盘点!国内隐私计算学者在 USENIX Security 2023 顶会上的成果

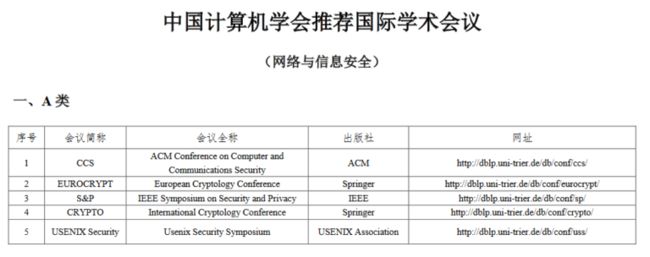
USENIX Security 是国际公认的网络安全与隐私计算领域的四大顶级学术会议之一、CCF(中国计算机学会) 推荐的 A 类会议。
每年的 USENIX Security 研讨会都会汇集大量研究人员、从业人员、系统管理员、系统程序员和其他对计算机系统、网络安全和隐私最新进展感兴趣的人。
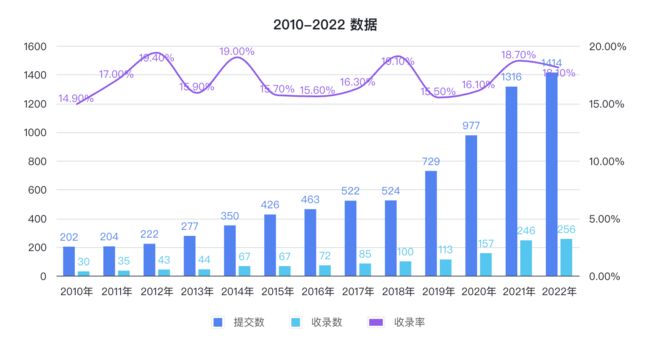
近日,在 2023 年 USENIX 安全研讨会(USENIX Security Symposium-2023)上,共计发表了隐私计算相关文章 51 篇,涉及联邦学习、同态加密、安全多方计算等多个隐私计算领域,作为网络安全与隐私计算领域的顶级会议,它的录取率常年低于 20%。
今年的会议上国内学者贡献了非常多的优秀成果,我们选取几个热门领域来简单盘点一下。
一、成果领域分布
| 成果领域 | 入选篇数 | 国内研究者参与优秀成果 |
|---|---|---|
| 差分隐私(DP) | 3 | Fine-grained Poisoning Attack to Local Differential Privacy Protocols for Mean and Variance Estimation (第一作者:西安电子科技大学) |
| 可信执行环境(TEE) | 4 | CIPHERH: Automated Detection of Ciphertext Side-channel Vulnerabilities in Cryptographic Implementations(第一作者:南方科技大学,其他成员来自香港科技大学、蚂蚁集团) Controlled Data Races in Enclaves: Attacks and Detection (第三作者:南方科技大学) |
| 联邦学习(FL) | 3 | Gradient Obfuscation Gives a False Sense of Security in Federated Learning (第二作者:浙江大学) |
| 零知识证明(ZK) | 2 | TAP: Transparent and Privacy-Preserving Data Services (第三作者:西南大学) |
| 同态加密(HE) | 3 | Squirrel: A Scalable Secure Two-Party Computation Framework for Training Gradient Boosting Decision Tree (全员来自阿里巴巴集团和蚂蚁集团) |
| 隐私集合计算(PSU) | 3 | Linear Private Set Union from Multi-Query Reverse Private Membership Test (全员来自中国科学院信息工程研究所信息安全国家重点实验室、中国科学院大学、山东大学、密码科学技术国家重点实验室、阿里巴巴集团) |
| 隐私数据分析 | 8 | Lalaine: Measuring and Characterizing Non-Compliance of Apple Privacy Labels (第四作者:阿里巴巴集团猎户座实验室) |
| AI 隐私增强 | 3 | V-CLOAK: Intelligibility-, Naturalness- & Timbre-Preserving Real-Time Voice Anonymization (成员来自浙江大学与武汉大学) |
