Fork和Join底层原理
文章目录
-
- 一、任务类型
-
- 1. 简介
- 2. CPU密集型
- 3. IO密集型
- 4. 线程数计算方法
- 二、Fork/Join框架
-
- 1. 思想
- 2. Fork/Join简介
- 3. Fork/Join使用
- 4. 底层原理
- 5. 总结
一、任务类型
1. 简介
思考: 线程池的线程数设置多少合适?
我们调整线程池中的线程数量的最主要的目的是为了充分并合理地使用 CPU 和内存等资源,从而最大限度地提高程序的性能。在实际工作中,我们需要根据任务类型的不同选择对应的策略。
2. CPU密集型
CPU密集型任务也叫计算密集型任务,比如加密、解密、压缩、计算等一系列需要大量费 CPU 资源的任务。对于这样的任务最佳的线程数为 CPU 核心数的 1~2 倍,如果设置过多的线程数,实际上并不会起到很好的效果。此时假设我们设置的线程数量是 CPU 核心数的 2 倍以上,因为计算任务非常重,会占用大量的 CPU 资源,所以这时 CPU 的每个核心工作基本都是满负荷的,而我们又设置了过多的线程,每个线程都想去利用 CPU 资源来执行自己的任务,这就会造成不必要的上下文切换,此时线程数的增多并没有让性能提升,反而由于线程数量过多会导致性能下降。
3. IO密集型
IO密集型任务,比如数据库、文件的读写,网络通信等任务,这种任务的特点是并不会特别消耗CPU资源,但是 IO 操作很耗时,总体会占用比较多的时间。对于这种任务最大线程数一般会大于 CPU 核心数很多倍,因为 IO 读写速度相比于 CPU 的速度而言是比较慢的,如果我们设置过少的线程数,就可能导致 CPU 资源的浪费。而如果我们设置更多的线程数,那么当一部分线程正在等待 IO 的时候,它们此时并不需要 CPU 来计算,那么另外的线程便可以利用CPU 去执行其他的任务,互不影响,这样的话在工作队列中等待的任务就会减少,可以更好地利用资源。
4. 线程数计算方法
1 线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
通过这个公式,我们可以计算出一个合理的线程数量,如果任务的平均等待时间长,线程数就随之增加,而如果平均工作时间长,也就是对于我们上面的 CPU 密集型任务,线程数就随之减少。太少的线程数会使得程序整体性能降低,而过多的线程也会消耗内存等其他资源,所以如果想要更准确的话,可以进行压测,监控 JVM 的线程情况以及 CPU 的负载情况,根据实际情况衡量应该创建的线程数,合理并充分利用资源。
二、Fork/Join框架
1. 思想
分治思想在很多领域都有广泛的应用,例如算法领域有分治算法(归并排序、快速排序都属于分治算法,二分法查找也是一种分治算法);大数据领域知名的计算框架 MapReduce 背 后的思想也是分治。既然分治这种任务模型如此普遍,那 Java 显然也需要支持,Java 并发包里提供了一种叫做 Fork/Join 的并行计算框架,就是用来支持分治这种任务模型的。
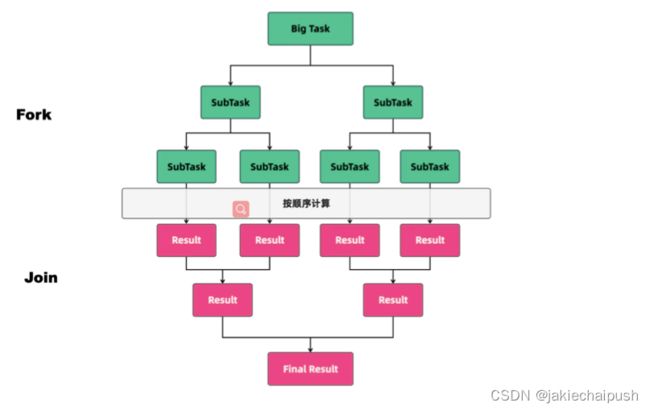
2. Fork/Join简介
传统线程池ThreadPoolExecutor有两个明显的缺点:一是无法对大任务进行拆分,对于某个任务只能由单线程执行;二是工作线程从队列中获取任务时存在竞争情况。这两个缺点都会影响任务的执行效率。为了解决传统线程池的缺陷,Java7中引入Fork/Join框架,并在Java8中得到广泛应用。Fork/Join框架的核心是ForkJoinPool类,它是对 AbstractExecutorService类的扩展。ForkJoinPool允许其他线程向它提交任务,并根据设定将这些任务拆分为粒度更细的子任务,这些子任务将由ForkJoinPool内部的工作线程来并行执 行,并且工作线程之间可以窃取彼此之间的任务。
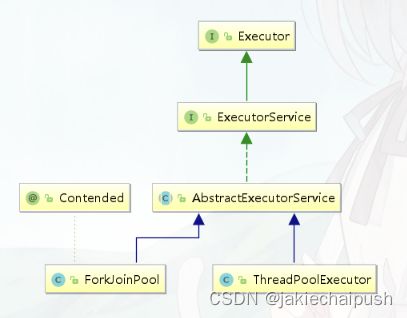
ForkJoinPool最适合计算密集型任务,而且最好是非阻塞任务。ForkJoinPool是 ThreadPoolExecutor线程池的一种补充,是对计算密集型场景的加强。根据经验和实验,任务总数、单任务执行耗时以及并行数都会影响到Fork/Join的性能。所 以,当你使用Fork/Join框架时,你需要谨慎评估这三个指标,最好能通过模拟对比评估,不要凭感觉冒然在生产环境使用。
3. Fork/Join使用
Fork/Join 计算框架主要包含两部分,一部分是分治任务的线程池 ForkJoinPool,另一部分是分治任务 ForkJoinTask。
- ForkJoinPool
ForkJoinPool 是用于执行 ForkJoinTask 任务的执行池,不再是传统执行池Worker+Queue 的组合式,而是维护了一个队列数组 WorkQueue(WorkQueue[]),这样在提交任务和线程任务的时候大幅度减少碰撞。
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false,
0, MAX_CAP, 1, null, DEFAULT_KEEPALIVE, TimeUnit.MILLISECONDS);
}
ForkJoinPool中有四个核心参数,用于控制线程池的并行数、工作线程的创建、异常处理和模 式指定等。各参数解释如下:
- int parallelism:指定并行级别(parallelism level)。ForkJoinPool将根据这个设定,决定工作线程的数量。如果未设置的话,将使用 Runtime.getRuntime().availableProcessors()来设置并行级别;
