java常用垃圾回收器G1和CMS有什么区别
在java中,虽然垃圾回收算法只有三种,也就是我们耳熟能详的标记清除算法(MS),复制算法(Copy),标记整理算法(MSC),这几个概念我在另一篇博客中有写到:java几种常见垃圾回收算法
但是由他们衍生出来的垃圾回收器却是很多的,从jdk1.8为界限,会将这几种常用的垃圾回收器做了总结和分类。
如下图所示:

看得出来,在前面这几种回收器中,新生代和老年代的回收算法不一样,所以经常搭配出现,我们重点说一下CMS和G1回收器。
注意:
对于Serial-Serial Old 和Parallel Scavenge-Parallel Old这两种垃圾回收器,新生代都采用复制回收算法,老年代采用标记整理算法,区别在于回收时采用一个还是多个线程,缺点也都很一致,就是会产生STW。
虽然CMS垃圾回收器比其他两种好,但是java8之前还算是默认使用的是PS-PO回收器。
一、ParNew-CMS(ConcurrentMarkSweep)回收器
与上图说的那样,parNew是一种新生代垃圾回收器,而CMS是一种老年代垃圾回收器,两者常作为搭档应用。
从他的名字ConcurrentMarkSweep我们就可以顾名思义,它是一种“并发标记清除算法”,新生代采用复制算法,老年代采用标记清除算法。
注意:
上面其他两种Serial Old和Parallel Old采用的是标记整理算法。
而标记清除算法是会产生内存碎片的,CMS怎么解决的呢?
解决这个问题的办法就是可以让CMS在进行一定次数的Full GC(标记清除)的时候进行一次标记整理算法,CMS提供了一下参数来控制:
-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5
也就是CMS在进行5次Full GC(标记清除)之后进行一次标记整理算法,从而可以控制老年带的碎片在一定数量以内,甚至可以配置CMS在每次Full GC的时候都进行内存的整理。
新生代采用复制算法,会暂停所有用户线程。
老年代采用CMS,而这种垃圾回收器的回收过程主要分成四个过程:
1、初始标记:
初始标记其实就是对被我们GC ROOT直接引用的对象做一个标记,在这个过程中将会触发一次STW(stop the word)机制,但是时间很短可以忽略。
2、并发标记:
在进行并发标记的过程中,我们的用户线程和CMS线程会一起执行。CMS所做的一件事情就是把堆里的所有引用对象全部找到并做标记。
但是在这个过程中可能会发生对象状态被改变的问题。
1、比如我的一个对象的引用链已经断开,变成了垃圾对象,但是CMS已经对他做过标记判断为非垃圾对象了怎么办?这就是在并发标记过程中产生的浮动垃圾(多标问题)
2、比如本来一个对象在CMS标记的过程中把他标记成了垃圾对象但是后来我们有引用了,结果在我们用的时候垃圾对象已经被干掉了,那我们是不是在引用这个对象的时候就会找不到这个垃圾对象。(漏标问题)这时候我们的第五步就产生了。
3. 预清理(CMS-concurrent-preclean),与用户线程同时运行;。
4. 可被终止的预清理(CMS-concurrent-abortable-preclean) 与用户线程同时运行;
5、重新标记:
在这一步,CMS会触发STW机制,并修复并发标记状态已经改变的对象,但是这个过程会比较漫长。他利用三色标记和增量更新来解决我们的漏标问题。
三色标记算法:
1、标记GC Roots为黑色
2、标记GC Roots引用的对象为灰色
3、其他对象为白色
将所有灰色对象放入队列之中,将灰色对象标记为黑色,将它的引用对象标记为灰色,重复这个步骤,直到没有了灰色对象,最终所有黑色对象就是存货对象。
为了解决上述漏标问题,在并发标记过程中所有被置空或加上指针的引用对象,都姑且算作活对象(尽管又可能它是死的),
6、并发清除:
那这一步就很好理解了,所谓的并发清理其实就是对没有被做标记的对象进行一个清理回收,在这个过程中同样不会产生STW。
7.并发重置:
重置本次GC过程中的标记数据,等待下次CMS的触发。
CMS回收器实际上是为了缩减另两种STW时间很长的回收器,而设计的,它的STW时间在毫秒级别,一般最高不超过100ms,但是依旧干不过G1,G1的STW时间,号称不过10ms,那么他是怎么实现的呢?
java11中的ZGC更是号称不过1ms,更牛逼!
