基于重参数结构DiverseBranchBlock改进YOLO的遥感苔藓分割系统
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
遥感图像在地理信息系统、环境监测、农业和城市规划等领域具有广泛的应用。其中,遥感苔藓分割是一项重要的任务,它可以帮助研究人员了解苔藓的分布、生长状态以及其对环境的响应。然而,由于苔藓的特殊性质,如小尺寸、低对比度和复杂的背景干扰等,苔藓分割任务仍然具有挑战性。
目前,深度学习已经在图像分割任务中取得了显著的成果。其中,基于YOLO(You Only Look Once)的目标检测算法在实时性和准确性方面表现出色,成为了苔藓分割任务中的一种重要方法。然而,传统的YOLO算法在处理苔藓分割任务时存在一些问题,如对小尺寸苔藓的检测效果不佳、对复杂背景的干扰较大等。
因此,本研究旨在通过引入重参数结构DiverseBranchBlock来改进YOLO算法,提高苔藓分割系统的性能。DiverseBranchBlock是一种有效的网络模块,它可以增加网络的深度和宽度,提高模型的表达能力。通过在YOLO算法中引入DiverseBranchBlock,我们可以更好地捕捉苔藓的细节信息,提高对小尺寸苔藓的检测能力,并减少复杂背景的干扰。
本研究的意义主要体现在以下几个方面:
首先,改进后的YOLO算法可以提高苔藓分割系统的准确性和鲁棒性。通过引入DiverseBranchBlock,我们可以更好地利用图像中的信息,提高对苔藓的检测和分割能力。这将有助于研究人员更准确地了解苔藓的分布和生长状态,为环境监测和生态研究提供更可靠的数据支持。
其次,改进后的苔藓分割系统可以提高遥感图像处理的效率。传统的苔藓分割方法通常需要耗费大量的时间和计算资源,限制了其在实际应用中的推广和应用。而基于重参数结构DiverseBranchBlock改进的YOLO算法具有较高的实时性,可以在较短的时间内完成苔藓分割任务,提高遥感图像处理的效率。
最后,本研究的方法还可以为其他遥感图像分割任务提供借鉴。苔藓分割任务具有一定的特殊性,如小尺寸、低对比度和复杂背景等。通过在苔藓分割任务中引入DiverseBranchBlock,我们可以探索一种通用的网络结构改进方法,为其他遥感图像分割任务提供参考和借鉴。
综上所述,基于重参数结构DiverseBranchBlock改进YOLO的遥感苔藓分割系统具有重要的研究意义和应用价值。通过提高苔藓分割系统的准确性和实时性,我们可以更好地了解苔藓的分布和生长状态,为环境监测和生态研究提供更可靠的数据支持。同时,本研究的方法还可以为其他遥感图像分割任务提供借鉴,推动遥感图像处理技术的发展。
2.图片演示
3.视频演示
基于重参数结构DiverseBranchBlock改进YOLO的遥感苔藓分割系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TXDatasets。

eiseg是一个图形化的图像注释工具,支持COCO和YOLO格式。以下是使用eiseg将图片标注为COCO格式的步骤:
(1)下载并安装eiseg。
(2)打开eiseg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的JSON文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
import contextlib
import json
import cv2
import pandas as pd
from PIL import Image
from collections import defaultdict
from utils import *
# Convert INFOLKS JSON file into YOLO-format labels ----------------------------
def convert_infolks_json(name, files, img_path):
# Create folders
path = make_dirs()
# Import json
data = []
for file in glob.glob(files):
with open(file) as f:
jdata = json.load(f)
jdata['json_file'] = file
data.append(jdata)
# Write images and shapes
name = path + os.sep + name
file_id, file_name, wh, cat = [], [], [], []
for x in tqdm(data, desc='Files and Shapes'):
f = glob.glob(img_path + Path(x['json_file']).stem + '.*')[0]
file_name.append(f)
wh.append(exif_size(Image.open(f))) # (width, height)
cat.extend(a['classTitle'].lower() for a in x['output']['objects']) # categories
# filename
with open(name + '.txt', 'a') as file:
file.write('%s\n' % f)
# Write *.names file
names = sorted(np.unique(cat))
# names.pop(names.index('Missing product')) # remove
with open(name + '.names', 'a') as file:
[file.write('%s\n' % a) for a in names]
# Write labels file
for i, x in enumerate(tqdm(data, desc='Annotations')):
label_name = Path(file_name[i]).stem + '.txt'
with open(path + '/labels/' + label_name, 'a') as file:
for a in x['output']['objects']:
# if a['classTitle'] == 'Missing product':
# continue # skip
category_id = names.index(a['classTitle'].lower())
# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]
box = np.array(a['points']['exterior'], dtype=np.float32).ravel()
box[[0, 2]] /= wh[i][0] # normalize x by width
box[[1, 3]] /= wh[i][1] # normalize y by height
box = [box[[0, 2]].mean(), box[[1, 3]].mean(), box[2] - box[0], box[3] - box[1]] # xywh
if (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
# Split data into train, test, and validate files
split_files(name, file_name)
write_data_data(name + '.data', nc=len(names))
print(f'Done. Output saved to {os.getcwd() + os.sep + path}')
# Convert vott JSON file into YOLO-format labels -------------------------------
def convert_vott_json(name, files, img_path):
# Create folders
path = make_dirs()
name = path + os.sep + name
# Import json
data = []
for file in glob.glob(files):
with open(file) as f:
jdata = json.load(f)
jdata['json_file'] = file
data.append(jdata)
# Get all categories
file_name, wh, cat = [], [], []
for i, x in enumerate(tqdm(data, desc='Files and Shapes')):
with contextlib.suppress(Exception):
cat.extend(a['tags'][0] for a in x['regions']) # categories
# Write *.names file
names = sorted(pd.unique(cat))
with open(name + '.names', 'a') as file:
[file.write('%s\n' % a) for a in names]
# Write labels file
n1, n2 = 0, 0
missing_images = []
for i, x in enumerate(tqdm(data, desc='Annotations')):
f = glob.glob(img_path + x['asset']['name'] + '.jpg')
if len(f):
f = f[0]
file_name.append(f)
wh = exif_size(Image.open(f)) # (width, height)
n1 += 1
if (len(f) > 0) and (wh[0] > 0) and (wh[1] > 0):
n2 += 1
# append filename to list
with open(name + '.txt', 'a') as file:
file.write('%s\n' % f)
# write labelsfile
label_name = Path(f).stem + '.txt'
with open(path + '/labels/' + label_name, 'a') as file:
for a in x['regions']:
category_id = names.index(a['tags'][0])
# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]
box = a['boundingBox']
box = np.array([box['left'], box['top'], box['width'], box['height']]).ravel()
box[[0, 2]] /= wh[0] # normalize x by width
box[[1, 3]] /= wh[1] # normalize y by height
box = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2], box[3]] # xywh
if (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
else:
missing_images.append(x['asset']['name'])
print('Attempted %g json imports, found %g images, imported %g annotations successfully' % (i, n1, n2))
if len(missing_images):
print('WARNING, missing images:', missing_images)
# Split data into train, test, and validate files
split_files(name, file_name)
