Java进阶核⼼之集合框架Collection
一,计算机核心基础之大话数据结构(精简速成)

数据在内存中,它有连续的结构,也有不连续的结构,比如数组,里面的每一个数据的内存地址都是连续的,当然也有非连续的。
为了方便理解数据结构,这里我们举一个例子,比如一个小区,有好多的公寓,如果他们公寓号从一公寓到n公寓,整齐排列,那么我们快递员就很容易的送货,这里可以理解为数组
非连续数据包结构我们以链表为例,比如快递人员相送一个公寓,但是公寓号很乱,没在一起,但是记录这那条街,快递小哥这时候收到的命令就是去4公寓,在xxx街道;
“结构”就是我们理解的数据元素之间的关系,是连续呢,还是非连续呢,就是我们上面举的例子
看完上面的讲解,相信大家可以看懂上面的知识点;

线性结构;大家简单结合上面说的开始结点和终端结点来理解下图
非线性结构,这里我们可以把数组当成一个串,属于线性结构,只是理解的角度不一样而已,大姐后续慢慢会理解的,
我带大家简单看一下树结构,简单认识就行

通过两个图的对比,能鲜明的对比线性结构和非线性结构的区别
***两者最大的区别就是非线性结构可以有多个前趋结点和多个后趋势结点;而线性结构有且仅有一个开始结点和终端结点;
常见数据结构入门

栈Stack
举一个实际的例子来理解,存钱罐
 栈就和这个硬币一一样最后进去的,最先拿出来。数据节点先进后出;
栈就和这个硬币一一样最后进去的,最先拿出来。数据节点先进后出;
队列Queue***************************重要*************************************
 结合知识点即可,简单易懂
结合知识点即可,简单易懂
链表Linked List;跟开始举的例子一样,链表每个数据结点都有自己的地址
{指针是指一个地址的信息}{分为数据域和指针域}
形象点解释。比如班长找校服没穿好的同学,他们站的混乱,
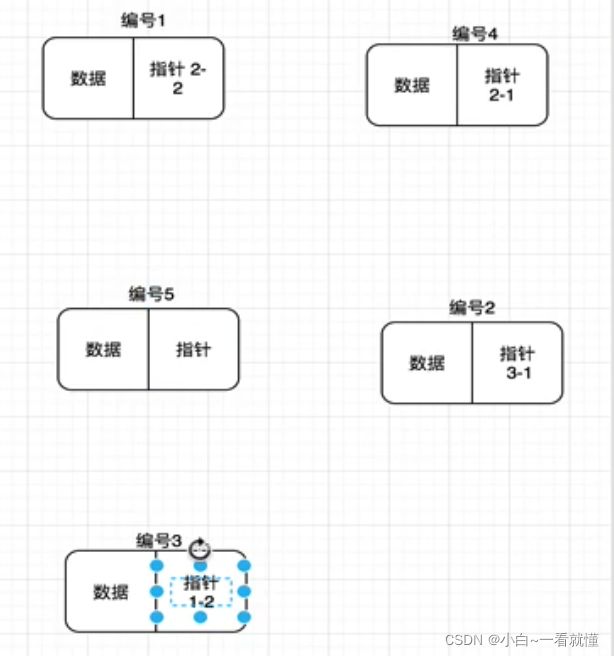
这样就能在混乱的地方找到符合的数据域,将分散的数据,通过地址信息串起来,每一个节点都存放下一个节点的地址信息
二,计算机核心基础之散列表HashTable讲解(**重要**)

比如给你1000万个数据和100万个表格,你怎样才能更快的访问,这就是哈希表。
最核心的知识点是:对任意给定的关键字key,代入函数后若能得到包含该关键字的记录在表中的地址,则这就是哈希表,函数发f(key)为哈希(Hash)函数
![]()
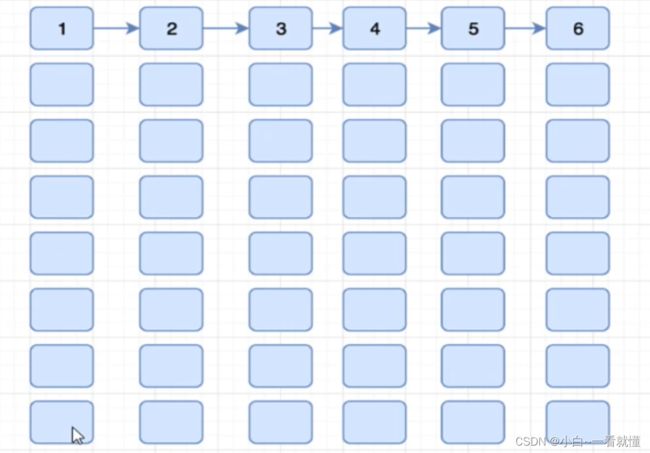
我们需要做到是不用遍历,直接定位需要的一个表格(更快的放进去,更快的拿出来)
(123456)是对应的每一个桶,一列代表一个桶


