Elasticsearch从入门到精通
Elasticsearch简介
应用开发中一个比较常见的功能是搜索,传统应用的解决方案:数据库的模糊查询。
模糊查询存在的问题:
- 海量数据下效率低下
- 功能不够丰富:不够智能、不能高亮
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。能够在海量的结构化和非结构化的数据中进行快速搜索,帮助我们完成诸如 订单搜索、商品推荐、日志分析、性能监控 等功能。
和Elasticsearch类似的产品还有Apache组织开源的Solr ,Solr和Elasticsearch都是基于Lucene这个Java类库二次开发而成的框架。Solr在功能性、传统搜索应用方面的表现更好,Elasticsearch则在新兴的实时搜索表现更佳。Solr的发展一直都比较平稳,近些年来呈现渐渐的下降趋势,而Elasticsearch则呈现明显上升的趋势。
Elasticsearch的特点:
- Elasticsearch是基于Lucene(Java全文检索工具)的开发的搜索引擎
- Elasticsearch支持分布式,多用户访问,可以轻松的扩展到上百台服务器
- Elasticsearch是近实时的不是实时的搜索引擎,简单说插入一条新数据后并不能保证立刻搜索到,但保证在1s内一定可以搜索到
- Elasticsearch通过简单的RESTful API来隐藏Lucene的复杂性,使得全文检索变得简单
- Elasticsearch使用JSON格式存储数据
接下来就来讲解一下Elasticsearch的安装使用
Elasticsearch安装
- 安装elasticsearch首先需要安装jdk环境
(如何安装jdk可以查阅博主之前的文章的前三步Tomcat的安装及配置) - 修改配置文件limits.conf
vi /etc/security/limits.conf
在最后一行添加下面内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
- 修改sysctl.conf
vi /etc/sysctl.conf
最后一行添加
vm.max_map_count=262144
运行该命令让sysctl生效
sysctl -p
- 把es安装包上传到opt文件夹里面进行解压
下载链接:https://pan.baidu.com/s/1_fnyYhUkM-m3QPIQK6xcEg
提取码:iw14
tar -zxvf elasticsearch-6.4.1.tar.gz
- 修改es的配置文件允许远程访问
[root@localhost config]# vi elasticsearch.yml
将55行
#network.host: 192.168.0.1
改为:
network.host: 0.0.0.0
注意去除前面的#
-
尝试启动es:

es不能使用root用户启动。我们需要添加其他用户。 -
添加es用户,修改es文件夹的所属用户为es,elasticsearch不能使用root用户启动。


所以我们需要通过linux的权限命令对文件夹进行修改所属用户。 -
使用es用户登录到linux里面,启动es

Elasticsearch使用操作
REST 回顾
REST(Resource Representational State Transfer)资源在网络传输中以某种表现形式进行状态转移。
REST风格的URI:
- 面向资源
- 通过HTTP的请求方式对资源进行操作
HTTP请求方式:
- GET 对资源的查询
- POST 对资源的新增或者更新
- PUT 对资源的更新或者新增
- DELETE 对资源的删除
RESTful API操作Elasticsearch
Elasticsearch数据相关的概念:
- 文档:json格式的数据,类似关系型数据库的一行数据。每个文档都会有唯一的id,可以由es生成,也可以由程序员指定
- 字段:每一个文档中的数据字段就相当于关系型数据库中一行的列
- 类型:Elasticsearch中保存数据的容器,类似于MySQL中的表
- 索引:保存有类型,类似于mysql的数据库。
| 序号 | Elasticsearch | mysql |
|---|---|---|
| 1 | 索引 | 库 |
| 2 | 类型 | 表 |
| 3 | 文档 | 行 |
| 4 | 字段 | 列 |
为方便大家前期对Elasticsearch的数据有一个大体的认识,可以类比关系型数据库的一些概念,但注意2者之间有本质差别不可等价齐观。(ES里一个索引只能有一个类型,而mysql里面一个库里面可以有许多表)
在这里再给大家推荐一个操作es的软件postman(博主在这里提供的是破解版,仅供个人学习使用,另外不要更新软件否则可能会收费)
下载链接:https://pan.baidu.com/s/1f-n7KqjOdISYyDEYnWbI2Q
提取码:0nsi
创建和删除索引
- 创建索引和类型:
PUT /索引名
{
"mappings":{
"类型名":{
"properties":{
"字段名":{
"type":"字段类型"
},
"字段名":{
"type":"字段类型"
}
}
}
}
}
字段类型:
字符串:keyword,text
数值类型:long,integer,short,byte,double,float
布尔:boolean
日期:date
二进制:binary
案例:
PUT http://192.168.240.137:9200/bookshop
{
"mappings":{
"book":{
"properties":{
"name":{
"type":"keyword"
},
"price":{
"type":"double"
},
"date":{
"type":"date"
}
}
}
}
}