print(f'Done. Output saved to {os.getcwd() + os.sep + path}')
# Convert ath JSON file into YOLO-format labels --------------------------------
def convert_ath_json(json_dir): # dir contains json annotations and images
# Create folders
dir = make_dirs() # output directory
jsons = []
for dirpath, dirnames, filenames in os.walk(json_dir):
jsons.extend(
os.path.join(dirpath, filename)
for filename in [
f for f in filenames if f.lower().endswith('.json')
]
)
# Import json
n1, n2, n3 = 0, 0, 0
missing_images, file_name = [], []
for json_file in sorted(jsons):
with open(json_file) as f:
data = json.load(f)
# # Get classes
# try:
# classes = list(data['_via_attributes']['region']['class']['options'].values()) # classes
# except:
# classes = list(data['_via_attributes']['region']['Class']['options'].values()) # classes
# # Write *.names file
# names = pd.unique(classes) # preserves sort order
# with open(dir + 'data.names', 'w') as f:
# [f.write('%s\n' % a) for a in names]
# Write labels file
for x in tqdm(data['_via_img_metadata'].values(), desc=f'Processing {json_file}'):
image_file = str(Path(json_file).parent / x['filename'])
f = glob.glob(image_file) # image file
if len(f):
f = f[0]
file_name.append(f)
wh = exif_size(Image.open(f)) # (width, height)
n1 += 1 # all images
if len(f) > 0 and wh[0] > 0 and wh[1] > 0:
label_file = dir + 'labels/' + Path(f).stem + '.txt'
nlabels = 0
try:
with open(label_file, 'a') as file: # write labelsfile
# try:
# category_id = int(a['region_attributes']['class'])
# except:
# category_id = int(a['region_attributes']['Class'])
category_id = 0 # single-class
for a in x['regions']:
# bounding box format is [x-min, y-min, x-max, y-max]
box = a['shape_attributes']
box = np.array([box['x'], box['y'], box['width'], box['height']],
dtype=np.float32).ravel()
box[[0, 2]] /= wh[0] # normalize x by width
box[[1, 3]] /= wh[1] # normalize y by height
box = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2],
box[3]] # xywh (left-top to center x-y)
if box[2] > 0. and box[3] > 0.: # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
n3 += 1
nlabels += 1
if nlabels == 0: # remove non-labelled images from dataset
os.system(f'rm {label_file}')
# print('no labels for %s' % f)
continue # next file
# write image
img_size = 4096 # resize to maximum
img = cv2.imread(f) # BGR
assert img is not None, 'Image Not Found ' + f
r = img_size / max(img.shape) # size ratio
if r < 1: # downsize if necessary
h, w, _ = img.shape
img = cv2.resize(img, (int(w * r), int(h * r)), interpolation=cv2.INTER_AREA)
ifile = dir + 'images/' + Path(f).name
if cv2.imwrite(ifile, img): # if success append image to list
with open(dir + 'data.txt', 'a') as file:
file.write('%s\n' % ifile)
n2 += 1 # correct images
except Exception:
os.system(f'rm {label_file}')
print(f'problem with {f}')
else:
missing_images.append(image_file)
nm = len(missing_images) # number missing
print('\nFound %g JSONs with %g labels over %g images. Found %g images, labelled %g images successfully' %
(len(jsons), n3, n1, n1 - nm, n2))
if len(missing_images):
print('WARNING, missing images:', missing_images)
# Write *.names file
names = ['knife'] # preserves sort order
with open(dir + 'data.names', 'w') as f:
[f.write('%s\n' % a) for a in names]
# Split data into train, test, and validate files
split_rows_simple(dir + 'data.txt')
write_data_data(dir + 'data.data', nc=1)
print(f'Done. Output saved to {Path(dir).absolute()}')
def convert_coco_json(json_dir='../coco/annotations/', use_segments=False, cls91to80=False):
save_dir = make_dirs() # output directory
coco80 = coco91_to_coco80_class()
# Import json
for json_file in sorted(Path(json_dir).resolve().glob('*.json')):
fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # folder name
fn.mkdir()
with open(json_file) as f:
data = json.load(f)
# Create image dict
images = {'%g' % x['id']: x for x in data['images']}
# Create image-annotations dict
imgToAnns = defaultdict(list)
for ann in data['annotations']:
imgToAnns[ann['image_id']].append(ann)
# Write labels file
for img_id, anns in tqdm(imgToAnns.items(), desc=f'Annotations {json_file}'):
img = images['%g' % img_id]
h, w, f = img['height'], img['width'], img['file_name']
bboxes = []
segments = []
for ann in anns:
if ann['iscrowd']:
continue
# The COCO box format is [top left x, top left y, width, height]
box = np.array(ann['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
if box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0
continue
cls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # class
box = [cls] + box.tolist()
if box not in bboxes:
bboxes.append(box)
# Segments
if use_segments:
if len(ann['segmentation']) > 1:
s = merge_multi_segment(ann['segmentation'])
s = (np.concatenate(s, axis=0) / np.array([w, h])).reshape(-1).tolist()
else:
s = [j for i in ann['segmentation'] for j in i] # all segments concatenated
s = (np.array(s).reshape(-1, 2) / np.array([w, h])).reshape(-1).tolist()
s = [cls] + s
if s not in segments:
segments.append(s)
# Write
with open((fn / f).with_suffix('.txt'), 'a') as file:
for i in range(len(bboxes)):
line = *(segments[i] if use_segments else bboxes[i]), # cls, box or segments
file.write(('%g ' * len(line)).rstrip() % line + '\n')
def min_index(arr1, arr2):
"""Find a pair of indexes with the shortest distance.