- ForkJoinWorkerThreadFactory factory: ForkJoinPool在创建线程时,会通过factory来创建。注意,这里需要实现的是ForkJoinWorkerThreadFactory,而不是 ThreadFactory。如果你不指定factory,那么将由默认的 DefaultForkJoinWorkerThreadFactory负责线程的创建工作;
- UncaughtExceptionHandler handler:指定异常处理器,当任务在运行中出错 时,将由设定的处理器处理;
- boolean asyncMode:设置队列的工作模式: asyncMode ? FIFO_QUEUE : LIFO_QUEUE。当asyncMode为true时,将使用先进先出队列,而为false时则使用后进先出的模式。
- ForkJoinTask
ForkJoinTask是ForkJoinPool的核心之一,它是任务的实际载体,定义了任务执行时的具体逻辑和拆分逻辑。ForkJoinTask继承了Future接口,所以也可以将其看作是轻量级的 Future。ForkJoinTask 是一个抽象类,它的方法有很多,最核心的是 fork() 方法和 join() 方法,承载着主要的任务协调作用,一个用于任务提交,一个用于结果获取。
- fork()——提交任务: fork()方法用于向当前任务所运行的线程池中提交任务。如果当前线程是
ForkJoinWorkerThread类型,将会放入该线程的工作队列,否则放入common线程池的工作 队列中。- join()——获取任务:执行结果 join()方法用于获取任务的执行结果。调用join()时,将阻塞当前线程直到对应的子任务完成运行并返回结果。
通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供 了以下三个子类:
- RecursiveAction:用于递归执行但不需要返回结果的任务。
- RecursiveTask :用于递归执行需要返回结果的任务。
- CountedCompleter :在任务完成执行后会触发执行一个自定义的钩子函数
ForkJoinTask最适合用于纯粹的计算任务,也就是纯函数计算,计算过程中的对象都是独立的,对外部没有依赖。提交到ForkJoinPool中的任务应避免执行阻塞I/O。
4. 底层原理
- ForkJoinPool底层原理
与传统线程池不同,ForkJoinPool底层会维护很多个双端队列,双端队列的数据结构如下:
static final class WorkQueue {
static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
// Instance fields
volatile int scanState; // versioned, <0: inactive; odd:scanning
int stackPred; // pool stack (ctl) predecessor
int nsteals; // number of steals
int hint; // randomization and stealer index hint
int config; // pool index and mode
volatile int qlock; // 1: locked, < 0: terminate; else 0
volatile int base; // index of next slot for poll
int top; // index of next slot for push
//用于存储任务
ForkJoinTask<?>[] array; // the elements (initially unallocated)
final ForkJoinPool pool; // the containing pool (may be null)
final ForkJoinWorkerThread owner; // owning thread or null if shared
volatile Thread parker; // == owner during call to park; else null
volatile ForkJoinTask<?> currentJoin; // task being joined in awaitJoin
volatile ForkJoinTask<?> currentSteal; // mainly used by helpStealer
WorkQueue(ForkJoinPool pool, ForkJoinWorkerThread owner) {
this.pool = pool;
this.owner = owner;
// Place indices in the center of array (that is not yet allocated)
base = top = INITIAL_QUEUE_CAPACITY >>> 1;
}
}
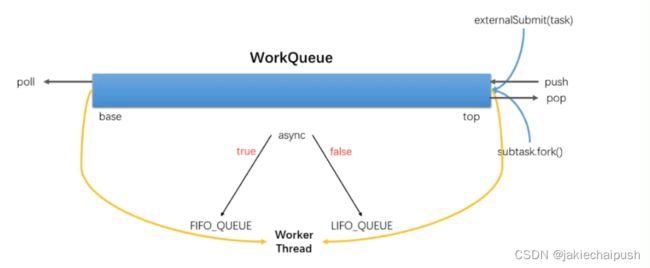
然后多个双端队列维护在一个数组中
WorkQueue[] queues; // main registry
然后线程池中的线程(ForkJoinWorkerThread)都是ForkJoinWorkerThreadFactory这个工厂来创建的
