Python爬虫处理\xa0、\u3000、\u2002、\u2003等空格
Python爬虫处理\xa0、\u3000、\u2002、\u2003等空格
-
- 导读
- 空格类型
- 普通半角空格
- 普通全角空格(\u3000)
- html实体不间断空格(\xa0)
- html实体半角空格(\u2002)
- html实体全角空格(\u2003)
- 统一处理方式
导读
在爬取网页时,对网页数据清洗时常会遇到空格,有的网页空格类型还不止一种,如果不能正确处理,可能无法提取到需要的数据。这里记录下自己使用正则处理各种类型空格的经历。
空格类型
这里把空格格式分两类,一类这里表述为普通文本空格,另一类表述为html实体空格。普通文本空格介绍普通半角空格和普通全角空格。html实体空格介绍三种,分别为html实体不间断空格( )、html实体半角空格( )和html实体全角空格( )。
- 普通半角空格:英文空格键。这是最常见的空格,如我们写代码时,按下空格键产生的就是这种空格键。正则里直接使用空格或者\s就能匹配,在python中对应的unicode码为\u0020;
- 普通全角空格:中文空格键。中文网页上常会出现,直接使用正则的\s匹配不到,unicode码为\u3000;
- html实体不间断空格:html中的常用空格,出现在html中为 。网页上看不到,打开浏览器开发工具可以看到,unicode码为\u00A0,对应的十六进制为\xa0;
- html实体半角空格:&ensp,unicode码为\u2002;
- html实体全角空格:&emsp,unicode码为\u2003;
普通半角空格
这种空格不需要特殊处理,使用正则匹配,可以直接使用空格或者\s。为了以下铺垫,这里也举个用unicode码匹配该类型空格的例子,代码如下所示
s = 'hello word, hi python'
print re.findall(r'i py', s) # 直接用空格
print re.findall(r'i\spy', s) # 用\s
print re.findall(ur'i\u0020py', s) # 用unicode码
执行结果如下

普通全角空格(\u3000)
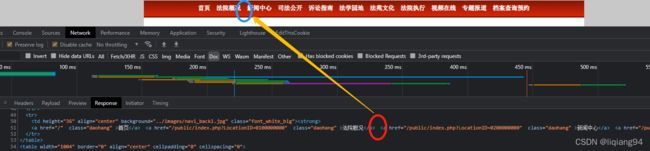
该链接导航栏各栏目之间有空格(这个就是\u3000类型的,但是直接看不出来,代码抓取下来可以看到),如下图所示
以下使用代码获取该段文本,并使用正则提取
import re
from requests import get
from lxml import etree
url = 'http://hebng.hljcourt.gov.cn/public/detail.php?id=1818'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0'}
resp = get(url, headers=headers)
html = resp.content.decode('gbk')
et = etree.HTML(html)
text_list = et.xpath('/html/body/table[3]/tr[2]//text()')
text = et.xpath('string(/html/body/table[3]/tr[2])')
print '=' * 50
print re.findall(ur'法院概况 新闻中心', text) # 匹配不到
print re.findall(ur'法院概况\s新闻中心', text) # 匹配不到
print re.findall(ur'法院概况\u3000新闻中心', text) # 这样才可以匹配到
print '=' * 50
执行结果如下

