Redis集群:分布式的less is more
Redis完全就是《数据密集型应用系统设计》的简单实现,主打一个**大道至简**。推荐配合这本书(或者15-445+6.824)一起看[1]。
本文就从分布式视角来介绍下Redis集群模式,顺便看看一些经典的分布式问题在redis下如何解决。
**这篇文章主要提供一个high level的视角,也就是聚焦于所有分布式系统都会有的一些问题,而不仅限于Redis,阅读时可以多带入自己熟悉的系统的视角。**比如mysql,bin-log/redo-log/undo-log/2PC解决的问题在本文中分别就对应了:复制(或者恢复)/故障恢复/事务隔离性/事务原子性[3]。
[1] 《数据密集型应用系统设计》第一三章不推荐阅读,第二章也是各种旁征博引,有的地方写的很含糊,所以本文会优先采用《分布式数据库 30 讲》的解释,想了解工业界和学术界的真实情况,请参阅相关英文文献。想学习OLAP的推荐15721,本文主要是OLTP方面,跟15445和6.824重叠内容比较多。
[2] 除此外mysql还提供 错误日志(errorlog)慢查询日志(slow query log)一般查询日志(general log)以及中继日志(relay log)
最重要的…
redis是一个ap系统_[3]__。_
无论是主从、哨兵还是集群,都没有提供操作的弱一致性保障(虽然C指的是强一致)。
虽然哨兵和集群的选主使用了raft的投票选举方式,但是redis并没有raft的多主复制能力。
Redis的操作的弱一致性问题将在后文讨论,如果想要redis提供强一致性,请使用redis raft。
弱一致性是一种很强的保障,非必要不要要求业务系统的弱一致性。这里主要的麻烦在于持久性(非易失存储系统)的保障。后文会提到这一点。
复制/状态的一致性、分区的一致性、操作的一致性、事务的一致性是不一样的,本文将讨论这几个一致性在Redis中的情况。
[3] CAP不是一个好的概念,因为它不包含关于故障转移、网络延迟的概念,而且网络分区是一个必选项,而只能从强一致和可用性之间权衡。所以对于系统设计并没有太多实际价值。这里主要强调的是Redis的设计理念:不保障一致性。一致性和可用性的关系如下图所示(我将在后文中逐个分析):

[4] 上图出自https://jepsen.io/consistency?spm=ata.21736010.0.0.6dd36d82uyQCCy 其理论出自http://www.vldb.org/pvldb/vol7/p181-bailis.pdf
[5] 上图中,客户端操作始终是全序视角(每个操作都可以比较先后顺序),到达服务端的操作也是全序的
[6] 阅读本文,思考以下三个问题:
- 分布式系统各种复制模式优劣以及复制一致性和状态一致性的关系,为什么默认的Redis集群方案无法达到弱一致性?
- 上图(通用的一致性模型)各个级别的一致性和可用性的关系,它们为什么是这样的关系?
- MV-OCC和MV-2PL的关键不同是什么?
Redis复制
复制是一个重要的topic,它会决定分布式系统持久化的能力和状态一致性。
弱一致性也必须有复制数据不能丢失的保障。
主从模式
redis使用主从的经典设计:
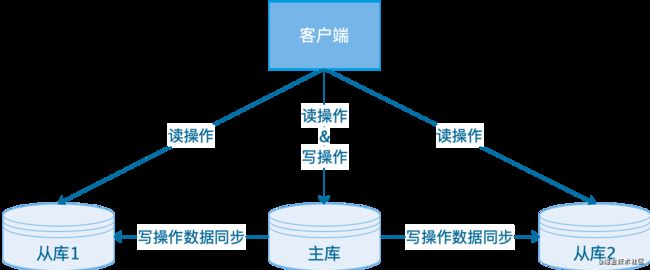
- 读操作:主库、从库都可以执行处理;
- 写操作:先在主库执行,再由主库将写操作同步给从库。
Redisd的采用同步异步混合进行的模式,在Redis中被称为完整重同步和部分重同步。

- 完整重同步用于初次复制的情况,通过让主服务器发送RDB文件,以及向从服务器发送保存在缓冲区中的写命令来同步。
- 部分重同步处理断线后重复制的情况,主服务器将从服务器断开后执行的写命令发送到从服务器。偏移量通过运行ID来得到。
这两种方式之后都会通过命令传播来将写命令发送给从库进行后续同步,Redis的主节点创建和维护一个环形缓冲复制队列(即repl_backlog_buffer),从节点部分复制(增量复制)的数据均来自repl_backlog_buffer。主节点只有一个repl_backlog_buffer,所有从节点共享。
通过级联方式,可以减少主库RDB同步的压力:

让我们回顾一下复制日志的三种实现方式:
- 基于语句的复制,比如AOF
- WAL预写日志,在 WAL 中,当一个事务要对数据库进行修改时,它首先将修改操作写入到日志文件中,而不是直接将修改应用到数据库文件。日志文件被设计为追加写入的形式,即新的日志记录会被追加到文件的末尾(比如mysql 的binlog)
- 逻辑日志,复制和存储引擎使用不同的日志格式。更容易保持兼容性和解析,比如RDB、binlog
思考:一致的复制
异步复制的问题很明显:会导致主从的不一致性。
那么我们不考虑诸如raft、paxos这种的共识的多主写入的算法,在诸如redis这种单主写入的系统中,有没有办法做到一致复制的同时保证速度呢?
链式复制是同步复制的一种变体, 已经在一些系统( 如Microsoft Azure存储)中成功实现。(这部分6.824也提到了)
在Chain Replication中,有一些服务器按照链排列。第一个服务器称为HEAD,最后一个被称为TAIL。
当客户端想要发送一个写请求,写请求总是发送给HEAD。
当HEAD收到了写请求,将本地数据更新成了B,之后会再将写请求通过链向下一个服务器传递。
下一个服务器执行完写请求之后,再将写请求向下一个服务器传递,以此类推,所有的服务器都可以看到写请求。
当写请求到达TAIL时,TAIL将回复发送给客户端,表明写请求已经完成了。这是处理写请求的过程。

2009年,普林斯顿的CRAQ(Chain Replication with Apportioned Queries: 读均摊的链式复制) 这篇论文对于上述问题进行了改进,同时还提供了weak consistency的支持,在低一致性需求的workload下提高性能。