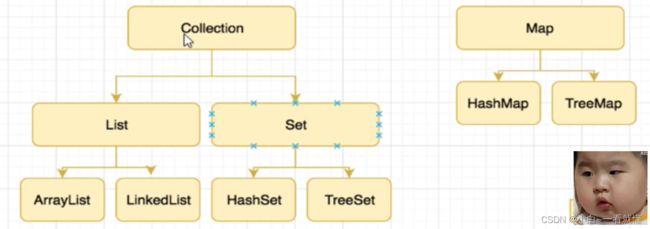
三,java进阶核心之Collection集合框架概要
这是概要,下面会详细介绍

List和数组最大的区别是它会自动扩容,不会出现越界的问题
Set会自动排重,不会重复,比如你存了1000个数据,50个是和之前重复的,最后只会存950个
四,集合框架List介绍

 常见的List API方法介绍; 上代码(Linkedlist和ArrayList中有很多共同的API,getlast()getfirst()是LinkedList特有的API,下面的代码用ArrayList方法)
常见的List API方法介绍; 上代码(Linkedlist和ArrayList中有很多共同的API,getlast()getfirst()是LinkedList特有的API,下面的代码用ArrayList方法)
package chapter8_4;
import java.util.ArrayList;
import java.util.LinkedList;
public class ListTest {
public static void main(String [] args){
//创建对象
ArrayList list =new ArrayList<>();
// LinkedList List =new LinkedList<>();
//往容器里面添加内容
list.add("Jack");
list.add("tom");
list.add("marry");
//System.out.println(list);
//根据所引获取元素
list.get(0);
//更新一个元素
list.set(0,"小D");
//返回容器大小
int size = list.size();
System.out.println("siza="+size);
//根据索引删除一个元素
String indexremove=list.remove(0);
System.out.println("删除后的元素"+list);
//根据对象删除一个元素
boolean objremove=list.remove("jack");
//清空内容
//判断是否为空
boolean beforeisEmpty= list.isEmpty();
System.out.println("清空之前"+beforeisEmpty);
list.clear();
boolean afterisEmpty= list.isEmpty();
System.out.println("清空之后"+afterisEmpty);
}
}
结果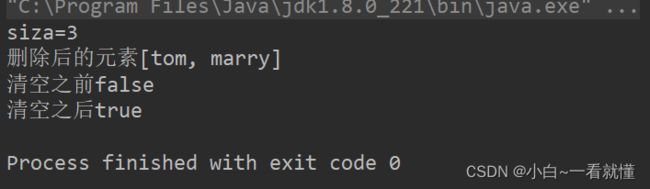
面试题

如果查询要求比较多时选ArrayList。因为LinkedList要移动指针,会很慢。而且ArrayList属于数组,是连续的,会很方便
如果需要很多增删改操作的话选LinkedList,因为它不需要移动很多元素,只需要移动这个元素的上面结点和下面结点就行了。而ArrayList要移动每一个元素的位置
五,集合框架Map介绍上集

