pg事务篇(二)—— 事务ID回卷与事务冻结(freeze)
一、 什么是事务ID回卷
前篇文章留下了一个问题,旧事务不应看见新事务修改结果,txid通过比较大小来判断是否可见,任何事务只可见txid<其自身txid的事务修改结果。但txid是无符号的32位整型,它并不是无限的,当42亿数据用尽之后又应该如何判断可见性?
pg事务篇(一)—— 事务与多版本并发控制MVCC_Hehuyi_In的博客-CSDN博客_pg 事务
pg将txid空间视为一个环,若不进行特殊处理,txid到达最大值后又会从3开始分配(0-2保留),如果进行简单的比大小,之前的事务就可以看到这个新事务创建的元组,而新事务不能看到之前事务创建的元组,这违反了事务的可见性。这种现象称为PG的事务ID回卷问题。
二、 事务ID的比较方法
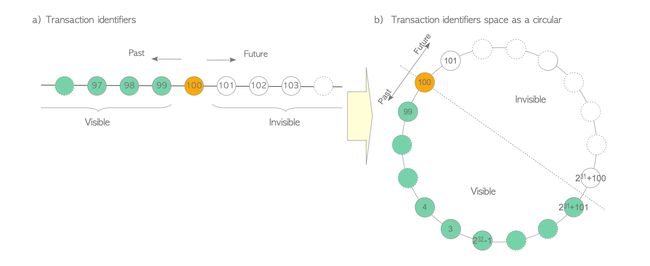
实际上虽然txid空间有42亿,却并非按实际数字大小来判断可见性。pg将txid空间一分为二,对于某个特定的txid,其后约21亿个txid属于未来,均不可见;其前约21亿个txid属于过去,均可见。
例如对于txid=100的事务,从101到2^31+100均为不可见事务(即n+1到n+2^31);从2^31+101到99均为可见事务(即n+2^31+1到n-1)。
我们来看代码中实际的比较方法:
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool TransactionIdPrecedes(TransactionId id1, TransactionId id2) // 结果返回一个bool值
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2)) //若其中一个不是普通id,则其一定较新(较大)
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}1. 比较特殊事务与普通事务txid
首先利用TransactionIdIsNormal判断当前txid是不是普通的txid(即txid>3),前面说过0-2都是保留的txid,它们比任何普通txid都要旧。
- 0:InvalidTransactionId,表示无效的事务ID
- 1:BootstrapTransactionId,表示系统表初始化时的事务ID,比任何普通的事务ID都旧。
- 2:FrozenTransactionId,冻结的事务ID,比任何普通的事务ID都旧。
- 大于2的事务ID都是普通的事务ID。
比较方法非常简单,就通过
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);可以代入值实验一下:
- 若id1=10,id2=2,return(10<2)。明显10<2为假,所以10比2大,普通事务较新。
- 若id1=2,id2=10,return(2<10)。2<10为真,所以10比2大,还是普通事务较新。
2. 普通事务间的比较
这里其实用到一个小技巧,把两个事务ID相减后转为int 32类型。
diff = (int32) (id1 - id2);
return (diff < 0);由于int 32带符号,需要用第一位表示符号位,所以它能表示的正数比unsigned int 32类型少一半,int 32的数据取值范围为[-2^(n-1),2^(n-1)-1],即[-2^31,2^31-1]。当两个txid相减结果>2^31时,转为int 32后其实是个负数(符号位从0变成了1)。
我们用回前面图的例子,id1=2^31+101,id2=100。id1-id2=2^31+1,用二进制表示即:100...中间30个0...001。当转为int 32后,由于第一位为符号位,而1表示负数,所以转换后这个值其实就是-1,小于0,因此txid=2^31+101的事务反而要旧。
这样的方法是不是就不会再有问题了呢?其实不是,如果图中的100真的是非常非常旧的事务,那它确实应该被2^31+101这个事务看见,此时上面的判断就是错的。
也就是说如果id2确实是回卷前的txid,上面的判断方法就会出现问题。为了避免这种问题,pg必须保证一个数据库中两个有效的事务之间的年龄最多是2^31(同一个数据库中,存在的最旧和最新两个事务txid相差不得超过2^31)。
接下来我们来看pg是如何做到的。
三、 冻结事务
为了保证同一个数据库中的最新和最旧的两个事务之间的年龄不超过2^31,pg引入了冻结(freeze)功能。
我们会在下文具体分析符合什么条件的元组才需要freeze,这里会先分析不同版本freeze具体的实现方法。
1. 9.4之前的实现方法
在9.4之前的版本中,freeze实现的方法很简单——直接将符合条件的元组的t_xmin设置为2(FrozenTransactionId),即可使其对所有普通事务可见。该元组原来对应的txid相当于被回收了,经过不断处理,就可以控制一个数据库的最老和最新的事务年龄不超过2^31。
但是这样的实现有很多问题:
