机器学习初学-多种集成学习算法
数据集Bank Customer | Kaggle
目录
■偏差和方差
它们是机器学习性能优化的风向标。弱模型的偏差很大,但是模型性能提高后,一旦过拟合,就会因为太依赖原始数据集而在其他数据集上产生高方差。
■Bagging算法
通常基于决策树算法基础之上,通过数据集的随机生成,训练出各种各样不同的树。而随机森林还在树分叉时,增加了对特征选择的随机性。随机森林在很多问题上都是一个很强的算法,可以作为一个基准。如果你们的算法能胜过随机森林,就很棒。
■Boosting算法
把梯度下降的思想应用在机器学习算法的优化上,使弱模型对数据的拟合逐渐增强。Boosting也常应用于决策树算法之上。这个思路中的Ada Boost、GBDT和XGBoost都是很受欢迎的算法。
■Stacking和Blending算法
用模型的预测结果,作为新模型的训练集。Stacking中使用了K折验证。
■Voting和Averaging算法
把几种不同模型的预测结果,做投票或者平均(或加权平均),得到新的预测结果。
■偏差和方差它们是机器学习性能优化的风向标。弱模型的偏差很大,但是模型性能提高后,一旦过拟合,就会因为太依赖原始数据集而在其他数据集上产生高方差。
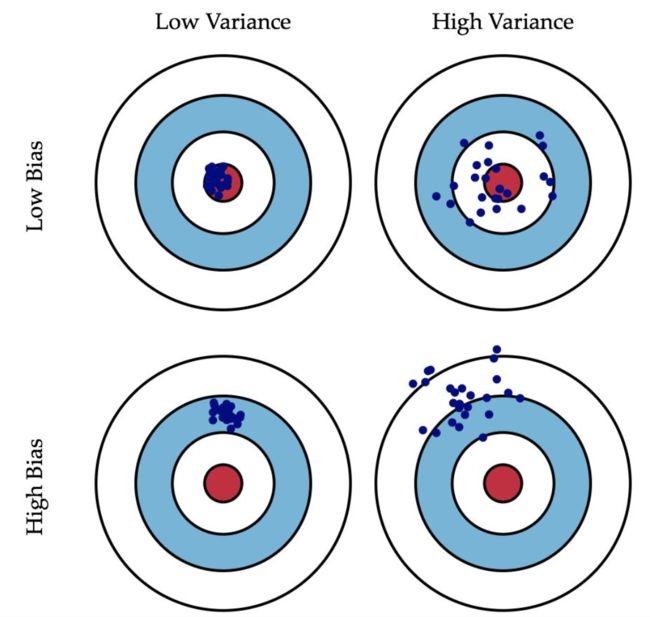
低偏差和低方差,是我们希望达到的效果,然而一般来说,偏差与方差是鱼与熊掌不可兼得的,这被称作偏差-方差窘境 (bias-variance dilemma)。
■给定一个学习任务,在训练的初期,模型对训练集的拟合还未完善,能力不够强,偏差也就比较大。正是由于拟合能力不强,数据集的扰动是无法使模型的效率产生显著变化的—此时模型处于欠拟合的状态,把模型应用于训练集数据,会出现高偏差。
■随着训练的次数增多,模型的调整优化,其拟合能力越来越强,此时训练数据的扰动也会对模型产生影响。
■当充分训练之后,模型已经完全拟合了训练集数据,此时数据的轻微扰动都会导致模型发生显著变化。当训练好的模型应用于测试集,并不一定得到好的效果—此时模型应用于不同的数据集,会出现高方差,也就是过拟合的状态。
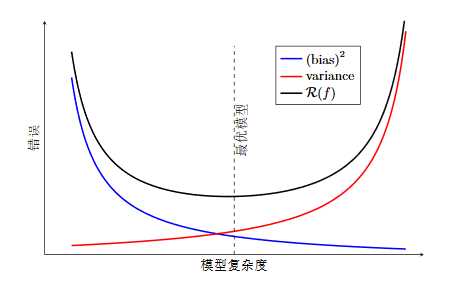
机器学习性能优化领域的最核心问题,就是不断地探求欠拟合-过拟合之间,也就是偏差-方差之间的最佳平衡点,也是训练集优化和测试集泛化的平衡点。

在训练初期,当模型很弱的时候,测试集和训练集上,损失都大。这时候需要调试的是机器学习的模型,或者甚至选择更好算法。这是在降低偏差。
在模型或者算法被优化之后,损失曲线逐渐收敛。但是过了一段时间之后,发现损失在训练集上越来越小,然而在测试集上逐渐变大。此时要集中精力降低方差。
因此,机器学习的性能优化是有顺序的,一般是先降低偏差,再聚焦于降低方差。
■Bagging算法,通常基于决策树算法基础之上,通过数据集的随机生成,训练出各种各样不同的树。而随机森林还在树分叉时,增加了对特征选择的随机性。随机森林在很多问题上都是一个很强的算法,可以作为一个基准。如果你们的算法能胜过随机森林,就很棒。
Bagging是我们要讲的第一种集成学习算法,是Bootstrap Aggregating的缩写。有人把它翻译为套袋法、装袋法,或者自助聚合,没有统一的叫法,就直接用它的英文名称。其算法的基本思想是从原始的数据集中抽取数据,形成K个随机的新训练集,然后训练出K个不同的模型。具体过程如下。
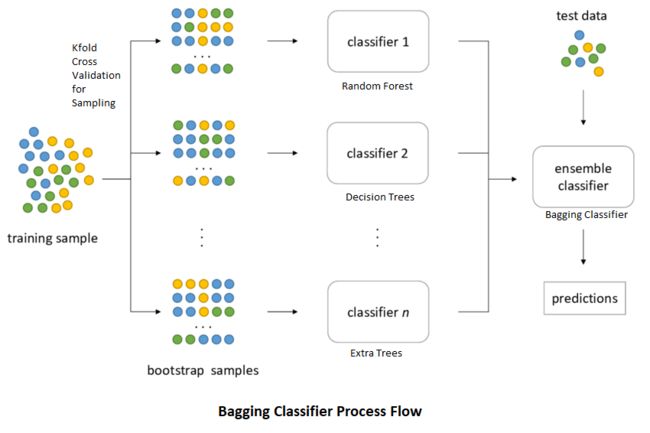
(1)从原始样本集中通过随机抽取形成K个训练集:每轮抽取n个训练样本(有些样本可能被多次抽取,而有些样本可能一次都没有被抽取,这叫作有放回的抽取)。这K个训练集是彼此独立的—这个过程也叫作bootstrap(可译为自举或自助采样),它有点像K折验证,但不同之处是其样本是有放回的。
(2)每次使用一个训练集通过相同的机器学习算法(如决策树、神经网络等)得到一个模型,K个训练集共得到K个模型。我们把这些模型称为基模型(base estimator),或者基学习器。
基模型的集成有以下两种情况。
■对于分类问题,K个模型采用投票的方式得到分类结果。
■对于回归问题,计算K个模型的均值作为最后的结果。
在Sklearn的集成学习库中,有BaggingClassifier和BaggingRegressor这两种Bagging模型,分别适用于分类问题和回归问题。
import numpy as np #导入Num Py库
import pandas as pd #导入Pandas库
df_bank = pd.read_csv("/kaggle/input/bank-customer/BankCustomer.csv") # 读取文件
df_bank.head() # 显示文件前5行数据
df_bank['Gender'].replace("Female", 0, inplace = True)
df_bank['Gender'].replace("Male", 1, inplace=True)
# 把多元类别转换成多个二元类别哑变量, 然后放回原始数据集
d_city = pd.get_dummies(df_bank['City'], prefix = "City")
df_bank = [df_bank, d_city]
df_bank = pd.concat(df_bank, axis = 1)
#df_bank是一个DataFrame对象,通过 pd.concat(df_bank, axis=1)表示将df_bank中的列按照水平方向进行连接,并返回一个新的DataFrame对象
# 构建特征和标签集合
y = df_bank ['Exited']
X = df_bank.drop(['Name', 'Exited', 'City'], axis=1)
X.head() #显示新的特征集
from sklearn.model_selection import train_test_split #拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)使用BaggingRegressor+决策树
# 对多棵决策树进行聚合(Bagging)
from sklearn.ensemble import BaggingClassifier #导入Bagging分类器
from sklearn.tree import DecisionTreeClassifier #导入决策树分类器
from sklearn.metrics import (f1_score, confusion_matrix) # 导入评估指标