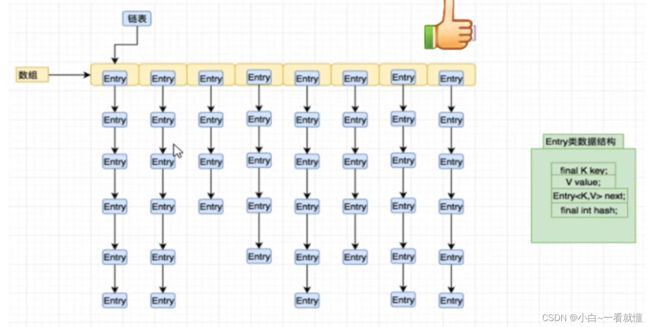
先看上图大概理解,下面教大家使用
数组中每个元素都是bucket桶;参考上面讲的Hash Table(是找到key相对应的桶)
六,集合框架Map介绍下集
常见Map API语法
package chapter8_4;
import java.util.*;
public class MapTest {
public static void main(String [] args){
//HashMap map= new HashMap<>();//无序的HashMap
//{A阿狗=广东深圳, C小东=广东深圳, B小明=广东广东}
//TreeMap map= new TreeMap<>();//系统默认帮你升序
//{A阿狗=广东深圳, B小明=广东广东, C小东=广东深圳}
LinkedHashMap map= new LinkedHashMap<>();//有序的HashMap。按照放的顺序
// {B小明=广东广东, C小东=广东深圳, A阿狗=广东深圳}
//往may里面放key-value
map.put("B小明","广东广东");
map.put("C小东","广东深圳" );
map.put("A阿狗","广东深圳" );
System.out.println(map);
System.out.println("========================================");
//根据key获取value
String getvalue =map.get("C小东");
System.out.println("getvalue="+getvalue);
//判断是都包括某个key
boolean isContains = map.containsKey("B小明");
System.out.println("conrainsKey小明"+isContains);
//返回map的元素数量
int size = map.size();
System.out.println("size="+size);
//获取所以value集合
Collection collection = map.values();
System.out.println(collection);
//获取所有key的集合
Set set=map.keySet();
System.out.println(set);
//返回一个set集合,集合的类型为Map.Entry.是Map声明的一个内部接口,接口为泛型,定义为Entry
//它表示一个实体(一个key-value对),主要有getKey()。getvalue()方法
Set> entrySet = map.entrySet();
for(Map.Entry entry:entrySet){
System.out.println("key="+entry.getKey()+"value="+entry.getValue());
}
//判断map是否为空
boolean beforeclear= map.isEmpty();
System.out.println("beforeclearisEmpty="+beforeclear);
//清空容器
map.clear();
//判断map是否为空
boolean afterclear= map.isEmpty();
System.out.println("afterclearisEmpty="+afterclear);
}
}
面试题

jdk1.8之后的改变是Map的每一个桶bucket到达一定的阈值之后,为了提高性能,就会舍弃链表结构,采用红黑树结构,阈值默认为大于8的时候,来提高速度
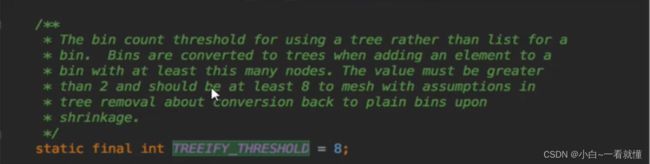
当进行桶内的entry数量<=8的 时候,同样会讲红黑树结构变为链表结构
七,集合框架之set介绍

package chapter8_4;
import jdk.internal.dynalink.beans.StaticClass;
import java.util.HashSet;
public class SetTest {
public static void main(String [] args){
HashSet set = new HashSet<>();
set.add("小明");
}
}

在set.add()中(为set添加元素)
这个图我们来理解Hashset,相当于key可以变化,但是value都是默认的null(从这里理解set基于map)

hashset中key通过哈希函数找到对应的桶bucket,存取速度是比较快的
treeset应用的是treeSet,如需要排序才用

常用的API方法
package chapter8_4;
import jdk.internal.dynalink.beans.StaticClass;
import java.util.HashSet;
import java.util.TreeSet;
public class SetTest {
public static void main(String [] args){
// HashSet set = new HashSet<>();
TreeSet set = new TreeSet<>();
//[jack, marry, tom]默认按字母排序
//往容器里添加对象
set.add("jack");
set.add("jack");
set.add("tom");
set.add("marry");
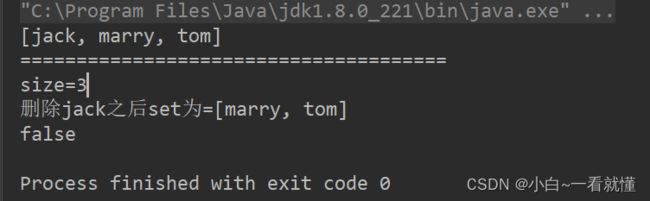
System.out.println(set);
System.out.println("======================================");
//返回大小
int size=set.size();
System.out.println("size="+size);
//根据对象删除元素
set.remove("jack");
System.out.println("删除jack之后set为="+set);
//是否为空
boolean isEmpty=set.isEmpty();
System.out.println(isEmpty);
//清空元素
set.clear();
}
}
结果