从以上图片可以看到该网页导航栏各栏目之间的空格就是这种\u3000这种空格,这种类型空格要匹配的话需要在正则表达式中使用unicode码。
html实体不间断空格(\xa0)
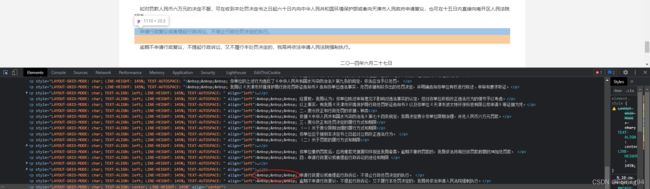
该链接正文之间有很多不间断空格,打开开发者工具可以直接看到
以下使用代码获取该段文本,并使用正则提取
import re
from requests import get
from lxml import etree
url = 'http://sthj.tj.gov.cn/ZWGK4828/ZFXXGK8438/FDZDGK27/XZCFQZXZCFXX7581/202010/t20201020_3958760.html'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0'}
resp = get(url, headers=headers)
html = resp.content.decode('utf-8')
et = etree.HTML(html)
text_list = et.xpath('//*[@id="zoom"]/p[30]/text()')
text = et.xpath('string(//*[@id="zoom"]/p[30])') # 注意申请行政复议前面有四个空格,其中三个不间断空格,一个普通半角空格
print '=' * 200
print re.findall(ur'\s\s申请行政复议', text) # 普通半角接普通半角匹配不到
print re.findall(ur'\xa0\s申请行政复议', text) # 不间断空格接普通半角空格可以匹配到
print re.findall(ur'\u00A0\s申请行政复议', text) # 不间断空格接普通半角空格可以匹配到
print '=' * 200
执行结果如下
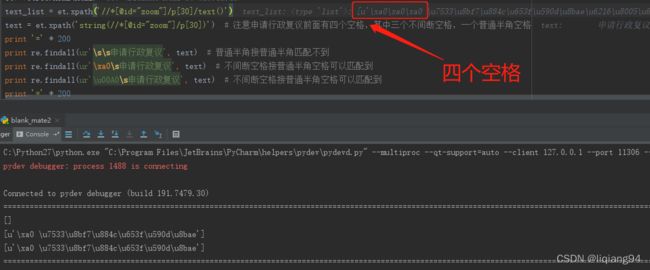
从以上图片结果可以看出,使用正则匹配非间断空格时,需要使用unicode码\u00A0或者十六进制\xa0。
html实体半角空格(\u2002)
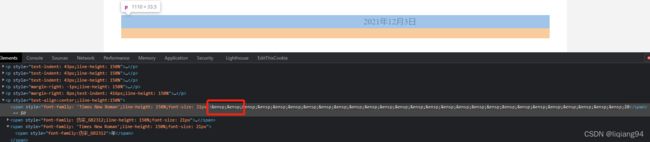
该链接正文末尾的日期前面有很多**&ensp**这种空格,打开开发者工具可以直接看到
以下使用代码获取该段文本,并使用正则提取
import re
from requests import get
from lxml import etree
url = 'http://sthj.tj.gov.cn/ZWGK4828/ZFXXGK8438/FDZDGK27/XZCFQZXZCFXX7581/202112/t20211207_5743296.html'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0'}
resp = get(url, headers=headers)
html = resp.content.decode('utf-8')
et = etree.HTML(html)
text_list = et.xpath('//*[@id="zoom"]/div/p[38]/span[1]/text()')
text = et.xpath('string(//*[@id="zoom"]/div/p[38]/span[1])')
print '=' * 200
print re.findall(ur'\s20', text) # 普通半角匹配不到
print re.findall(ur'\u200220', text) # unicode码\u2002可以匹配到
print '=' * 200
执行结果如下
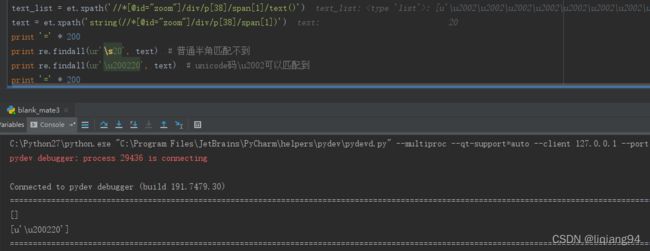
从以上图片结果可以看出,使用正则匹配html实体半角空格时,需要使用unicode码\u2002。
html实体全角空格(\u2003)
该链接正文表格表头有一列中有该类型空格, ,如下图所示

以下使用代码获取该段文本,并使用正则提取
import re
from requests import get
from lxml import etree
url = 'http://hebng.hljcourt.gov.cn/public/detail.php?id=1818'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:79.0) Gecko/20100101 Firefox/79.0'}
resp = get(url, headers=headers)
html = resp.content.decode('gbk')
et = etree.HTML(html)
text_list = et.xpath('//table[@class="ke-zeroborder"]/tbody/tr[1]/td[1]/text()')
text = et.xpath('string(table[@class="ke-zeroborder"]/tbody/tr[1]/td[1])')
print '=' * 200
print re.findall(ur'\t\s\r', text_list[0]) # 普通半角匹配不到
print re.findall(ur'\t\u2003\r', text_list[0], flags=re.S) # unicode码\u2003可以匹配到
print '=' * 200
执行结果如下

从以上结果看出,使用正则匹配html实体半角空格时,需要使用unicode码\u2003。
统一处理方式
从以上几个例子可以看出,网页上的空格类型要想处理好,是要兼顾几种情况的,其实爬虫主要遇到的就是\xa0、\u3000这两种。可以使用统一正则匹配,如下测试代码
import re
s = u'\u2002\u2003\xa0\u3000Say'
print len(s)
print s
print re.findall(r'\s{4}Say', s) # 普通空格匹配不到
print re.findall(ur'[\u2002\u2003\xa0\u3000]{4}Say', s) # 使用unicode码可以匹配到
print re.findall(r'\s{4}Say', s, flags=re.U) # 使用re.U模式可以匹配到
代码执行结果如下
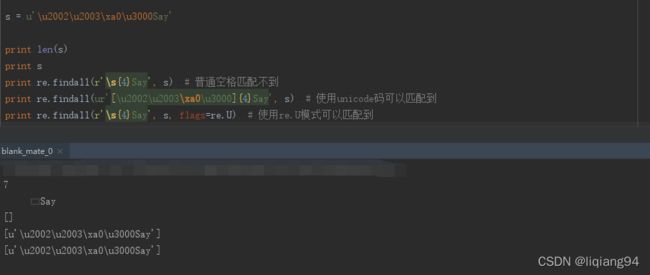
注意看以上结果,这里的s是unicode字符串,共7个字符,其中四个不同类型的空格,使用对应的unicode码可以匹配到这些空格。
要注意下当正则模式的编译标志位(flags)为re.U时,使用正则符号\s是可以匹配到各种类型的空格的。
最后安利一个查unicode字符的网站unicode-table,可以在html实体这里看到有许多html中不同类型的空格。