- 当前可见的数据页(通过visibility map可以快速定位)需要全部扫描,带来大量的IO扫描
- 符合条件的元组需要更新xmin,造成大量的脏页,带来大量的IO
2. 9.4之后冻结清理实现
为了解决之前老版本存在的问题,9.4及之后不直接修改符合条件元组的t_xmin,而是:
- 只更新元组头结点的t_infomask为HEAP_XMIN_FROZEN,表示该元组已经被冻结过(frozen)
- 有些插入操作,也可以直接将记录置为frozen,例如大批量的COPY数据,insert into等
- 如果整个page所有记录已经frozen,则在vm文件中标记为FROZEN,冻结清理会跳过该页,减少了IO扫描
其中值得注意的是,如果vm页损坏了,可以通过vacuum DISABLE_PAGE_SKIPPING强制扫描所有的数据页。
可以看出,9.4之后对freeze的实现进行了很多方面的优化,提高了其性能。不过如果是9.4之前的数据通过pg_upgrade的脚本导入的数据,仍然会发现有t_xmin为2的元组。autovaccum可以周期性地进行freeze之外,也可以执行VACUUM FREEZE命令来强制freeze。
至此,我们弄清楚了freeze是怎么实现的,接下来会去分析元组满足什么样的条件才会触发周期性的freeze。在pg中,这个条件是由一系列的参数设置来实现的。
四、 需要冻结的元组
与freeze相关的参数主要有三个:
- vacuum_freeze_min_age
- vacuum_freeze_table_age
- autovacuum_freeze_max_age
1. vacuum_freeze_min_age
每个元组距离上次freeze操作后多久(多少txid)需要重新freeze。
- 每次表被freeze之后,会更新pg_class.relfrozenxid列为本次freeze的txid。该列保存对应表最近冻结的txid,意味着小于此值的txid均已被冻结。
- 表年龄就是当前最新的txid与relfrozenxid的差值,而元组年龄可以理解为每个元组的t_xmin与relfrozenxid的差值。当元组年龄超过vacuum_freeze_min_age后需要进行freeze。
- 增大该参数可以避免一些无用的freeze操作,减小该参数可以使表在必须被强制清理前保留更多的XID。
惰性冻结

2. vacuum_freeze_table_age
在freeze过程中,需要对所有可见且未被all-frozen的数据页进行扫描,这个扫描过程称为aggressive vacuum(迫切冻结)。每次vacuum都去扫描每个表所有符合条件的数据页显然是不现实的,而vacuum_freeze_table_age就用来决定aggressive vacuum的周期。
- vacuum_freeze_table_age表示表的年龄大于该值时,会进行aggressive vacuum。该参数最大值为20亿,最小值为1.5亿。如果为0,则每次扫描表都进行aggressive vacuum。
-
如果当前db中所有表都进行了冻结,pg会更新pg_database.datfrozenxid列,该列包含对应db中最小的pg_class.relfrozenxid

图:aggressive vacuum(9.6前)

9.6开始利用vm进行判断

到这里,我们可以看出:
- vacuum_freeze_table_age决定要不要进行aggressive vacuum(而不决定要不要冻结元组);当表的年龄超过vacuum_freeze_table_age则会aggressive vacuum
- vacuum_freeze_min_age决定要不要冻结元组;当元组的年龄超过vacuum_freeze_min_age后可以进行freeze
为了保证上文中同一数据库的最老最新事务差不超过2^31的原则,两次aggressive vacuum之间的新老事务差不能超过2^31,即vacuum_freeze_table_age不能超过20亿减vacuum_freeze_min_age。但是看上面的参数,很明显不能保证这个约束,为了解决这个问题,pg引入了autovacuum_freeze_max_age参数。
3. autovacuum_freeze_max_age
如果当前最新的txid减去元组的t_xmin>=autovacuum_freeze_max_age,则元组对应的表会强制进行autovacuum(即使已经关闭了autovacuum)。该参数最小值为2亿,最大值为20亿。
也就是说,在经过autovacuum_freeze_max_age-vacuum_freeze_min_age的txid增长之后,这个表肯定会被强制进行一次freeze。因为autovacuum_freeze_max_age最大值为20亿,所以在两次freeze之间,txid的增长肯定不会超过20亿,这就保证了上文中所说的20亿原则。
4. 参数设置建议