思考:链式同步和半同步各有什么优劣?为什么现在都不使用无主复制了?
故障转移
这一节对应《数据密集型应用系统设计》中的“分布式系统的麻烦”,因为大多数开发人员可能并非要考虑这方面的问题,因此只用一小节的内容介绍一下Redis的实现。
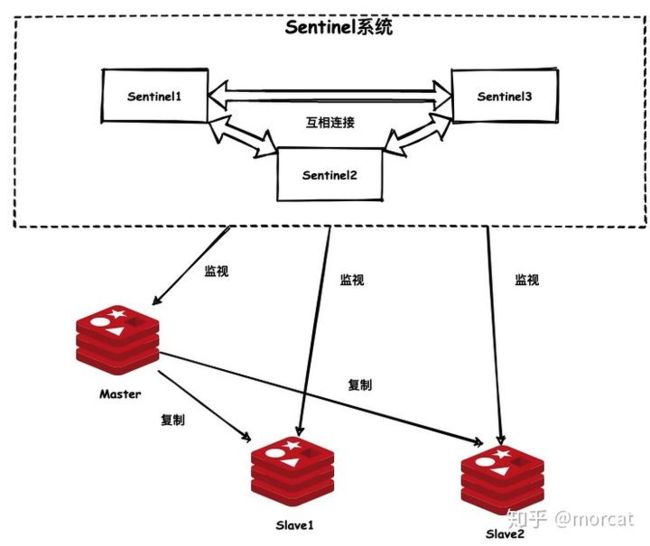
哨兵模式引入了一个Sentinel系统去监视主服务器及其所属的所有从服务器。一旦发现有主服务器宕机后,会自动选举其中的一个从服务器升级为新主服务器以达到故障转义的目的。同样的Sentinel系统也需要达到高可用,所以一般也是集群,互相之间也会监控。而Sentinel其实本身也是一个以特殊模式的Redis服务器。
流程:
1.Sentinel与主从服务器建立连接
- Sentinel服务器启动之后便会创建于主服务器的命令连接,并订阅主服务器的**sentinel:hello频道以创建订阅连接**
- Sentinel默认会每10秒向主服务器发送 INFO 命令,主服务器则会返回主服务器本身的信息,以及其所有从服务器的信息。
- 根据返回的信息,Sentinel服务器如果发现有新的从服务器上线后也会像连接主服务器时一样,向从服务器同时创建命令连接与订阅连接。
2.判定主服务器是否下线
每一个Sentinel服务器每秒会向其连接的所有实例包括主服务器,从服务器,其他Sentinel服务器)发送 PING命令,根据是否回复 PONG 命令来判断实例是否下线。
判定主观下线
如果实例在收到 PING命令的down-after-milliseconds毫秒内(根据配置),未有有效回复。则该实例将会被发起 PING命令的Sentinel认定为主观下线。
判定客观下线
当一台主服务器没某个Sentinel服务器判定为客观下线时,为了确保该主服务器是真的下线,Sentinel会向Sentinel集群中的其他的服务器确认,如果判定主服务器下线的Sentinel服务器达到一定数量时(一般是N/2+1),那么该主服务器将会被判定为客观下线,需要进行故障转移。
3.选举领头Sentinel
当有主服务器被判定客观下线后,Sentinel集群会选举出一个领头Sentinel服务器来对下线的主服务器进行故障转移操作。整个选举其实是基于RAFT一致性算法而实现的,大致的思路如下:
- 每个发现主服务器下线的Sentinel都会要求其他Sentinel将自己设置为局部领头Sentinel。
- 接收到的Sentinel可以同意或者拒绝
- 如果有一个Sentinel得到了半数以上Sentinel的支持则在此次选举中成为领头Sentinel。
- 如果给定时间内没有选举出领头Sentinel,那么会再一段时间后重新开始选举,直到选举出领头Sentinel。
4.选举新的主服务器
领头服务器会从从服务中挑选出一个最合适的作为新的主服务器。挑选的规则是:
- 选择健康状态的从节点,排除掉断线的,最近没有回复过 INFO命令的从服务器。
- 选择优先级配置高的从服务器
- 选择复制偏移量大的服务器(表示数据最全)
挑选出新的主服务器后,领头服务器将会向新主服务器发送 SLAVEOF no one命令将他真正升级为主服务器,并且修改其他从服务器的复制目标,将旧的主服务器设为从服务器,以此来达到故障转移。
Redis分区
集群模式
Redis Cluster的整个数据库将会被分为16384个哈希槽,数据库中的每个键都属于这16384个槽中的其中一个,集群中的每个节点可以处0个或者最多16384个槽。Redis作者认为集群在一般情况下是不会超过1000个实例,取了16384个,即可以将数据合理打散至Redis集群中的不同实例,又不会在交换数据时导致带宽占用过多
计算键属于哪个槽
**CRC16(key) & 16383**
Sharding流程
- 当客户端发起对键值对的操作指令后,将任意分配给其中某个节点
- 节点计算出该键值所属插槽
- 判断当前节点是否为该键所属插槽
- 如果是的话直接执行操作命令
- 如果不是的话,向客户端返回moved错误,moved错误中将带着正确的节点地址与端口,客户端收到后可以直接转向至正确节点
Redis的每个节点都可以分为主节点与对应从节点。主节点负责处理槽,从节点负责复制某个主节点,并在主节点下线时,代替下线的主节点。
重新平衡分区
当集群删除或者增加Redis实例时,redis-trib会进行槽重新分片操作。
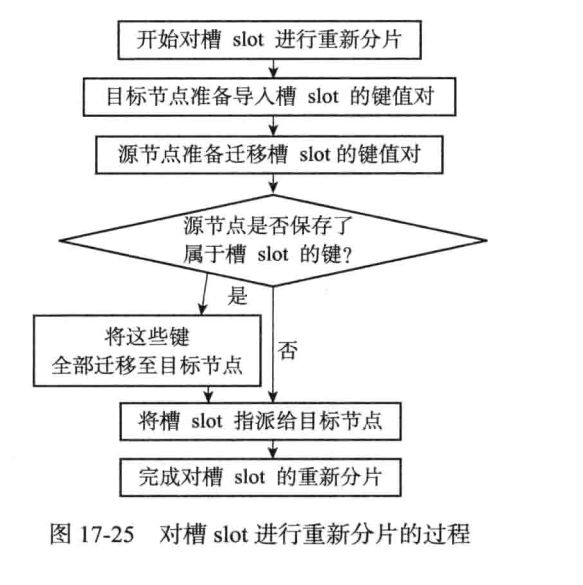

