2023.9.6 类加载器和双亲委派模型、ClickHouse和PostgreSQL
早上又是满课,而且来晚了,最后一排还没有桌子,够艰苦的,ipad放腿上写力扣。
老规矩还是写了两题
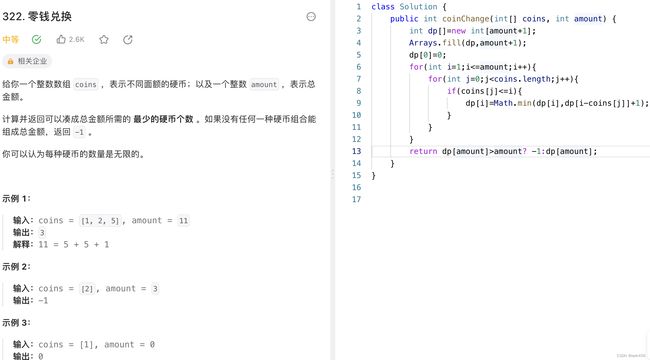
第一题,光从题目看其实很难一眼看出来该用什么。但是它有两个个明显的特征:叠加和比较,所以应该用动态规划来解决。这里设dp[i]为i元所需硬币的最少数量,然后遍历i到目标值amount,逐步记录每个钱数最少硬币数量,跟前面的完全平方数非常像,里面的嵌套的循环就是由近到远来查,看中间到底能空多少个,空得越多,所需硬币数量就越少。这类问题必须要关注下是否要给初始变量赋值。
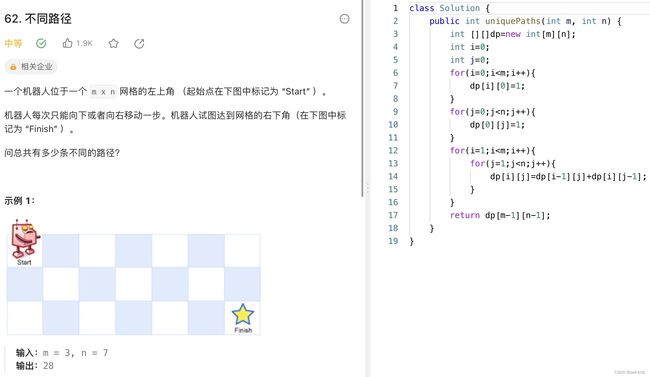
第二道,挺有意思的一道题,可以看作是二维的"爬楼梯",这里只能往下或往右走一步,所以到达任意一个格子的路线只能从左边的格子来一步或者上边的格子来一步。上面说了,动态规划一定不能忘了初始化,最上面和最左边的所有格子全部只有一种路线到达,初始化完之后遍历就可以了,其中dp[i][j]表示到达第i-1行,第j-1列的格子的路线数。
写完也到下一节课了,还是继续看《深入理解JAVA虚拟机》。
和标题一样,主要看了类加载器和双亲委派模型,内容总体来说还是挺多的,这里就挑重点讲吧
类加载器
昨天讲类加载阶段中"通过一个类的全限定名来获取描述该类的二进制字节流"这个动作,实现这个动作的代码就叫做类加载器。类加载器对于一个类是否唯一起重要的作用,判断两个类是否相等,前提就是看这两个类是否是由同一个类加载器加载的,否则即使来自同一个Class文件,它们也是不同的两个类。接着,再去比较类的equals、isAssignableFrom、isInstance方法的返回值来做判断。
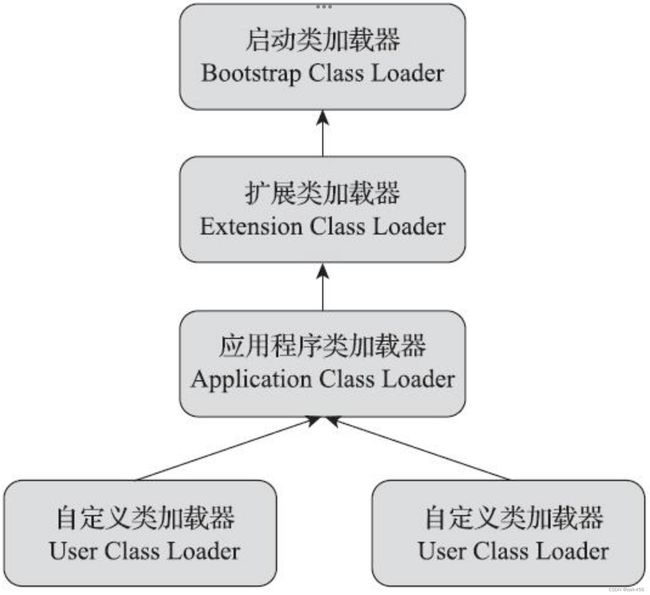
稍微有点扯远了,这里继续讲类加载器,从Java开发人员的角度来讲,类加载器分为三类:
(1)启动类加载器(Bootstrap Class Loader):前面已经介绍过,这个类加载器负责加载存放在
(2)扩展类加载器(Extension Class Loader):这个类加载器是在类sun.misc.Launcher$ExtClassLoader中以Java代码的形式实现的。它负责加载
(3)应用程序类加载器(Application Class Loader):它负责加载用户类路径(ClassPath)上所有的类库,开发者同样可以直接在代码中使用这个类加载器。
双亲委派模型
双亲委派模型使得刚刚讲过的类加载器之间形成了一个关系连,除了最顶层的启动类加载器之外,其余所有的类加载器都有自己的父类加载器。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
