spring cloud(四) Eureka配置Httpbasic验证+Eureka配置详解
目录
- spring cloud(一) 从一个简单的springboot服务开始
- spring cloud(二) 起步,集成Eureka服务发现
- spring cloud(三)Eureka高可用性+Feign声明式Rest客户端
- spring cloud(四) Eureka配置Httpbasic验证+Eureka配置详解
未完待续
一、 为EurekaServer配置Httpbasic验证
为了保证服务的安全性,我们为EurekaServer配置Httpbasic验证,只有知道username和password的服务示例才能注册到EurekaServer。那接下来我们修改一下eureka_server项目,配置httpbasic验证,然后为product_server和consume_server配置eureka_server的username和password。
1. 引入spring-boot-starter-security依赖
org.springframework.boot
spring-boot-starter-security
2. 配置security
首先需要禁用csrf(cross site request forgery),当spring security在classpath路径下,它将要求每个客户端请求带上csrf token,eureka客户端通常不会拥有一个有效的csrf token,我们需要在配置中禁用对/eureka/**这个端点进行csrf验证。然后我们还需要开启httpbasic验证。此时我们便可以通过url中配置username和password,去验证客户端的可靠性。为了简单起见,我们在启动类中配置。
package com.yshmsoft;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
@EnableWebSecurity
static class WebSecurityConfigure extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
// 在/eureka/**端点忽略csrf验证
http.csrf().ignoringAntMatchers("/eureka/**");
// 配置使请求需要通过httpBasic或form验证
http.authorizeRequests()
.anyRequest().authenticated()
.and()
.formLogin()
.and()
.httpBasic();
super.configure(http);
}
}
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}3. 修改之前所有项目中eureka服务的url,使支持httpBasic验证
# eureka_server的application.yml
spring:
application:
name: eureka-server
security:
user:
name: user
password: 123456
logging:
level:
root: info
org.springframework:
security: debug
---
server:
port: 8761
eureka:
client:
service-url:
defaultZone: http://user:123456@peer2:8762/eureka/
instance:
hostname: peer1
prefer-ip-address: true
spring:
profiles: peer1
---
server:
port: 8762
eureka:
client:
fetch-registry: false
register-with-eureka: false
service-url:
defaultZone: http://user:123456@peer1:8761/eureka/
instance:
hostname: peer2
prefer-ip-address: true
spring:
profiles: peer2# consume_server的application.yml
spring:
application:
name: consume-server
server:
port: 8000
logging:
level:
root: info
eureka:
client:
service-url:
defaultZone: http://user1:123456@peer1:8761/eureka/,http://user:123456@peer2:8762/eureka/# product_server的application.yml
server:
port: 8080
spring:
security:
user:
name: user
password: 123456
datasource:
platform: h2
schema: classpath:schema.sql
data: classpath:data.sql
jpa:
generate-ddl: false
show-sql: true
hibernate:
ddl-auto: none
application:
name: product-server
logging:
level:
root: info
org.hibernate: info
eureka:
client:
service-url:
defaultZone: http://user:123456@peer1:8761/eureka/,http://user:123456@peer2:8762/eureka/
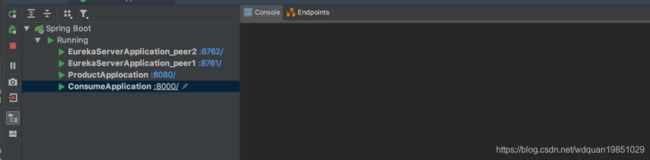
4. 启动服务测试服务是否正常运行
项目启动成功:
登录验证:

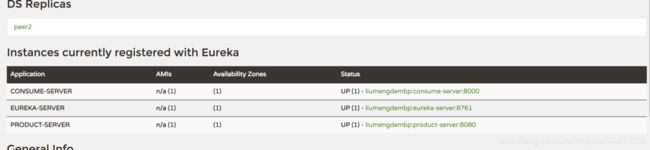
登录之后服务注册正常:
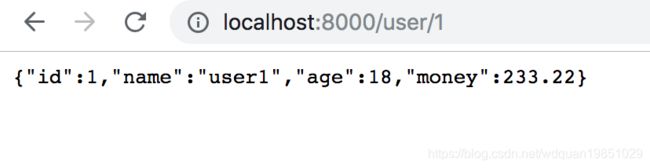
服务正常访问:
配置httpBasic验证完成
二、 spring cloud中Eureka instance配置参数介绍
- appname 设置appname 默认值为null 如果设置spring.application.name则为 spring.application.name
- virtualHostName 设置虚拟主机名 默认值为unknown如果设置spring.application.name则为 spring.application.name
- secureVirtualHostName 设置安全虚拟主机名 默认值为null 如果设置spring.application.name则为 spring.application.name
Eureka配置源码:

- instanceEnabledOnit 设置eureka实例是否在注册到eureka server之后立刻可以提供服务,一般情况下实例注册到eureka server之后会首先执行一些其他任务。 该值默认为false
- nonSecurePort 非https下的端口号 默认为80
- securePort https下的端口号 默认为443
- nonSecurePortEnabled 是否启用非https端口 默认true
- securePortEnabled 是否启用https端口 默认为false
- leaseRenewalIntervalInSeconds 设置每隔多长时间向eureka server发送一次心跳包,当超过一定时间eureka server会将超时的client从服务列表中移除 默认为30
- leaseExpirationDurationInSeconds 设置接收客户端心跳包超时时间,超过指定时间没有心跳的客户端将被移除,此值至少要比leaseRenewalIntervalInSeconds大才行 默认为90
- instanceId 配置实例的唯一id
- metadataMap 自定义元数据以name/value对的形式
- statusPageUrlPath 查看服务信息的url 此服务依赖spring-boot-actuator 默认值为actuatorPrefix + "/info"
- homePageUrlPath 服务跟路径 默认为 /
- homePageUrl 服务本路径 默认为null
- healthCheckUrlPath 服务健康状态检查url此服务依赖spring-boot-actuator 默认为actuatorPrefix + "/health"
- healthCheckUrl 服务健康状态检查url 此服务依赖spring-boot-actuator 默认为null
- secureHealthCheckUrl 服务健康状态检查url 此服务依赖spring-boot-actuator 默认为null
- preferIpAddress 指优先使用ip地址而不是os提供的hostname 默认false
三、 spring cloud中 Eureka client配置参数介绍
- enabled 是否启用此eureka client 默认true
- registryFetchIntervalSeconds 间隔多久从defaultUrl同步一次服务注册表默认30
- instanceInfoReplicationIntervalSeconds 间隔多久将instance的变化同步到eureka server 默认为30
- initialInstanceInfoReplicationIntervalSeconds 初始多长时间将instance信息复制到eureka server 默认为40
- 设置多久轮询一次eureka server信息 默认为5分钟
- proxyHost 代理host
- proxyPort 代理port
- proxyUserName 代理username
- proxyPassword 代理password
- eurekaServerReadTimeoutSeconds 从eureka server读取信息的超时时间 默认为8
- eurekaServerConnectTimeoutSeconds 和eureka server连接超时时间默认为5
- backupRegistryImpl 获取实现了eureka客户端在第一次启动时读取注册表的信息作为回退选项的实现名称
- eurekaServerTotalConnections 设置从eureka client连接所有eureka server的总连接数 默认为200
- eurekaServerTotalConnectionsPerHost 设置 eureka连接的所有eureka server的host 默认为50
- shouldUnregisterOnShutdown 当服务停止时是否取消注册 默认值为true
- allowRedirects 设置eureka server是否可以重定向eureka client到备份服务器或集群中
- eurekaServerURLContext 表示eureka注册中心的路径,如果配置为eureka,则为http://x.x.x.x:x/eureka/,在eureka的配置文件中加入此配置表示eureka作为客户端向注册中心注册,从而构成eureka集群。此配置只有在eureka服务器ip地址列表是在DNS中才会用到,默认为null
- eurekaServerPort 获取eureka服务器的端口,此配置只有在eureka服务器ip地址列表是在DNS中才会用到。默认为null
- eurekaServerDNSName 获取要查询的DNS名称来获得eureka服务器,此配置只有在eureka服务器ip地址列表是在DNS中才会用到。默认为null
- region 实例所在region 默认为us-east-1
- eurekaConnectionIdleTimeoutSeconds 设置连接空闲多长时间自动关闭 默认为30
- registryRefreshSingleVipAddress 设置client只对某个instance的注册表感兴趣默认为null
- heartbeatExecutorThreadPoolSize 设置heartbeatExecutor的线程池大小 默认为2
- heartbeatExecutorExponentialBackOffBound 设置heartbeatExecutor最大重试次数 默认为10
- cacheRefreshExecutorThreadPoolSize 初始化refreshExector线程池大小 默认为2
- cacheRefreshExecutorExponentialBackOffBound 设置刷新操作的最大重试次数默认为10
- serviceUrl 设置availability zone的map
- gZipContent 设置是否支持gzip压缩
- useDnsForFetchingServiceUrls eureka客户端是否应该使用DNS机制来获取eureka服务器的地址列表,默认为false
- registerWithEureka 设置是否注册到eureka server 默认为true
- fetchRemoteRegionsRegistry 设置是否从eureka获取regions列表 默认为true
- filterOnlyUpInstances 设置是否过滤只留下状态为UP的instance 默认为true
- fetchRegistry 设置是否获取注册表 默认为true
- dollarReplacement 获取一个$符号的替身 默认为_-
- escapeCharReplacement 获取一个的替身默认为_
本篇介绍了如何为eureka server配置httpBasic验证。详细列出了eureka的各项参数配置以及默认值。在分布式场景下,我们怎么保证服务的负载均衡呢?下篇将介绍spring cloud中负载均衡的应用。敬请期待