如果已经迁移完成,会发送MOVED指令指向有相应槽的节点。ask指令客户端不会更新缓存,MOVED指令客户端会更新缓存。
为什么不使用一致性哈希
less is more。
Redis这种基于槽迁移的办法是不能使用一致性哈希的,为了简洁和高效,Redis没有用一致性哈希。
在集群中的每个实例都能拿到槽位相关的信息,集群的扩容、缩容都是以「哈希槽」作为基本单位进行操作,总的来说就是「实现」会更加简单(简洁,高效,有弹性)。过程大概就是把部分槽进行重新分配,然后迁移槽中的数据即可,不会影响到集群中某个实例的所有数据。
Redis分区的问题
范围查询效率比较低。可以考虑使用复合主键。
脑裂
脑裂的主要原因其实就是哨兵集群认为主节点已经出现故障了,重新选举其它从节点作为主节点,而原主节点其实是假故障,从而导致短暂的出现两个主节点,那么在主从切换期间客户端一旦给原主节点发送命令,就会造成数据丢失。
所以应对脑裂的解决办法应该是去限制原主库接收请求,Redis提供了两个配置项。
- min-slaves-to-write:与主节点通信的从节点数量必须大于等于该值主节点,否则主节点拒绝写入。
- min-slaves-max-lag:主节点与从节点通信的ACK消息延迟必须小于该值,否则主节点拒绝写入。
这两个配置项必须同时满足,不然主节点拒绝写入。
在假故障期间满足min-slaves-to-write和min-slaves-max-lag的要求,那么主节点就会被禁止写入,脑裂造成的数据丢失情况自然也就解决了。
Redis操作和状态一致性
DB-Cache一致性
从前面我们可以看到,Redis的设计就是易失的,不提供最终一致性的保障,那么使用DB作为最后的保障就成了一个必选项,那么如何保持DB-Cache一致性呢?
只读缓存
新增数据
**新增数据时 ,**写⼊数据库;访问数据时,缓存缺失,查数据库,更新缓存。
这个过程不会有不一致的问题。
更新数据
无并发
无论是先删除缓存还是先更新数据库都会有不一致的问题:
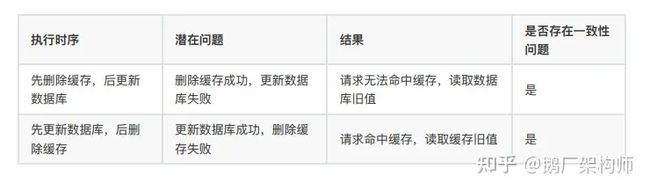

- 把要删除缓存值或者是要更新数据库值操作生成消息,暂存到消息队列中(例如使⽤ Kafka 消息队列);
- 当删除缓存值或者是更新数据库值操作成功时,把这些消息从消息队列中去除(丢弃),以免重复操作;
- 当删除缓存值或者是更新数据库值操作失败时,执⾏失败策略,重试服务从消息队列中重新读取(消费)这些消息,然后再次进⾏删除或更新;
- 删除或者更新失败时,需要再次进⾏重试,重试超过的⼀定次数,向业务层发送报错信息
有并发
先删除缓存再更新数据库
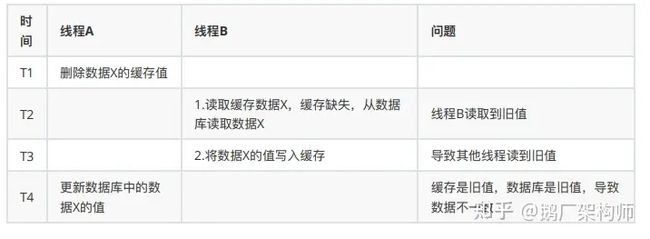
缓存过期时间 + 延时双删
通过设置缓存过期时间,若发⽣上述淘汰缓存失败的情况,则在缓存过期后,读请求仍然可以从DB中读取最新数据并更新缓存,可减⼩数据不⼀致的影响范围。虽然在⼀定时间范围内数据有差异,但可以保证数据的最终⼀致性。
此外,还可以通过延时双删进⾏保障:在线程 A 更新完数据库值以后,让它先 sleep ⼀⼩段时间,确保线程 B 能 够先从数据库读取数据,再把缺失的数据写⼊缓存,然后,线程 A 再进⾏删除。后续,其它线程读取数据时,发现缓存缺失,会从数据库中读取最新值。
redis.delKey(X)
db.update(X)
Thread.sleep(N)
redis.delKey(X)
这两个方法并不能真正保证强一致性。
先更新数据库再删除缓存(双写一致)

更新数据时,加写锁;查询数据时,加读锁

这个地方的问题非常民科,因为Redis和mysql都没有强一致性协议的实现,
不管怎么样都无法强一致的。
双写这里,先更新数据库再mq删缓存确实能最终一致。
操作一致性和状态一致性
在前面,我们探讨了复制的一致性、分区的一致性、事务的一致性(核心在于隔离性)。
操作和状态的一致性并不是和上面这些概念是割裂的,而是要靠复制和分区的一致性来保障。
论文“The many faces of consistency”中提出了一致性的两个概念:状态一致性(State Consistency)和操作一致性(Operation Consistency)。它们是观察数据一致性的两个视角。
- 状态一致性是指,数据所处的客观、实际状态所体现的一致性;
- 操作一致性是指,外部用户通过协议约定的操作,能够读取到的数据一致性。
状态的一致性
状态的一致性和复制是息息相关的:
从状态的视角来看,任何变更操作后,数据只有两种状态,所有副本一致或者不一致。在某些条件下,不一致的状态是暂时,还会转换到一致的状态,而那些永远不一致的情况几乎不会去讨论,所以习惯上大家会把不一致称为“弱一致”。相对的,一致就叫做“强一致”了。
比如说,MySQL的全同步复制是状态强一致的,而NoSQL 的最终一致性是弱一致的。
操作的一致性
最终一致性是一个含糊的概念:到底多久会一致?这个问题必须从操作的一致性来衡量。
线性一致性 > 顺序一致性 > 因果一致性 > { 写后读一致性,单调读一致性,前缀一致性 }