Args:
arr1: (N, 2).
arr2: (M, 2).
Return:
a pair of indexes(tuple).
"""
dis = ((arr1[:, None, :] - arr2[None, :, :]) ** 2).sum(-1)
return np.unravel_index(np.argmin(dis, axis=None), dis.shape)
def merge_multi_segment(segments):
"""Merge multi segments to one list.
Find the coordinates with min distance between each segment,
then connect these coordinates with one thin line to merge all
segments into one.
Args:
segments(List(List)): original segmentations in coco's json file.
like [segmentation1, segmentation2,...],
each segmentation is a list of coordinates.
"""
s = []
segments = [np.array(i).reshape(-1, 2) for i in segments]
idx_list = [[] for _ in range(len(segments))]
# record the indexes with min distance between each segment
for i in range(1, len(segments)):
idx1, idx2 = min_index(segments[i - 1], segments[i])
idx_list[i - 1].append(idx1)
idx_list[i].append(idx2)
# use two round to connect all the segments
for k in range(2):
# forward connection
if k == 0:
for i, idx in enumerate(idx_list):
# middle segments have two indexes
# reverse the index of middle segments
if len(idx) == 2 and idx[0] > idx[1]:
idx = idx[::-1]
segments[i] = segments[i][::-1, :]
segments[i] = np.roll(segments[i], -idx[0], axis=0)
segments[i] = np.concatenate([segments[i], segments[i][:1]])
# deal with the first segment and the last one
if i in [0, len(idx_list) - 1]:
s.append(segments[i])
else:
idx = [0, idx[1] - idx[0]]
s.append(segments[i][idx[0]:idx[1] + 1])
else:
for i in range(len(idx_list) - 1, -1, -1):
if i not in [0, len(idx_list) - 1]:
idx = idx_list[i]
nidx = abs(idx[1] - idx[0])
s.append(segments[i][nidx:])
return s
def delete_dsstore(path='../datasets'):
# Delete apple .DS_store files
from pathlib import Path
files = list(Path(path).rglob('.DS_store'))
print(files)
for f in files:
f.unlink()
if __name__ == '__main__':
source = 'COCO'
if source == 'COCO':
convert_coco_json('./annotations', # directory with *.json
use_segments=True,
cls91to80=True)
elif source == 'infolks': # Infolks https://infolks.info/
convert_infolks_json(name='out',
files='../data/sm4/json/*.json',
img_path='../data/sm4/images/')
elif source == 'vott': # VoTT https://github.com/microsoft/VoTT
convert_vott_json(name='data',
files='../../Downloads/athena_day/20190715/*.json',
img_path='../../Downloads/athena_day/20190715/') # images folder
elif source == 'ath': # ath format
convert_ath_json(json_dir='../../Downloads/athena/') # images folder
# zip results
# os.system('zip -r ../coco.zip ../coco')
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----datasets
-----coco128-seg
|-----images
| |-----train
| |-----valid
| |-----test
|
|-----labels
| |-----train
| |-----valid
| |-----test
|
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 export.py
def export_formats():
# YOLOv5 export formats
x = [
['PyTorch', '-', '.pt', True, True],
['TorchScript', 'torchscript', '.torchscript', True, True],
['ONNX', 'onnx', '.onnx', True, True],
['OpenVINO', 'openvino', '_openvino_model', True, False],
['TensorRT', 'engine', '.engine', False, True],
['CoreML', 'coreml', '.mlmodel', True, False],
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
['TensorFlow GraphDef', 'pb', '.pb', True, True],
['TensorFlow Lite', 'tflite', '.tflite', True, False],
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
['TensorFlow.js', 'tfjs', '_web_model', False, False],
['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
def try_export(inner_func):
# YOLOv5 export decorator, i..e @try_export
inner_args = get_default_args(inner_func)