对比在仅使用一个决策树的情况下 和 树的Bagging 的情况下的准确率和F1分数
dt = BaggingClassifier(DecisionTreeClassifier()) # 只使用一棵决策树
dt.fit(X_train, y_train) # 拟合模型
y_pred = dt.predict(X_test)# 进行预测
print("决策树测试准确率: {:.2f}%".format(dt.score(X_test, y_test)*100))
print("决策树测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
bdt = BaggingClassifier(DecisionTreeClassifier()) #树的Bagging
bdt.fit(X_train, y_train)# 拟合模型
y_pred = bdt.predict(X_test) # 进行预测
print("决策树Bagging测试准确率: {:.2f}%".format(bdt.score(X_test, y_test)*100))
print("决策树Bagging测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
在这里比较了只使用一棵决策树和经过Bagging之后的树这两种算法的预测效果,可以看到决策树Bagging的准确率及F1分数明显占优势。在没有调参的情况下,其验证集的F1分数达到57.47%。当然,因为Bagging过程的随机性,每次测试的分数都稍有不同。
如果使用决策树+Bagging+网格搜索来进行超参调优
from sklearn.model_selection import GridSearchCV # 导入网格搜索工具
bdt_param_grid = {
'estimator__max_depth': [5, 10, 20, 50, 100], # 决策树最大深度的候选值
'n_estimators': [1, 5, 10, 50] # 集成模型中决策树的数量的候选值
}
# 创建一个使用网格搜索的Bagging分类器模型
bdt_gs = GridSearchCV(
BaggingClassifier(DecisionTreeClassifier()), # 使用决策树作为基分类器的Bagging模型
param_grid=bdt_param_grid, # 参数网格
scoring='f1', # 使用F1分数作为评估指标
n_jobs=10, # 并行运行的作业数量n_jobs参数指定并行运行的作业数量。在机器学习和数据处理中,一些算法和工具支持并行计算,通过同时在多个处理器核心或线程上执行任务,可以加快任务的完成速度
verbose=1 # 输出详细信息
)
bdt_gs.fit(X_train, y_train) # 拟合模型
bdt_gs = bdt_gs.best_estimator_ # 最佳模型
y_pred = bdt.predict(X_test) # 进行预测
print("决策树Bagging测试准确率: {:.2f}%".format(bdt_gs.score(X_test, y_test)*100))
print("决策树Bagging测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
 测试准确率提升1%左右
测试准确率提升1%左右
准确率为何会提升?其中的关键正是降低了模型的方差,增加了泛化能力。因为每一棵树都是在原始数据集的不同子集上进行训练的,这是以偏差的小幅增加为代价的,但是最终的模型应用于测试集后,性能会大幅提升。
当我们说到集成学习,最关键的一点是各个基模型的相关度要小,差异性要大。异质性越强,集成的效果越好。两个准确率为99%的模型,如果其预测结果都一致,也就没有提高的余地了。 那么对树的集成,关键在于这些树里面每棵树的差异性是否够大。
在树的聚合中,每一次树分叉时,都会遍历所有的特征,找到最佳的分支方案。而随机森林在此算法基础上的改善就是在树分叉时,增加了对特征选择的随机性,而并不总是考量全部的特征。这个小小的改进,就在较大程度上进一步提高了各棵树的差异。
在决策树算法中,m代表在树的分叉过程中选择用于划分的特征数量。每次分叉时,决策树算法会从可用的特征集合中选择m个特征,并基于这些特征进行划分。通过选择不同的m值,可以控制决策树的分支数和模型的复杂度。
对于分类问题,一种常见的规则是将m设置为特征数的平方根。例如,如果有36个特征,那么m大约为6。这个规则的意义在于平衡模型的复杂度和效果。选择较小的m值可以限制每次分叉的特征数量,防止决策树过于深度和复杂,从而避免过拟合的问题。
对于回归问题,另一种常见的规则是将m设置为特征数的1/3。例如,如果有36个特征,那么m大约为12。与分类问题类似,选择较小的m值可以限制模型的复杂度,防止过度拟合。
具体来说,随机森林在每次分叉时,会随机选择一个小于或等于总特征数的m值作为每个决策树的特征子集大小。这个m值是在训练过程中自动调整的,并且可以防止每个决策树过于依赖于特定的特征,增加了模型的鲁棒性和泛化能力。
在大多数实现中,随机森林默认的m取值规则为:
- 对于分类问题,默认情况下,m被设置为特征数的平方根。
- 对于回归问题,默认情况下,m被设置为特征数的1/3。
在Sklearn的集成学习库中,也有RandomForestClassifier和RandomForestRegressor两种随机森林模型,分别适用于分类问题和回归问题。
下面用随机森林算法+网格搜索解决同样的问题,看一下预测效率:
from sklearn.ensemble import RandomForestClassifier # 导入随机森林模型
from sklearn.model_selection import GridSearchCV # 导入网格搜索函数
from sklearn.metrics import f1_score # 导入F1分数评估函数
rf = RandomForestClassifier() # 实例化一个随机森林模型
# 定义要优化的参数网格
rf_param_grid = {
"max_depth": [None], # 决策树的最大深度,None表示不限制
"max_features": [1, 3, 10], # 每棵决策树的最大特征数
"min_samples_split": [2, 3, 10], # 分裂一个节点所需的最小样本数
"min_samples_leaf": [1, 3, 10], # 每个叶子节点所需的最小样本数