线性一致性不是可序列化(SSI)
线性一致性不会组织写偏差和幻读,它提供一种单个操作的新鲜度的保障。
同时,SSI由于使用了快照,也不是线性一致的。
Total Avaiable下的一致性
在每个非故障节点上可用,即使网络完全宕机。
单调写一致性(Monotonic writes)
Monotonic writes ensures that if a process performs write w1, then w2, then all processes observe w1 before w2.
单调写入确保如果一个进程执行写入w1,然后执行写入w2,那么所有进程都在w2之前观察到w1。(对于服务端而言)
服务端的写入必须是w1 -> w2
单调读一致性(Monotonic Reads)
Monotonic reads ensures that if a process performs read r1, then r2, then r2 cannot observe a state prior to the writes which were reflected in r1; intuitively, reads cannot go backwards.
Monotonic reads does not apply to operations performed by different processes, only reads by the same process.
Monotonic reads can be totally available: even during a network partition, all nodes can make progress.
单调读取确保如果进程执行读取r1,然后是r2,那么r2不能观察到r1中反映的写入之前的状态;凭直觉,阅读不能倒退。
单调读取不适用于不同进程执行的操作,只适用于同一进程执行的读取。
单调读取可以完全可用:即使在网络分区期间,所有节点都可以进行。(对于客户端而言)
客户端的读取必须是v1->v2(版本号)
写跟随读一致(Writes Follow Reads)
Writes follow reads, also known as session causality, ensures that if a process reads a value v, which came from a write w1, and later performs write w2, then w2 must be visible after w1. Once you’ve read something, you can’t change that read’s past.
Writes follow reads is a totally available property. Every node can make progress regardless of network partitions.
写入跟随读取,也称为会话因果关系,确保如果进程读取来自写入w1的值v,然后执行写入w2,则w2必须在w1之后可见。一旦你读过一些东西,你就无法改变它的过去。
写入后读取是完全可用的属性。无论网络分区如何,每个节点都可以取得进展。(对于服务端而言)
R1 -> W2 -> R2 -> R3
事务-读未提交(Read Uncommitted)
JEPSEN中的RU跟平常说的不太一样,它不仅禁止第一类更新丢失(回滚时修改其它事务数据),而且禁止脏写
事务-读已提交(Read Committed)
禁止第一类更新丢失、脏写和脏读
事务-单调原子视图(Monotonic Atomic View)
Monotonic atomic view is a consistency model which strengthens read committed by preventing transactions from observing some, but not all, of a previously committed transaction’s effects. It expresses the atomic constraint from ACID that all (or none) of a transaction’s effects should take place. Once a write from transaction T1 is observed by transaction T2, then all effects of T1 should be visible to T2. This is particularly helpful in enforcing foreign key constraints and ensuring indices and materialized views reflect their underlying objects.
Monotonic atomic view is a transactional model: operations (usually termed “transactions”) can involve several primitive sub-operations performed in order. It is also a multi-object property: operations can act on multiple objects in the system.
单调原子视图是一种一致性模型,它通过防止事务观察到以前提交的事务的部分(但不是全部)影响来加强读取提交。它表达了ACID的原子约束,即事务的所有(或没有)效果都应该发生。一旦事务T2观察到来自事务T1的写入,那么T1的所有影响对于T2应该是可见的。这对于强制执行外键约束和确保索引和物化视图反映其底层对象特别有帮助。
单调原子视图是一个事务模型:操作(通常称为“事务”)可以涉及按顺序执行的几个基元子操作。它也是一个多对象属性:操作可以作用于系统中的多个对象。
Sticky Avaiable下的一致性
写后读一致(Read Your Writes)
Read your writes, also known as read my writes, requires that if a process performs a write w, then that same process performs a subsequent read r, then r must observe w’s effects.
Note that read your writes does not apply to operations performed by different processes. There is no guarantee, for instance, that if process 1 writes a value successfully, that process 2 will subsequently observe that write.
读取您的写入,也称为读取我的写入,要求如果一个进程执行写入w,那么同一进程执行后续读取r,那么r必须观察w的效果。
请注意,读写操作不适用于不同进程执行的操作。例如,不能保证如果进程1成功写入值,则进程2随后会观察到该写入。
PRAM
PRAM (Pipeline Random Access Memory) comes from Lipton & Sandberg’s 1988 paper PRAM: A Scalable Shared Memory, which attempts to relax existing coherent memory models to obtain better concurrency (and therefore performance). It enforces that any pair of writes executed by a single process are observed (everywhere) in the order the process executed them; however, writes from different processes may be observed in different orders.
PRAM(Pipeline Random Access Memory)来自Lipton&Sandberg 1988年的论文《PRAM:A Scalable Shared Memory》,该论文试图放松现有的一致内存模型,以获得更好的并发性(从而获得更好的性能)。它强制单个进程执行的任何一对写入都按照进程执行它们的顺序进行观察(随处可见);然而,可以以不同的顺序观察到来自不同进程的写入。
单进程有序不同进程无序
因果一致性(Causal Consistency)
因果一致性的基础是偏序关系,也就是说,部分事件顺序是可以比较的。至少一个节点内部的事件是可以排序的,依靠节点的本地时钟就行了;节点间如果发生通讯,则参与通讯的两个事件也是可以排序的,接收方的事件一定晚于调用方的事件。
基于这种偏序关系,Leslie Lamport 在论文“Time, Clocks, and the Ordering of Events in a Distributed System”中提出了逻辑时钟的概念。借助逻辑时钟仍然可以建立全序关系,当然这个全序关系是不够精确的。因为如果两个事件并不相关,那么逻辑时钟给出的大小关系是没有意义的。
多数观点认为,因果一致性弱于线性一致性,但在并发性能上具有优势,也足以处理多数的异常现象,所以因果一致性也在工业界得到了应用。具体到分布式数据库领域,CockroachDB 和 YugabyteDB 都在设计中采用了逻辑混合时钟(Hybrid Logical Clocks),这个方案源自 Lamport 的逻辑时钟,也取得了不错的效果。因此,这两个产品都没有实现线性一致性,而是接近于因果一致性,其中 CockroachDB 将自己的一致性模型称为“No Stale Reads”。
Unavaiable下的一致性
顺序一致性(Sequential consistency)
Sequential consistency is a strong safety property for concurrent systems. Informally, sequential consistency implies that operations appear to take place in some total order, and that that order is consistent with the order of operations on each individual process.
Sequential consistency cannot be totally or sticky available; in the event of a network partition, some or all nodes will be unable to make progress.
A process in a sequentially consistent system may be far ahead, or behind, of other processes. For instance, they may read arbitrarily stale state. However, once a process A has observed some operation from process B, it can never observe a state prior to B. This, combined with the total ordering property, makes sequential consistency a surprisingly strong model for programmers.
When you need real-time constraints (e.g. you want to tell some other process about an event via a side channel, and have that process observe that event), try linearizability. When you need total availability, and a total order isn’t required, try causal consistency.
序列一致性是并发系统的一个强大的安全特性。非正式地说,顺序一致性意味着操作似乎以某种总体顺序发生,并且该顺序与每个单独流程上的操作顺序一致。
顺序一致性不可能是完全可用的或粘性可用的;在网络分区的情况下,部分或所有节点将无法进行处理。
顺序一致系统中的进程可能远远领先于或落后于其他进程。例如,他们可以任意读取过时的状态。然而,一旦进程a观察到进程B的某些操作,它就永远无法观察到B之前的状态。这与总排序特性相结合,使序列一致性成为程序员的一个令人惊讶的强大模型。
当您需要实时约束时(例如,您想通过侧通道告诉其他进程有关事件的信息,并让该进程观察该事件),请尝试线性化。当您需要总可用性,而不需要总订单时,请尝试因果一致性。
线性一致性(Linearizability)
Linearizability is one of the strongest single-object consistency models, and implies that every operation appears to take place atomically, in some order, consistent with the real-time ordering of those operations: e.g., if operation A completes before operation B begins, then B should logically take effect after A.
This model cannot be totally or sticky available; in the event of a network partition, some or all nodes will be unable to make progress.
Linearizability is a single-object model, but the scope of “an object” varies. Some systems provide linearizability on individual keys in a key-value store; others might provide linearizable operations on multiple keys in a table, or multiple tables in a database—but not between different tables or databases, respectively.
When you need linearizability across multiple objects, try strict serializability. When real-time constraints are not important, but you still want every process to observe the same total order, try sequential consistency
线性化是最强的单对象一致性模型之一,它意味着每个操作似乎都是原子性的,以某种顺序发生,与这些操作的实时顺序一致:例如,如果操作A在操作B开始之前完成,那么B在逻辑上应该在A之后生效。
此模型不能完全可用或粘性可用;在网络分区的情况下,部分或所有节点将无法进行处理。
线性化是一个单一的对象模型,但“对象”的范围各不相同。一些系统在键值存储中的各个键上提供线性化;其他的可能对一个表中的多个键或数据库中的多张表提供可线性化的操作,但不能分别在不同的表或数据库之间提供。
当您需要跨多个对象的线性化时,请尝试严格的串行化。当实时约束不重要,但您仍然希望每个流程都遵守相同的总顺序时,请尝试顺序一致性
事务-游标稳定性(Cursor stability)
Cursor stability is a consistency model which strengthens read committed by preventing lost updates. It introduces the concept of a cursor, which refers to a particular object being accessed by a transaction. Transactions may have multiple cursors. When a transaction reads an object using a cursor, that object cannot be modified by any other transaction until the cursor is released, or the transaction commits.
This prevents lost updates, where transaction T1 reads, modifies, and writes back an object x, but a different transaction T2 transaction also updates x after T1 read x—causing T2’s update to be effectively lost.
Cursor stability is a transactional model: operations (usually termed “transactions”) can involve several primitive sub-operations performed in order. It is also a multi-object property: operations can act on multiple objects in the system.
Cursor stability cannot be totally available; in the presence of network partitions, some or all nodes may be unable to make progress. For total availability, at the cost of allowing lost updates, consider read committed. For a stronger level, which ensures the stability of every record read, rather than cursors, consider repeatable read.
游标稳定性是一种一致性模型,它通过防止丢失更新来加强提交的读取。它引入了游标的概念,游标指的是事务正在访问的特定对象。事务可能有多个游标。当事务使用游标读取对象时,在释放游标或事务提交之前,任何其他事务都不能修改该对象。
这防止了丢失的更新,其中事务T1读取、修改和写回对象x,但不同的事务T2事务也在T1读取x之后更新x,从而导致T2的更新实际上丢失。
游标稳定性是一个事务模型:操作(通常称为“事务”)可以包括按顺序执行的几个基元子操作。它也是一个多对象属性:操作可以作用于系统中的多个对象。
光标稳定性不可能完全可用;在存在网络分区的情况下,一些或所有节点可能无法取得进展。为了获得总体可用性,以允许丢失更新为代价,请考虑已提交读取。为了确保每个记录读取(而不是游标)的稳定性,考虑可重复读取。
事务-可重复读(Repeatable Read)
见下文
事务-快照隔离(SnapshotIsolation)
见下文
事务-可串行化(Serializable)
见下文
Redis集群的一致性
More generally, a storage system that can lose data cannot be called an eventually consistent storage system.
从上面我们可以看出来,弱一致性是一种非常强的保障,只有将AOF配置为always(确保每次写入都调用内核的pdflush线程簇刷脏页),并且使用非易失的磁盘阵列,并且在消息队列中追加AOF进行故障转移的任务 才能堪堪保证弱一致性。
分布式系统如何实现线性一致性?
单主复制(可能线性一致)比如上面提到的没有故障转移的情况
共识算法(线性一致)
多主复制(非线性一致)
无主复制(非线性一致) 即使w+r>n 仍有可能非线性:

从产品层面看,主流分布式数据库大多以实现线性一致性为目标,在设计之初或演进过程中纷纷引入了全局时钟,比如 Spanner、TiDB、OceanBase、GoldenDB 和巨杉等等。
工程实现上,多数产品采用单点授时(TSO),也就是从一台时间服务器获取时间,同时配有高可靠设计; 而 Spanner 以全球化部署为目标,因为 TSO 有部署范围上的限制,所以 Spanner 的实现方式是通过 GPS 和原子钟实现的全局时钟,也就是 TrueTime,它可以保证在全球范围内任意节点能同时获得的一个绝对时间,误差在 7 毫秒以内。
数据密集型应用系统设计中将TSO称为全序广播。
Redis如何实现分布式锁?
参考ATA最近开源的:https://zhuanlan.zhihu.com/p/669266056
分布式锁的选择:

最佳实践还是Redisson使用setnx+定期检查实现的锁,redlock有各种问题。redisson也不是完全可靠的。、
Redis事务
事务状态转换
Redis事务有四个重要的特殊命令:
MULTI、EXEC、DISCARD、WATCH
MULTI: 开启事务,开启后输入的命令都不会直接执行,而是加入事务命令队列,如果检测到参数数量错误或命令不存在,则会中止当前事务并清空队列。而执行时检测出的错误并不会阻止其它命令的执行。
EXEC: 执行事务,按执行命令顺序返回结果。
DISCARD: 终止事务,清空命令队列并终止事务。
WATCH: 监听 key,被监听的 key 如果在事务之外被修改,则事务不会执行(EXEC 时结果返回 nil)。
UNWATCH: 取消监听 key。

Redis事务有没有原子性?
语法错误和类型错误
语法错误是在提交时检查的,能够保证原子性;类型错误是在运行时检查的,不能保证原子性。
WATCH检查
Redis使用WATCH命令来决定事务是继续执行还是回滚,那就需要在MULTI之前使用WATCH来监控某些键值对,然后使用MULTI命令来开启事务,执行对数据结构操作的各种命令,此时这些命令入队列。
当使用EXEC执行事务时,首先会比对WATCH所监控的键值对,如果没发生改变,它会执行事务队列中的命令,提交事务;如果发生变化,将不会执行事务中的任何命令。
Lua脚本
Lua脚本同样不能进行回滚。
所以Redis没有原子性。
分布式事务原子性:从TCC到Precolator
原子性协议有TCC、2PC、3PC 以及[MVCC+]Precolator等
TCC