值得一提的是,如果vacuum_freeze_table_age>autovacuum_freeze_max_age要高,则在vacuum_freeze_table_age生效前autovacuum_freeze_max_age已生效,起不到减少数据页扫描的作用。所以建议vacuum_freeze_table_age要设置的比autovacuum_freeze_max_age小(官方文档建议为95%),太小会造成频繁的aggressive vacuum。
freeze 操作会消耗大量的IO,对于不经常更新的表,可以合理地增大autovacuum_freeze_max_age和vacuum_freeze_min_age的差值。但是如果设置过大,因为需要存储更多的事务提交信息,会造成pg_xact 和 pg_commit目录占用更多的空间。例如,我们把autovacuum_freeze_max_age设置为最大值20亿,pg_xact大约占500MB,pg_commit_ts大约是20GB(一个事务的提交状态占2位)。如果是对存储比较敏感的用户,也要考虑这点影响。
减小vacuum_freeze_min_age会造成vacuum 做很多无用功,因为当数据库freeze了符合条件的row后,这个row很可能接着会被改变。理想的状态就是,当该行不会被改变,才去freeze这行。
遗憾的是,无论参数怎么调优,都存在一个问题,freeze是不能主动预测的,只能被动触发,所以更提倡用户进行主动预测需要freeze 的时机,选择合适的时间(比如说应用负载较低的时间)主动执行vacuum freeze命令。接下来我们会具体讨论如何去做关于vacuum freeze 的运维。
五、 关于主动执行冻结的建议
当数据库最老的表年龄达到了1000万时,数据库会打印如下的warning:
WARNING: database "mydb" must be vacuumed within 177009986 transactions
HINT: To avoid a database shutdown, execute a database-wide VACUUM in "mydb".
根据提示,对该数据库执行vacuum free命令,可以解决这个潜在的问题。注意因为非超级用户没有权限更新database的datfrozenxid,只能使用超级用户执行vacuum free database_name。
当数据库可用的txid空间还有100万时,即当前最新与最老txid差值还差100万达到20亿时,pg会变为只读并拒绝开启任何新的事务,同时在日志中打印如下错误信息:
ERROR: database is not accepting commands to avoid wraparound data loss in database "mydb"
HINT: Stop the postmaster and vacuum that database in single-user mode.
根据提示,用户可以以单用户模式启动pg并执行vacuum freeze命令,但此时已经影响了业务。
如果freeze发生的时间正好是数据库比较繁忙的时间,会造成IO资源争抢,导致正常的业务受损。用户可以自己监控数据库和表的年龄,在业务比较空闲的时间主动执行以下操作:
- 查询当前所有表的年龄:
SELECT c.oid::regclass as table_name, greatest(age(c.relfrozenxid),age(t.relfrozenxid)) as age FROM pg_class c LEFT JOIN pg_class t ON c.reltoastrelid = t.oid WHERE c.relkind IN ('r', 'm'); - 查询所有数据库的年龄:
SELECT datname, age(datfrozenxid) FROM pg_database; - 设置vacuum_cost_delay为一个比较高的数值(例如50ms),减少普通vacuum对正常数据查询的影响
- 设置vacuum_freeze_table_age=0.5*autovacuum_freeze_max_age,vacuum_freeze_min_age为原来值的0.1倍
- 对上面查询的表依次执行vacuum freeze,注意要预估好时间。
目前已经有很多实现好的开源PostgreSQL vacuum freeze监控管理工具,比如flexible-freeze,能够:
- 确定数据库的高峰和低峰期
- 在数据库低峰期创建一个cron job执行flexible_freeze.py
- flexible_freeze.py会自动对具有最老XID的表进行vacuum freeze
参考
PgSQL · 特性分析 · 事务ID回卷问题
The Internals of PostgreSQL : Chapter 5 Concurrency Control
The Internals of PostgreSQL : Chapter 6 Vacuum Processing
PostgreSQL: Documentation: 10: 19.11. Client Connection Defaults