def outer_func(*args, **kwargs):
prefix = inner_args['prefix']
try:
with Profile() as dt:
f, model = inner_func(*args, **kwargs)
LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
return f, model
except Exception as e:
LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
return None, None
return outer_func
@try_export
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript')
ts = torch.jit.trace(model, im, strict=False)
d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
else:
ts.save(str(f), _extra_files=extra_files)
return f, None
@try_export
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx>=1.12.0')
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
if dynamic:
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
if isinstance(model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(model, DetectionModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_simp, check = onnxsim.simplify(f, check=True)
assert check, 'assert check failed'
onnx.save(model_simp, f)
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure ❌ {e}')
return f, None
export.py是一个用于将YOLOv5 PyTorch模型导出为其他格式的程序文件。该文件提供了多种导出格式选项,包括TorchScript、ONNX、OpenVINO、TensorRT、CoreML、TensorFlow SavedModel、TensorFlow GraphDef、TensorFlow Lite、TensorFlow Edge TPU、TensorFlow.js和PaddlePaddle。用户可以根据需要选择要导出的格式,并使用相应的命令行参数运行export.py文件。
export.py文件还提供了一些辅助函数,用于导出模型到不同的格式。例如,export_torchscript函数用于将模型导出为TorchScript格式,export_onnx函数用于将模型导出为ONNX格式。这些函数使用了一些第三方库,如torch和onnx,来实现模型导出的功能。
此外,export.py文件还提供了一些辅助函数,用于检查系统环境和模型要求,以及打印日志信息。这些函数可以帮助用户在导出模型时进行必要的检查和调试。
用户可以使用export.py文件来导出YOLOv5模型到所需的格式,并使用detect.py文件进行推理。推理过程中可以使用导出的模型文件进行目标检测和分类任务。
5.2 train.py
class YOLOv5Trainer:
def __init__(self, hyp, opt, device, callbacks):
self.hyp = hyp
self.opt = opt
self.device = device
self.callbacks = callbacks
def train(self):
# implementation of the train() function
pass
def load_model(self):
# implementation of the load_model() function
pass
def freeze_layers(self):
# implementation of the freeze_layers() function
pass
def create_optimizer(self):
# implementation of the create_optimizer() function
pass
def create_scheduler(self):
# implementation of the create_scheduler() function
pass
def resume_training(self):
# implementation of the resume_training() function
pass
def run(self):
self.callbacks.run('on_pretrain_routine_start')
self.load_model()
self.freeze_layers()
self.create_optimizer()
self.create_scheduler()
self.resume_training()
train.py是一个用于训练YOLOv5模型的程序文件。它可以在自定义数据集上训练YOLOv5模型,并支持单GPU和多GPU分布式训练。
程序中的主要功能包括:
- 解析命令行参数,包括数据集配置文件、模型权重、训练参数等。
- 加载模型和数据集,并进行必要的预处理。
- 设置训练过程中的优化器、学习率调度器等。
- 定义训练函数,包括前向传播、计算损失、反向传播等。
- 进行训练过程,包括迭代训练多个epoch、保存模型权重、计算评估指标等。
- 支持断点续训和模型权重的加载。
这个命令将使用预训练的yolov5s模型,在尺寸为640的图像上训练一个目标检测模型。
5.3 ui.py
class Yolov5v7Detector:
def __init__(self, weights='./best.pt', data=ROOT / 'data/coco128.yaml', device='', half=False, dnn=False):
self.weights = weights
self.data = data
self.device = device
self.half = half
self.dnn = dnn
self.model, self.stride, self.names, self.pt = self.load_model()
def load_model(self):
device = select_device(self.device)
model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, names, pt = model.stride, model.names, model.pt
return model, stride, names, pt
def run(self, img, imgsz=(640, 640), conf_thres=0.25, iou_thres=0.45, max_det=1000, classes=None,
agnostic_nms=False, augment=False, retina_masks=True):
imgsz = check_img_size(imgsz, s=self.stride)
self.model.warmup(imgsz=(1 if self.pt else 1, 3, *imgsz))
cal_detect = []
device = select_device(self.device)
