Flink集群搭建
1 安装包下载
根据自己的环境下载相应的flink安装包:https://flink.apache.org/downloads.html
下载的版本要与自己的scala版本一致,我安装的scala版本为2.11,所以要下载对应scala2.11版本的flink
我使用的环境linux-CentOS7.9、Scala-2.11.6、jdk-1.8、flink-1.7.2-bin-hadoop27-scala_2.11.tgz
2 上传到包到服务器解压
使用ftp或者sftp等将几个包上传到服务器并解压
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz
3 配置环境变量
vim /etc/profile
#flink
export FLINK_HOME=/home/hadoop/flink-1.7.2
export PATH=$FLINK_HOME/bin:$PATH
#jdk config
export JAVA_HOME=/home/hadoop/jdk1.8.0_291
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
#scala
export PATH=$PATH:/home/hadoop/scala-2.11.8/bin刷新文件后生效 source /etc/profile
4 flink配置
①配置 flink-conf.yaml
cd /home/hadoop/flink-1.7.2/conf
jobmanager.rpc.address: test01
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6124
# The heap size for the JobManager JVM
jobmanager.heap.size: 1024m
# 因为只开放了37600端口,所以更改了ssh端口
env.ssh.opts: -p 37600
# The heap size for the TaskManager JVM
taskmanager.heap.size: 1024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
rest.port: 8081②配置主节点 master
Vim master
test01:8081③配置从节点slaves
Vim slaves
test02
test03
test04flink-conf.yaml中配置key/value时候在“:”后面需要有一个空格,否则配置不会生效。
5 同步信息
scp /etc/profile root@test02:etc/profile
scp -r ./flink-1.7.2 root@test02:/home/hadoop
source /etc/proflie
scp /etc/profile root@test03:etc/profile
scp -r ./flink-1.7.2 root@test03:/home/hadoop
source /etc/proflie
scp /etc/profile root@test04:etc/profile
scp -r ./flink-1.7.2 root@test04:/home/hadoop
source /etc/proflie
6 启动flink集群
1 启动flink集群
[hadoop@test01 flink-1.7.2]$ ./bin/start-cluster.sh
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Starting cluster.
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Starting standalonesession daemon on host test01.
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Starting taskexecutor daemon on host test02.
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Starting taskexecutor daemon on host test03.
2 验证是否启动
JPS检验下
主节点和从节点分别可以看到StandaloneSessionClusterEntrypoint和TaskManagerRunner的2个进程
[hadoop@test01 flink-1.7.2]$ jps
31939 Jps
31596 StandaloneSessionClusterEntrypoint
[hadoop@test02 ~]$ jps
5488 Jps
4821 TaskManagerRunner
3 登录web界面 http://test01:8081
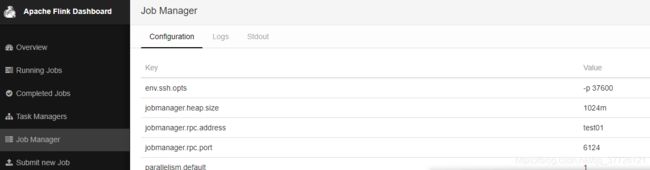
4集群测试
[hadoop@test01 flink-1.7.2]$ ./bin/start-scala-shell.sh remote test01 8081
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Starting Flink Shell:
Connecting to Flink cluster (host: test01, port: 8081).
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
F L I N K - S C A L A - S H E L L
NOTE: Use the prebound Execution Environments to implement batch or streaming programs.
Batch - Use the 'benv' variable
* val dataSet = benv.readTextFile("/path/to/data")
* dataSet.writeAsText("/path/to/output")
* benv.execute("My batch program")
HINT: You can use print() on a DataSet to print the contents to the shell.
Streaming - Use the 'senv' variable
* val dataStream = senv.fromElements(1, 2, 3, 4)
* dataStream.countWindowAll(2).sum(0).print()
* senv.execute("My streaming program")
HINT: You can only print a DataStream to the shell in local mode.
scala>
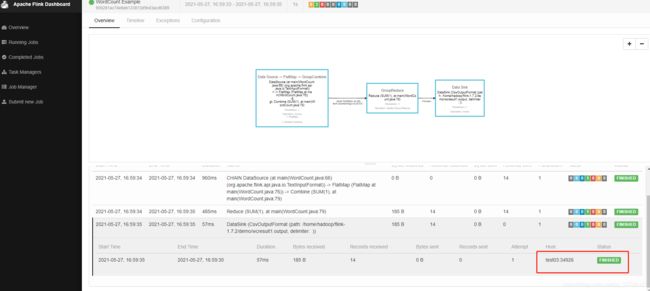
5 代码验证
[hadoop@test01 flink-1.7.2]$ ./bin/flink run ./examples/batch/WordCount.jar --input /home/hadoop/flink-1.7.2/demo/data.txt --output /home/hadoop/flink-1.7.2/demo/wcresult1.output
Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR was set.
Starting execution of program
Program execution finished
Job with JobID 650281ac74e8eb123813d5b43acd6389 has finished.
Job Runtime: 1550 ms
查看输出路径
可以看到任务在test03上跑的,所以打开test03查看输出文件
[hadoop@test03 demo]$ cat wcresult1.output
be 2
in 1
is 1
mind 1
nobler 1
not 1
or 1
question 1
suffer 1
that 1
the 2
this 1
to 3
whether 1
6 停止集群
stop-cluster.sh
参考链接:
https://blog.csdn.net/qq_38617531/article/details/86675403