注意力机制和自注意力机制
有很多自己的理解,仅供参考
Attention注意力机制
对于一张图片,我们第一眼看上去,眼睛会首先注意到一些重点的区域,因为这些区域可能包含更多或更重要的信息,这就是注意力机制,我们会把我们的焦点聚焦在比较重要的事物上。大数据中对于重要的数据,我们要使用;对于不重要的数据,我们不太想使用,但是,对于一个模型而言(CNN、LSTM),很难决定什么重要,什么不重要。由此,注意力机制诞生了。
注意力机制是一个很宽泛的概念,可以极端地理解为QKV(三个向量分别称为Query、Key、Value)相乘就是注意力。通过一个查询变量 Q,去找到 V 里面比较重要的东西。假设 K==V,然后 QK 相乘求相似度A,然后 AV 相乘得到注意力值Z,这个 Z 就是 V 的另外一种形式的表示。Q 可以是任何一个东西,V 也是任何一个东西, 但K往往是等同于 V 的(同源),当然K和V不同源不相等也可以。
Attention没有规定 QKV 怎么来,只规定 QKV 怎么做,即上述描述的操作。
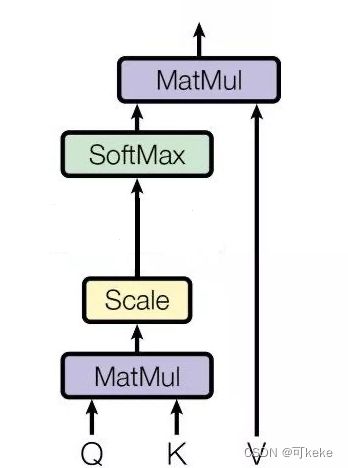
具体计算过程
至于Attention机制的具体计算过程,对目前大多数方法进行抽象的话,可以归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图展示的三个阶段。
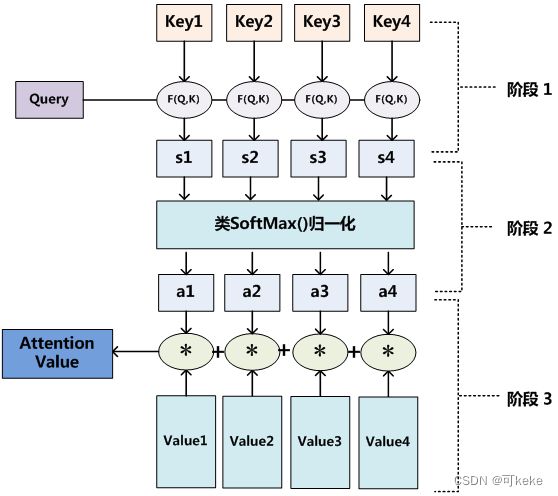
Q, K = k 1 , k 2 , ⋯ , k n K=k_1, k_2, \cdots, k_n K=k1,k2,⋯,kn ,然后我们一般使用点乘(求内积)的方法计算Q 和 K 里的每一个事物的相似度,就拿到了 Q 和 k 1 k_1 k1的相似值 s 1 s_1 s1,Q 和 k 2 k_2 k2的相似值 s 2 s_2 s2,Q 和 k n k_n kn的相似值 s n s_n sn,接着做一层 s o f t m a x ( s 1 , s 2 , ⋯ , s n ) softmax(s_1,s_2,\cdots,s_n) softmax(s1,s2,⋯,sn)得到概率 ( a 1 , a 2 , ⋯ , a n ) (a_1,a_2,\cdots,a_n) (a1,a2,⋯,an),进而就可以找出哪个对Q 而言更重要了;最后进行一个汇总,当使用 Q 查询结束了后,Q 已经失去了它的使用价值,我们最终是要拿到这张图片(以图片举的例子),原图 V = ( v 1 , v 2 , ⋯ , v n ) V=(v_1,v_2,\cdots,v_n) V=(v1,v2,⋯,vn),现在这张图片变为了 V ′ = ( a 1 ∗ v 1 + a 2 ∗ v 2 + ⋯ + a n ∗ v 1 ) V'=(a_1*v_1+a_2*v_2+\cdots+a_n*v_1) V′=(a1∗v1+a2∗v2+⋯+an∗v1),得到了一个新的 V’,这个新的 V’ 就多了哪些更重要、哪些不重要的信息在里面(对Q来说),然后用 V’ 代替 V它。