names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
im = letterbox(img, imgsz, self.stride, self.pt)[0]
im = im.transpose((2, 0, 1))[::-1]
im = np.ascontiguousarray(im)
im = torch.from_numpy(im).to(device)
im = im.half() if self.half else im.float()
im /= 255
if len(im.shape) == 3:
im = im[None]
pred, proto = self.model(im, augment=augment)[:2]
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det, nm=32)
for i, det in enumerate(pred):
annotator = Annotator(img, line_width=1, example=str(names))
if len(det):
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], img.shape).round()
masks = process_mask_native(proto[i], det[:, 6:], det[:, :4], img.shape[:2])
segments = [
scale_segments(img.shape if retina_masks else im.shape[2:], x, img.shape, normalize=True)
for x in reversed(masks2segments(masks))]
id_list = []
for id in range(len(det[:, :6])):
class_name = names[int(det[:, :6][id][5])]
if class_name == 'person':
id_list.append(id)
def del_tensor(arr, id_list):
if len(id_list) == 0
这个程序文件是一个基于PyQt5的图形用户界面程序。它的主要功能是使用YOLOv5模型进行目标检测和分割,识别遥感图像中的苔藓区域。
程序的主要结构如下:
- 导入所需的库和模块。
- 定义了一些全局变量和常量。
- 定义了一些函数,包括加载模型、运行模型、目标检测和分割等功能。
- 定义了一个继承自QThread的线程类Thread_1,用于在后台运行目标检测和分割。
- 定义了一个继承自Ui_MainWindow的主窗口类,用于创建图形用户界面。
- 在if name == "main"的条件下,加载模型,创建应用和主窗口对象,并启动应用。
主窗口界面包括一个标题标签、一个显示图像的标签、一个文本浏览器和三个按钮。用户可以通过点击按钮选择对象、进行文件/实时识别和退出系统操作。在文本浏览器中会显示一些提示信息和识别结果。
整个程序的主要功能是通过调用YOLOv5模型对遥感图像中的苔藓区域进行检测和分割,并将结果显示在图像标签中。用户可以通过选择对象按钮选择要识别的图像文件,然后通过文件/实时识别按钮进行识别操作。识别结果会显示在图像标签和文本浏览器中。
需要注意的是,这个程序文件中的代码比较长,包含了很多功能和细节,如果想要深入了解每个部分的具体实现和原理,需要仔细阅读代码和相关文档。
5.4 val.py
class YOLOv5Validator:
def __init__(self, weights, data, batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300,
device='', workers=8, single_cls=False, augment=False, verbose=False, save_txt=False,
save_hybrid=False, save_conf=False, save_json=False, project=ROOT / 'runs/val', name='exp',
exist_ok=False, half=True, dnn=False, model=None, dataloader=None, save_dir=Path(''),
plots=True, callbacks=Callbacks(), compute_loss=None):
self.weights = weights
self.data = data
self.batch_size = batch_size
self.imgsz = imgsz
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.max_det = max_det
self.device = device
self.workers = workers
self.single_cls = single_cls
self.augment = augment
self.verbose = verbose
self.save_txt = save_txt
self.save_hybrid = save_hybrid
self.save_conf = save_conf
self.save_json = save_json
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.dnn = dnn
self.model = model
self.dataloader = dataloader
self.save_dir = save_dir
self.plots = plots
self.callbacks = callbacks
self.compute_loss = compute_loss
def save_one_txt(self, predn, save_conf, shape, file):
# Save one txt result
gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
for *xyxy, conf, cls in predn.tolist():
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(file, 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
def save_one_json(self, predn, jdict, path, class_map):
# Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
image_id = int(path.stem) if path.stem.isnumeric() else path.stem
box = xyxy2xywh(predn[:, :4]) # xywh
box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
for p, b in zip(predn.tolist(), box.tolist()):
jdict.append({
'image_id': image_id,
'category_id': class_map[int(p[5])],
'bbox': [round(x, 3) for x in b],
'score': round(p[4], 5)})
def process_batch(self, detections, labels, iouv):
"""
Return correct prediction matrix
Arguments:
detections (array[N, 6]), x1, y1, x2, y2, conf, class
labels (array[M, 5]), class, x1, y1, x2, y2
