Java高级API-XML,JSON和正则表达式
Java高级API-XML,JSON和正则表达式
-
- XML
-
- XML简介
- XML约束
- XML解析
- DOM解析
- DOM常用接口
- JSON
-
- 什么是JSON
- JSON语法
- Java处理JSON
- 正则表达式
-
- 概述
- 单个符号
- 快捷符号
- 常用正则表达式
-
- 元字符及其在正则表达式上下文中的行为:
- 汇总整理:
XML
XML简介
1.功能:用来存储数据,并且能够对数据进行增删改查的操作。
2.与HTML的区别:1)xml主要用来存储数据,而HTML主要用来展示数据;
2)xml的语法格式非常严格,HTML的语法格式非常松散;
3)xml标签名称全部都是自定义的,而HTML的标签是预定义的。
3.xml的基本格式:
<?xml version = '1.0'?>
<根标签>
<user id='1'>
<name>zhangsan</name>
<age>20</age>
<sex>male</sex>
</user>
<user id='2'>
<name>lisi</name>
<age>18</age>
<sex>female</sex>
</user>
</根标签>
XML约束
分类:1.DTD约束(比较简单,约束性较低) 2.Schema约束(约束性强,较为复杂)
基本组成部分:1.文档申明(必须写在第一行,并且前面不能有空格)
2.指令(结合CSS样式)
3.标签
4.属性
5.文本
DTD约束的两种定义方式:
1.外部引入(本地):<!DOCTYPE 根标签名 SYSTEM "dtd文件的位置">
2.外部引入(网络):<!DOCTYPE 根标签名 PUBLIC “自定义文件名称 " dtd文件的URL">
XML解析
分类:1.DOM解析 2.SAX解析
操作方式和优缺点:
1.操作方式
DOM:一次性将整个文档加载进内存,然后在内存中形成DOM树结构,可以对其进行增删改查的操作。
SAX:逐行读取文档进内存,每读取完一行就释放一行。
2.优缺点
DOM:优点:能够对解析的文档进行增删改的操作。缺点:占用内存较大
SAX:优点:几乎不占内存。缺点:只能读取解析的文档。
DOM解析
1. 建立DocumentBuilderFactor,用于获得DocumentBuilder对象:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
2. 建立DocumentBuidler:
DocumentBuilder builder = factory.newDocumentBuilder();
3. 建立Document对象,获取树的入口:
Document doc = builder.parse(“xml文件的相对路径或者绝对路径”);
4. 建立NodeList:
NodeList n1 = doc.getElementByTagName(“读取节点”);
5. 进行xml信息获取
代码:
public class TestXML {
Document dom;
public void getDocument(String path){
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
dom = builder.parse(new FileInputStream(path));
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (FileNotFoundException e){
e.printStackTrace();
} catch (IOException e){
e.printStackTrace();
} catch (SAXException e){
e.printStackTrace();
}
}
public void getBrands(){
getDocument("resources/phones.xml");
NodeList brand = dom.getElementsByTagName("brand");
for (int i = 0;i< brand.getLength();i++){
Node item = brand.item(i);
Element e = (Element)item;
System.out.println(e.getAttribute("name"));
NodeList children = e.getChildNodes();
for (int j = 0;j<children.getLength();j++){
Node child = children.item(j);
if (child instanceof Element){
Element ele = (Element) child;
System.out.println("\t" + ele.getAttribute("name"));
NodeList grandsons = ele.getChildNodes();
for (int z = 0;z<grandsons.getLength();z++){
Node grandson = grandsons.item(z);
if (grandson instanceof Text){
Text t = (Text)grandson;
System.out.println("\t\t----" + t.getWholeText());
}
}
}
}
}
}
public void getInfo(){
getDocument("resources/phones.xml");
NodeList types = dom.getElementsByTagName("type");
for (int i = 0;i<types.getLength();i++){
Node item = types.item(i);
if (item instanceof Element){
Element e = (Element)item;
System.out.println(e.getAttribute("name"));
}
}
}
public void saveXml(String path){
getDocument("resources/phones.xml");
Node root = dom.getElementsByTagName("PhoneInfo").item(0);
//Document d = DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument();
Element brand = dom.createElement("brand");
//Document child = DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument();
brand.setAttribute("name","Samsung");
Element e1 = dom.createElement("type");
Element e2 = dom.createElement("type");
e1.setAttribute("name","Note30");
e2.setAttribute("name","Galaxy");
Text t1 = dom.createTextNode("1300");
Text t2 = dom.createTextNode("200");
e1.appendChild(t1);
e2.appendChild(t2);
brand.appendChild(e1);
brand.appendChild(e2);
root.appendChild(brand);
TransformerFactory factory = TransformerFactory.newInstance();
try {
Transformer transformer = factory.newTransformer();
DOMSource source = new DOMSource(dom);
StreamResult result = new StreamResult(new FileOutputStream(path));
transformer.transform(source,result);
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (FileNotFoundException e){
e.printStackTrace();
} catch (TransformerException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
TestXML t = new TestXML();
t.getBrands();
t.saveXml("changed.xml");
}
DOM常用接口

JSON
什么是JSON
- JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)。
- JSON 是轻量级的文本数据交换格式。
- SON 独立于语言:JSON 使用 Javascript语法来描述数据对象,但是 JSON 仍然独立于语言和平台。JSON 解析器和 JSON 库支持许多不同的编程语言。 目前非常多的动态(PHP,JSP,.NET)编程语言都支持JSON。
- JSON 具有自我描述性,更易理解
JSON语法
JSON 语法是 JavaScript 对象表示语法的子集。
· 数据在名称/值对中
· 数据由逗号分隔
· 大括号保存对象
· 中括号保存数组
1.表示一个对象
{"name":'"zhangsan","age":22}
{"name":"lisi","addr":{"city":"jinan","street":"huayuanlu"}}
属性名要添加引号
属性值如果是字符串,要添加引号
数据类型:string,number,boolean,null,object
2.表示一个对象数组
[{},{},{}]
Java处理JSON
1.首先引入json的jar包
2.