- 查看索引
GET /索引名/_mappings
案例:
GET http://192.168.240.137:9200/bookshop/_mappings
结果:
{
"bookshop": {
"mappings": {
"book": {
"properties": {
"date": {
"type": "date"
},
"name": {
"type": "keyword"
},
"price": {
"type": "double"
}
}
}
}
}
}

- 删除索引
DELETE /索引名
案例:
DELETE http://192.168.240.137:9200/bookshop
{
"acknowledged": true
}

补充一下:
删除所有索引
DELETE http://192.168.240.137:9200/*
- 查询当前所有的索引
GET http://192.168.240.137:9200/_cat/indices?v

添加(修改)和删除文档
- 添加文档
POST http://192.168.240.137:9200/bookshop/book/1
{
"name":"西游记",
"price":10,
"date":"2012-12-12"
}

其中id也可以不添加,系统会自动给我们创建一个id值。补充一下,如果索引和文档不存在,系统也会自动给我们创建。如果字段不存在,系统也会自动添加。
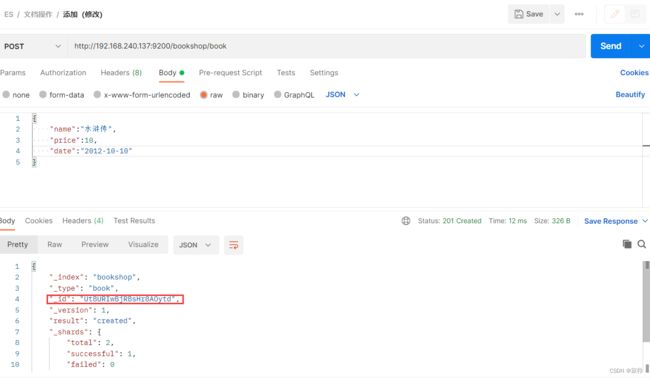
由es分配id
POST http://192.168.240.137:9200/bookshop/book
{
"name":"水浒传",
"price":10,
"date":"2012-10-10"
}
#指定文档的id
POST http://192.168.240.137:9200/bookshop/book/2
{
"name":"三国演义",
"price":10,
"date":"2023-11-12"
}

-
查询文档
GET /索引/类型/id值
案例:
示例:
查看全部
GET http://192.168.240.137:9200/bookshop/book/_search
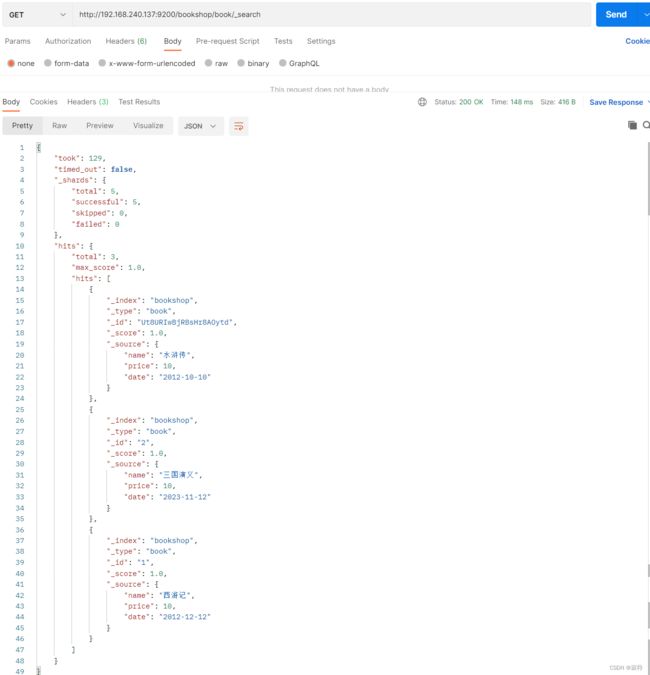
查看id为1的数据
GET http://192.168.240.137:9200/bookshop/book/1

-
删除文档
DELETE /索引/类型/id
案例:
DELETE http://192.168.240.137:9200/bookshop/book/Ut8URIwBjRBsHr8AOytd

