python爬虫-GUI界面音乐下载器
首先整个结构分为爬虫代码和图形代码,两者结合就是完整的程序:
后面需要引入的包:
from tkinter import filedialog,scrolledtext,messagebox
from tkinter import *
import requests,json
爬虫部分:
这儿也是最难的,因为要找到真实链接地址,需要在很多的接口中去找,然后通过数据清洗找到需要的url,提取出来。这是整个代码中的精华,后期下载都是从这儿获取音乐的真实URL地址进行下载。
进入音乐官网搜索界面,打开F12开发者界面,可以看到搜索到的所有结果全部在这个接口里面
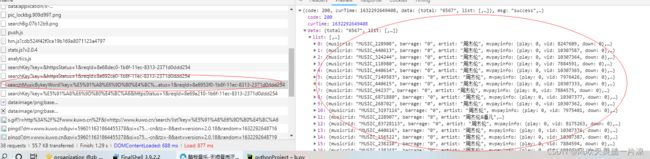
爬虫代码里面运用request请求,请求这个接口,拿到你搜索到的所有数据,这儿还有一个请求参数,在headers里面查看,可以发现你要搜索的歌曲或者歌手都是请求参数发出去的
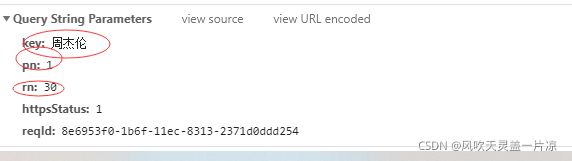
写好整个请求参数后,就是对拿到的数据进一步处理
因为要找到歌曲的真实URL地址,花了我好多时间,不多说,直接上干货,因为这个请求时直接返回了音乐的真实url地址,而这个请求地址中唯一的变量就是rid后面的那串id,回到刚刚搜索拿到的所有数据,在里面刚好有rid,正好拿来用

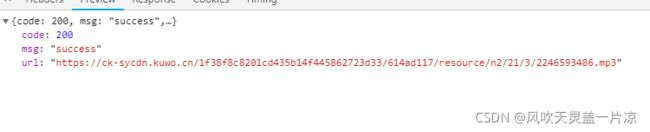

爬取的原理就是上面我说的那样,看起来页很简单,就是找这些数据要花点时间,不多说,直接上代码:
class Downloadmusic(object):
Music_list = []
Music_total = []
def __init__(self):
self.url = "http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36 Edg/84.0.522.63",
"Cookie": "_ga=GA1.2.1083049585.1590317697; _gid=GA1.2.2053211683.1598526974; _gat=1; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1597491567,1598094297,1598096480,1598526974; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1598526974; kw_token=HYZQI4KPK3P",
"Referer": "http://www.kuwo.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6",
"csrf": "HYZQI4KPK3P"
}
self.args = {
"key": UI.Music_se[0],
"pn": UI.Page_num[-1], # 第几页
"rn": "30",
"httpsStatus": "1",
"reqId": "cc337fa0-e856-11ea-8e2d-ab61b365fb50",
}
self.music_api = "http://www.kuwo.cn/url?format=mp3&rid={}&response=url&type=convert_url3" \
"&br=128kmp3&from=web&t=1598528574799&httpsStatus=1" \
"&reqId=72259df1-e85a-11ea-a367-b5a64c5660e5"
# 获取歌曲信息
def url_data(self):
global number
number = 1
self.Music_list.clear()
self.Music_total.clear()
re = requests.get(url=self.url,headers=self.headers,params=self.args)
re.encoding = "utf-8"
Data = json.loads(re.text)['data']['list']
music_datas = json.loads(re.text)['data']['total']
self.Music_total.append(music_datas)
for i in Data:
try:
rid = str(i['rid'])
music_name = str(i['name'])
music_actor = str(i['artist'])
music_api = self.music_api.format(rid)
music_url = requests.get(url=music_api)
Music_url = json.loads(music_url.text)['url']
self.Music_list.append(Music_url + "$" + music_name)
music_mess.insert(END, " " + str(number) + ". " + music_name + 3 * " " + music_actor + "\n")
music_mess.update()
number += 1
except:
music_mess.insert(END," 该歌曲请求地址失败!!!" + "\n")
上方代码页很简单,就是一个请求拿到数据后,对数据进行一个处理,因为返回的是一个元组,所以需要把它转化一下,转换成json格式,这样好处理一点,然后通过循环把需要到的元素提取出来,真实的url地址也在这一步直接处理了,然后返回到一个列表中,要用到时直接从列表中取,精华部分说完了,那么该说下载了。
因为后面gui界面的操作原因,所以我把下载分为两种方式:
def download_all(self):
