re:Invent 2023 | Serverless 数据流:Amazon Kinesis 数据流和 Amazon Lambda
关键字: [Amazon Web Services re:Invent 2023, Amazon Kinesis Data Streams, Kinesis Data Streams, Amazon Lambda, Data Streaming, Failures, Error Handling]
本文字数: 1500, 阅读完需: 8 分钟
视频
如视频不能正常播放,请前往bilibili观看本视频。>> re:Invent 2023 | Serverless 数据流:Amazon Kinesis 数据流和 Amazon Lambda [重复]_哔哩哔哩_bilibili
导读
需要一个无服务器的近实时数据流架构吗?只需将 Amazon Kinesis Data Streams 连接到 Amazon Lambda。很简单!不过,在现实世界中会发生什么呢?在本讲座中,将探索使用 Amazon Kinesis Data Streams 和 Amazon Lambda 创建可扩展的、适用于生产环境的数据流架构的复杂性。我们将带您深入了解在此过程中应对分布式系统固有的挑战和陷阱时所必需的技巧和最佳实践,并观察亚马逊云科技服务的工作和交互方式。此外,思考如何接受失败,因为正如 Werner Vogels 博士喜欢说的那样,任何事情都会经历失败,一直如此。
演讲精华
以下是小编为您整理的本次演讲的精华,共1200字,阅读时间大约是6分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。
演讲者开始了她的演讲,强调她将关注关于将Amazon Kinesis数据流与亚马逊云科技Lambda一起用于无服务器数据流式架构的潜在问题。她描述了一个简单但强大的模式,这种模式正变得越来越普遍:利用Kinesis数据流以异步且可扩展的方式获取实时数据,同时触发亚马逊云科技的Lambda函数来消费和处理来自数据流的数据。这种“存储优先”的架构将数据写入Kinesis,使其在毫秒内可用,然后Lambda可以接近实时地访问数据进行处理。
为了展示这种架构可能存在的问题,演讲者分享了她曾参与过的一个客户实施案例。该架构运行良好,直到有一天他们发现写入Kinesis数据流的数据丢失了。这些丢失的数据在生产者应用程序端没有明确的记录。虽然后来她注意到了一些矛盾的指标,但没有明确显示存在问题。然而,从流中消费数据的亚马逊云科技的Lambda函数开始表现出异常行为,这引发了对于架构中出现问题的原因的调查。
演讲者随后提供了一些关于Kinesis数据流的背景信息。这是亚马逊云科技的一项完全管理的服务,用于大规模实时流式传输数据。写入Kinesis流的数据可以在毫秒内可用,并根据配置至少保存24小时,最长7天。这种保留能力是其与其他一些亚马逊云科技流媒体服务相比的关键区别。
Kinesis通过在使用流中分片来实现高可扩展性。每个分片具有每秒写入的有限容量,但可以配置所需的分片数量以支持所需的吞吐量。演讲者指出,这种基于分片的方法意味着Kinesis并非完全是无服务器的,因为必须根据数据量的变化主动管理分片数量并调整其容量。Kinesis现在提供了一种按需容量模式来取消分片管理,但这会带来更高的成本以及在扩展容量方面的较低灵活性。
在处理Kinesis数据流的消费问题时,应用程序可以借助由数据流触发的Amazon Web Services Lambda函数来进行实时数据处理。作为数据流消费者的Lambda具备诸多优势,例如内置的可扩展性和错误处理功能。据演讲者介绍,Lambda集成在底层通过事件源映射进行处理,这些映射负责处理记录批处理、重试以及其他关键功能。
在分析客户提出的问题时,研究人员发现,生产者应用程序在将数据写入Kinesis时发生数据丢失的问题,原因在于生产者并未正确处理部分批量失败。生产者使用的Amazon Web Services SDK支持将单个记录或批处理记录写入流中。批处理可以减少请求次数以提高性能,但是批处理操作并非原子性的。如果一个批次部分失败,SDK会重试整个批次而不检查部分失败的情况。因此,在生产者内部并未编写处理失败记录的代码,从而导致数据无声丢失。演讲者强调,在使用分布式系统的批处理操作时,必须考虑部分失败的潜在影响。
此外,演讲者还建议在处理部分批量失败的同时,通过设置限制并使用指数退避和抖动来合理配置SDK的重试功能。她指出,分布式系统中经常出现故障,原因包括限流或网络问题等。采用指数退避和抖动作为重试策略可以有效应对这些问题,避免在已经承受压力的系统中出现过度负载。
针对另一个问题,即在高流量期间,由于shard级别的限流问题导致CloudWatch在流级别指标不准确且无法揭示问题,演讲者提出了相应的解决方案。每个shard的限制是基于每秒执行次数的,而CloudWatch将指标聚合到每分钟级别。因此,短暂的峰值可能会导致限流,而在聚合指标中看不见。建议在这种情况下专门监控与限流相关的指标以获取更清晰的视觉呈现。
总的来说,通过对生产者问题的调查,发现了需要对批量部分失败进行适当处理,合理配置重试机制以及关注限流等相关指标。演讲者强调,这些经验教训不仅适用于Kinesis特定的环境,还可以广泛应用于其他分布式系统或服务中。
Kinesis分片需要手动管理和扩展,这与按需模式不同,后者不需要管理分片,但成本较高。
-
批量写入可以提高性能,但需要处理部分失败以防止数据丢失。
-
具有随机化的指数退避对于分布式系统的重试非常重要。
-
每个分片的指标可能会揭示出聚合指标遗漏的问题。
-
事件源映射会调用Lambda并处理失败,但默认设置可能导致数据丢失。
-
事件源映射的配置,如重试限制和批量分割,有助于创建可靠的处理。
-
过滤记录可以避免不必要的Lambda调用并节省成本。
总的来说,演讲者在讲解一个客户案例时,强调了使用Kinesis和Lambda默认设置可能会引发严重数据丢失和系统不稳定问题。为了充分利用这些服务实现实时数据流,需要采取正确的措施,如妥善处理批量失败、实施重试策略并精心配置事件源映射。这些经验教训对于设计具有弹性的分布式系统具有普遍意义。将故障视为学习机会是构建稳定系统的核心关键。
下面是一些演讲现场的精彩瞬间:
演讲者在探讨Kinesis作为完全无服务器服务时,分析了其优缺点。