如果没有使用双亲委派模型,都由各个类加载器自行去加载的话,如果用户自己也编写了一个名为java.lang.Object的类,并放在程序的ClassPath中,那系统中就会出现多个不同的Object类,Java类型体系中最基础的行为也就无从保证,应用程序将会变得一片混乱。另外,双亲委派模型并不是不能被破坏的,历史上主要出现过3次较大规模的"被破坏情况",这里不细说。
Java模块化系统
JDK9引入的模块机制可以实现可配置的封装隔离机制,Java的模块除了像之前的JAR包一样简单地充当代码的容器之外还包含以下内容:依赖其他模块的列表、导出的包列表,即其他模块可以使用的列表、开放的包列表,即其他模块可反射访问模块的列表、使用的服务列表、提供服务的实现列表。
引入了模块化系统之后 ,双亲委派模型也发生了一些变化
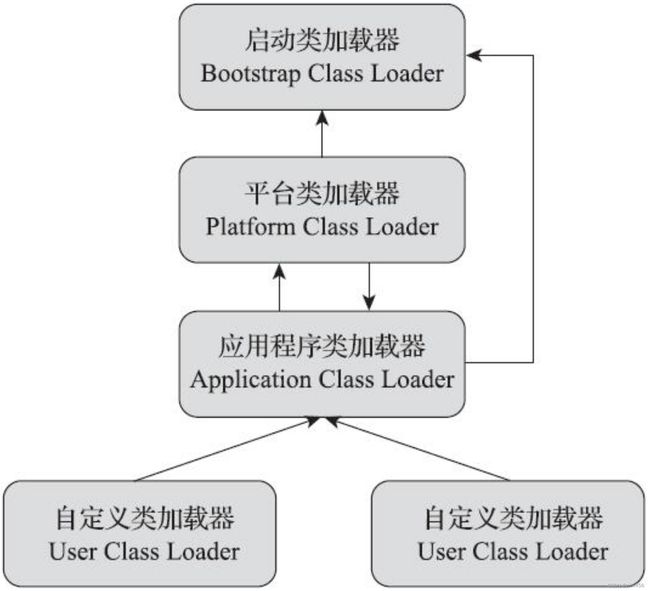
首先,扩展类加载器被平台类加载器取代。JDK根据模块化进行构建,其中的Java类库就已经满足了可拓展的需求,之前扩展类加载器的目录就没有存在的价值了;
其次,平台类加载器和应用程序类加载器不再派生自java.net.URLClassLoader,现在启动类加载器,平台类加载器、应用程序类加载器全部继承与jack.internal.loader.BuiltinClassLoader;
最后,JDK 9中虽然仍然维持着三层类加载器和双亲委派的架构,但类加载的委派关系也发生了变动。当平台及应用程序类加载器收到类加载请求,在委派给父加载器加载前,要先判断该类是否能够归属到某一个系统模块中,如果可以找到这样的归属关系,就要优先委派给负责那个模块的加载器完成加载,也许这可以算是对双亲委派的第四次破坏。
时间才到中午,想要深扒一下之前做的RPC框架,下午另开一篇文章讲吧。现在简单说说实习的时候做的项目用到的数据库:ClickHouse和PostgreSQL。
ClickHouse
ClickHouse是一个开源的列式数据库管理系统,专门用于处理大规模数据集的高性能分析查询。
什么是列式存储?如下图,数据连续存储的依据是按列进行排序的。

而下面这种就是行式存储,也是Mysql在磁盘上的存储类型。

ClickHouse支持SQL语言操作,同时也可以用Mybatis操作,但在一些细节上与Mysql有一些不同
1、聚合函数:ClickHouse提供了丰富的高级聚合函数,如各种统计函数、直方图函数、采样函数等,以支持更复杂的分析查询。MySQL也提供了一些聚合函数,但相对较少;
2、数据更新:ClickHouse主要专注于高性能的分析查询,对于数据更新操作的支持相对较弱。虽然ClickHouse可以进行实时数据插入和更新,但不支持复杂的事务处理和数据一致性保证。MySQL则是一个事务性数据库,支持复杂的数据更新操作和事务处理;