"bootstrap": [True, False], # 是否使用自助法(bootstrap sampling)在随机森林模型中,如果 "bootstrap" 参数设置为 True,表示使用自助法进行采样。每个决策树将会根据这个训练数据集进行训练,从而构建一个随机森林模型。如果 "bootstrap" 参数设置为 False,表示不使用自助法进行采样,即每个决策树的训练数据集将是从原始数据集中无放回地抽样得到的一个子集。这会导致不同决策树之间的训练数据集没有重叠,一些样本可能在某些决策树的训练中没有出现。
"n_estimators": [100, 300], # 决策树的数量
"criterion": ["gini"] # 划分标准(衡量不纯度的指标)
}
rf_gs = GridSearchCV(rf, param_grid=rf_param_grid, scoring="f1", n_jobs=10, verbose=1)
# 使用网格搜索函数,传入随机森林模型 rf、参数网格 rf_param_grid、评分指标 "f1",
# n_jobs 是并行运行的作业数,verbose=1 打印更详细的执行过程
rf_gs.fit(X_train, y_train) # 使用训练数据集进行模型训练
rf_gs = rf_gs.best_estimator_ # 获取网格搜索后得到的最佳模型
y_pred = rf_gs.predict(X_test) # 使用最佳模型进行预测
accuracy = rf_gs.score(X_test, y_test) * 100 # 计算最佳模型在测试集上的准确率
f1 = f1_score(y_test, y_pred) * 100 # 计算最佳模型在测试集上的F1分数
print("随机森林测试准确率: {:.2f}%".format(accuracy))
print("随机森林测试F1分数: {:.2f}%".format(f1))
经历很长一段时间的训练后

准确率低0.25%但F1高2%左右,可见随机森林比数的聚合效果略好
从树的聚合到随机森林,增加了树生成过程中的随机性,降低了方差。顺着这个思路更进一步,就形成了另一个算法叫作极端随机森林,也叫更多树(extra tree)可以加快运算效率。仅需更换随机森林模型为ExtraTreesClassifier其他照旧。
from sklearn.ensemble import ExtraTreesClassifier# 导入极端随机森林模型
rf = ExtraTreesClassifier() # 极端随机森林模型前面说过,随机森林算法在树分叉时会随机选取m个特征作为考量,对于每一次分叉,它还是会遍历所有的分支,然后选择基于这些特征的最优分支。这本质上仍属于贪心算法(GreedyAlgorithm),即在每一步选择中都采取在当前状态下最优的选择。而极端随机森林算法一点也不“贪心”,它甚至不去考量所有的分支,而是随机选择一些分支,从中拿到一个最优解。
关于随机森林和极端随机森林算法的性能,有以下几点需要注意。
(1)随机森林算法在绝大多数情况下是优于极端随机森林算法的。
(2)极端随机森林算法不需要考虑所有分支的可能性,所以它的运算效率往往要高于随机森林算法,也就是说速度比较快。
(3)对于某些数据集,极端随机森林算法可能拥有更强的泛化功能。但是很难知道具体什么情况下会出现这样的结果,因此不妨各种算法都试试。
刚才的示例代码使用的都是上述算法的分类器版本。咱们再用一个实例来比较决策树、树的聚合、随机森林,以及极端随机森林在处理回归问题上的优劣。
处理回归问题要选择各种工具的Regressor(回归器)版本,而不是Classifier(分类器)。
这个示例是从Yury Kashnitsky发布在Kaggle上的一个Notebook的基础上修改后形成的,其中展示了4种树模型拟合一个随机函数曲线(含有噪声)的情况,其目的是比较4种算法中哪一种对原始函数曲线的拟合效果最好。
# 导入所需的库
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.ensemble import RandomForestRegressor, BaggingRegressor, ExtraTreesRegressor
from sklearn.tree import DecisionTreeRegressor
# 生成需要拟合的数据点—多次函数曲线
def compute(x):
return 1.5 * np.exp(-x ** 2) + 1.1 * np.exp(-(x - 2) ** 2)
# 将一维数组转为扁平化的一维数组
def f(x):
x = x.ravel()
return compute(x)
# 生成训练集和测试集
def generate(n_samples, noise):
X = np.random.rand(n_samples) * 10 - 4
X = np.sort(X).ravel()
y = compute(X) + np.random.normal(0.0, noise, n_samples)
X = X.reshape((n_samples, 1))
return X, y
# 生成训练集和测试集数据
X_train, y_train = generate(250, 0.15)
X_test, y_test = generate(500, 0.15)
# 用决策树回归模型拟合
dtree = DecisionTreeRegressor().fit(X_train, y_train)
d_predict = dtree.predict(X_test)
# 创建一个图表
plt.figure(figsize=(20, 12))
# 绘制第一个子图,决策树回归模型的拟合结果
plt.subplot(2, 2, 1)
plt.plot(X_test, f(X_test), "c")
plt.scatter(X_train, y_train, c="c", s=20)
plt.plot(X_test, d_predict, "g", lw=2)
plt.title("Decision Tree, MSE = %.2f" % np.sum((y_test - d_predict) ** 2))
# 用树的聚合回归模型拟合
bdt = BaggingRegressor(DecisionTreeRegressor()).fit(X_train, y_train)
bdt_predict = bdt.predict(X_test)
# 绘制第二个子图,树的聚合回归模型的拟合结果
plt.subplot(2, 2, 2)
plt.plot(X_test, f(X_test), "b")