一般在Transformer中 K=V,当然也可以不相等,但是 K 和 V 之间一定具有某种联系,这样的 QK 点乘才能指导 V 哪些重要,哪些不重要。
Attention不依赖于RNN
前面已经说了Attention是一个很宽泛宏大的概念,所以显然Attention机制本身并不依赖于RNN(循环神经网络)。它是一种独立于具体模型结构的机制,可以与多种模型结构结合使用。
在自然语言处理任务中,Attention机制最初是与RNN结合使用的。具体来说,常见的组合是将Attention机制应用于RNN编码器-解码器模型,如机器翻译任务中的序列到序列模型。在这种情况下,RNN编码器用于将输入序列编码为固定长度的上下文向量,然后解码器使用Attention机制来动态地关注编码器输出的不同部分。
然而,Attention机制不仅限于与RNN结合使用。它可以与其他类型的模型结构一起使用,例如卷积神经网络(CNN)和自注意力机制(如Transformer模型)。在Transformer模型中,Attention机制被广泛应用,并且成为其核心组件之一,用于实现序列中不同位置之间的自注意力计算。
因此,尽管Attention机制最初与RNN结合使用,但它并不是RNN的特定部分,而是一种通用的机制,可以与各种模型结构结合使用,以提高模型在序列处理任务中的性能和效果。
Self-Attention自注意力机制
和Attention类似,他们都是一种注意力机制。不同的是Attention是source对target,输入的source和输出的target内容不同。例如英译中,输入英文,输出中文。而Self-Attention是source对source,是source内部元素之间或者target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。
简单说,Self-Attention不仅固定了QKV的操作(Attention机制),还规定了QKV同源(Q≈K≈V来源于同一个输入X),也就是通过X找到X里面的关键点,QKV通过X与三个参数(矩阵) W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV相乘得到。注意力机制包括自注意力机制和其他种类的注意力机制,比如交叉注意力机制。
具体计算操作和Attention一样
-
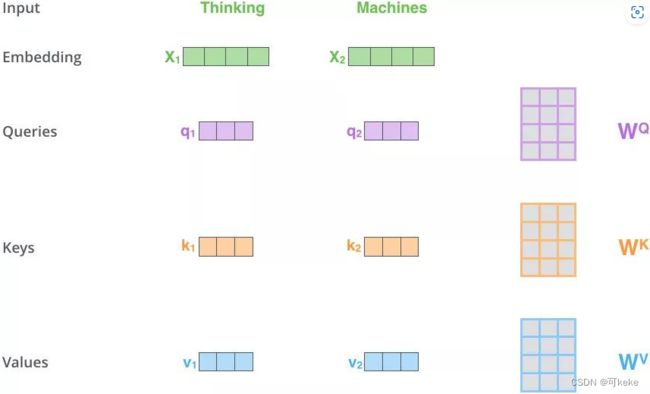
将输入单词X转化成嵌入向量(embedding) a a a
-
根据嵌入向量 a a a得到q,k,v三个向量; q i = W q a i q^i=W^qa^i qi=Wqai, k i = W k a i k^i=W^ka^i ki=Wkai, v i = W v a i v^i=W^va^i vi=Wvai
-
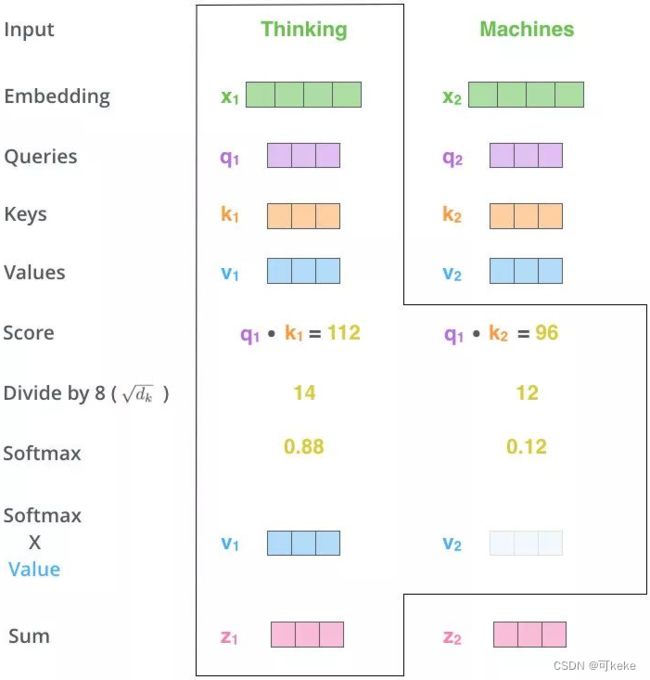
