OpenRisc-44-or1200的pipeline整体分析
引言
我们在前面分析了ORPSoC,or1200_top,和or1200_cpu的整体架构,在最近,我们也分析了or1200的pipeline(流水线)中的两级,EX级和IF级。
但是,我们还没有从宏观的角度,整体的了解一下or1200的流水线结构,本小节就做这件事情。
1,流水线
1>概述
关于流水线的概念,历史,划分等等这些内容,在很多文献里都提到过,而且我们之前也介绍过,这里不再展开阐述,如有疑问请参考:
http://blog.csdn.net/rill_zhen/article/details/8038697
或者
http://en.wikipedia.org/wiki/Pipeline_(computing)
2>or1200的流水线
在分析or1200的流水线之前,我们有必要先了解一下关于or1200_top(OpenRISC的一种实现,包括core和外围模块)。
下面一段内容来自官网的翻译:http://opencores.org/or1k/OR1200_OpenRISC_Processor
1》概述
or1200是一个32-bit的标量RISCharvard架构的微处理器。具有5级整型流水(没有fpu),支持MMU和基本的DSP处理能力。
默认配置下,or1200的dcache和icache都是8K直接映射,cacheline是16B。dcache和icache都是物理索引(也就是说cache的地址是物理地址,关于什么是物理索引,虚拟索引,虚拟物理混合索引,我们之前介绍过,请参考:http://blog.csdn.net/rill_zhen/article/details/9491095)。
默认配置下,or1200的dmmu和immu中的TLB都是基于散列的,映射方式采用直接映射,dtlb和itlb都是64 entry。
or1200除了最基本的模块外,还增加了debug,tt,pic,pm等模块。
2》基本架构组成
a,核心模块:CPU/DSP
b,兼容IEEE754单精度的FPU
c,直接映射数据cache
d,直接映射指令cache
e,基于散列DTLB的数据MMU
f,基于散列ITLB的指令MMU
g,具有功耗管理单元和功耗管理接口
h,嘀嗒定时器
i,中断控制器和中断接口
j,指令总线和数据总线都是wishbone B3
3》目前状态
or1200是稳定版本,并且已经在很多商用ASIC和FPGA上实现了。但是为了增加新的特性和进一步的完善它,所以开发还在继续。
4》验证
or1200利用or1ksin(or1200的simulator),在模拟器上跑了很多C和汇编程序。
5》调试接口
一般情况下,or1200都有一个debug nuit模块,和JTAG模块来实现对or1200的在线调试。
6》or1200的实现
or1200在0.18u 6LM工艺下,工作在150MHz时,测量其性能有150多个dhrystone,相当于2.1MIPS,MAC运算能力为150个。(Dhrystone是测量处理器运算能力的最常见基准程序之一,常用于处理器的整型运算性能的测量。程序是用C语言编写的,因此C编译器的编译效率对测试结果也有很大影响。Dhrystone的计量单位为每秒计算多少次Dhrystone,后来把在VAX-11/780机器上的测试结果1757 Dhrystones/s定义为1 Dhrystone MIPS(百万条指令每秒))。
如果采用默认配置,整个or1200所用的门的数量大概是40K个。
7》实现和性能统计
采用默认配置,在FPGA上实现的情况统计:
15K core cells (1850 FFs, 48 block RAMs) at 25MHz on Actel ProASIC3 technology
4K LUTs, 7 block RAM at 60MHz on Xilinx Virtex 5 technology
ORPSoC的性能统计:(benchmarks run within ORPmon)
OR1200, 8KByte/4KByte I/D cache, hardware multiply/divide disabled, @20MHz on Actel ProASIC3, SDR SDRAM
Dhrystone (120,000 runs): 17,000 Dhrystones/second