final ForkJoinWorkerThreadFactory factory;
//ForkJoinWorkerThreadFactory是ForkJoinThread的一个内部接口
public static interface ForkJoinWorkerThreadFactory {
public ForkJoinWorkerThread newThread(ForkJoinPool pool);
}
DefaultForkJoinWorkerThreadFactory内部类实现了ForkJoinWorkerThreadFactory的具体逻辑,实现了newThread方法
static final class DefaultForkJoinWorkerThreadFactory
implements ForkJoinWorkerThreadFactory {
public final ForkJoinWorkerThread newThread(ForkJoinPool pool) {
return new ForkJoinWorkerThread(pool);
}
}
在创建完一个线程时,我们需要与指定的一个双端队列进行绑定,这部分在ForkJoinWorkerThread构造函数中指定
protected ForkJoinWorkerThread(ForkJoinPool pool) {
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}
绑定的实际逻辑在registerWorker这个方法中实现
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
wt.setDaemon(true); // configure thread
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
//创建一个新的双端队列,通过构造函数来绑定指定线程
WorkQueue w = new WorkQueue(this, wt);
int i = 0; // assign a pool index
int mode = config & MODE_MASK;
int rs = lockRunState();
try {
WorkQueue[] ws; int n; // skip if no array
if ((ws = workQueues) != null && (n = ws.length) > 0) {
int s = indexSeed += SEED_INCREMENT; // unlikely to collide
int m = n - 1;
i = ((s << 1) | 1) & m; // odd-numbered indices
if (ws[i] != null) { // collision
int probes = 0; // step by approx half n
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
while (ws[i = (i + step) & m] != null) {
if (++probes >= n) {
workQueues = ws = Arrays.copyOf(ws, n <<= 1);
m = n - 1;
probes = 0;
}
}
}
w.hint = s; // use as random seed
w.config = i | mode;
w.scanState = i; // publication fence
ws[i] = w;
}
} finally {
unlockRunState(rs, rs & ~RSLOCK);
}
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
return w;
}
以上是线程创建以及任务与线程绑定的原理,下面分析在任务提交过程中,这两个过程是如何进行的
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task;
}
然后调用externalPush实现真正提交任务的逻辑
final void externalPush(ForkJoinTask<?> task) {
WorkQueue[] ws; WorkQueue q; int m;
int r = ThreadLocalRandom.getProbe();
int rs = runState;
//判断当前工作队列数组是否创建以及是否为空
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&
U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask<?>[] a; int am, n, s;
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
int j = ((am & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
U.putIntVolatile(q, QLOCK, 0);
if (n <= 1)
signalWork(ws, q);
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
//如果为空直接调用externalSubmit函数
externalSubmit(task);