Returns:
correct (array[N, 10]), for 10 IoU levels
"""
correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
iou = box_iou(labels[:, 1:], detections[:, :4])
correct_class = labels[:, 0:1] == detections[:, 5]
for i in range(len(iouv)):
x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
correct[matches[:, 1].astype(int), i] = True
return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
def run(self):
# Initialize/load model and set device
training = self.model is not None
if training: # called by train.py
device, pt, jit, engine = next(self.model.parameters()).device, True, False, False # get model device, PyTorch model
self.half &= device.type != 'cpu' # half precision only supported on CUDA
self.model.half() if self.half else self.model.float()
else: # called directly
device = select_device(self.device, batch_size=self.batch_size)
# Directories
self.save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(self.save_dir / 'labels' if self.save_txt else self.save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
self.model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, pt, jit, engine = self.model.stride, self.model.pt, self.model.jit, self.model.engine
self.imgsz = check_img_size(self.imgsz, s=stride) # check image size
self.half = self.model.fp16 #
val.py是一个用于在检测数据集上验证训练好的YOLOv5检测模型的程序文件。它可以根据指定的参数加载模型并在验证集上进行推理。该程序文件还提供了一些可选的功能,如保存结果、计算mAP等。具体功能如下:
- 导入必要的库和模块。
- 定义了一些全局变量和常量。
- 定义了一些辅助函数,如保存结果的函数、处理批次的函数等。
- 定义了主函数run(),用于加载模型、配置参数、创建数据加载器、进行推理等。
- 在主函数中,首先根据参数加载模型并设置设备。
- 然后根据参数配置模型的推理模式和数据加载器。
- 接下来,根据参数进行推理,并计算损失(如果需要)。
- 最后,根据推理结果计算指标(如mAP)并保存结果(如果需要)。
总之,val.py是一个用于在检测数据集上验证YOLOv5模型的程序文件,它提供了一些可选的功能,如保存结果、计算mAP等。
5.5 yolov5-DBB.py
class TransI_FuseBN(nn.Module):
def __init__(self, bn):
super(TransI_FuseBN, self).__init__()
self.bn = bn
def forward(self, kernel):
gamma = self.bn.weight
std = (self.bn.running_var + self.bn.eps).sqrt()
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), self.bn.bias - self.bn.running_mean * gamma / std
class TransII_AddBranch(nn.Module):
def forward(self, kernels, biases):
return sum(kernels), sum(biases)
class TransIII_1x1_kxk(nn.Module):
def __init__(self, groups):
super(TransIII_1x1_kxk, self).__init__()
self.groups = groups
def forward(self, k1, b1, k2, b2):
if self.groups == 1:
k = F.conv2d(k2, k1.permute(1, 0, 2, 3))
b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))
else:
k_slices = []
b_slices = []
k1_T = k1.permute(1, 0, 2, 3)
k1_group_width = k1.size(0) // self.groups
k2_group_width = k2.size(0) // self.groups
for g in range(self.groups):
k1_T_slice = k1_T[:, g*k1_group_width:(g+1)*k1_group_width, :, :]
k2_slice = k2[g*k2_group_width:(g+1)*k2_group_width, :, :, :]
k_slices.append(F.conv2d(k2_slice, k1_T_slice))
b_slices.append((k2_slice * b1[g*k1_group_width:(g+1)*k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))
k, b_hat = transIV_depthconcat(k_slices, b_slices)
return k, b_hat + b2
class TransIV_DepthConcat(nn.Module):
def forward(self, kernels, biases):
return torch.cat(kernels, dim
该程序文件名为yolov5-DBB.py,是一个使用PyTorch实现的深度学习模型文件。该文件包含了一些函数和类的定义,用于构建深度学习模型。
其中定义了一些辅助函数,如transI_fusebn、transII_addbranch、transIII_1x1_kxk等,用于对卷积核和偏置进行转换和操作。
还定义了一些模型组件,如conv_bn、IdentityBasedConv1x1、BNAndPadLayer、DiverseBranchBlock、Bottleneck_DBB和C3_DBB等,用于构建深度学习模型的不同部分。
最后,还定义了一些模型的前向传播函数,如forward和init_gamma等,用于模型的训练和推理过程。
总体来说,该程序文件是一个用于构建深度学习模型的工具文件,提供了一些函数和类的定义,方便用户构建自己的模型。
5.6 classify\predict.py
class YOLOv5Classifier:
def __init__(self, weights, source, data, imgsz, device, view_img, save_txt, nosave, augment, visualize, update,