尽管按需计费模式的需求流与预置流有所不同——即使分片保留未使用,仍需支付额外费用,但这仍然是一种具有自动扩展功能的实用解决方案。
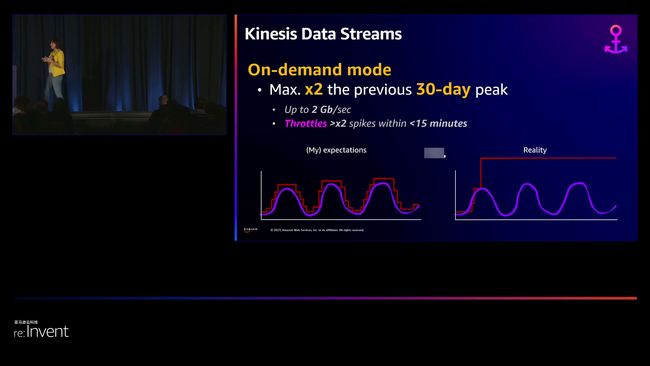
然而,要实现真正的无服务器架构,仍有待努力。

值得一提的是,亚马逊云科技SDK的默认超时设置长达两分钟,这对于实时处理任务而言过长,因为每毫秒都至关重要。

此外,亚马逊云科技Lambda会自动重试失败的批处理记录,以确保数据流得到可靠处理。

面对可能出现的故障,保持冷静并做好准备是关键。

总结
演讲者探讨了如何将Amazon Kinesis数据流与亚马逊云科技的Lambda相结合以实现实时数据处理。她强调了从失败中吸取教训以构建可靠系统的重要性。首先,Kinesis具有强大的可扩展性,但需要应对分片和吞吐量限制。虽然按需模式消除了分片管理的需要,但它并未实现真正的自动扩展。其次,要密切关注节流、部分批量失败等错误情况。实施有限的重试和回退策略,以免给系统带来过大的压力。同时,关注诸如节流等关键性能指标,以便全面了解系统状况。再者,尽管Lambda的事件源映射具有批处理等优点,但默认的重试设置可能引发问题。因此,应设置事件重试限制并利用批处理分割等功能。避免不必要的调用至关重要。总之,失败是我们学习和成长的机会。深入了解这些服务的工作原理,特别是分布式系统的基本原则,如重试和限制。在架构系统时,要充分考虑需求,而不仅仅是拒绝可用工具。通过拥抱失败,我们可以构建更加灵活且健壮的系统。
演讲原文
Serverless data streaming: Amazon Kinesis Data Streams and AWS Lambda [REPEAT]-CSDN博客
想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
2023亚马逊云科技re:Invent全球大会 - 官方网站
点击此处,一键获取亚马逊云科技全球最新产品/服务资讯!
点击此处,一键获取亚马逊云科技中国区最新产品/服务资讯!
即刻注册亚马逊云科技账户,开启云端之旅!
【免费】亚马逊云科技“100 余种核心云服务产品免费试用”
【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”
亚马逊云科技是谁?
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者,自 2006 年以来一直以不断创新、技术领先、服务丰富、应用广泛而享誉业界。亚马逊云科技可以支持几乎云上任意工作负载。亚马逊云科技目前提供超过 200 项全功能的服务,涵盖计算、存储、网络、数据库、数据分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用开发、部署与管理等方面;基础设施遍及 31 个地理区域的 99 个可用区,并计划新建 4 个区域和 12 个可用区。全球数百万客户,从初创公司、中小企业,到大型企业和政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本,加快创新,提升竞争力,实现业务成长和成功。