TCC是Try-Confirm-Cancel的简写。
TCC最主要的问题在于对于业务的侵入性,无论是Confirm还是Cancel都必须根据业务实际情况来写。
同时,为了避免网络抖动引起的问题,confirm和cancel都必须具有业务操作上的幂等性。

2PC
2PC使用数据库的commit/rollback操作替代了TCC的confirm/delete操作,减少了对于业务的侵入性。
但是有如下问题:
- 同步阻塞(行锁)
- 单点故障
- 数据不一致
MVCC+Percolator
执行前:
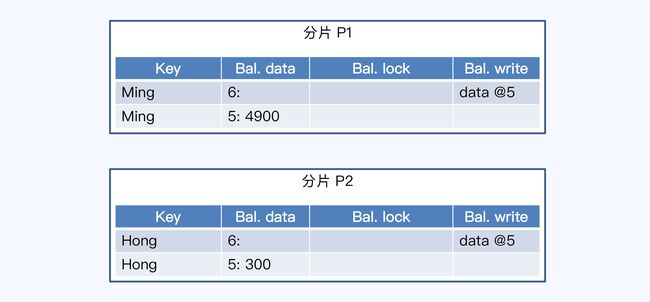
准备阶段:
片接到请求后要做两件事,写日志和添加私有版本。

提交阶段:

一致性:只处理一个锁。
单点故障:事务管理器可以用记录日志的方式使自身无状态化,日志通过共识算法同时保存在系统的多个节点上。这样,事务管理器宕机后,可以在其他节点启动新的事务管理器,基于日志恢复事务操作。
Redis事务有没有隔离性?
没有
分布式事务隔离性
转到https://www.yuque.com/treblez/qksu6c/ahgvn94c2nh1y34w#bdk7E
Redis事务有没有持久性?
毫无疑问,Redis这种异步复制的模式没有持久性。
分布式事务如何实现持久性?
- 存储硬件无损、可恢复的故障。这种情况下,主要依托于**预写日志(Write Ahead Log, WAL)**保证第一时间存储数据。WAL 采用顺序写入的方式,可以保证数据库的低延时响应。WAL 是单体数据库的成熟技术,NoSQL 和分布式数据库都借鉴了过去。(或者物理日志,比如redo-log)
- 存储硬件损坏、不可恢复的故障。这种情况下,需要用到日志复制技术,将本地日志及时同步到其他节点。实现方式大体有三种:第一种是单体数据库自带的同步或半同步的方式,其中半同步方式具有一定的容错能力,实践中被更多采用;第二种是将日志存储到共享存储系统上,后者会通过冗余存储保证日志的安全性,亚马逊的 Aurora 采用了这种方式,也被称为 Share Storage;第三种是基于 Paxos/Raft 的共识算法同步日志数据,在分布式数据库中被广泛使用。无论采用哪种方式,目的都是保证在本地节点之外,至少有一份完整的日志可用于数据恢复。
事务一致性
事务的一致性是一个很微妙的概念,它指的是事务使数据库从一个一致性状态变换到另一个一致性状态,完整性约束不受破坏。完整性约束指的是数据关系的完整性和业务逻辑的完整性。
它没提出任何具体的要求,也没有具体的设计(凑数的)。
分布式事务隔离性
《数据密集型应用系统设计》这一章写的不太好,需要看一些论文来理解这里的问题。
6.824这里说的也不太好,推荐看15-445。
Critique隔离级别
SQL-92的隔离级别:
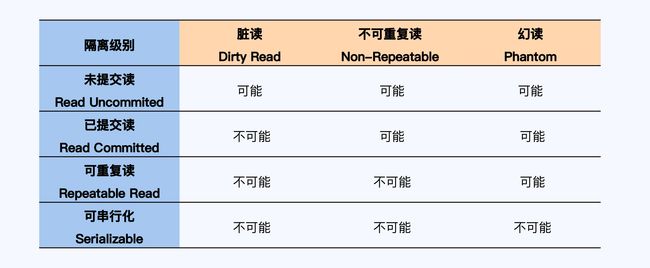
快照隔离能解决幻读的问题,但却无法处理写倾斜(Write Skew)问题,也不符合可串行化要求。
Critique 对幻读的描述大致是这样的,事务 T1 使用特定的查询条件获得一个结果集,事务 T2 插入新的数据,并且这些数据符合 T1 刚刚执行的查询条件。T2 提交成功后,T1 再次执行同样的查询,此时得到的结果集会增大。这种异常现象就是幻读。
不少人会将幻读与不可重复读混淆,这是因为它们在自然语义上非常接近,都是在一个事务内用相同的条件查询两次,但两次的结果不一样。差异在于,对不可重复读来说,第二次的结果集相对第一次,有些记录被修改(Update)或删除(Delete)了;而幻读是第二次结果集里出现了第一次结果集没有的记录 (Insert)。一个更加形象的说法,幻读是在第一次结果集的记录“间隙”中增加了新的记录。所以,MySQL 将防止出现幻读的锁命名为间隙锁(Gap Lock)。
写倾斜是这样一种情况:


crtique隔离级别:

SQL-92:
RU-RC - RR(抄袭了InnoDB的SI) - SR
crtique:
RU-RC - RR - SI - SSI
这里的一段渊源:

MVCC与RR/RC
首先介绍一下多版本并发控制(Multi-Version Concurrency Control,MVCC),MVCC就是通过记录数据项历史版本的方式,来提升系统应对多事务访问的并发处理能力。
MVCC的存储方式:
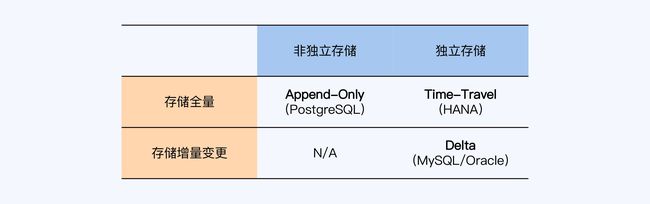

RC 读已提交下MVCC的工作原理:

事务 T6 要读取 R1 到 R6 这六条记录,在 T6 启动时(T6-1)会向系统申请一个活动事务列表,活动事务就是已经启动但尚未提交的事务,这个列表中会看到 T3、T4、T5 等三个事务。T
6 查询到 R3、R4、R5 时,看到它们最新版本的事务 ID 刚好在活动事务列表里,就会读取它们的上一版本。而 R1、R2 最新版本的事务 ID 小于活动事务列表中的最小事务 ID(即 T3),所以 T6 可以看到 R1、R2 的最新版本。
RR 可重复读下MVCC的工作原理:
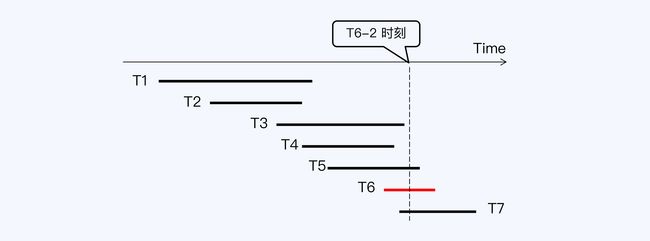
我们只需要记录下 T6-1 时刻的活动事务列表,在 T6-2 时再次使用就行了。那么,这个反复使用的活动事务列表就被称为“快照”(Snapshot)。
RC 与 RR 的区别在于 RC 下每个 SQL 语句会有一个自己的快照,所以看到的数据库是不同的,而 RR 下,所有 SQL 语句使用同一个快照,所以会看到同样的数据库。
因为现在的DB都主要基于MVCC的方式实现RR/RC,所以就不介绍锁的方式了。
当前读和快照读
当前读:读取的是最新版本的数据, 并且对读取的记录加锁, 阻塞其他事务同时改动相同记录,避免出现安全问题。
快照读:读取的是快照中的数据,不需要进行加锁。读取已提交和可重复读这俩隔离级别下的普通 select 操作就是快照读。其实就是 MVCC 机制,或者说,在快照读下,采用 MVCC 机制解决幻读。
对于读写冲突时时钟漂移的问题,一般会通过获取窗口时间戳后写等待和读等待的方式解决,感兴趣的可以看Spanner的论文。
下文的几种隔离性算法都是基于MVCC的,也就是MVOCC、MV2PL、MVSGT。这几个算法都可以通过上面的方式解决脏读和不可重复读的问题。
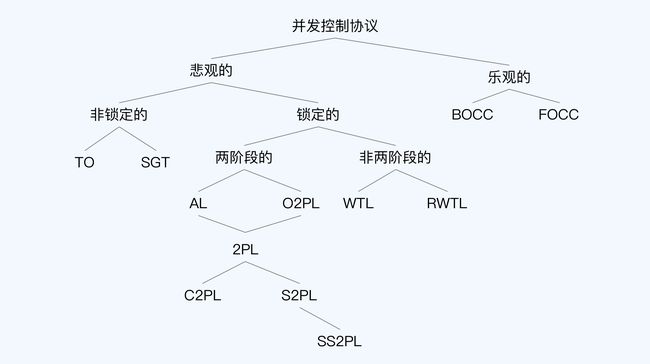
并发控制的三个阶段
在经典理论教材“Principles of Distributed Database Systems”中,作者将乐观协议和悲观协议的操作,都统一成四个阶段,分别是**有效性验证(V)、读(R)、计算(C)和写(W)。两者的区别就是这四个阶段的顺序不同:悲观协议的操作顺序是 VRCW,而乐观协议的操作顺序则是 RCVW。**因为在比较两种协议时,计算(C)这个阶段没有实质影响,可以忽略掉。那么简化后,悲观协议的顺序是 VRW,而乐观协议的顺序就是 RVW。
读阶段(Read Pharse),每个事务对数据项的局部拷贝进行更新。要注意,此时的更新结果对于其他事务是不可见的。将后面要写入的内容,先要暂时加载到一个仅自己可见的临时空间内。
有效性确认阶段(Validation Pharse),验证准备提交的事务。这个验证就是指检查这些更新是否可以保证数据库的一致性,如果检查通过进入下一个阶段,否则取消事务。
写阶段(Write Pharse),将读阶段的更新结果写入到数据库中,接受事务的提交结果。
狭义OCC、广义OCC和TiDB
广义上的OCC满足读(R)、有效性确认(V)、和写(W)的流程即可。
狭义也就是学术界常用的OCC则在V阶段要求:使用满足串行化要求的时间戳检测算法。
但不管是哪种OCC,因为可能在事务冲突较多时会出现大量的回滚,效率低下,所以乐观协议现在已经很少用了。
介绍下TiDB的广义OCC实现原理:
Validation(OCC)的并发控制
执行过程中,每个事务维护自己的写操作(Basic T/O在事务执行过程中写就将数据写入DB)和相应的RTS/WTS(事务写时间戳和事务读时间戳),提交时判断自己的更改是否和数据库中已存在的数据冲突,如果不冲突才写入DB。OCC分为三个阶段:
• Read & Write Phase:即读写阶段,事务维护读的结果和即将提交的更改,以及写入记录的RTS和WTS。
• Validation Phase:检查事务是否与数据库中的数据冲突。
• Write Phase:不冲突就写入,冲突就abort,restart。
Read & Write Phase结束,进入Validation Phase相当于事务准备完成,进入提交阶段了,进入Validation Phase的时间被选做记录行的时间戳,来定序。不用事务开始时间是因为:事务执行时间可能较长,导致后开始的事务可能先提交,这会加大事务冲突的概率,较小时间戳的事务后写入数据库,肯定会abort。
Validation过程
假设当前只有两个事务T1和T2,并修改了相同数据行,T1的时间戳 < T2的时间戳(即validation顺序:T1 < T2,对用户而言,T1先发生于T2),则有如下情况:
(1)T1在validate阶段,T2还在Read & Write Phase。此时只要T1和T2已经发生的读写没有冲突,就可以提交。
• 如果WS(T1) ∩ (RS(T2) ∪ WS(T2)) = ∅,说明T2和T1写的记录无冲突,validation通过,可以写入。
• 否则,T2与T1之间存在读写冲突或写写冲突,T1需要回滚。读写冲突:T2读到了T1写之前的版本,T1提交后,它可能读到T1写的版本,不可重复读。写写冲突:T2有可能在旧版本基础上更新,再次写入,造成T1的更新丢失。
(2)T1完成validate阶段,进入write阶段直到提交完成,这已经是不可逆的了。T2在T1进入write phase之前的读写,肯定和T1的操作不冲突(因为T1 validation通过了)。T2之后继续的读写操作,有可能冲突与T1要提交的操作,因此T2进入validate阶段:
• 如果WS(T1) ∩ RS(T2)= ∅,说明T2没读到T1写的记录,validation通过,T2可以写入。(为什么不验证WS(T2)了呢?WS(T1)已经提交了,且它的时间戳小于WS(T2),WS(T2)里之前的一部分肯定没有冲突,之后的一部分,因为没有读过T1的写入的对象,写进去也没问题,不会覆盖WS(T1)的写)