plt.scatter(X_train, y_train, c="b", s=20)
plt.plot(X_test, bdt_predict, "y", lw=2)
plt.title("Bagging for Trees, MSE = %.2f" % np.sum((y_test - bdt_predict) ** 2))
# 用随机森林回归模型拟合
rf = RandomForestRegressor(n_estimators=10).fit(X_train, y_train)
rf_predict = rf.predict(X_test)
# 绘制第三个子图,随机森林回归模型的拟合结果
plt.subplot(2, 2, 3)
plt.plot(X_test, f(X_test), "b")
plt.scatter(X_train, y_train, c="b", s=20)
plt.plot(X_test, rf_predict, "r", lw=2)
plt.title("Random Forest, MSE = %.2f" % np.sum((y_test - rf_predict) ** 2))
# 用极端随机森林回归模型拟合
et = ExtraTreesRegressor(n_estimators=10).fit(X_train, y_train)
et_predict = et.predict(X_test)
# 绘制第四个子图,极端随机森林
plt.subplot(2, 2, 4)
plt.plot(X_test, f(X_test), "b")
plt.scatter(X_train, y_train, c="b", s=20)
plt.plot(X_test, et_predict, "purple", lw=2)
plt.title("Extra Trees, MSE = %.2f" % np.sum((y_test - et_predict) ** 2));
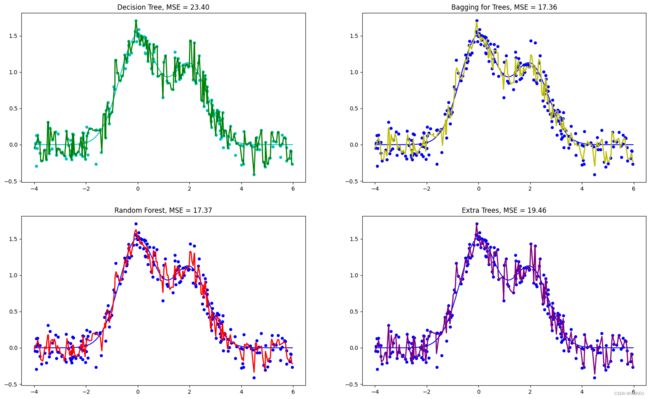 曲线越平滑过拟合越小,越贴近原函数 可见随机森林和决策树使用Bagging聚合表现较好
曲线越平滑过拟合越小,越贴近原函数 可见随机森林和决策树使用Bagging聚合表现较好
对于后3种集成学习算法,每次训练得到的均方误差都是不同的,因为算法内部均含有随机成分。经过集成学习后,较之单棵决策树,3种集成学习算法都显著地降低了在测试集上的均方误差。
■Boosting算法,把梯度下降的思想应用在机器学习算法的优化上,使弱模型对数据的拟合逐渐增强。Boosting也常应用于决策树算法之上。这个思路中的Ada Boost、GBDT和XGBoost都是很受欢迎的算法。
Boosting的基本思路是逐步优化模型。这与Bagging不同。Bagging是独立地生成很多不同的模型并对预测结果进行集成。
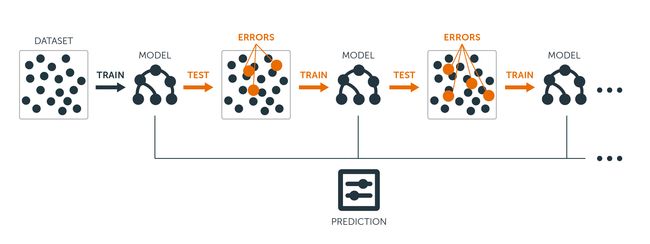
Boosting则是持续地通过新模型来优化同一个基模型,每一个新的弱模型加入进来的时候,就在原有模型的基础上整合新模型,从而形成新的基模型。而对新的基模型的训练,将一直聚集于之前模型的误差点,也就是原模型预测出错的样本(而不是像Bagging那样随机选择样本),目标是不断减小模型的预测误差。
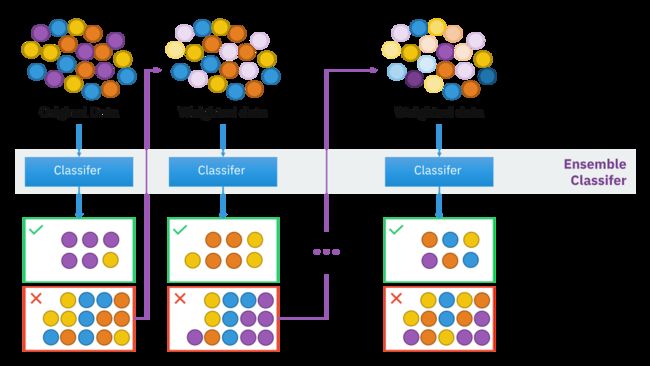
1.样本选择:Bagging算法是有放回的随机采样;而Boosting算法是每一轮训练集不变,只是训练集中的每个样例在分类器中的权重发生变化,而权重根据上一轮的分类结果进行调整。
2.样例权重:Bagging使用随机抽样,样例的权重;而Boosting根据错误率不断的调整样例的权重值,错误率越大则权重越大。
3.预测函数:Bagging所有预测模型的权重相等;而Boosting算法对于误差小的分类器具有更大的权重。
4.并行计算:Bagging算法可以并行生成各个基模型;而Boosting理论上只能顺序生产,因为后一个模型需要前一个模型的结果。
5.Bagging是减少模型的variance(方差);而Boosting是减少模型的Bias(偏度)。
6.Bagging里每个分类模型都是强分类器,因为降低的是方差,方差过高需要降低是过拟合。而Boosting里每个分类模型都是弱分类器,因为降低的是偏度,偏度过高是欠拟合。
Boosting是如何实现自我优化的呢?有以下两个关键步骤:
(1)数据集的拆分过程—Boosting和Bagging的思路不同。Bagging是随机抽取,而Boosting是在每一轮中有针对性的改变训练数据。具体方法包括:增大在前一轮被弱分类器分错的样本的权重或被选取的概率,或者减小前一轮被弱分类器分对的样本的权重或被选取的概率。通过这样的方法确保被误分类的样本在后续训练中受到更多的关注。
(2)集成弱模型的方法—也有多种选择。可通过加法模型将弱分类器进行线性组合,比如Ada Boost的加权多数表决,即增大错误率较小的分类器的权重,同时减小错误率较大的分类器的权重。而梯度提升决策树不是直接组合弱模型,而是通过类似梯度下降的方式逐步减小损失,将每一步生成的模型叠加得到最终模型。
从这个概念开始,让我们继续了解Boosting是如何在此基础上发展的。其中一些近年来已被用于在 Kaggle比赛中获得出色的表现!
实战中的Boosting算法,有Ada Boost、梯度提升决策树(GBDT),以及XGBoost等。这些算法都包含了Boosting提升的思想。也就是说,每一个新模型的生成都是建立在上一个模型的基础之上,具体细节则各有不同。
AdaBoost
该算法的基础是Boosting的主要核心:给予错误分类的观测值更多的权重。
特别是,AdaBoost 代表adaptive——自适应提升,意味着元学习器根据弱分类器的结果进行调整,为最后一个弱学习器的错误分类观察赋予更多权重。
Ada Boost是给不同的样本分配不同的权重,被分错的样本的权重在Boosting过程中会增大,新模型会因此更加关注这些被分错的样本,反之,正确样本的权重会减小。然后,将修改过权重的新数据集输入下层模型进行训练,最后将每次得到的基模型组合起来,也根据其分类错误率对模型赋予权重,集成为最终的模型。

注意带圆圈的 + 和 - 符号:如果分类错误,它们会增加,否则如果分类正确,它们会减少。
from sklearn.ensemble import AdaBoostClassifier # 导入Ada Boost模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV # 导入网格搜索工具
dt = DecisionTreeClassifier() # 选择决策树分类器作为Ada Boost的基准算法