二、热门领域盘点
注:因为篇幅有限,本文只列举了国内学者优秀成果的一部分内容。
2.1 差分隐私(DP)
- 论文:Fine-grained Poisoning Attack to Local Differential Privacy Protocols for Mean and Variance Estimation
- 中文:用于均值和方差估计的局部差分隐私协议的细粒度中毒攻击
- 国内研究者:西安电子科技大学(第一作者)
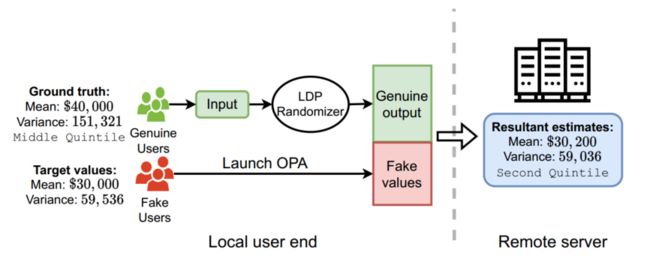
尽管局部差异隐私(LDP)保护个人用户的数据不受不可信数据管理员的推断,但最近的研究表明,攻击者可以从用户端发起数据中毒攻击,将精心制作的虚假数据注入 LDP 协议,以最大限度地扭曲数据管理员的最终估计。
在这项工作中,研究团队通过提出一种新的细粒度攻击来进一步推进这一知识,该攻击允许攻击者微调并同时操纵均值和方差估计,这是许多现实世界应用程序中流行的分析任务。(威胁现实世界大量实际应用程序数据安全)
为了实现这一目标,该攻击利用 LDP 的特性将假数据注入本地 LDP 实例的输出域。称为输出中毒攻击(OPA)。
研究者观察到较小的隐私损失增强了 LDP 的安全性,实现了安全隐私的一致性,这与先前工作中已知的安全隐私权衡相矛盾。(突破已有研究,发现新结论)
研究者进一步研究了一致性,并揭示了 LDP 数据中毒攻击的威胁格局的更全面的观点,针对直观地向 LDP 提供错误输入的基线攻击来全面评估新提出的攻击。
实验结果表明,在三个真实世界的数据集上,OPA 优于基线。研究者还提出了一种新的防御方法,可以从污染的数据收集中恢复结果的准确性,并为安全的 LDP 设计提供了见解。(在给出攻击方法的同时,提供了有效的防御方法)
2.2 可信执行环境(TEE)
- 论文:CIPHERH: Automated Detection of Ciphertext Side-channel Vulnerabilities in Cryptographic Implementations
- 中文:CIPHERH-密码实现中密文侧信道漏洞的自动检测
- 国内研究者:南方科技大学(第一作者)

密文侧通道是一种新型的侧通道,利用可信执行环境(TEE)的确定性内存加密。它使对手能够从逻辑上或物理上读取加密存储器的密文,从而以高保真度破坏由TEE保护的加密实现。
先前的研究得出结论,密文侧信道不仅对首次发现该漏洞的 AMD SEV-SNP 有效,而且对所有具有确定性内存加密的TEE都是严重威胁。
在本文中,研究者提出了 CIPHERH,这是一个实用的框架,用于自动分析加密软件和检测易受密文侧通道攻击的程序点。(提出自动化的侧信道攻击检测框架)
CIPHERH 设计用于在生产密码软件中执行实用的混合分析,具有快速的动态污点分析以跟踪整个程序中秘密的使用情况,以及对每个“污点”函数的静态符号执行过程,并使用符号约束来推断密文侧通道漏洞。
通过经验评估,从 OpenSSL、MbedTLS 和 WolfSSL 的最先进的 RSA 和 ECDSA/EDCH 实现中发现了 200 多个易受攻击的程序点。有代表性的案例已经报告给开发商,并由开发商确认或修补。(在实际产品中发现大量攻击风险)
2.3 联邦学习(FL)
- 论文名称:Gradient Obfuscation Gives a False Sense of Security in Federated Learning
- 中文:梯度混淆在联邦学习中给人一种虚假的安全感
- 国内研究者:浙江大学(第二作者)