3、数据类型:ClickHouse和MySQL在数据类型上有一些差异。ClickHouse提供了更丰富的数据类型,如低精度整数、日期时间类型、IPv4和IPv6地址类型等。MySQL也提供了广泛的数据类型,但在某些特殊类型上可能有所不同;
4、索引结构:ClickHouse的索引结构是通过MergeTree实现的LSM树(日志结构合并树),而Mysql采用的是B+树。这里详细说一下MergeTree:
MergeTree的核心思想是将数据分为多个层级的数据文件,每个层级的数据文件按照有序的方式存储数据。一般来说,MergeTree包括两个主要的层级:内存层级(Memory Level)和磁盘层级(Disk Level)。层级的数据结构可以是任何方便键值查找的数据结构。
内存层级是LSM树的写入缓冲区,用于接收新写入的数据。当内存层级的数据量达到一定阈值时,会触发一个合并操作,将内存层级的数据与磁盘层级的数据进行合并。
磁盘层级是LSM树的持久化存储,由多个有序的数据文件组成。每个数据文件的大小一般是固定的,新写入的数据会被追加到最新的数据文件中。当磁盘层级的数据文件数量达到一定阈值时,会触发一个合并操作,将多个数据文件合并成一个更大的数据文件。
MergeTree的合并操作主要包括两个步骤:合并排序和去重。合并排序是将多个有序的数据文件合并成一个更大的有序数据文件,通常使用归并排序算法来实现。去重是为了避免重复数据的存储,合并过程中会检查并去除重复的数据。
从上可以看出,ClickHouse是服务于大规模数据的,可以专门去用于查询类型的大量数据,基于列式存储结构可以快速地提取出需要的数据。
另外,ClickHouse不支持ACID事务,它更关注于高效的查询。但是它也有一些措施,例如数据复制和分布式表。
PostgreSQL
PostgreSql是一个开源的关系型数据库,采用行式存储结构,总体和Mysql比较像,同样支持SQL语言和Mybatis操作。
1、数据类型支持:PostgreSQL支持更多的数据类型,包括数组、JSON、XML、地理空间数据等。MySQL则更加专注于基本的数据类型支持。
2、SQL语法:PostgreSQL对SQL标准的支持更加完整和严格,遵循更多的SQL标准规范。MySQL在某些情况下可能有一些非标准的语法和行为。
3、存储过程和触发器:PostgreSQL提供了更强大和灵活的存储过程和触发器支持,支持多种编程语言(如PL/pgSQL、PL/Python、PL/Perl等)。MySQL的存储过程和触发器功能相对较弱。
4、多版本并发控制(MVCC):PostgreSQL使用MVCC来处理并发访问,允许多个事务同时读取和修改数据库。MySQL在某些情况下使用锁机制来处理并发,可能会导致性能瓶颈。
暂时先讲到这里,休息一下新开一篇来讲手写RPC框架。