ada = AdaBoostClassifier(base_estimator=dt) # Ada Boost模型
# 使用网格搜索优化参数
ada_param_grid = {
"base_estimator__criterion": ["gini", "entropy"],
"base_estimator__splitter": ["best", "random"],
"base_estimator__random_state": [7, 9, 10, 12, 15],
"algorithm": ["SAMME", "SAMME.R"],
"n_estimators": [1, 2, 5, 10],
"learning_rate": [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3, 1.5]
}
ada_gs = GridSearchCV(ada, param_grid=ada_param_grid, scoring="f1", n_jobs=10, verbose=1)
ada_gs.fit(X_train, y_train) # 拟合模型
ada_gs = ada_gs.best_estimator_ # 获取最佳模型
y_pred = ada_gs.predict(X_test) # 进行预测
print("Ada Boost测试准确率: {:.2f}%".format(ada_gs.score(X_test, y_test) * 100))
print("Ada Boost测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred) * 100))
述代码通过网格搜索来优化AdaBoost模型的参数。以下是参数优化的解释:
base_estimator__criterion: 决策树分类器的评判标准,可选值为"gini"和"entropy"。base_estimator__splitter: 决策树分类器的分裂策略,可选值为"best"和"random"。base_estimator__random_state: 决策树分类器的随机种子,用于控制每次训练时的随机性。algorithm: Ada Boost算法的类型,可选值为"SAMME"和"SAMME.R"。"SAMME"在每个分类器的权重更新中使用等同权重,"SAMME.R"使用预测概率进行权重更新。n_estimators: Ada Boost模型中的基础分类器数量。learning_rate: 每个基础分类器的贡献权重,控制着每个基础分类器的重要性。

目前最差结果
GBDT
梯度提升(GrandingBoosting)算法是梯度下降和Boosting这两种算法结合的产物。因为常见的梯度提升都是基于决策树的,有时就直接叫作GBDT,即梯度提升决策树(GrandingBoosting DecisionTree)。
不同于Ada Boost只是对样本进行加权,GBDT算法中还会定义一个损失函数,并对损失和机器学习模型所形成的函数进行求导,每次生成的模型都是沿着前面模型的负梯度方向(一阶导数)进行优化,直到发现全局最优解。
也就是说,GBDT的每一次迭代中,新的树所学习的内容是之前所有树的结论和损失,对其拟合得到一个当前的树,这棵新的树就相当于是之前每一棵树效果的累加。
梯度提升算法,对于回归问题,目前被认为是最优算法之一。
from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升模型
gb = GradientBoostingClassifier() # 梯度提升模型
# 使用网格搜索优化参数
gb_param_grid = {
'loss': ["log_loss"], # 损失函数选择为"deviance",对应梯度提升分类器的交叉熵损失
'n_estimators': [100, 200, 300], # 基础模型数量
'learning_rate': [0.1, 0.05, 0.01], # 学习率,控制每个基础模型的贡献程度
'max_depth': [4, 8], # 每个基础模型的最大深度
'min_samples_leaf': [100, 150], # 每个叶子节点的最小样本数,避免过拟合
'max_features': [0.3, 0.1] # 每个基础模型的特征采样比例,用于进一步随机化模型
}
gb_gs = GridSearchCV(gb, param_grid=gb_param_grid, scoring="f1", n_jobs=10, verbose=1)
gb_gs.fit(X_train, y_train) # 拟合模型
gb_gs = gb_gs.best_estimator_ # 获取最佳模型
y_pred = gb_gs.predict(X_test) # 进行预测
print("梯度提升测试准确率: {:.2f}%".format(gb_gs.score(X_test, y_test) * 100))
print("梯度提升测试F1分数: {:.2f}%".format(f1_score(y_test, y_pred) * 100))

目前最优结果
XGB
极端梯度提升(e Xtreme Gradient Boosting,XGBoost,有时候也直接叫作XGB)和GBDT类似,也会定义一个损失函数。不同于GBDT只用到一阶导数信息,XGBoost会利用泰勒展开式把损失函数展开到二阶后求导,利用了二阶导数信息,这样在训练集上的收敛会更快。
仅需更换GradientBoostingClassifier为XGBClassifier即可
from xgboost import XGBClassifier # 导入XGB模型
gb = XGBClassifier() # XGB模型”结果和GBDT效果相差不到0.5%
XGBoost(eXtreme Gradient Boosting)和GBDT(Gradient Boosting Decision Trees)都属于梯度提升算法的变体,它们在性能和适用情况上有一些区别。
1. 性能:
速度和扩展性:XGBoost相对于GBDT有更好的性能表现。XGBoost采用了一些优化技术,如按特征分块并行处理、近似直方图算法等,从而在处理大规模数据时具有更高的速度和更好的扩展性。
准确率:通常情况下,XGBoost和GBDT在准确率上没有显著的差异。它们都能够处理分类和回归任务,并且具有较强的泛化能力。
2. 适用情况:
数据规模:如果你的数据集规模较小(例如几千到几万的样本),并且对模型的准确性要求较高,那么使用GBDT可能是一个不错的选择。GBDT能够对数据进行更精细的拟合,并且其可解释性较好。
大规模数据:如果你的数据集规模较大(例如上百万甚至更多的样本),则XGBoost更适合。XGBoost通过并行处理和优化技术,可以高效地训练和预测大规模数据,而且通常能够获得与GBDT相近甚至更好的准确率。
特征维度:如果你的特征维度较高(即特征数量较多),XGBoost的处理能力可能更胜一筹。GBDT对高维数据的处理较为困难,容易出现维度灾难的问题。XGBoost则通过特征分块和稀疏特征优化等技术,能够更好地应对高维数据。
总之,XGBoost和GBDT都是强大的梯度提升算法,它们在性能和适用情况上有所区别。根据数据集的规模、维度和对模型性能的要求,选择适合的算法可以帮助获得更好的结果。
Bagging 就是在几乎不改变模型准确性的前提下尽可能减小模型的方差。因此 Bagging 中的基模型一定要为强模型,否则就会导致整体模型的偏差大,即准确度低。
Boosting 就是在几乎不改变模型方差的前提下减小模型的偏差。故 Boosting 中的基模型一定要为弱模型,否则就会导致整体模型的方差大(强模型容易过拟合,导致方差过大)。
在集成学习领域,通常将模型分为强模型(strong models)和弱模型(weak models)。强模型是指具有较高预测能力和复杂性的模型,而弱模型则是指预测能力较弱、复杂性较低的模型。
强模型:
1. 支持向量机(SVM):SVM 是一种复杂的模型,对于高维数据和非线性问题的分类和回归表现出色。它可以通过适当的核函数处理复杂的决策边界。
2. 随机森林(Random Forest):随机森林是一种基于决策树的集成学习方法,通过组合多个决策树模型来提高预测性能。它具有较强的泛化能力和鲁棒性。
3. 深度神经网络(Deep Neural Networks):深度神经网络是一类复杂的神经网络模型,具有多层隐藏层,可以学习非常复杂的特征表示和模式。弱模型:
1. 决策树(Decision Tree):决策树是一种基本的分类和回归模型,根据特征的条件进行分支和决策。它相对简单,容易理解和解释,但在处理复杂问题时可能出现过拟合的情况。
2. 朴素贝叶斯分类器(Naive Bayes Classifier):朴素贝叶斯分类器基于贝叶斯定理和特征之间的独立性假设,对分类问题进行建模。它是一种简单而有效的分类器,对于文本分类等任务常被使用。
3. K最近邻算法(K-Nearest Neighbors):K最近邻算法是一种基于实例的学习方法,根据最近邻样本的标签进行分类。它简单易懂,但对于高维数据和大规模数据集可能计算开销较大。需要注意的是,强模型和弱模型这一分类并非绝对,而是相对而言。有时候,一个模型在某些情况下可能是强模型,在另一些情况下可能是弱模型。此外,通过集成弱模型,可以形成强大的集成模型,提高整体的预测性能。
参考:
Bagging和Boosting区别 - 知乎
Bagging能降低方差的一种理解_为什么bagging模型(或者rf模型)能够降低方差_qq_41802245的博客-CSDN博客 Adaboost as a Classifier & Regressor - Medium
■Stacking和Blending算法,用模型的预测结果,作为新模型的训练集。Stacking中使用了K折验证。
集成学习分为两大类
■如果基模型都是通过一个基础算法生成的同类型的学习器,叫同质集成。
■有同质集成就有异质集成。异质集成,就是把不同类型的算法集成在一起。那么为了集成后的结果有好的表现,异质集成中的基模型要有足够大的差异性。
下面就是一些不同类型的模型之间相互集成的算法。
Stacking
先说异质集成中的Stacking(可译为堆叠)。其思路是,使用初始训练集学习若干个基模型之后,用这几个基模型的预测结果作为新的训练集的特征来训练新模型。Stacking算法的流程如下图所示。

基模型在异质类型中选择,如决策树、KNN、SVM或神经网络等,都可组合在一起。
(1)通常把训练集拆成K折(请大家回忆第1课中介绍过的K折验证)。
(2)利用K折验证的方法在其他K-1个fold上训练模型,在第K个fold上进行验证。
(3)这样训练K次之后,用训练好的模型对训练集整体进行最终训练,得到一个基模型。
(4)使用基模型预测训练集,得到对训练集的预测结果。
(5)使用基模型预测测试集,得到对测试集的预测结果。
(6)重复步骤(2)~(5),生成全部基模型和预测结果(比如CART、KNN、SVM以及神经网络,4组预测结果)。
(7)现在可以忘记训练集和测试集这两个数据集样本了。只需要用训练集预测结果作为新训练集的特征,测试集预测结果作为新测试集的特征去训练新模型。新模型的类型不必与基模型有关联。
from sklearn.model_selection import StratifiedKFold # 导入K折验证工具
def Stacking(model, train, y, test, n_fold):
folds = StratifiedKFold(n_splits=n_fold, random_state=1, shuffle=True) # 使用K折交叉验证
train_pred = np.empty((0, 1), float) # 初始化一个空的训练预测结果数组
test_pred = np.empty((0, 1), float) # 初始化一个空的测试预测结果数组
for train_indices, val_indices in folds.split(train, y.values):
# 依次获取每次K折交叉验证的训练集和验证集的索引
X_train, x_val = train.iloc[train_indices], train.iloc[val_indices] # 根据索引获取训练集和验证集的数据
y_train, y_val = y.iloc[train_indices], y.iloc[val_indices] # 根据索引获取训练集和验证集的标签
model.fit(X=X_train, y=y_train) # 在训练集上训练模型
train_pred = np.append(train_pred, model.predict(x_val)) # 对验证集进行预测并添加到训练预测结果数组中
test_pred = np.append(test_pred, model.predict(test)) # 使用训练好的模型对测试集进行预测,并将结果添加到测试预测结果数组中
return test_pred, train_pred # 返回测试集的预测结果和训练集的预测结果