}
若此时是第一个次提交任务,工作队列数组WorkQueue还没有创建,所以进入externalSubmit逻辑
private void externalSubmit(ForkJoinTask<?> task) {
int r;
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (;;) {
WorkQueue[] ws; WorkQueue q; int rs, m, k;
boolean move = false;
if ((rs = runState) < 0) {
tryTerminate(false, false); // help terminate
throw new RejectedExecutionException();
}
else if ((rs & STARTED) == 0 || // initialize
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
rs = lockRunState();
try {
if ((rs & STARTED) == 0) {
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
/
int p = config & SMASK; // ensure at least 2 slots
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
//构建了一个偶数容量的workQueues数组
workQueues = new WorkQueue[n];
ns = STARTED;
}
} finally {
unlockRunState(rs, (rs & ~RSLOCK) | ns);
}
}
//这个if就是将任务放在一个workqueue的原理
else if ((q = ws[k = r & m & SQMASK]) != null) {
//首先通过CAS操作获取指定工作队列的锁
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {
//获得任务数组
ForkJoinTask<?>[] a = q.array;
//获得工作队列顶端
int s = q.top;
boolean submitted = false;
try {
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
//往任务放在任务数组中
U.putOrderedInt(q, QTOP, s + 1);
submitted = true;
}
} finally {
//释放锁
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
if (submitted) {
//唤醒工作线程执行
signalWork(ws, q);
return;
}
}
move = true; // move on failure
}
else if (((rs = runState) & RSLOCK) == 0) { // create new queue
//创建一个新的工作队列,绑定线程为null
q = new WorkQueue(this, null);
q.hint = r;
q.config = k | SHARED_QUEUE;
q.scanState = INACTIVE;
rs = lockRunState(); // publish index
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
//经过一系列运算将,工作队列放在工作队列数组中
ws[k] = q; // else terminated
unlockRunState(rs, rs & ~RSLOCK);
}
else
move = true; // move if busy
if (move)
r = ThreadLocalRandom.advanceProbe(r);
}
}
上面代码就是初始化workQueues数组以及WorkQueue的代码,当是第一个提交任务workQueues数组没有初始化时会进入上面代码的逻辑,然后创建一个偶数容量的workQueue数组,接着将任务放在相关队列中。最后调用signalWork唤醒队列指定的工作线程区执行任务
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c; int sp, i; WorkQueue v; Thread p;
while ((c = ctl) < 0L) {
//如果工作线程为空就创建工作线程
if ((sp = (int)c) == 0) {
if ((c & ADD_WORKER) != 0L)
tryAddWorker(c);
break;
}
if (ws == null)
break;
if (ws.length <= (i = sp & SMASK))
break;
if ((v = ws[i]) == null)
break;
int vs = (sp + SS_SEQ) & ~INACTIVE;
int d = sp - v.scanState;
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs;
if ((p = v.parker) != null)
//使用unpark方法唤醒线程
U.unpark(p);