- 更新(修改)文档
POST /索引/类型/id
POST http://192.168.240.137:9200/bookshop/book/2
{
"name":"三国",
"price":10,
"date":"2023-11-12",
"product_address":"made in China"
}

这里的更新(修改)会直接覆盖掉原来的,如果字段不存在,会新建。
批量操作
批量写 _bulk
Bulk API支持在一次请求中,可以对任意的索引执行多种不同的写操作。
PUT /_bulk
{操作类型以及操作的索引 类型 文档id信息}
{操作用到的数据}
注意最后必须添加一个空行
案例:
PUT http://192.168.146.40:9200/_bulk
{"index":{"_index":"dangdang","_type":"book","_id":"1"}}
{"bookName":"红楼梦","author":"曹雪芹","price":19800.0}
{"update":{"_index":"dangdang","_type":"book","_id":"1"}}
{"doc":{"price":"1980.0"}}
{"create":{"_index":"dangdang","_type":"book","_id":"2"}}
{"bookName":"水浒传","author":"施耐庵"}
{"delete":{"_index":"dangdang","_type":"book","_id":"3"}}
注意:
- json数据不能主动换行,必须写成一行
- 多个json间必须要换行
- 在文件中json串最后一行下方必须再有一个空行
扩展:
如果在URI路径上指定了索引和类型,那么操作时json串中的条件可以省略对应的值,上面的操作也可以写成如下所示:
PUT http://192.168.146.40:9200/dangdang/book/_bulk
{"index":{"_id":"1"}}
{"bookName":"红楼梦","author":"曹雪芹","price":19800.0}
{"index":{"_id":"1"}}
{"doc":{"price":"1980.0"}}
{"create":{"_id":"2"}}
{"bookName":"水浒传","author":"施耐庵"}
{"delete":{"_id":"3"}}
操作中单条操作的失败,不会影响其它操作。返回结果中包含了每一条操作的结果(成功或者失败)。
批量读 _mget
可以一次性的查询多个数据,减少网络连接产生的开销,提高性能。
GET /_mget
{
"docs":[
{索引 类型 等信息},
...
]
}
案例:
GET http://192.168.146.40:9200/_mget
{
"docs":[
{
"_index":"dangdang",
"_type":"book",
"_id":1
},
{
"_index":"dangdang",
"_type":"book",
"_id":2
}
]
}
如果在URI路径上指定了索引和类型,那么操作时json串中的条件可以省略对应的值,上面的操作也可以写成如下所示:
GET http://192.168.146.40:9200/dangdang/book/_mget
{
"docs":[
{"_id":1},
{"_id":2}
]
}
Elasticsearch高级检索DSL检索
不安装其他插件的情况下,es默认是不支持中文的分词查询的
准备测试数据:
添加索引并设置类型
PUT /ems
{
"mappings":{
"emp":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"integer"
},
"bir":{
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || yyyy/MM/dd HH:mm:ss|| yyyy/MM/dd ||epoch_millis"
},
"content":{
"type":"text"
},
"address":{
"type":"keyword"
}
}
}
}
}
PUT /ems/emp/_bulk
{"index":{"_id":1}}
{"name":"小黑","age":23,"bir":"2012-12-12","content":"为开发团队选择一款优秀的MVC框架是件难难事,在众多可行的方案中决择需要很高的经验和水平","address":"北京"}
{"index":{"_id":2}}
{"name":"王小黑","age":24,"bir":"2012-12-12","content":"Spring 框架是一个分层架构,由 7 个定义良好的模块组成。Spring 模块构建在心容器之上,核心容器定义了创建、配置和管理 bean 的方式。为了测试添加一个内容北京","address":"上海"}
{"index":{"_id":3}}
{"name":"张小五","age":8,"bir":"2012-12-12","content":"SpringCloud作为Java语言的微服务框架,它依赖于Spring Boot,有快速开发、持续交付和容易部署等特点。SpringCloud的组件非常多,涉及微服务的方方面面,并在开源社区Spring 和Netflix、Pivotal 两大公司的推动下越来越完善","address":"无锡"}
{"index":{"_id":4}}
{"name":"win7","age":9,"bir":"2012-12-12","content":"Spring的目标是致力于全方位的简化Java开发。 这势必引出更多的解释,Spring是如何简化Java开发的?","address":"南京"}
{"index":{"_id":5}}
{"name":"梅超风","age":43,"bir":"2012-12-12","content":"Redis一个开源的使 用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API","address":"杭州"}
{"index":{"_id":6}}
{"name":"张无忌","age":59,"bir":"2012-12-12","content":"ElasticSearch是一个 基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口","address":"北京"}
from和size(分页查询)
form和size等同于MySQL中limit后的2个数值,借助这2个属性可以完成分页。
GET /ems/emp/_search
{
"query":{"match_all":{}},
"from":3,
"size":3,
"sort":[
{"age":{"order": "desc"}}
]
}