from sklearn.tree import DecisionTreeClassifier # 导入决策树模型
model1 = DecisionTreeClassifier(random_state=1) # 创建一个决策树模型对象,设置随机种子为1
test_pred1, train_pred1 = Stacking(model=model1, n_fold=10, train=X_train, test=X_test, y=y_train) # 调用Stacking函数,使用决策树模型进行预测
train_pred1 = pd.DataFrame(train_pred1) # 将训练集的预测结果转换为DataFrame格式
test_pred1 = pd.DataFrame(test_pred1) # 将测试集的预测结果转换为DataFrame格式
from sklearn.neighbors import KNeighborsClassifier # 导入KNN模型
model2 = KNeighborsClassifier() # 创建一个KNN模型对象
test_pred2, train_pred2 = Stacking(model=model2, n_fold=10, train=X_train, test=X_test, y=y_train) # 调用Stacking函数,使用KNN模型进行预测
train_pred2 = pd.DataFrame(train_pred2) # 将训练集的预测结果转换为DataFrame格式
test_pred2 = pd.DataFrame(test_pred2) # 将测试集的预测结果转换为DataFrame格式
# 把上面的预测结果连接成一个新的特征集,标签保持不变,用回原始的标签集。最后使用逻辑回归模型对新的特征集进行分类预测:
# Stacking的实现—用逻辑回归模型预测新的特征集
X_train_new = pd.concat([train_pred1, train_pred2], axis=1) # 将训练集的预测结果按列连接起来,构成新的特征集
X_test_new = pd.concat([test_pred1, test_pred2], axis=1) # 将测试集的预测结果按列连接起来,构成新的特征集
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
model = LogisticRegression(random_state=1) # 创建一个逻辑回归模型对象,设置随机种子为1
model.fit(X_train_new, y_train) # 使用逻辑回归模型,在训练集上拟合模型
y_pred = model.predict(X_test_new) # 使用训练好的模型对测试集进行预测
accuracy = model.score(X_test_new, y_test) # 计算模型在测试集上的准确率
print("Stacking(KNN+决策树)+逻辑回归模型的准确率为: {:.2f}%".format(accuracy * 100)) # 打印准确率结果
Blending
再来说说Blending(可译为混合)。它的思路和Stacking几乎是完全一样的,唯一的不同之处在哪里呢?就是Blending的过程中不进行K折验证,而是只将原始样本训练集分为训练集和验证集,然后只针对验证集进行预测,生成的新训练集就只是对于验证集的预测结果,而不是对对全部训练集的预测结果。
■Voting和Averaging算法,把几种不同模型的预测结果,做投票或者平均(或加权平均)集成基模型的预测结果,得到新的预测结果。
Voting
Voting就是投票的意思。这种集成算法一般应用于分类问题。思路很简单。假如用6种机器学习模型来进行分类预测,就拥有6个预测结果集,那么6种模型,一种模型一票。如果是猫狗图像分类,4种模型被认为是猫,2种模型被认为是狗,那么集成的结果会是猫。当然,如果出现票数相等的情况(3票对3票),那么分类概率各为一半。
下面就用Voting算法集成之前所做的银行客户流失数据集,看一看Voting的结果能否带来F1分数的进一步提升。截止目前,针对这个问题我们发现的最好算法是随机森林和GBDT,随后的次优算法是极端随机森林、树的聚合和XGBoost,而支持向量机(SupportVectorMachine)和Ada Boost对于这个问题来说稍微弱一些,但还是比逻辑回归强很多(从这里也可以看出“集成学习算法家族”的整体实力是非常强的)。
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, ExtraTreesClassifier
from xgboost import XGBClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import f1_score
# 随机森林模型的调优结果 rf_gs
rf_gs = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
# 梯度提升树模型的调优结果 gb_gs
gb_gs = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
# 极端随机树模型的调优结果 ext_gs
ext_gs = ExtraTreesClassifier(n_estimators=100, max_features='sqrt', random_state=42)
# XGBoost模型的调优结果 xgb_gs
xgb_gs = XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
# AdaBoost模型的调优结果 ada_gs
ada_gs = AdaBoostClassifier(n_estimators=100, learning_rate=0.1, random_state=42)
# 创建Voting模型并配置各个子模型
voting = VotingClassifier(
estimators=[
('rf', rf_gs), # 随机森林模型
('gb', gb_gs), # 梯度提升树模型
('ext', ext_gs), # 极端随机树模型
('xgb', xgb_gs), # XGBoost模型
('ada', ada_gs) # AdaBoost模型
],
voting='soft', # 使用软投票策略
weights=[2, 5, 1, 1, 1], # 设置随机森林模型、梯度提升树模型的权重为2、5,其他模型权重为1
n_jobs=10 # 设置并行任务的数量