为每个向量计算一个score, a i j a_{ij} aij=score = q i ∗ k j q^i*k^j qi∗kj;若需要计算 a 1 a^{1} a1(embedding后的向量)和 a 1 , a 2 , a 3 , ⋯ , a n a^{1},a^{2},a^{3},\cdots,a^{n} a1,a2,a3,⋯,an之间的关系(或关联),则需要用 q 1 q^{1} q1和 k 1 , k 2 , k 3 , ⋯ , k n k^{1},k^{2},k^{3},\cdots,k^{n} k1,k2,k3,⋯,kn进行匹配计算
-
为了梯度的稳定,Transformer使用了score归一化,即除以 d k \sqrt{dk} dk,原因是防止q和k的点乘结果较大
-
对score施以softmax激活函数
-
softmax点乘Value值v,得到加权的每个输入向量的评分v
-
相加之后得到最终的输出结果z= ∑ v
与RNN和LSTM的区别
RNN无法解决长序列依赖问题,LSTM无法做并行计算,而self-attention很好的解决了这两个问题。
- 长距离依赖建模:Self-Attention可以对序列中的任意两个位置进行直接的关联和交互,因此能够更好地建模长距离依赖。
- 并行计算:在序列中的每个时间步,Self-attention可以同时计算所有位置的注意力权重,从而并行处理整个序列。相比之下,LSTM是逐个时间步进行计算,需要依赖前一时间步的隐藏状态,限制了并行性。
- 句法特征和语义特征:Self-Attention得到的新的词向量具有句法特征和语义特征(表征更完善)。
简单了解:
句法特征:句法特征关注的是语言中单词之间的结构和关系。它们描述了句子中的语法规则、词性、句法依存关系等。句法特征可以帮助我们理解句子的结构和语法规则,例如主谓宾结构、修饰关系等。
语义特征:语义特征则关注的是句子和单词的语义含义。它们描述了单词之间的关联和句子的意义。语义特征帮助我们理解句子的意思、推断隐含信息和进行语义推理。
理论上Self-Attention (Transformer 50个左右的单词效果最好)解决了RNN模型的长序列依赖问题,但是由于文本长度增加时,训练时间也将会呈指数增长,因此在处理长文本任务时可能不一定比LSTM(200个左右的单词效果最好)等传统的RNN模型的效果好。LSTM通过这些门控机制,避免了传统RNN中梯度消失和梯度爆炸的问题,在一些情况下仍然是一种有效的模型选择,研究者也提出了一些结合LSTM和Self-attention的模型,以发挥它们各自的优势。
参考:
ChatGPT
https://www.cnblogs.com/nickchen121/p/15105048.html
https://zhuanlan.zhihu.com/p/265108616
https://zhuanlan.zhihu.com/p/619154409
https://zhuanlan.zhihu.com/p/631398525