// 对象转换为json字符串
Student st = new Student();
st.setId(1);
st.setAge(22);
st.setName("张三s");
st.setAddr("jinan");
JSONObject obj = JSONObject.fromObject(st);
String str = obj.toString();
System.out.println(str);// {"addr":"jinan","age":22,"id":1,"name":"张三s"}
// 数组对象转换位json字符串
Student s1 = new Student(2, 22, "李四", "济宁");
Student s2 = new Student(3, 23, "王五", "青岛");
Student s3 = new Student(4, 24, "赵六", "上海");
Student[] ssarr = { s1, s2, s3 };
JSONArray obj1 = JSONArray.fromObject(ssarr);
String str1 = obj1.toString();
System.out.println(str1);
// list对象转换为json字符串
Student s11 = new Student(2, 22, "李四1", "济宁1");
Student s22 = new Student(3, 23, "王五1", "青岛1");
Student s33 = new Student(4, 24, "赵六1", "上海1");
List<Student> sslist = new ArrayList<Student>();
sslist.add(s11);
sslist.add(s22);
sslist.add(s33);
JSONArray obj2 = JSONArray.fromObject(sslist);
String str2 = obj2.toString();
System.out.println(str2);
java 用于处理json的库很多。json-lib,jackson,fastjson,gson。json-lib性能最低,fastjson性能最高,这里介绍下fastjson。主要接口如下:
public static final Object parse(String text); // 把JSON文本parse为JSONObject或者JSONArray
*public static final JSONObject parseObject(String text); // 把JSON文本parse成JSONObject
*public static final T parseObject(String text, Class clazz); // 把JSON文本parse为JavaBean
*public static final JSONArray parseArray(String text); // 把JSON文本parse成JSONArray
*public static final List parseArray(String text, Class clazz); //把JSON文本parse成JavaBean集合
*public static final String toJSONString(Object object); // 将JavaBean序列化为JSON文本
public static final String toJSONString(Object object, boolean prettyFormat); // 将JavaBean序列化为带格式的JSON文本
public static final Object toJSON(Object javaObject); //将JavaBean转换为JSONObject或者JSONArray。
代码:
package cn.kgc.kb11;
import com.alibaba.fastjson.JSON;
import sun.text.resources.nl.JavaTimeSupplementary_nl;
/**
* @Author ZhangPeng
* @Date 2021/2/22
* @Description
*/
public class TestJson {
public static void main(String[] args) {
String s = "{\"name\":\"张三\",\"id\":\"1\",\"age\":\"18\",\"gender\":\"男\"}";
Object o = JSON.toJSON(s);
System.out.println(o);
Student stu = new Student(2,"李四",28,"女");
Object o1 = JSON.toJSON(stu);
System.out.println(o1);
String jsonStr = JSON.toJSONString(stu);
System.out.println(jsonStr);
// Object o2 = JSON.parse(jsonStr);
// if (o2 instanceof Student){
// System.out.println(o2);
// }
Student student = JSON.parseObject(s, Student.class);
System.out.println(student.getName());
}
}
效果图:

正则表达式
概述
用来描述或者匹配一系列符合某个语句规则的字符串。
单个符号
1、英文句点.符号:匹配单个任意字符。
表达式t.o 可以匹配:tno,t#o,teo等等。不可以匹配:tnno,to,Tno,t正o等。
2、中括号[]:只有方括号里面指定的字符才参与匹配,也只能匹配单个字符。
表达式:t[abcd]n 只可以匹配:tan,tbn,tcn,tdn。不可以匹配:thn,tabn,tn等。
3、| 符号。相当与“或”,可以匹配指定的字符,但是也只能选择其中一项进行匹配。
表达式:t(a|b|c|dd)n 只可以匹配:tan,tbn,tcn,tddn。不可以匹配taan,tn,tabcn等。
4、表示匹配次数的符号
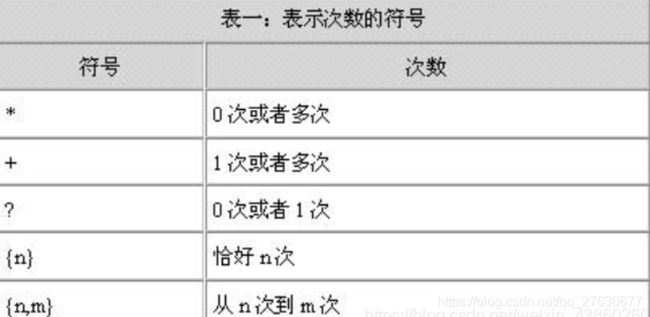