break;
}
if (q != null && q.base == q.top) // no more work
break;
}
}
当工作线程为空时就创建工作线程
private void tryAddWorker(long c) {
boolean add = false;
do {
long nc = ((AC_MASK & (c + AC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
if (ctl == c) {
int rs, stop; // check if terminating
if ((stop = (rs = lockRunState()) & STOP) == 0)
add = U.compareAndSwapLong(this, CTL, c, nc);
unlockRunState(rs, rs & ~RSLOCK);
if (stop != 0)
break;
if (add) {
createWorker();
break;
}
}
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
if (fac != null && (wt = fac.newThread(this)) != null) {
//开启工作线程
wt.start();
return true;
}
} catch (Throwable rex) {
ex = rex;
}
deregisterWorker(wt, ex);
return false;
}
创建工作线程使用前面说到的工作创建,然后与指定的队列进行绑定。这里就是前面介绍到的registerWorker逻辑。ForkJoinWorkThread 是用于执行任务的线程,用于区别使用非 ForkJoinWorkThread 线程提交task。启动一个该 Thread,会自动注册一个 WorkQueue 到 Pool,拥有 Thread 的 WorkQueue 只能出现在 WorkQueues[] 的奇数位。上面分析了当我们第一次提交任务调用externalPush入队,没有创建workQueues时调用externalSubmit的逻辑。若不是第一次条件,工作队列数组已经创建了,此时就不会调用externalSubmit。

继续看externalPush:
final void externalPush(ForkJoinTask<?> task) {
WorkQueue[] ws; WorkQueue q; int m;
int r = ThreadLocalRandom.getProbe();
int rs = runState;
//判断当前工作队列数组是否创建以及是否为空
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
//如果有工作队列数组,就通过位运算获得某个队列
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&
//给当前工作队列加锁
U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask<?>[] a; int am, n, s;
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) {
int j = ((am & s) << ASHIFT) + ABASE;
//将任务放在任务队列中
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1); //解锁
U.putIntVolatile(q, QLOCK, 0);
if (n <= 1)
//然后唤醒线程
signalWork(ws, q);
return;
}
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
//如果为空直接调用externalSubmit函数
externalSubmit(task);
}
至此工作队列和工作队列数组已经准备好的,任务也已经创建完毕了,工作线程也创建或准备好了,下面就可以执行工作线程的run方法执行任务了。
public void run() {
//判断工作队列是否为空
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
onStart();
//真正执行任务
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
onTermination(exception);
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);
}
}
}
}
真正执行任务是runWorker方法
final void runWorker(WorkQueue w) {
w.growArray(); //
int seed = w.hint; //
int r = (seed == 0) ? 1 : seed; //
for (ForkJoinTask<?> t;;) {
//通过scan方法获取任务
if ((t = scan(w, r)) != null)
w.runTask(t);
//如果没有任务就阻塞线程
else if (!awaitWork(w, r))
break;
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift
}
}
这里就是runTask方法执行任务,如果没有任务就调用awaitWork方法阻塞(底层会调用park方法)
final void runTask(ForkJoinTask<?> task) {
if (task != null) {
scanState &= ~SCANNING; //
(currentSteal = task).doExec();
U.putOrderedObject(this, QCURRENTSTEAL, null); // release for GC
execLocalTasks();
ForkJoinWorkerThread thread = owner;
if (++nsteals < 0) // collect on overflow
transferStealCount(pool);
scanState |= SCANNING;
if (thread != null)
thread.afterTopLevelExec();
}
}
final int doExec() {
int s; boolean completed;
if ((s = status) >= 0) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
s = setCompletion(NORMAL);
}
return s;
}
实际执行任务的逻辑就是exec()
//这是个抽象方法(ForkJoinTask的),具体实现逻辑靠它子类
protected abstract boolean exec();
回到runwork方法,我们说到获取任务是通过t = scan(w, r)的方法,如果当前队列没有任务,它就会采用工作窃取的的方式从其它队列中获取任务。
总体逻辑还是比较复杂,可以用下图辅助理解:
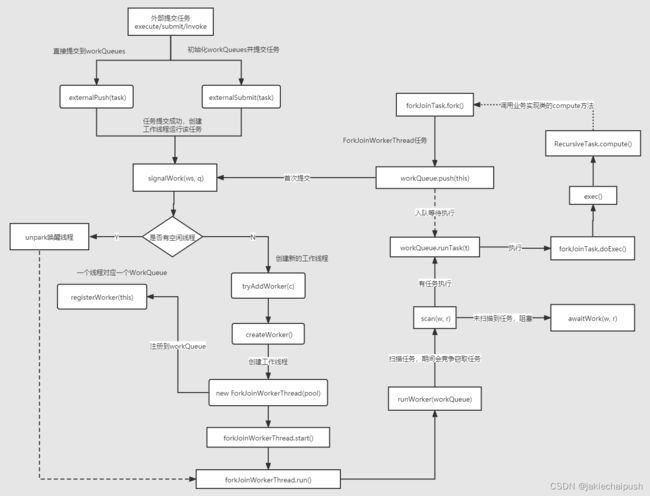
5. 总结
- ForkJoinPool 的工作原理
- ForkJoinPool 内部有多个工作队列,当我们通过 ForkJoinPool 的 invoke() 或者submit() 方法提交任务时,ForkJoinPool 根据一定的路由规则把任务提交到一个工作队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的工作 队列中。
- ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
- 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的top,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从top取出任务来执行。
- 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务,窃取的任务位于其他线程的工作队列的base,也就是说工作线程在窃取其他工作线程的任务时,使用的是FIFO 方式。
- 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其 完成。
在既没有自己的任务,也没有可以窃取的任务时,进入休眠 。
- 工作窃取
ForkJoinPool与ThreadPoolExecutor有个很大的不同之处在于,ForkJoinPool存在引入了工作窃取设计,它是其性能保证的关键之一。工作窃取,就是允许空闲线程从繁忙线程的双端队列中窃取任务。默认情况下,工作线程从它自己的双端队列的头部获取任务。但是,当自 己的任务为空时,线程会从其他繁忙线程双端队列的尾部中获取任务。这种方法,最大限度地减少了线程竞争任务的可能性。ForkJoinPool的大部分操作都发生在工作窃取队列(work-stealing queues ) 中,该队列由内部类WorkQueue实现。它是Deques的特殊形式,但仅支持三种操作方式:push、pop 和poll(也称为窃取)。在ForkJoinPool中,队列的读取有着严格的约束,push和pop仅能从其所属线程调用,而poll则可以从其他线程调用。
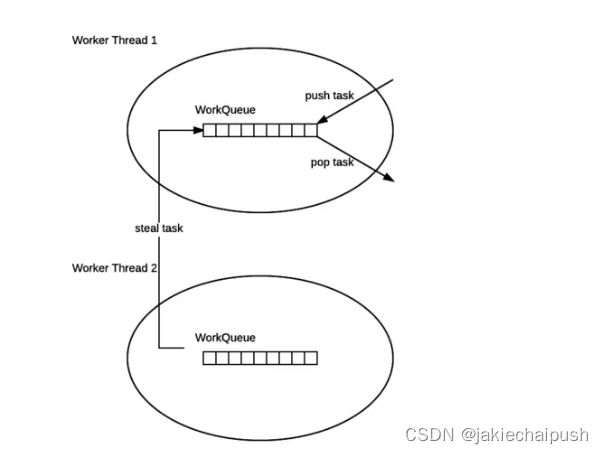
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争;工作窃取算法缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
这样做的主要原因是为了提高性能,通过始终选择最近提交的任务,可以增加资源仍分配在CPU缓存中的机会,这样CPU处理起来要快一些。而窃取者之所以从尾部获取任务,则是为了降低线程之间的竞争可能,毕竟大家都从一个部分拿任务,竞争的可能要大很多。此外,这样的设计还有一种考虑。由于任务是可分割的,那队列中较旧的任务最有可能粒度较大,因为它们可能还没有被分割,而空闲的线程则相对更有“精力”来完成这些粒度较大的任务。
- 工作队列
- WorkQueue 是双向列表,用于任务的有序执行,如果 WorkQueue 用于自己的执行线程 Thread,线程默认将会从尾端选取任务用来执行 LIFO。
- 每个 ForkJoinWorkThread 都有属于自己的 WorkQueue,但不是每个WorkQueue 都有对应的ForkJoinWorkThread。
- 没有ForkJoinWorkThread 的 WorkQueue 保存的是 submission,来自外部提交,在WorkQueues[] 的下标是 偶数位。