补充:由上图可知,这几种新生代和老年代是可以分别互换使用的但是我们一般不会去互换它来用,需要注意的是,CMS在使用的时候,会留有一个Serial Old用来做替补,当并发清除的时候,用户产生的新的垃圾在内存中装不下的时候,就会触发Serial Old停止用户线程,再进行清除。
二、G1回收器
1、G1的简介
随着计算机软硬件的不断发展,我们用来存放对象的堆内存也随之越来越大,动辄数G甚至数十G,而这时候再使用串行和并行的回收方式,就显得不那么有效率,所以产生出来一个全新的垃圾回收方式——G1的回收方式。G1的牛逼之处在于,它和以往的回收算法大不相同,不能说没有关系,只能说毫不相干。。。
在jdk1.9之后,G1便是默认的垃圾回收器,用于替代CMS,而同时,一种回收器通吃新生代和老年代回收。
它主要有以下几个方面的改进:
1、G1可以设置STW的停顿时间,通过参数:-XX:MaxGCPauseMillis = N,默认250ms。
2、年轻代回收:STW,Parallel,Copy
3、老年代回收:Mostly-concurrent Marking(VS CMS),Increment Compaction。
几乎是一个实时回收算法(软实时)。
2、G1的内存布局
G1摒弃了以往的堆内存分代思想,而是将内存分为等大的区域块:利用参数 -XX:GCHeapRegionSize = N,默认2048个区域。并且每个区域不在固定,可以是Eden,也可以是Surviver也可以是Old,也就是说,这三个区域从此不再连续了,并且分配了一个Humongous区域(属于老年代)来存放那些大小超过一个区域的一半的超大对象,如图所示:

3、G1的回收过程
年轻代(Fully young GC):
G1在回收年轻代的时候,是会产生STW的,它不会回收整个堆,而是回收一个Collection Set(CS:回收区域集合)来进行回收,并且会估计整个Region的垃圾比例,优先回收垃圾占比高的Region。
但是这里必须考虑两个问题:
1、跨代引用(老年代对象持有年轻代引用)
2、不同Region之间互相引用
解决方法:
GC又将Region分成很多个卡片,并引入两个数据结构Card Table(用来记录卡片) 和 Remember Set(RS:被引用对象的Region用来记录引用对象的Card)。也就是说当两个Region有对象互相引用的时候,就会将引用对象的Card记录在另一个区域的RS里面,这样我们回收对象的时候,出现这种引用情况就不需要引用整个堆,而只需要扫描那个对应的Card就可以了,这是一个典型的“空换时”的概念。
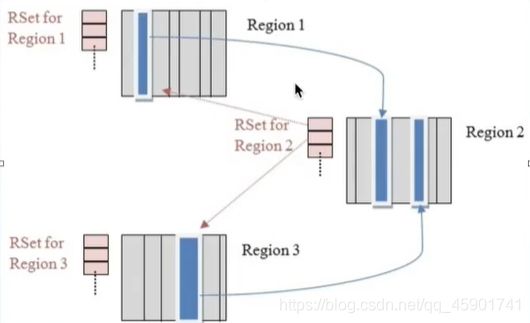
回收过程:
STW开始
1、构建CS(Collection Set)
2、扫描GC Roots
3、更新Remember Set :排空Card Dirty Queue
4、找到跨域引用的对象
5、复制算法(Mark Copy)进行回收:清空Eden,连同一个Survivor复制到另一个Survivor里面去。
6、记录每个阶段时间,进行自行调优
7、记录Eden/Survivor数量和GC时间,根据暂停目标进行Eden数量调整,看看是提升吞吐量还是降低吞吐量。
老年代(OldGC):
当堆用量到达一定程度时触发,利用参数 -XX:InitiatingHeapOccupancyPercent 控制,默认45%,是一种并发标记回收方式,利用三色标记算法进行标记回收。
回收过程:
1、STW开始,先进行一次Fully young GC,这也是为什么G1能横跨整个堆内存无视区域的原因。
2、恢复应用线程
3、并发初始标记
4、再次STW
- Remark重新标记,解决漏标问题
- CleanUp,回收所有全空的区域。
5、恢复应用线程。
注意上面我们老年代回收的时候,是直接清空了所有空区域,并没有进行复制操作,所有不会压缩老年代,这是CMS的问题,但是G1当然解决了,这时候G1中第三种回收算法就起了作用。
Mixed GC (混合GC)
Mixed GC不一定发生,选择若干个Region进行,默认1/8个区域,过程和年轻代完全一样,因为需要拷贝。