if UI.Folderpath == []:
UI().alert()
else:
for i in self.Music_list:
path="%s/%s.mp3" % (UI.Folderpath[0],i.split("$")[1])
mess=requests.get(i.split("$")[0])
with open(path,'wb') as f:
f.write(mess.content)
mess_output.insert(END,i.split("$")[1] + 5*" " + "已下载成功!" + "\n")
mess_output.update()
# 单曲下载
def download_single(self):
if UI.Folderpath == []:
UI().alert()
else:
if UI.Music_num[0] == '':
mess_output.insert(0.0, " 请输入歌曲前面的正确序号!!!" + "\n")
else:
if int(UI.Music_num[0]) < 1 or int(UI.Music_num[0]) > number-1:
mess_output.insert(0.0, " 请输入歌曲前面的正确序号!!!" + "\n")
else:
if 1 <= int(UI.Music_num[0]) <= number:
music = self.Music_list[int(UI.Music_num[0]) - 1].split("$")
path = "%s/%s.mp3" % (UI.Folderpath[0], music[1])
mess = requests.get(music[0])
with open(path, 'wb') as f:
f.write(mess.content)
mess_output.insert(END, " " + music[1] + 5 * " " + "已下载成功!" + "\n")
else:
pass
一个全部下载,一个单曲下载,下载页很简单,就是里面有很多的判断,没有这些判断的话后面的程序的bug有点多,这些就省略了,自己去看
接下来就是GUI部分、因为我也是才接触这个,也不是很了解,只能说一知半解,我也是在网上搜教程慢慢写的。不多说,写这个GUI用的是tkinter,这个是Python中一个GUI图形界面库,目前来说他是Python当中用的最多的图形操作界面。
为了方便管理代码块。所以这个也进行了封装
class UI(object):
Music_se = []
Folderpath = []
Music_num = []
Page_num = []
def __init__(self):
pass
def main(self):
global root
root = Tk()
self.args()
self.lable()
self.text()
self.button()
root.mainloop()
上面的这些创建的列表都是为了给爬取部分传递参数用的
可以看到,主要功能块分为 程序窗口参数设置、界面标签、文本输出框以及按钮控件,一个简单的程序主窗口就这样搭建起来了
下方是整个界面的详细参数:
def args(self):
root.title("music download")
root.geometry("1200x700+350+200")
root.resizable(width="False", height="False")
root.configure(bg="#faebd7")
def lable(self):
lab1=Label(root, text="请先选择保存路径后再下载!!!", font=("宋体", 15), bg="#faebd7", fg="red")
lab1.place(x="500", y="5")
lab2=Label(root, text="请输入歌曲前方序号:", font=("宋体", 12), bg="#faebd7", fg="blue")
lab2.place(x="480", y="105")
def text(self):
global mess_output,music_mess,search,music_num,page_num_show
music_mess=scrolledtext.ScrolledText(root, font=("宋体", 15),relief=FLAT, fg="green")
music_mess.place(height="500", width="450", x="100",y="150")
mess_output=scrolledtext.ScrolledText(root, font=("宋体", 15), relief=FLAT, fg="green")
mess_output.place(height="500", width="450", x="650", y="150")
search=Entry(root,font=("宋体",15), relief=FLAT, fg="green")
search.place(height="30", width="300", x="400", y="50")
music_num=Entry(root,font=("宋体", 15), relief=FLAT, fg="green")
music_num.place(height="30", width="60", x="640", y="100")
page_num_show=Entry(root,font=("宋体", 15), relief=FLAT, fg="black", bg="#faebd7")
page_num_show.place(height="30", width="50", x="845", y="100")
def button(self):