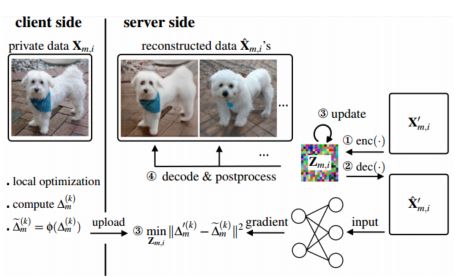
联邦学习已被提议作为一种保护隐私的机器学习框架,使多个客户端能够在不共享原始数据的情况下进行协作。然而,在此框架中的设计并不能保证客户端隐私保护。
先前的工作表明,联合学习中的梯度共享策略可能容易受到数据重建攻击。然而,在实践中,考虑到高通信成本或由于隐私增强要求,客户端可能不发送原始梯度。

经验研究表明,梯度模糊处理,包括通过梯度噪声注入的有意模糊处理和通过梯度压缩的无意模糊处理,可以提供更多的隐私保护,防止重建攻击。
在这项工作中,研究者针对联邦学习中的图像分类任务提出了一种新的重建攻击框架。研究者展示了常用的梯度后处理程序,如梯度量化、梯度稀疏化和梯度扰动,在联邦学习中可能会给人一种虚假的安全感。(证明了已有防护防护手段失效)
与先前的研究相反,研究者认为隐私增强不应被视为梯度压缩的副产品。此外,研究者在所提出的框架下设计了一种新的方法来在语义层面重建图像。研究者量化了语义隐私泄露,并将其与传统的图像相似性得分进行了比较。研究者的比较挑战了文献中的图像数据泄漏评估方案。研究结果强调了重新审视和重新设计现有联合学习算法中客户端数据隐私保护机制的重要性。(凸显了设计针对联邦学习客户端新的数据隐私保护机制的重要性)
2.4 零知识证明(ZK)
- 论文名称:TAP: Transparent and Privacy-Preserving Data Services
- 中文:透明和保护隐私的数据服务
- 国内研究者:西南大学(第三作者)
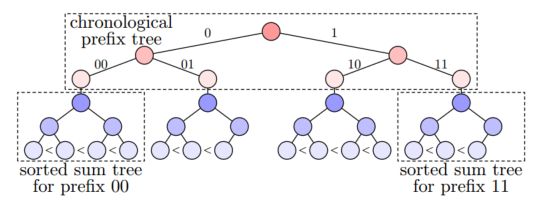
如今,用户期望处理其数据的服务提供更高的安全性。除了传统的数据隐私和完整性要求外,他们还期望透明度,即服务对数据的处理可由用户和可信的审计员进行验证。研究者的目标是构建一个多用户系统,为大量操作提供数据隐私、完整性和透明度,同时实现实际性能。(强调隐私计算的用户透明度属性)
为此,研究者首先确定使用经过身份验证的数据结构的现有方法的局限性。研究者发现它们分为两类:
- 向其他用户隐藏每个用户的数据,但可验证操作范围有限的操作(例如CONIKS、Merkle2 和责任证明)
- 支持广泛的可验证操作,但使所有数据公开可见的操作(如 IntegridDB 和 FalconDB)
然后,研究者提出 TAP 来解决上述限制。TAP的关键组件是一种新颖的树数据结构,它支持有效的结果验证,并依赖于使用零知识范围证明的独立审计,以表明树是正确构建的,而不会泄露用户数据。
TAP 支持广泛的可验证操作,包括分位数和样本标准差。研究者对 TAP 进行了全面评估,并将其与两个最先进的基线(即 IntegridDB 和 Merkle2)进行了比较,表明该系统在规模上是实用的。(相比最先进的基线模型,提出的方案是可行的)
2.5 同态加密(HE)
- 论文名称:Squirrel: A Scalable Secure Two-Party Computation Framework for Training Gradient Boosting Decision Tree
- 中文:一种可扩展且安全的训练梯度提升决策树的两方计算框架
- 国内研究者:全员来自阿里巴巴集团和蚂蚁集团
梯度提升决策树(GBDT)及其变体由于其强大的可解释性而在工业中得到广泛应用。安全多方计算允许多个数据所有者联合计算一个函数,同时保持他们的输入私有。
在这项工作中,研究团队提出了 Squirrel,这是一个基于垂直分割数据集的两方 GBDT 训练框架,其中两个数据所有者各自拥有相同数据样本的不同特征。Squirrel 对半诚实的对手是保密的,在训练过程中不会透露任何敏感的中间信息。