sort(排序)
sort属性值是一个数组,表示可以设定多个字段的排序
{
"sort":[
{"字段1":{"order":"asc|desc"}},
{"字段2":{"order":"asc|desc"}}
]
}
上述语法也可以简化如下:
{
"sort":[
{"字段1":"asc|desc"},
{"字段2":"asc|desc"}
]
}
案例:
GET /ems/emp/_search
{
"query":{"match_all":{}},
"sort":[
{"address":{"order":"desc"}},
{"age":{"order": "asc"}}
]
}
{
"query":{"match_all":{}},
"sort":[
{"address":"desc"},
{"age":"asc"}
]
}


_source(查询指定字段)
_source是一个数组,指定要显示的字段。
{
"_source":["字段名1","字段名2",...]
}
案例:
GET /ems/emp/_search
{
"query": {
"match_all": {}
},
"_source":["name","age"]
}


query(查询规则)
query用于设置查询规则,Elasticsearch中有多种查询规则
{
"query":{
"match_all":{},//匹配所有
"match":{},//分词查询
"term":{},//关键字查询
"range":{},//范围查询
"prefix":{},//前缀查询
"wildcard":{},//通配符查询
"ids":{},//多id查询
"fuzzy":{},//模糊查询
"bool":{},//bool查询
"multi_match":{}//多字段查询
}
}
我们选几种常见的进行讲解
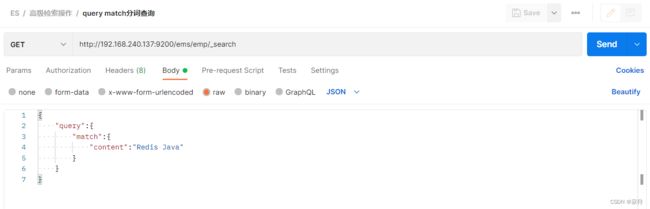
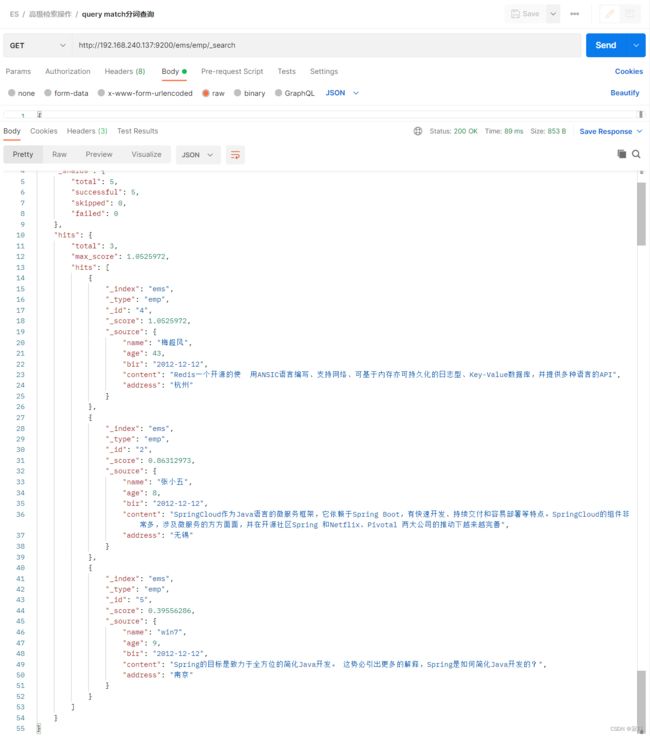
match(分词查询)
match 匹配查询,会对条件分词后查询
GET /ems/emp/_search
{
"query":{
"match":{
"content": "Redis Java"
}
}
}
term (关键字查询)
term 关键字: 用来使用关键词查询,不会对条件分词
GET /ems/emp/_search
{
"query":{
"term":{
"content":{
"value":"spring" //注意字母必须小写;如果出现大写字母,查询不到结果
}
}
}
}


range(范围查询)
range 关键字: 用来指定查询指定范围内的文档
GET /ems/emp/_search
{
"query":{
"range":{
"age":{
"gte":40, // greater than equals
"lt":80 // less than
}
}
}
}

