数据库与缓存数据一致性解决方案
数据库与缓存数据一致性解决方案
- 1. 数据库与缓存读写模式策略的选择
-
- 1.1 为什么使用缓存
-
- 1.1.1 性能
- 1.1.2 并发
- 1.1.3 带来的问题:一致性问题
- 2.解决方案
-
- 2.1 先更新数据库,再更新缓存
- 2.2 先删除缓存,再更新数据库
- 2.3 先更新数据库,再删除缓存
- 3. 总结
1. 数据库与缓存读写模式策略的选择
1.1 为什么使用缓存
主要是从两个角度去考虑:性能和并发
使用缓存是为了提高性能,增加并发
1.1.1 性能
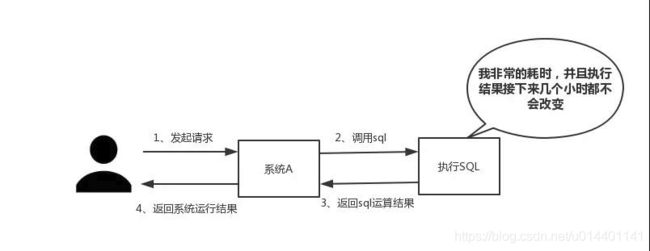
如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。

1.1.2 并发
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。
 不适用使用缓存的场景:数据量太大、数据访问频率非常低的业务都不适合使用Redis,数据太大会增加成本,访问频率太低,保存在内存中纯属浪费资源
不适用使用缓存的场景:数据量太大、数据访问频率非常低的业务都不适合使用Redis,数据太大会增加成本,访问频率太低,保存在内存中纯属浪费资源
1.1.3 带来的问题:一致性问题
数据库的数据和缓存的数据是不可能一致的,数据分为最终一致和强一致两类。
强一致:不可以使用缓存
缓存能做的只能保证数据的最终一致性。
我们能做的只能是尽可能的保证数据的一致性。
不管是先删库再删缓存 还是 先删缓存再删库,都可能出现数据不一致的情况,因为读和写操作是并发的,我们没办法保证他们的先后顺序。
具体应对策略根据业务需求来制订
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列,分布式锁。
2.解决方案
数据库与缓存读写模式策略
写完数据库后是否需要马上更新缓存还是直接删除缓存?
(1)、如果写数据库的值与更新到缓存值是一样的,不需要经过任何的计算,可以马上更新缓存,但是如果对于那种写数据频繁而读数据少的场景并不合适这种解决方案,因为也许还没有查询就被删除或修改了,这样会浪费时间和资源,对于更新和查询分开,更新不频繁,例如某些规则的配置,各服务读取,修改在后台管理系统,适合用先更新数据库在redis的方案
(2)、如果写数据库的值与更新缓存的值不一致,写入缓存中的数据需要经过几个表的关联计算后得到的结果插入缓存中,那就没有必要马上更新缓存,只有删除缓存即可,等到查询的时候在去把计算后得到的结果插入到缓存中即可。
所以一般的策略是当更新数据时,先删除缓存数据,然后更新数据库,而不是更新缓存,等要查询的时候才把最新的数据更新到缓存
我们常见的三种缓存更新方案:
-
先更新数据库,再更新缓存
-
先删除缓存,再更新数据库
-
先更新数据库,再删除缓存
2.1 先更新数据库,再更新缓存
适合更新数据与读取缓存分离,通过后台管理系统修改一些不经常修改的数据。各服务只负责读取缓存。
方案分析:
这种方案有以下缺点:
- 并发更新问题
比如线程A更新了数据库,线程B更新了数据库,线程B更新了缓存,线程A更新了缓存,这样最终存入的就是脏数据。
业务维护难度大,比如有些更新操作多,但是读取时并不多,可能浪费更新到redis的资源,另外redis缓存的数据并不一定是直接写入数据库的,可能是经过刷选,过滤,复杂计算得出的,这个时候维护麻烦,每次写入数据库,都得更新缓存,重复计算,刷选。并且不一定是更新一张表的数据要更新缓存,可能缓存跟多张表的数据有关系。
解决办法:加分布式锁,操作串行化,因为更新场景很少,数据只读,不会影响性能。
- 数据库更新成功,缓存更新失败,数据不一致
解决办法:
1.返回前端页面失败,让前端重试,两次失败概率很小
2.通过MQ保证数据的最终一致性
2.2 先删除缓存,再更新数据库
这种方案在我们实际中使用较多,大部分都能容忍可能出现的脏数据的业务,及时出现脏数据,缓存过期后,也会读取最新的值。
方案分析:
存在的问题
存在脏数据的可能,比如线程A删除缓存,线程B查询缓存不存在数据,从数据库获取,获取成功后,数据存入缓存,现在A更新数据。这样缓存中的数据就是脏数据了。
解决办法:实际就是并发的问题
对于修改频繁的情况,采用双删
# 删除缓存
redisConn.delete("cacheKey")
# 更新数据库
db.execute("update t set count = count +1 where id = 10")
# 延时删除缓存
sleep(1000)
redisConn.delete("cacheKey")
这种方案有以下缺点:
多次操作redis删除key
延时删除,导致接口性能不高,影响接口吞吐量
第二次可能删除失败,还是存在问题
解决方案,异步删除时可以使用MQ消息队列(比如RocketMq的延时消息),确保删除成功,删除失败则重试,这种方案对业务代码影响大,造成大量的侵入,并且MQ也可能存在消息堆积,删除延迟过长的问题。
2.3 先更新数据库,再删除缓存
先更新数据库,再删除缓存。这种方案虽然也会出现脏数据,但是概率极低,而且redis也有过期时间,能够保证最终一致性。
方案分析:
存在的问题
请求A查询数据库,得一个旧值,请求B将新值写入数据库,请求B删除缓存,请求A将查到的旧值写入缓存。这种情况下会存在脏数据。
出现这种问题的概率极低,除非是查询比写入慢。要解决也可以采用异步延时删除。说实话如果对于这种极低概率的脏数据都不能容忍,建议不需要使用缓存了。毕竟现在大部分都是读写分离,主从还存在延时呢。这种要强一致性的建议走mysql。对msql进行扩容比如分库分表,读写分离等等。
当然非得使用缓存又要保存数据强一致性,也有办法。采用消息队列异步删除,采用binlog同步缓存数据,删除缓存,不过这种方案代码侵入大,维护难,大部分都采用方案三。
# 更新数据库
db.execute("update t set count = count +1 where id = 10")
# 删除缓存
redisConn.delete("cacheKey")
缓存强一致性方案流程如下:
 另一种方案:
另一种方案:
通过MQ串行化数据修改操作,需要评估影响

3. 总结
在评估对并发和性能影响后,通过锁避免并发问题,通过 mq,双删,设置有效期尽可能保证数据最终一致性。