Squirrel 还可以扩展到具有数百万样本的数据集,即使在广域网(WAN)下也是如此。(支持广域网下的百万样本模型训练)
Squirrel 通过 GBDT 算法和高级密码学的几种新颖的联合设计实现了其高性能。
-
提出一种新的高效机制,使用不经意转移来隐藏每个节点上的样本分布 (全新的高效节点分布隐藏机制)
-
提出一种使用基于格的同态加密(HE)的梯度聚合的高度优化方法,比现有的同态计算方法快三个数量级。(超越现有方法多个数量级)
-
提出一种新的协议来评估秘密共享值上的 sigmoid 函数,比现有的两种方法改进了 19 倍-200 倍。
结合所有这些改进,Squirrel 在具有 5 万个样本的数据集上每棵树的成本不到 6 秒,比 Pivot(VLDB 2020)高出 28 倍以上。研究者还表明,Squirrel 可以扩展到具有超过一百万个样本的数据集,例如,在 WAN 上每棵树大约 90 秒。(2min 以内完成百万样本数据集生成单决策树)
2.6 隐私集合计算(PSU)
- 论文名称:Linear Private Set Union from Multi-Query Reverse Private Membership Test
- 中文:多查询反向私有成员测试中的线性私有集并集
- 国内研究者:全员来自中国科学院信息工程研究所信息安全国家重点实验室、中国科学院大学、山东大学、密码科学技术国家重点实验室、阿里巴巴集团
专用集并集(PSU)协议使双方(各自持有一个集)能够在不向任何一方透露任何其他信息的情况下计算其集的并集。
到目前为止,有两种已知的方法来构建 PSU 协议。
- 第一种:主要依赖于加性同态加密(AHE),这通常是低效的,因为它需要对每个项目执行非恒定数量的同态计算。
- 第二种:主要基于 Kolesnikov 等人最近提出的遗忘转移和对称密钥操作(ASIACRYPT 2019)。
第二种具有良好的实用性能,比第一个快几个数量级。然而,这两种方法都不是最优的,因为它们的计算和通信复杂性都不是 O(n),其中 n 是集合的大小。因此,构建最优PSU协议的问题仍然悬而未决的问题。(虽然已有一些方案,但是都会随着集合的扩大带来较大开销,不满足实际需求)
在这项工作中,研究团队通过提出一个来自遗忘传输的 PSU 通用框架和一个新引入的称为多查询反向私有成员身份测试(mq-RPMT)的协议来解决这个开放问题。研究者提出了 mq-RPMT 的两种通用构造。
- 第一种:基于对称密钥加密和一般的 2PC 技术。
- 第二种:基于可重新随机化的公钥加密。
这两种结构都导致 PSU 具有线性计算和通信复杂性。(设计了线性复杂度的方案,突破原本的复杂度限制)
研究团队实现了两个 PSU 协议,并将它们与最先进的 PSU 进行了比较。实验表明,研究团队的基于 PKE 的协议在所有方案中具有最低的通信能力,根据集合大小的不同,通信能力降低了 3.7−14.8 倍。根据网络环境的不同,研究团队的 PSU 方案的运行时间比最先进的方案快 1.2−12 倍。(实验证明,通信能力最大提升 14 倍,运行时间快 12 倍)
三、最后
恭喜上述国内研究团队在隐私计算顶会上“露脸”,同时也说明隐私计算技术正在逐渐从理论方法走向实际应用,充分利用隐私计算技术可以在满足隐私保护需求的同时,顺应数据要素流通的发展趋势,助力数字经济健康发展。中国的学术界和工业界将继续深入合作,打造更好的优质隐私计算产品,实现数据“可用不可见、可用不可存、可控可计量”的安全流通,助力数字中国健康发展。
PrimiHub 一款由密码学专家团队打造的开源隐私计算平台。我们专注于分享数据安全、密码学、联邦学习、同态加密等隐私计算领域的技术和内容。