视频播放量的变化逻辑
文章目录
- 前言
- 一、播放量是怎么变化的?
- 二、抓包
- h5请求参数怎么解决
- COOKIE怎么搞?
-
- buvid3
- b_lsid
- _uuid
- buvid4和sid
- 刷
前言
以此文记录爬虫逆向学习思路
代理ip+cookie来刷播放
缺陷:据说破站这方面的检测很严格了,这种刷播放的方式,不会真的观看视频,就是点播一下,如果很多播放量都是这种点播而且还都是游客播放b站是能检测到的,检测到就刷了也没用播放量也不会涨的。
一、播放量是怎么变化的?
可能一个网站就有一种变化方式,可能是专门发送请求给服务器进行播放量修改,也可能藏在某个不起眼的请求中,或者是JS代码中的某个参数值。
破站的播放量可以通过发h5请求进行增加。
怎么确定的?
目前也没什么好办法,毕竟一进入播放页浏览器请求一下就冒一大堆,只能一个一个的看,然后去试,看是不是这个请求让播放量增加的。
不过我想了一个思路,就是我刷新两次网页,看两次视频,那么就有2个播放量的增长,也就是两次请求到服务器修改播放量的值,完了我就专门看那些请求次数为2次的请求,去找刷播放量的。
怎么看出来这个请求就是改播放量的?
网上查+感觉+实践
二、抓包
就是它h5:

看看它的请求参数和cookie:
为什么要看cookie?
cookie是可以代表用户身份的,要刷播放,肯定是模仿很多人在看视频,那么就需要知道这些cookie哪些是固定的,哪些是变化,变化的cookie是怎么来的。

h5请求参数怎么解决
1.先拿多个相同的请求做对比,以排除掉那些参数值一直定死的的参数。
2.看那些会变化的参数可能的具体含义(直接看出来最好办),是不是密文(是密文可能要探索加密逻辑,进行逆向)。
排除掉请求中的定死的参数,后推断出stime,ftime都是时间戳。
bvid是视频id,url中就有。
aid 和 cid 是什么不知道,但是它的来源无非就是其他请求的返回值(cookie /response)或者js代码动态生成的。
拿着aid或者aid的值在浏览器中search就发现了目标:

那么要拿到这两个参数就只要:
res = session.get("https://www.bilibili.com/video/BV1rw411X7AN/")
data_list = re.findall(r'__INITIAL_STATE__=(.+);\(function', res.text) //小细节 \( 转义(是普通( 不是re中的()分组符号
data_dict = json.loads(data_list[0]) //转为python对象
aid = data_dict['aid']
cid = data_dict['videoData']['cid']
COOKIE怎么搞?
和确定参数一点点不同:
1.先拿多个相同的请求做对比,以排除掉那些参数一直定死。
2.cookie的来源:JS代码生成或者其他请求返回
排除固定值的cookie参数后.
列出不固定值得cookie:
buvid3
b_lsid
_uuid
buvid4
sid
buvid3
选中cookie选项:
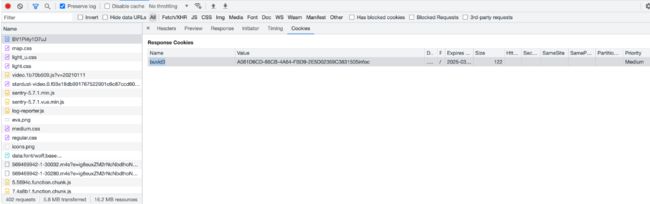
然后在h5请求的前面一个个的请求,都是比它先发出去的请求,一个个看:
建议直接↓键刷过去看。快一点,难得点
上图得请求中返回Response Cookies 中就返回了cookie–buvid3的值,搞定一个cookie值.
session可以自动维护非js生成的cookie,那么只要发个请求,这个buvid3值就被记录好了。
res = session.get("https://www.bilibili.com/video/BV1rw411X7AN/")
b_lsid
老办法,在h5请求的前面一个个的请求,都是比它先发出去的请求,一个个看:
建议直接↓键刷过去看。快一点,难得点
发现spi请求中Requests Cookies中带有b_lsid的值,但是在它之前的请求中都没有返回带有该cookie的Response Cookies,Respose中也没有这个参数,
那么就应该是JS代码生成的了
浏览器中search b_lsid或者b_lsid的值来查找JS代码生成逻辑:
细节:还可以搜索setCookie,因为要设定Cookie的值一般就要用这个函数。
细节:搜到后,在Response中右键点击open in source方便打断点