表达式:[0—9]{ 3 } \— [0-9]{ 2 } \— [0-9]{ 3 } 的匹配格式为:999—99—999
因为—符号在正则表达式中有特殊的含义,它表示一个范围,所以在前面加转义字符\。
5、符号:表示否,如果用在方括号内,表示不想匹配的字符。
表达式:[^x] 第一个字符不能是x
6、\S符号:非空字符
7、\s符号:空字符,只可以匹配一个空格、制表符、回车符、换页符,不可以匹配自己输入的多个空格。
8、\r符号:空格符,与\n、\tab相同
快捷符号
1、\d表示[0—9]
2、\D表示[^0—9]
3、\w表示[0—9A—Z_a—z]
4、\W表示[^0—9A—Z_a—z]
5、\s表示[\t\n\r\f]
6、\S表示[^\t\n\r\f]
常用正则表达式
^\d+$ :非负整数(正整数 + 0)
^[0-9]*[1-9][0-9]*$ :正整数
^((-\d+)|(0+))$ :非正整数(负整数 + 0)
^-[0-9]*[1-9][0-9]*$ :负整数
^-?\d+$ :整数
^\d+(\.\d+)?$ :非负浮点数(正浮点数 + 0)
^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$ :正浮点数
^((-\d+(\.\d+)?)|(0+(\.0+)?))$ :非正浮点数(负浮点数 + 0)
^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$ :负浮点数
^(-?\d+)(\.\d+)?$ :浮点数
^[A-Za-z]+$ :由26个英文字母组成的字符串
^[A-Z]+$ :由26个英文字母的大写组成的字符串
^[a-z]+$ :由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ :由数字和26个英文字母组成的字符串
^\w+$ :由数字、26个英文字母或者下划线组成的字符串
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$ :email地址
^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$ :url
/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ :年-月-日
/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ :月/日/年
^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$ :Emil
/^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9]+)?$/ :电话号码
^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$ :IP地址
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
匹配空行的正则表达式:\n[\s| ]*\r
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})?
匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$
元字符及其在正则表达式上下文中的行为:
\ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个后向引用、或一个八进制转义符。
^ 匹配输入字符串的开始位置。如果设置了 RegExp 对象的Multiline 属性,^ 也匹配 \n或 \r之后的位置。
$ 匹配输入字符串的结束位置。如果设置了 RegExp 对象的Multiline 属性,$ 也匹配 \n或 \r之前的位置。
* 匹配前面的子表达式零次或多次。
+ 匹配前面的子表达式一次或多次。+ 等价于 {1,}。
? 匹配前面的子表达式零次或一次。? 等价于 {0,1}。
{n} n 是一个非负整数,匹配确定的n 次。
{n,} n 是一个非负整数,至少匹配n 次。
{n,m} m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。在逗号和两个数之间不能有空格。
? 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。
. 匹配除 \n之外的任何单个字符。要匹配包括 \n 在内的任何字符,请使用象 [.\n]的模式。
(pattern) 匹配pattern 并获取这一匹配。
(?:pattern) 匹配pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。
(?=pattern) 正向预查,在任何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
(?!pattern) 负向预查,与(?=pattern)作用相反
x|y 匹配 x 或 y。
[xyz] 字符集合。
[^xyz] 负值字符集合。
[a-z] 字符范围,匹配指定范围内的任意字符。
[^a-z] 负值字符范围,匹配任何不在指定范围内的任意字符。
\b 匹配一个单词边界,也就是指单词和空格间的位置。
\B 匹配非单词边界。
\cx 匹配由x指明的控制字符。
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\f 匹配一个换页符。等价于 \x0c 和 \cL。
\n 匹配一个换行符。等价于 \x0a 和 \cJ。
\r 匹配一个回车符。等价于 \x0d 和 \cM。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\t 匹配一个制表符。等价于 \x09 和 \cI。
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w 匹配包括下划线的任何单词字符。等价于[A-Za-z0-9_]。
\W 匹配任何非单词字符。等价于 [^A-Za-z0-9_]。
\xn 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。
\num 匹配 num,其中num是一个正整数。对所获取的匹配的引用。