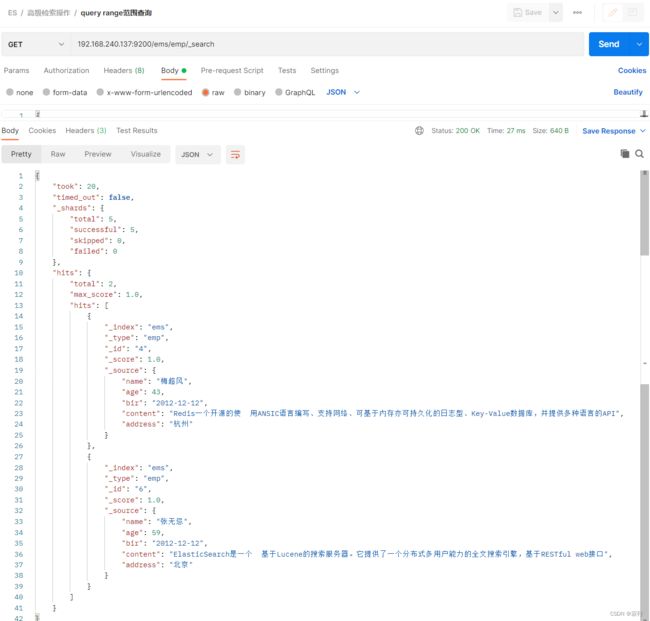
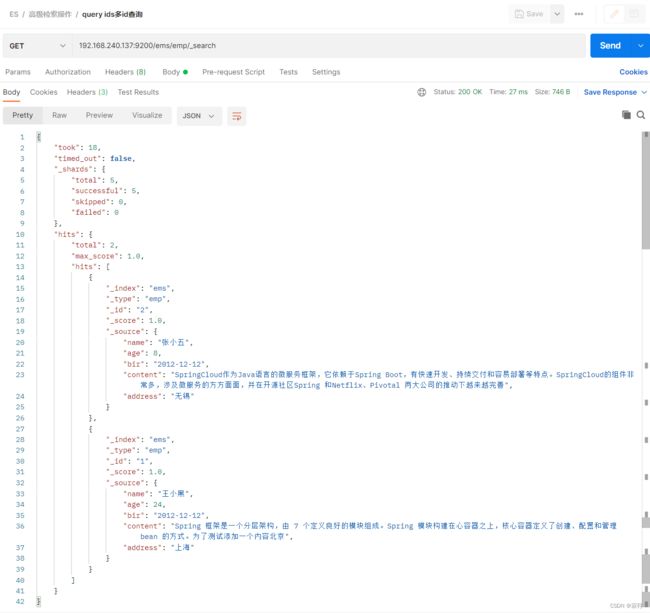
ids(多id查询)
GET /ems/emp/_search
{
"query":{
"ids":{
"values":["1","2"]
}
}
}

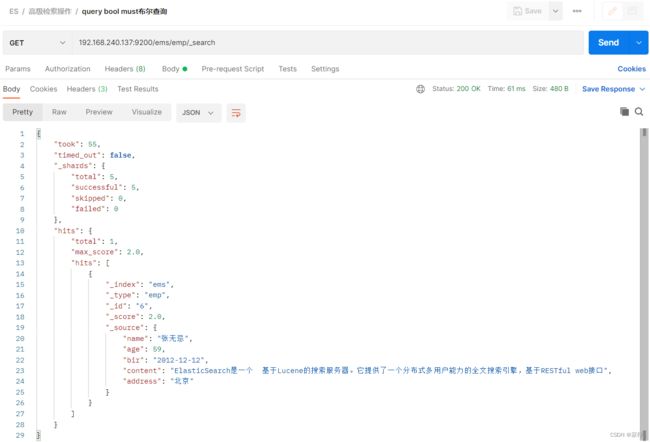
bool(布尔查询)
bool查询:bool查询用于合并多个查询条件
bool查询中有must、should、must_not3个关键字
must:相当于java中的&&,所有条件必须同时满足
should:相当于java中||,任一条件满足即可
must_not:相当于java中的!,取反操作
- must示例:
GET /ems/emp/_search
{
"query":{
"bool":{
"must":[
{ //查询地址以北作为前缀的
"prefix":{
"address":{
"value":"北"
}
}
},{
"range":{
"age":{
"gte":40
}
}
}
]
}
}
}