打断点在setCookie(“b_lsid”,t)发现b_lsid最后等于t,
然后在这个函数里看t的生成逻辑:
细节:cookie具有时效性,不一定会立马失效,既然在之前的请求中生成了cookie还没失效那么在刷新网页时就不用再生成cookie,那么这个断点就没用,因为生成该cookie的代码都不会运行。
怎么办?
打开无痕模式,可以打开一个干净的无cookie的窗口
点击网址栏上的锁清除cookie
value: function() {
var e = this.splitDate() //返回时间数据字典
, t = (0, l.G$)(e.millisecond) //把时间戳向上取整转为16进制的文本后大写
, r = "".concat((0, l.Q4)(8), "_").concat(t); //concat 字符串拼接 (0, l.Q4)(8)
// 长度为8每个字符为16*[0,1)后取整转16进制字符串大写不足8位会在前面补0
this.lsid = r,
this.time.start = e.millisecond,
this.time.day = e.day,
s.Z.setCookie("b_lsid", r, 0, "current-domain") // b_lsid = r
}
var e = this.splitDate()是干什么的,不知道,鼠标选中看它的值,返回的是时间数据,定位到该函数的内部:
tips: console可以运行JS自带的代码,和浏览器发送请求运行过的代码。
var e = this.splitDate() //返回时间数据字典格式
//等价
value: function(e) {
var t = new Date(e || Date.now()) // 等价于 t = new Date(Date.now()) 等于Fri Dec 08 2023 13:23:10 GMT+0800 (中国标准时间)
, r = t.getDate() //8 日
, n = t.getHours() //13 时
, o = t.getMinutes() //23 分钟
, i = t.getTime(); //时间戳
return {
day: r,
hour: n,
minute: o,
second: Math.floor(i / 1e3), //取整
millisecond: i
}
}
(0, l.G$)(e.millisecond)
//等价
a = function(e) {
return Math.ceil(e).toString(16).toUpperCase()}
(0, l.Q4)(8) //长度为8每个字符为随机取16*[0,1)中的值后取整转16进制字符串大写且不足8位会在前面补0
//等价
o = function(e) {
for (var t = "", r = 0; r < e; r++)
t += a(16 * Math.random()); //16*[0,1)后取整转字符串大写 长度为8
return i(t, e)
}
a = function(e) {
return Math.ceil(e).toString(16).toUpperCase()
}
i = function(e, t) {
var r = "";
if (e.length < t)
for (var n = 0; n < t - e.length; n++)
r += "0";
return r + e
}
_uuid
步骤依旧:
这里就直接给Js代码分析了
// // uuid=n 标准的uuid码生成
// var n = function() {
// var e = o(8)
// , t = o(4)
// , r = o(4)
// , n = o(4)
// , a = o(12)
// , s = (new Date).getTime(); //时间戳
//
// return e + "-" + t + "-" + r + "-" + n + "-" + a + i((s % 1e5).toString(), 5) + "infoc"
// }
//
// //
// o = function(e) {
// for (var t = "", r = 0; r < e; r++)
//生成长度为e每个字符由16*[0,1)的数取整转16进制字符后转大写的字符串t
// t += a(16 * Math.random());
// //返回字符串如果长度小于e就补前缀0
// return i(t, e)}
//
// a = function(e) {
// return Math.ceil(e).toString(16).toUpperCase()
// }
//
//
// //
// i = function(e, t) {
// var r = "";
// if (e.length < t)
// for (var n = 0; n < t - e.length; n++)
// r += "0";
// return r + e
// }
buvid4和sid
直接在spi请求中返回了,那么模拟请求就好了:

响应体返回buvid4:
def b_4():
resp = requests.get("https://api.bilibili.com/x/frontend/finger/spi")
data =resp.json()["data"]["b_4"] //b_4和buvid4的值相同,所以取b_4的值
return data
响应cookies中返回sid:
res = session.get(
url='https://api.bilibili.com/x/player/v2',
params={
"cid": cid, //cid 本文h5请求参数分析中得到了来源
"aid": aid, //cid 本文h5请求参数分析中得到了来源
"bvid": bvid, //cid 本文h5请求参数分析中得到了来源
}
)
sid = res.cookies.get_dict()["sid"]
session.cookies.set("sid", sid)
刷
所有请求参数和cookie都搞定后,根据请求发送顺序和cookie的生成逻辑写python代码模拟请求发送
注意:不要忘了固定cookie值和固定请求参数值的给定,时间空间上不要出错。
然后就是ip,一个Ip上发送的很多h5请求可以被破站发现,一发现就可以查出来你在刷播放,可以直接拒绝你的代码请求。
所以花钱上隧道代理:
代理
def get_proxies():
proxy_host = "tunnel2.qg.net:17955"
proxy_username = "xxxxxxx"
proxy_pwd = "xxxxxxxxxxx"
return {
"http": "http://{}:{}@{}".format(proxy_username, proxy_pwd, proxy_host),
"https": "http://{}:{}@{}".format(proxy_username, proxy_pwd, proxy_host),
}
最后再分享个api,可以监控视频播放量啥的的。
def get_video_id_info(video_url, proxies): //视频链接 接口
session = requests.Session()
bvid = video_url.rsplit('/')[-1]
res = session.get(
url="https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp".format(bvid),
proxies=proxies
)
cid = res.json()['data'][0]['cid']
res = session.get(
url="https://api.bilibili.com/x/web-interface/view?cid={}&bvid={}".format(cid, bvid),
proxies=proxies
)
res_json = res.json()
aid = res_json['data']['aid']
view_count = res_json['data']['stat']['view']
duration = res_json['data']['duration']
print("\n视频 {},平台播放量为:{}".format(bvid, view_count))
session.close()
return aid, bvid, cid, duration, int(view_count)