project, name, exist_ok, half, dnn, vid_stride):
self.weights = weights
self.source = source
self.data = data
self.imgsz = imgsz
self.device = device
self.view_img = view_img
self.save_txt = save_txt
self.nosave = nosave
self.augment = augment
self.visualize = visualize
self.update = update
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.dnn = dnn
self.vid_stride = vid_stride
def run(self):
source = str(self.source)
save_img = not self.nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(save_dir / 'labels' if self.save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(self.device)
model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(self.imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]),
vid_stride=self.vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]),
vid_stride=self.vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.Tensor(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
results = model(im)
# Post-process
with dt[2]:
pred = F.softmax(results, dim=1) # probabilities
# Process predictions
for i, prob in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
annotator = Annotator(im0, example=str(names), pil=True)
# Print results
top5i = prob.argsort(0, descending=True)[:5].tolist() # top 5 indices
s += f"{', '.join(f'{names[j]} {prob[j]:.2f}' for j in top5i)}, "
# Write results
text = '\n'.join(f'{prob[j]:.2f} {names[j]
这个程序文件是一个用于YOLOv5分类推理的Python脚本。它可以在图像、视频、目录、URL、摄像头等多种数据源上运行分类推理。
程序的主要功能包括:
- 加载模型和数据
- 运行推理
- 后处理和结果保存
- 可视化和显示结果
程序使用了YOLOv5模型和相关的工具函数和类。它可以接受命令行参数来指定模型路径、数据源、推理尺寸、设备等。程序还提供了一些可选的功能,如结果保存、结果可视化、模型更新等。
程序的主要逻辑是循环处理数据源中的每个图像或视频帧,将其输入模型进行推理,然后对推理结果进行后处理和保存。最后,程序会打印出推理速度和保存结果的路径。
该程序是一个命令行工具,可以通过命令行参数来指定不同的配置和数据源,以实现不同的分类推理任务。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于重参数结构DiverseBranchBlock改进YOLO的遥感苔藓分割系统。它包含了多个程序文件,用于实现目标检测、分类和分割任务。其中,YOLOv5模型是核心模型,通过训练和推理实现目标检测和分类功能。此外,还有一些辅助文件用于数据加载、模型导出、模型评估等功能。
下表整理了每个文件的功能:
| 文件路径 | 功能 |
|---|---|
| export.py | 将YOLOv5模型导出为其他格式的工具文件 |
| train.py | 训练YOLOv5模型的程序文件 |
| ui.py | 基于PyQt5的图形用户界面程序文件 |
| val.py | 在检测数据集上验证训练好的YOLOv5模型的程序文件 |
| yolov5-DBB.py | 使用PyTorch实现的深度学习模型文件 |
| classify/predict.py | 运行YOLOv5分类推理的Python脚本 |
| classify/train.py | 训练YOLOv5分类模型的程序文件 |
| classify/val.py | 在验证集上验证训练好的YOLOv5分类模型的程序文件 |
| models/common.py | 包含一些通用的模型组件和辅助函数 |
| models/experimental.py | 包含一些实验性的模型组件和辅助函数 |
| models/tf.py | 包含一些与TensorFlow相关的模型组件和辅助函数 |
| models/yolo.py | 包含YOLOv5模型的定义和相关函数 |
| models/init.py | 模型模块的初始化文件 |
| segment/predict.py | 运行YOLOv5分割推理的Python脚本 |
| segment/train.py | 训练YOLOv5分割模型的程序文件 |
| segment/val.py | 在验证集上验证训练好的YOLOv5分割模型的程序文件 |
| utils/activations.py | 包含一些激活函数的定义和实现 |
| utils/augmentations.py | 包含一些数据增强的函数和类 |
| utils/autoanchor.py | 包含自动锚框生成的函数和类 |
| utils/autobatch.py | 包含自动批次大小调整的函数和类 |
| utils/callbacks.py | 包含一些回调函数的定义和实现 |
| utils/dataloaders.py | 包含数据加载器的定义和实现 |
| utils/downloads.py | 包含一些下载和解压缩的函数和类 |
| utils/general.py | 包含一些通用的辅助函数和类 |
| utils/loss.py | 包含一些损失函数的定义和实现 |
| utils/metrics.py | 包含一些评估指标的定义和实现 |
| utils/plots.py | 包含一些绘图函数的定义和实现 |
| utils/torch_utils.py | 包含一些与PyTorch相关的辅助函数和类 |
| utils/triton.py | 包含与Triton Inference Server相关的辅助函数和类 |
| utils/init.py | 工具模块的初始化文件 |
| utils/aws/resume.py | 包含AWS训练恢复的函数和类 |
| utils/aws/init.py | AWS模块的初始化文件 |
| utils/flask_rest_api/example_request.py | 包含Flask REST API示例请求的函数和类 |
| utils/flask_rest_api/restapi.py | 包含Flask REST API的实现 |
| utils/loggers/init.py | 日志记录器模块的初始化文件 |
| utils/loggers/clearml/clearml_utils.py | 包含与ClearML日志记录器相关的辅助函数和类 |