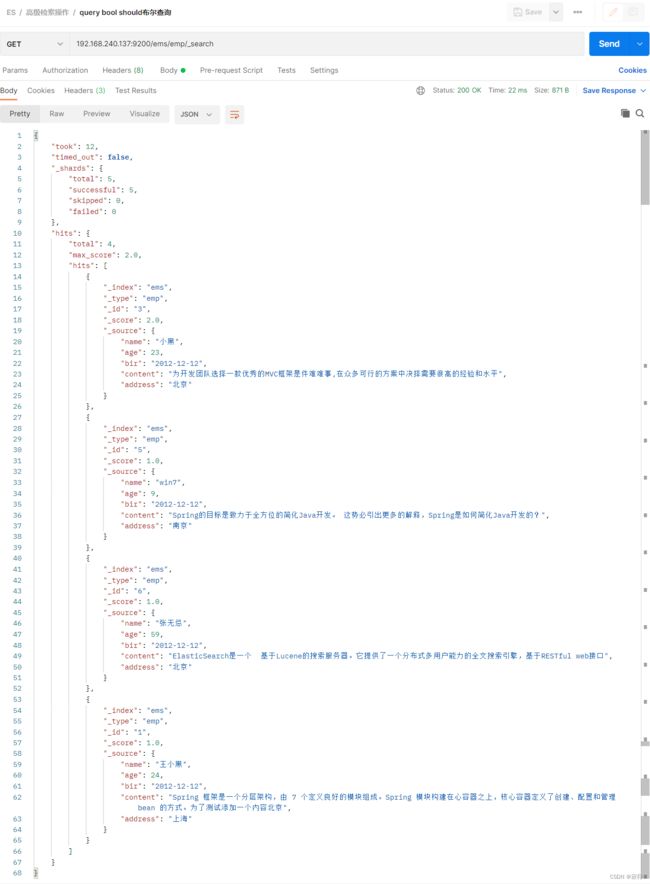
- should示例
GET /ems/emp/_search
{
"query":{
"bool":{
"should":[
{
"prefix":{
"address":{
"value":"北"
}
}
},{
"ids":{
"values":["1","3","5"]
}
}
]
}
}
}

- must_not示例
GET /ems/emp/_search
{
"query":{
"bool":{
"must_not":[
{
"prefix":{
"address":{
"value":"北"
}
}
},{
"term":{
"content":{
"value":"spring"
}
}
}
]
}
}
}


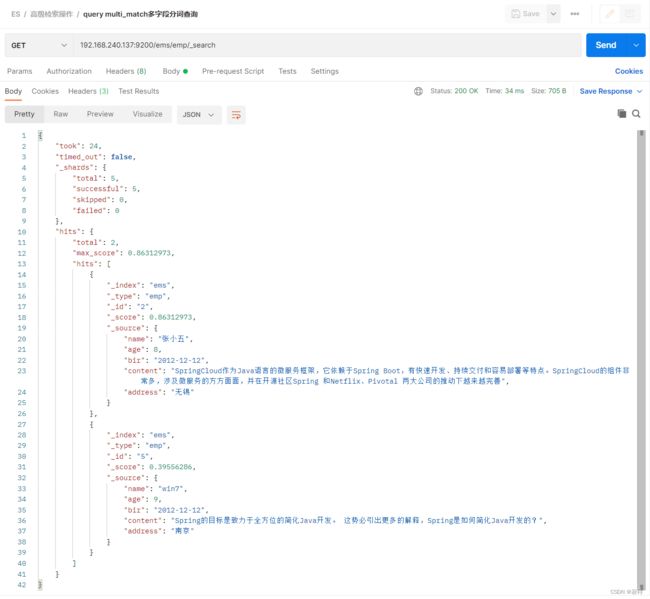
multi_match(多字段分词查询)
muli_match用于在多个字段中分词查询
GET /ems/emp/_search
{
"query":{
"multi_match":{
"query":"张黑java",
"fields":["name","content"]
}
}
}

高亮查询
hightlight用于在查询关键字上添加样式,以达到高亮显示的效果。
GET /ems/emp/_search
{
"query":{
"multi_match":{
"query":"张黑java",
"fields":["name","content"]
}
},
"highlight":{
"fields":{
"content":{},
"name":{}
},
"pre_tags":[""],
"post_tags":[""]
}
}