CoreMark 1.0 : 11.954573 (0.6 CoreMark/MHz) / GCC4.5.1-or32-1.0rc1 -O2 -msoft-mul -msoft-div -msoft-float / STACK
OR1200, 8KByte/4KByte I/D cache, hardware multiply/divide enabled, @20MHz on Actel ProASIC3, SDR SDRAM
Dhrystone (120,000 runs): 20,000 Dhrystones/second
CoreMark 1.0 : 25.773196 (1.25 CoreMark/MHz) / GCC4.5.1-or32-1.0rc1 -O2 -mhard-mul -mhard-div -msoft-float / STACK
OR1200, 32KByte/32KByte I/D cache, hardware multiply/divide enabled, @50MHz on Xilinx ML501
Dhrystone (500,000 runs): 50,000 Dhrystones/second
CoreMark 1.0 : 66.788100 (1.34 CoreMark/MHz) / GCC4.5.1-or32-1.0rc1 -O3 -mhard-mul -mhard-div -msoft-float -nostdlib / STACK
最小配置时,在FPGA上的实现:
7K core cells (1100 FFs, 4 block RAMs) at 35MHz on Actel ProASIC3 technology
2.4K LUTs, 1 block RAM at 125MHz on Xilinx Virtex 5 technology
2,or1200的流水线结构
1>a general picture
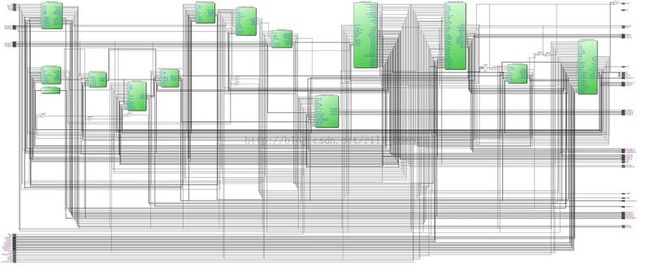
惯例,在分析or1200 core的流水线结构之前,我们先看一下or1200_cpu的所有模块的连接图,如下所示:
从中我们可以看出,整个or1200的CPU =内核一共由14个module组成。
2>or1200的流水线线结构
一般,在进行computer architecture design时,大体上分为两部分工作,一部分是数据通路的设计,另外一部分是控制通路的设计。所以,我们在分析or1200的架构时,也从这两个方面分析。
通过前面的介绍,我们知道or1200 的内核采用经典五级流水,由14个子模块组成,那么整体结构如何,各个流水线阶段都由那些子模块组成呢?如下所示:
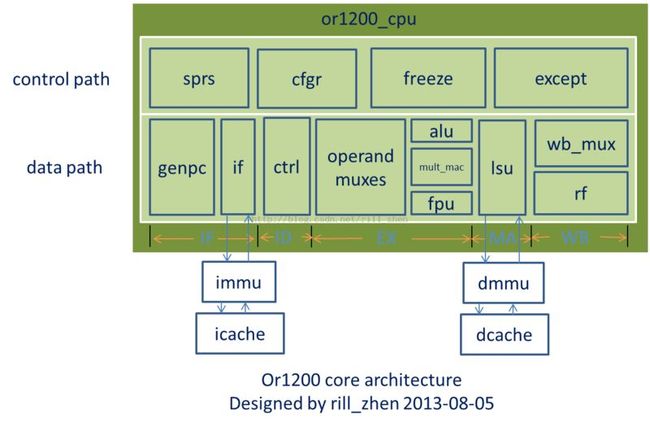
3>子模块功能
之前,我们已经分析了IF级和EX级的模块,请参考:
IF级:
http://blog.csdn.net/rill_zhen/article/details/9733811
EX级:
http://blog.csdn.net/rill_zhen/article/details/9700155
EX级需要说明的是fpu模块虽然从图中看是实现了浮点运算,但实际上这个模块内部什么都没有,不要以为有一个叫fpu的模块就说or1200支持浮点运算。
下面我们简单说一下其它三个流水线阶段。
ID级:
也就是指令解码阶段,这个阶段由ctrl一个模块组成,其功能就是根据IF级的if模块读取指令cache获得的指令,根据指令格式进行解析,产生各种控制信号。
MA级:
也就是访存阶段,这个阶段由lsu(load store unit)一个模块组成,其功能就是读写外部的主存,当然,要先经过dmmu和dcache两道关卡。
WB级:
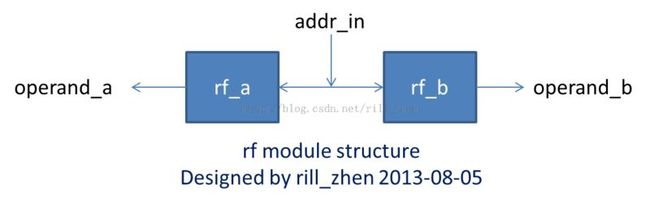
也就是写回阶段,这个阶段由wb_mux和rf两个模块组成,由于想进行写回操作的模块不止一个,所以需要一个mux。rf就是寄存器堆,其物理结构是两个双端口的RAM,值得注意的是这两个RAM的两个地址端口连在一起,而两个数据输出端口是分开的。而两个RAM分别存放第一个操作数和第二操作数,这样组织的结果就是只要一次写操作,同时写两个操作数,只需要一次读操作,就可以同时读到两个操作数。其结构如下:
3,小结
本小节从宏观的角度介绍了or1200的流水线的结构,并对每个流水阶段做了简单介绍。