search = Button(root, text="搜索", bg="orchid", comman=lambda: (self.get_music(), Downloadmusic().url_data()))
search.place(height="30", width="40", x="710", y="50")
choose_path = Button(root, text="保存路径", bg="orchid", comman=self.path)
choose_path.place(height="30", width="60", x="760", y="50")
download_all = Button(root, text="全部下载", bg="orchid", comman=lambda: Downloadmusic().download_all())
download_all.place(height="30", width="60", x="830", y="50")
download_singe = Button(root, text="单曲下载", bg="orchid", comman=lambda: (self.get_num(), Downloadmusic().download_single()))
download_singe.place(height="30", width="60",x="710",y="100")
last_page = Button(root, text="上一页", bg="orchid", comman=self.last_page)
last_page.place(height="30", width="60", x="780", y="100")
next_page = Button(root, text="下一页", bg="orchid", comman=self.next_page)
next_page.place(height="30", width="60", x="900", y="100")
delete_mess=Button(root, text="清除信息", bg="orchid", comman=self.delete_message)
delete_mess.place(height="30", width="60", x="900", y="50")
# 获取搜索的音乐
def get_music(self):
Music = search.get()
self.Music_se.clear()
self.Music_se.append(Music)
self.Page_num.append(1)
music_mess.delete(0.0, END)
page_num_show.delete(0, END)
page_num_show.insert(0, str(1) + "页")
# 获取输入的歌曲序号
def get_num(self):
MUSIC_NUM = music_num.get()
self.Music_num.clear()
self.Music_num.append(MUSIC_NUM)
# 保存路径
def path(self):
folderpath = filedialog.askdirectory()
self.Folderpath.clear()
self.Folderpath.append(folderpath)
mess_output.insert(0.0, " 音乐已保存在: " + folderpath + "\n")
# 提示框
def alert(self):
messagebox.showinfo(title="提示",message="请选择保存路径后在下载!!!")
self.path()
# 清除信息
def delete_message(self):
mess_output.delete(0.0,END)
# 下一页
def next_page(self):
if int(self.Page_num[-1]) <= int(Downloadmusic.Music_total[0]):
self.Page_num.append(self.Page_num[-1] + 1)
music_mess.delete(0.0, END)
page_num_show.delete(0,END)
page_num_show.insert(0, str(self.Page_num[-1]) + "页")
Downloadmusic().url_data()
else:
pass
# 上一页
def last_page(self):
if self.Page_num[-1] > 1:
self.Page_num.append(self.Page_num[-1] - 1)
music_mess.delete(0.0,END)
page_num_show.delete(0,END)
page_num_show.insert(0, str(self.Page_num[-1]) + "页")
Downloadmusic().url_data()
else:
pass
if __name__ == "__main__":
UI().main()
界面很简单,但是实际写出来还是有点小难度,七中涉及到运行逻辑,稍微不对就报错,光调试就用了一天,实在有点费脑,最烦的就是位置的一个调整,各种控件到底该在什么地方,多大合适,为了界面美化,可花费了一番功夫,还好做的不是很丑(个人觉得哈),如果大家认为丑那就没法了,个人审美也就这样。
下面是我的成品:

关于UI界面我也没啥可说的,因为我也是半懂状态,实在不会去网上搜tkinter相关的知识自己去了解哈
注:本文章旨在指导爬虫的分析以及编写代码过程,且该文章发表日期较为久远,原网站数据结构已经发生变动,爬取数据可能存在问题,所以直接拿来使用有问题,待作者有时间再来更新整个爬虫代码,敬请期待。。。。。