\n 标识一个八进制转义值或一个后向引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为后向引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值
\nm 标识一个八进制转义值或一个后向引用。如果 \nm 之前至少有is preceded by at least nm 个获取得子表达式,则 nm 为后向引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的后向引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm
\nml 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml
\un 匹配 n,其中 n 是一个用四个十六进制数字表示的Unicode字符。
匹配中文字符的正则表达式: [u4e00-u9fa5]
匹配双字节字符(包括汉字在内):[^x00-xff]
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/<(.*)>.*|<(.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
汇总整理:
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
匹配双字节字符(包括汉字在内):[^\x00-\xff]
匹配空行的正则表达式:\n[\s| ]*\r
匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/
匹配首尾空格的正则表达式:(^\s*)|(\s*$)
匹配IP地址的正则表达式:/(\d+)\.(\d+)\.(\d+)\.(\d+)/g //
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
匹配网址URL的正则表达式:http://(/[\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?
sql语句:^(select|drop|delete|create|update|insert).*$
非负整数:^\d+$
正整数:^[0-9]*[1-9][0-9]*$
非正整数:^((-\d+)|(0+))$
负整数:^-[0-9]*[1-9][0-9]*$
整数:^-?\d+$
非负浮点数:^\d+(\.\d+)?$
正浮点数:^((0-9)+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
非正浮点数:^((-\d+\.\d+)?)|(0+(\.0+)?))$
负浮点数:^(-((正浮点数正则式)))$
英文字符串:^[A-Za-z]+$
英文大写串:^[A-Z]+$
英文小写串:^[a-z]+$
英文字符数字串:^[A-Za-z0-9]+$
英数字加下划线串:^\w+$
E-mail地址:^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
URL:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$ 或者:^http:\/\/[A-Za-z0-9]+\.[A-Za-z0-9]+[\/=\?%\-&_~@[\]\':+!]*([^<>\"\"])*$
邮政编码:^[1-9]\d{5}$
中文:^[\u0391-\uFFE5]+$
电话号码:^((\(\d{2,3}\))|(\d{3}\-))?(\(0\d{2,3}\)|0\d{2,3}-)?[1-9]\d{6,7}(\-\d{1,4})?$
手机号码:^((\(\d{2,3}\))|(\d{3}\-))?13\d{9}$
双字节字符(包括汉字在内):^\x00-\xff
匹配首尾空格:(^\s*)|(\s*$)(像vbscript那样的trim函数)
匹配HTML标记:<(.*)>.*<\/\1>|<(.*) \/>
匹配空行:\n[\s| ]*\r
提取信息中的网络链接:(h|H)(r|R)(e|E)(f|F) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的邮件地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
提取信息中的图片链接:(s|S)(r|R)(c|C) *= *('|")?(\w|\\|\/|\.)+('|"| *|>)?
提取信息中的IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
提取信息中的中国手机号码:(86)*0*13\d{9}
提取信息中的中国固定电话号码:(\(\d{3,4}\)|\d{3,4}-|\s)?\d{8}
提取信息中的中国电话号码(包括移动和固定电话):(\(\d{3,4}\)|\d{3,4}-|\s)?\d{7,14}
提取信息中的中国邮政编码:[1-9]{1}(\d+){5}
提取信息中的浮点数(即小数):(-?\d*)\.?\d+
提取信息中的任何数字 :(-?\d*)(\.\d+)?
IP地址:(\d+)\.(\d+)\.(\d+)\.(\d+)
电话区号:/^0\d{2,3}$/
腾讯QQ号:^[1-9]*[1-9][0-9]*$
帐号(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
中文、英文、数字及下划线:^[\u4e00-\u9fa5_a-zA-Z0-9]+$
java代码:
public class TestRegex {
public static void main(String[] args) {
String s = "[email protected]";
Pattern p = Pattern.compile("\\w{6,}@\\w+\\.\\w+");
Matcher matcher = p.matcher(s);
if (matcher.matches()){
System.out.println(matcher.group());
}else {
System.out.println("没匹配!");
}
}
}