)
# 拟合模型
voting = voting.fit(X_train, y_train)
# 进行预测
y_pred = voting.predict(X_test)
# 计算并打印Voting模型的测试准确率
accuracy = voting.score(X_test, y_test) * 100
print("Voting测试准确率: {:.2f}%".format(accuracy))
# 计算并打印Voting模型的测试F1分数
f1 = f1_score(y_test, y_pred) * 100
print("Voting测试F1分数: {:.2f}%".format(f1))
Voting测试准确率: 86.50%
Voting测试F1分数: 58.33%
当然还可以集成更多模型:
from sklearn.ensemble import VotingClassifier # 导入Voting模型
from sklearn.linear_model import LogisticRegression # 导入逻辑回归模型
from sklearn.tree import DecisionTreeClassifier # 导入决策树模型
from sklearn.naive_bayes import GaussianNB # 导入朴素贝叶斯模型
from sklearn.ensemble import RandomForestClassifier # 导入随机森林模型
from sklearn.svm import SVC # 导入支持向量机模型
from sklearn.neighbors import KNeighborsClassifier # 导入K最近邻模型
from sklearn.neural_network import MLPClassifier # 导入多层感知机模型
from sklearn.ensemble import AdaBoostClassifier # 导入AdaBoost模型
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 导入线性判别分析模型
from sklearn.gaussian_process import GaussianProcessClassifier # 导入高斯过程模型
from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升树模型
from xgboost import XGBClassifier # 导入XGBoost模型
from sklearn.ensemble import ExtraTreesClassifier # 导入极端随机树模型
# 创建Voting模型并配置各个子模型
voting = VotingClassifier(
estimators=[
('lr', LogisticRegression()), # 逻辑回归模型
('dt', DecisionTreeClassifier()), # 决策树模型
('nb', GaussianNB()), # 朴素贝叶斯模型
('rf', RandomForestClassifier()), # 随机森林模型
('svm', SVC(probability=True)), # 支持向量机模型
('knn', KNeighborsClassifier()), # K最近邻模型
('mlp', MLPClassifier()), # 多层感知机模型
('ada', AdaBoostClassifier()), # AdaBoost模型
('lda', LinearDiscriminantAnalysis()), # 线性判别分析模型
('gp', GaussianProcessClassifier()), # 高斯过程模型
('gb', GradientBoostingClassifier()), # 梯度提升树模型
('xgb', XGBClassifier()), # XGBoost模型
('ext', ExtraTreesClassifier()) # 极端随机树模型
],
voting='soft', # 使用软投票策略
n_jobs=10 # 设置并行任务的数量
)
# 拟合模型
voting = voting.fit(X_train, y_train)
# 进行预测
y_pred = voting.predict(X_test)
# 计算并打印Voting模型的测试准确率
accuracy = voting.score(X_test, y_test) * 100
print("Voting测试准确率: {:.2f}%".format(accuracy))
# 计算并打印Voting模型的测试F1分数
f1 = f1_score(y_test, y_pred) * 100
print("Voting测试F1分数: {:.2f}%".format(f1))
【机器学习】集成学习投票法:投票回归器(VotingRegressor) & 投票分类器(VotingClassifier)_Avasla的博客-CSDN博客
Averaging
最后,还有一种更为简单粗暴的结果集成算法—Averaging,就是完全独立地进行几种机器学习模型的训练,训练好之后生成预测结果,最后把各个预测结果集进行平均
model1.fit(X_train, y_train)
model2.fit(X_train, y_train)
model3.fit(X_train, y_train)
pred_m1=model1.predict_proba(X_test)
pred_m2=model2.predict_proba(X_test)
pred_m3=model3.predict_proba(X_test)
pred_final=(pred_m1+pred_m2+pred_m3)/3 是不是很直接?
果觉得几个基模型中一种模型比另一种更好怎么办?
手动加权:
pred_final = (pred_m1*0.5+pred_m2*0.3+pred_m3*0.2)
即可
与通常只用于分类问题的Voting相比较,Averaging的优点在于既可以处理分类问题,又可以处理回归问题。分类问题是将概率值进行平均,而回归问题是将预测值进行平均,而且在平均的过程中还可以增加权重。
集成学习的核心思想就是训练出多个模型以及将这些模型进行组合。根据分类器的训练方式和组合预测的方法,集成学习模型中有可以降低方差的Bagging、有降低偏差的Boosting,以及各种模型结果的集成,如Stacking、Blending、Voting和Averaging等。