• 否则,T2与T1之间存在读写冲突和写写冲突,T2需要回滚。读写冲突:T2读到了T1写之前的版本,T1提交后,它可能读到T1写的版本,不可重复读。写写冲突:T2有可能在旧版本基础上更新,再次写入,造成T1的更新丢失。
OCC如何解决幻读?
准备阶段(验证阶段)
① 获取当前时间戳作为提交时间戳,事务状态设置为preparing
② 读集有效性验证,检查读集中的版本是否依然可见;重新执行扫描集检查是否存在幻读
③ 等待提交依赖全部完成或当前事务是否已被其它事务设置为中止
④ 同步写redo日志
⑤ 将事务状态设置为commited
2PL
2PL(Two-phase locking)是数据库最常见的(比如mysql)基于锁的并发控制协议,顾名思义,它包含两个阶段:
• 阶段一:Growing,事务向锁管理器请求它需要的所有锁(存在加锁失败的可能)。
• 阶段二:Shrinking,事务释放Growing阶段获取的锁,不允许再请求新锁。
C2PL、S2PL和SS2PL
保守两阶段封锁协议(Conservative 2PL,C2PL),事务在开始时设置它需要的所有锁。
严格两阶段封锁协议(Strict 2PL,S2PL),事务一直持有已经获得的所有写锁,直到事务终止。
强两阶段封锁协议(Strong Strict 2PL,SS2PL),事务一直持有已经获得的所有锁,包括写锁和读锁,直到事务终止。SS2PL 与 S2PL 差别只在于一直持有的锁的类型。
数据库往往使用的是加强版的S(trong)S(trict)2PL,它完全杜绝了事务未提交的数据被读到。
死锁检测
• Deadlock Detection:
数据库系统根据waits-for图记录事务的等待关系,其中点代表事务,有向边代表事务在等待另一个事务放锁。当waits-for图出现环时,代表死锁出现了。系统后台会定时检测waits-for图,如果发现环,则需要选择一个合适的事务abort。
• Deadlock Prevention:
当事务去请求一个已经被持有的锁时,数据库系统为防止死锁,杀死其中一个事务(一般持续越久的事务,保留的优先级越高)。这种防患于未然的方法不需要waits-for图,但提高了事务被杀死的比率。
意向锁
S-Lock和X-Lock,S-Lock是读请求使用的共享锁,X-Lock是写请求使用的排他锁。层次越高的锁(如表锁),可以有效减少对资源的占用,显著减少锁检查的次数,但会严重限制并发。层次越低的锁(如行锁),有利于并发执行,但在事务请求对象多的情况下,需要大量的锁检查。数据库系统为了解决高层次锁限制并发的问题,引入了意向(Intention)锁的概念:
• Intention-Shared (IS):表明其内部一个或多个对象被S-Lock保护,例如某表加IS,表中至少一行被S-Lock保护。
• Intention-Exclusive (IX):表明其内部一个或多个对象被X-Lock保护。例如某表加IX,表中至少一行被X-Lock保护。
• Shared+Intention-Exclusive (SIX):表明内部至少一个对象被X-Lock保护,并且自身被S-Lock保护。例如某个操作要全表扫描,并更改表中几行,可以给表加SIX。
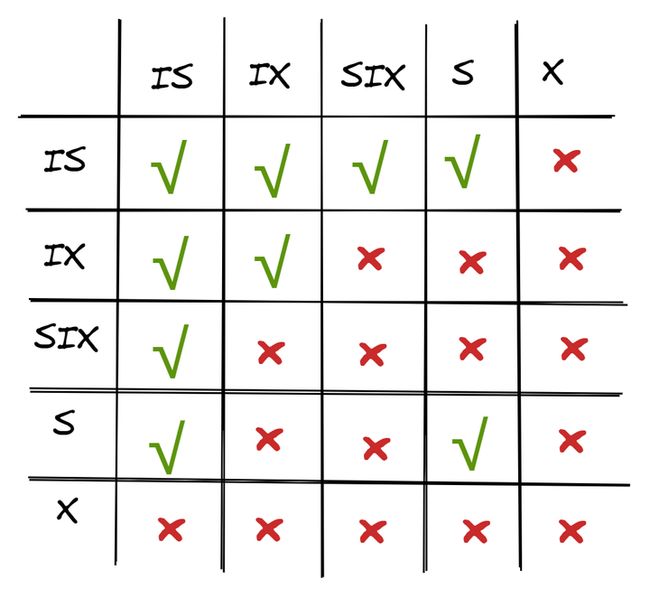
意向锁的好处在于:当表加了IX,意味着表中有行正在修改。
(1)这时对表发起DDL操作,需要请求表的X锁,那么看到表持有IX就直接等待了,而不用逐个检查表内的行是否持有行锁,有效减少了检查开销。(避免幻读)
(2)这时有别的读写事务过来,由于表加的是IX而非X,并不会阻止对行的读写请求(先在表上加IX,再去记录上加S/X),事务如果没有涉及已经加了X锁的行,则可以正常执行,增大了系统的并发度。
另外,如果MySQL innodb 列没有扫描到索引,会加表锁而不是意向锁。
SGT
SSI 是一种隔离级别的命名,最早来自 PostgreSQL,CockroachDB 沿用了这个名称。它是在 SI 基础上实现的可串行化隔离。同样,作为 SSI 核心的 SGT 也不是 CockroachDB 首创,学术界早就提出了这个理论,但真正的工程化实现要晚得多。
串行化图的构建规则是这样的,事务作为节点,当一个操作与另一个操作冲突时,在两个事务节点之间就可以画上一条有向边。
具体来说,事务之间的边又分为三类情况:
- 写读依赖(WR-Dependencies),第二个操作读取了第一个操作写入的值。
- 写写依赖(WW-Dependencies),第二个操作覆盖了第一个操作写入的值。
- 读写反依赖(RW-Antidependencies),第二个操作覆盖了第一个操作读取的值,可能导致读取值过期。
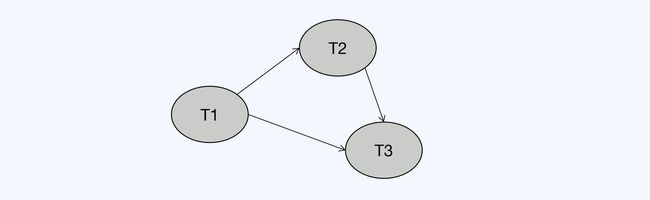
能够构建出 DAG,就说明相关事务是可串行化执行的,不需要中断任何事务。
参考文献
本文仅仅是一个资料的汇总。
参考文献:
《数据密集型应用系统设计》
《分布式数据库 30 讲》
《Redis设计与实现》
《mysql45讲》
6.824
15-445
https://zhuanlan.zhihu.com/p/133823461
https://zhuanlan.zhihu.com/p/651444889
https://zhuanlan.zhihu.com/p/344916555
https://www.zhihu.com/question/462751291/answer/1968377970
本文对应内容都可以在上述课程中找到,本文仅作为参考,请以英文文献为准。