| utils/loggers/clearml/hpo.py | 包含与ClearML超参数优化相关的辅助函数和类 |
| utils/loggers/clearml/init.py | ClearML日志记录器模块的初始化文件 |
| utils/loggers/comet/comet_utils.py | 包含与Comet日志记录器相关的辅助函数和类 |
| utils/loggers/comet/hpo.py | 包含与Comet超参数优化相关的辅助函数和类 |
| utils/loggers/comet/init.py | Comet日志记录器模块的初始化文件 |
| utils/loggers/wandb/log_dataset.py | 包含与Weights & Biases日志记录器相关的辅助函数和类 |
7.DBB简介
该博客参考ACNet的又一次对网络结构重参数化的探索,设计了一个类似Inception的模块,以多分支的结构丰富卷积块的特征空间,各分支结构包括平均池化,多尺度卷积等。最后在推理阶段前,把多分支结构中进行重参数化,融合成一个主分支。这样能在相同的推理速度下,“白嫖”模型性能
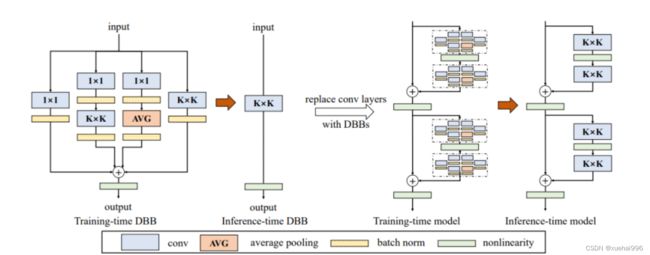
DBB结构转换
卷积的性质
常规卷积核本质上也是一个张量,其形状为(输出通道数,输入通道数,卷积核大小,卷积核大小)
而卷积操作本质上也是一个线性操作,因此卷积在某些情况下具备一些线性的性质
可加性
可加性即在两个卷积核形状一致的情况下,卷积结果满足可加性 即其中 和 分别表示两个独立的卷积操作
同质性
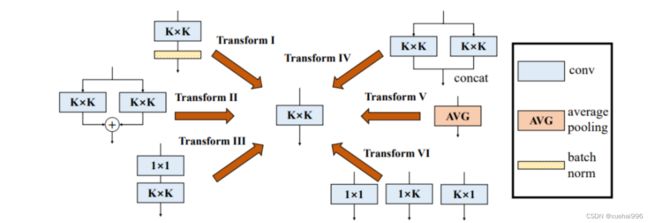
即后续我们针对多分支结构的转换都是基于这两种基本性质来操作的论文提及的6种转换

序列卷积融合
在网络设计中,我们也会用到1x1卷积接3x3卷积这种设计(如ResNet的BottleNeck块),它能调整通道数,减少一定的参数量。
其原始公式如下
我们假设输入是一个三通道的图片,1x1卷积的输出通道为2,3x3卷积的输出通道为4,那么图示如下
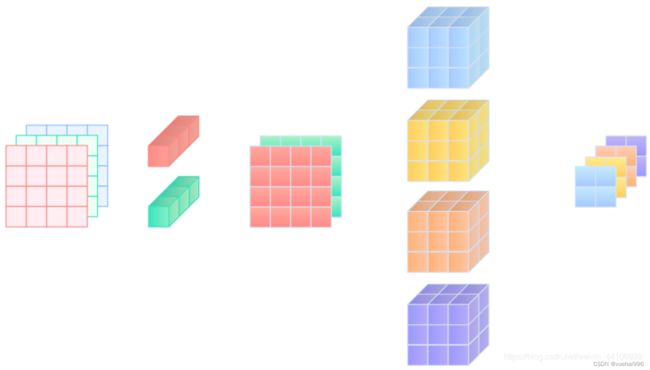
1x1接3x3
作者提出了这么一个转换方法,首先将1x1卷积核的第零维和第一维互相调换位置
然后3x3卷积核权重与转置后的"1x1卷积核"进行卷积操作

1x1和KxK卷积转换
最后输入与其做卷积操作,整个流程可以写为
拼接融合
在Inception模块中,我们经常会用到的一个操作就是concat,将各分支的特征,在通道维上进行拼接。
我们也可以将多个卷积拼接转换为一个卷积操作,只需要将多个卷积核权重在输出通道维度上进行拼接即可,下面是一个示例代码
平均池化层转换
我们简单回顾一下平均池化层操作,它也是一个滑动窗口,对特征图进行滑动,将窗口内的元素求出均值。与卷积层不一样的是,池化层是针对各个输入通道的(如Depthwise卷积),而卷积层会将所有输入通道的结果相加。一个平均池化层的示意图如下:
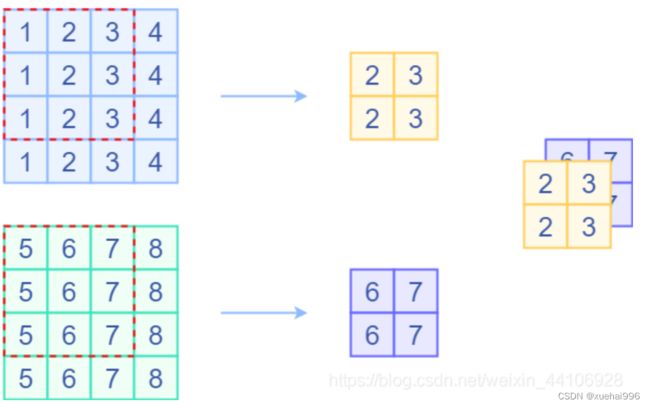
平均池化层
那其实平均池化层是可以等价一个固定权重的卷积层,假设平均池化层窗口大小为3x3,那么我可以设置3x3卷积层权重为 1/9,滑动过去就是取平均。另外要注意的是卷积层会将所有输入通道结果相加,所以我们需要对当前输入通道设置固定的权重,对其他通道权重设置为0。
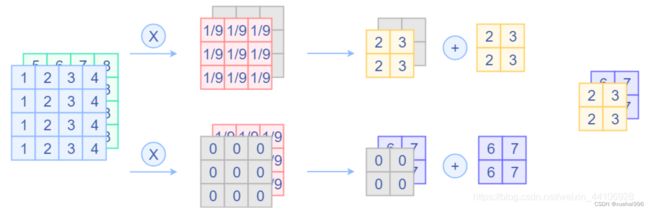
卷积层替换平均池化层
另外补充一下,由于最大池化层是一个非线性的操作,所以是不能用卷积层替换的 下面是测试代码:
多尺度卷积融合
这部分其实就是ACNet的思想,存在一个卷积核
那么我们可以把卷积核周围补0,来等效替代KxK卷积核 下面是一个示意图

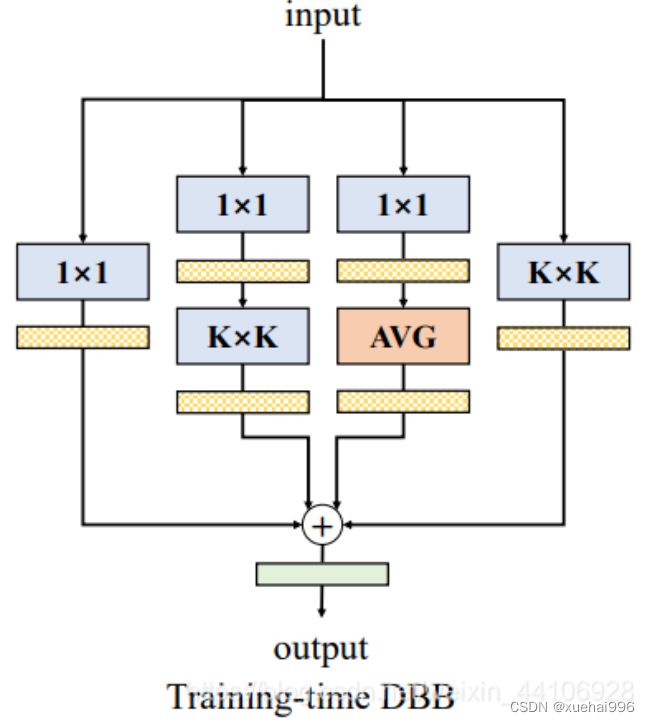
DBB结构
其中一共有四个分支,分别是
1x1 卷积分支
1x1 - KxK卷积分支
1x1 - 平均池化分支
KxK 卷积分支 启发于Inception模块,各操作有不同的感受野以及计算复杂度,能够极大丰富整个模块的特征空间
因为最后都可以等价转换为一个KxK卷积,作者后续实验就是将这个Block替换到骨干网络中的KxK卷积部分。
8.多尺度分割
多尺度分割的概念
多尺度的分析方法对不同尺度的图像信息进行综合,将相对较大的尺度和相对较小的尺度这对矛盾体统一起来。多尺度的分析方法非常适用于图像分割中自动、半自动的研究,很多事物都具有多尺度的特性,所以,从多尺度、多特征去对某种现象或者过程进行描述才会更加准确全面的提现事物的本质特征,全面的获取分割目标的纹理信息会很大程度的提高分割的准确率。
在高分辨率遥感图像中涵盖多种地物,线形地物包括河流和道路等,面状地物包括植被、建筑、耕地等,它们之间不仅存在光谱差异,而且各种地物的分布方式、大小、形状、纹理特征都呈现出明显的区别。因此当进行图像分割时,如果设置一个相同的尺度来分割多种不同的地物,并不能满足各种地物分割的需求。如果用相同的尺度分割乔木和灌木,一种情况可能是乔木分割相对精确,但是灌木的分割效果受到影响,另一种情况是灌木分割效果良好,但其中涵盖了部分乔木的信息。从中可以看出如果尺度选择不恰当,会对目标信息的提取精度产生很大的影响。所以分层次多尺度的分割方法具有很大的优势,它可以针对不同地物的特点选择合适的纹理尺度,以便于图像的进一步分割。
多尺度的分割方法是从地表地物的多层次和多格局的特征出发进行考虑的,对地表地物建立不同的分割尺度等级,获得每个尺度上的地物信息,全面的考虑每种地物的尺度信息。图建立了与地表实际地物相对应的数据对象层,最下面的一层是原始图像,接着创建其它层次,使得每一类地物对应一个对象层,要提取每类地物的时候找到相对应的对象层提取对应的目标信息,对其它目标的分割提取不产生影响。

9.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

参考博客《基于重参数结构DiverseBranchBlock改进YOLO的遥感苔藓分割系统》
10.参考文献
[1]周志强,汪渤,李立广,等.基于双边与高斯滤波混合分解的图像融合方法[J].系统工程与电子技术.2016,(1).DOI:10.3969/j.issn.1001-506X.2016.01.02 .
[2]黄煌,肖鹏峰,王结臣.多尺度归一化割用于遥感图像分割[J].遥感信息.2015,(5).DOI:10.3969/j.issn.1000-3177.2015.05.003 .
[3]陈杰,陈铁桥,刘慧敏,等.高分辨率遥感影像耕地分层提取方法[J].农业工程学报.2015,(3).DOI:10.3969/j.issn.1002-6819.2015.03.025 .
[4]姒绍辉,胡伏原,张伟,等.一种改进的双边滤波图像去噪算法[J].计算机工程与应用.2015,(2).DOI:10.3778/j.issn.1002-8331.1303-0275 .
[5]刘小丹,杨燊.基于蓝噪声理论的遥感图像森林植被纹理测量[J].国土资源遥感.2015,(2).DOI:10.6046/gtzyyg.2015.02.10 .
[6]马浩然,赵天忠,曾怡.面向对象的最优分割尺度下多层次森林植被分类[J].东北林业大学学报.2014,(9).DOI:10.3969/j.issn.1000-5382.2014.09.012 .
[7]杨勇,郭玲,王天江.基于多尺度结构张量的多类无监督彩色纹理图像分割方法[J].计算机辅助设计与图形学学报.2014,(5).
[8]刘兆祎,李鑫慧,沈润平,等.高分辨率遥感图像分割的最优尺度选择[J].计算机工程与应用.2014,(6).DOI:10.3778/j.issn.1002-8331.1206-0094 .
[9]周雨薇,陈强,孙权森,等.结合暗通道原理和双边滤波的遥感图像增强[J].中国图象图形学报.2014,(2).DOI:10.11834/jig.20140218 .
[10]李珊,覃锡忠,贾振红,等.高分影像在改进的最优分割尺度下的多层次混合分类[J].激光杂志.2013,(5).DOI:10.3969/j.issn.0253-2743.2013.05.009 .