Sink类型 |
说明 |
| HDFS Sink |
数据写入HDFS |
| Logger Sink |
数据写入日志文件 |
| Avro Sink |
数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Thrift Sink |
数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC Sink |
数据在IRC上进行回放 |
| File Roll Sink |
存储数据到本地文件系统 |
| Null Sink |
丢弃到所有数据 |
| HBase Sink |
数据写入HBase数据库 |
| Morphline Solr Sink |
数据发送到Solr搜索服务器(集群) |
| ElasticSearch Sink |
数据发送到Elastic Search搜索服务器(集群) |
| Kite Dataset Sink |
写数据到Kite Dataset,试验性质的 |
| Custom Sink |
自定义Sink实现 |
Flume支持众多的source、channel、sink类型,详细手册可参考官方文档
Flume安装安装步骤如下:
1. 下载flume:wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.5.0-cdh5.3.6.tar.gz
2. 解压flume。
3. 修改conf/flume-env.sh文件,如果没有就新建一个。
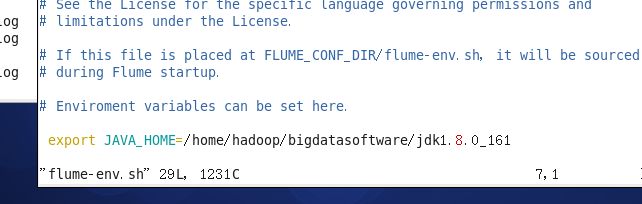
4. 添加flume的bin目录到环境变量中去。
5. 验证是否安装成功, flume-ng version

监听Hive日志信息并写入到hdfs
1. 编写nginx配置信息 在hive根目录下创建log文件夹, 2. 编写flume的agent配置信息
配置如下
# Name the components on this agenta2.sources = r2a2.sinks = k2a2.channels = c2
# Describe/configure the sourcea2.sources.r2.type = execa2.sources.r2.command = tail -F /home/hadoop/bigdatasoftware/apache-hive-0.13.1-bin/log/hive.log #要监控的log文件a2.sources.r2.shell = /bin/bash -c
# Describe the sinka2.sinks.k2.type = hdfsa2.sinks.k2.hdfs.path = hdfs://hadoop-001:9000/logs/%Y%m%d/%H0 #生成hdfs文件的目录格式#上传文件的前缀a2.sinks.k2.hdfs.filePrefix = logs-#是否按照时间滚动文件夹a2.sinks.k2.hdfs.round = true#多少时间单位创建一个新的文件夹a2.sinks.k2.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour#是否使用本地时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true#积攒多少个Event才flush到HDFS一次a2.sinks.k2.hdfs.batchSize = 1000#设置文件类型,可支持压缩a2.sinks.k2.hdfs.fileType = DataStream#多久生成一个新的文件 a2.sinks.k2.hdfs.rollInterval = 600#设置每个文件的滚动大小 a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关a2.sinks.k2.hdfs.rollCount = 0#最小冗余数 a2.sinks.k2.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memorya2.channels.c2.type = memory
a2.channels.c2.type = memorya2.channels.c2.capacity = 1000a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channela2.sources.r2.channels = c2a2.sinks.k2.channel = c2
3. 移动hdfs依赖包到flume的lib文件夹中。
cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/common/lib/commons-configuration-1.6.jar ./ cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/common/lib/hadoop-auth-2.7.2.jar ./ cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar ./ cp ~/bigdatasoftware/hadoop-2.7.2/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar ./
4. 进入flume根目录,启动
flume: ./bin/flume-ng agent --conf ./conf/ --name a2 --conf-file ./conf/flume-file-hdfs.conf
5.在hive上进行一系列操作
在hdfs上查看即可发现已生成文件
