使用 PyTorch 完全分片数据并行技术加速大模型训练
本文,我们将了解如何基于 PyTorch 最新的 完全分片数据并行 (Fully Sharded Data Parallel,FSDP) 功能用 Accelerate 库来训练大模型。
动机
随着机器学习 (ML) 模型的规模、大小和参数量的不断增加,ML 从业者发现在自己的硬件上训练甚至加载如此大的模型变得越来越难。 一方面,人们发现大模型与较小的模型相比,学习速度更快 (数据和计算效率更高) 且会有显著的提升 [1]; 另一方面,在大多数硬件上训练此类模型变得令人望而却步。
分布式训练是训练这些机器学习大模型的关键。大规模分布式训练 领域最近取得了不少重大进展,我们将其中一些最突出的进展总结如下:
-
使用 ZeRO 数据并行 - 零冗余优化器 [2]
-
阶段 1: 跨数据并行进程 / GPU 对
优化器状态进行分片 -
阶段 2: 跨数据并行进程/ GPU 对
优化器状态 + 梯度进行分片 -
阶段 3: 跨数据并行进程 / GPU 对
优化器状态 + 梯度 + 模型参数进行分片 -
CPU 卸载: 进一步将 ZeRO 阶段 2 的
优化器状态 + 梯度卸载到 CPU 上 [3] -
张量并行 [4]: 模型并行的一种形式,通过对各层参数进行精巧的跨加速器 / GPU 分片,在实现并行计算的同时避免了昂贵的通信同步开销。
-
流水线并行 [5]: 模型并行的另一种形式,其将模型的不同层放在不同的加速器 / GPU 上,并利用流水线来保持所有加速器同时运行。举个例子,在第 2 个加速器 / GPU 对第 1 个 micro batch 进行计算的同时,第 1 个加速器 / GPU 对第 2 个 micro batch 进行计算。
-
3D 并行 [3]: 采用
ZeRO 数据并行 + 张量并行 + 流水线并行的方式来训练数百亿参数的大模型。例如,BigScience 176B 语言模型就采用了该并行方式 [6]。
本文我们主要关注 ZeRO 数据并行,更具体地讲是 PyTorch 最新的 完全分片数据并行 (Fully Sharded Data Parallel,FSDP) 功能。DeepSpeed 和 FairScale 实现了 ZeRO 论文的核心思想。我们已经将其集成到了 transformers 的 Trainer 中,详见博文 通过 DeepSpeed 和 FairScale 使用 ZeRO 进行更大更快的训练[10]。最近,PyTorch 已正式将 Fairscale FSDP 整合进其 Distributed 模块中,并增加了更多的优化。
Accelerate : 无需更改任何代码即可使用 PyTorch FSDP
我们以基于 GPT-2 的 Large (762M) 和 XL (1.5B) 模型的因果语言建模任务为例。
以下是预训练 GPT-2 模型的代码。其与 此处 的官方因果语言建模示例相似,仅增加了 2 个参数 n_train (2000) 和 n_val (500) 以防止对整个数据集进行预处理/训练,从而支持更快地进行概念验证。
run_clm_no_trainer.py
运行 accelerate config 命令后得到的 FSDP 配置示例如下:
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
fsdp_config:
min_num_params: 2000
offload_params: false
sharding_strategy: 1
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 2
use_cpu: false
多 GPU FSDP
本文我们使用单节点多 GPU 上作为实验平台。我们比较了分布式数据并行 (DDP) 和 FSDP 在各种不同配置下的性能。我们可以看到,对 GPT-2 Large(762M) 模型而言,DDP 尚能够支持其中某些 batch size 而不会引起内存不足 (OOM) 错误。但当使用 GPT-2 XL (1.5B) 时,即使 batch size 为 1,DDP 也会失败并出现 OOM 错误。同时,我们看到,FSDP 可以支持以更大的 batch size 训练 GPT-2 Large 模型,同时它还可以使用较大的 batch size 训练 DDP 训练不了的 GPT-2 XL 模型。
硬件配置: 2 张 24GB 英伟达 Titan RTX GPU。
GPT-2 Large 模型 (762M 参数) 的训练命令如下:
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-large \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
FSDP 运行截屏:

FSDP 运行截屏
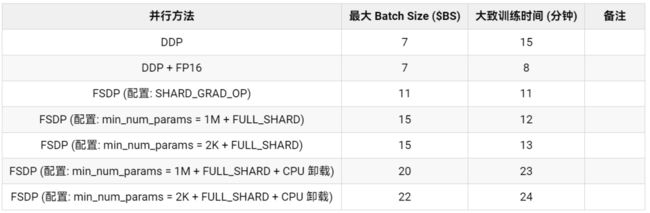
表 1: GPT-2 Large (762M) 模型 FSDP 训练性能基准测试
从表 1 中我们可以看到,相对于 DDP 而言,FSDP 支持更大的 batch size,在不使用和使用 CPU 卸载设置的情况下 FSDP 支持的最大 batch size 分别可达 DDP 的 2 倍及 3 倍。从训练时间来看,混合精度的 DDP 最快,其后是分别使用 ZeRO 阶段 2 和阶段 3 的 FSDP。由于因果语言建模的任务的上下文序列长度 ( --block_size ) 是固定的,因此 FSDP 在训练时间上加速还不是太高。对于动态 batch size 的应用而言,支持更大 batch size 的 FSDP 可能会在训练时间方面有更大的加速。目前,FSDP 的混合精度支持在 transformers 上还存在一些 问题。一旦问题解决,训练时间将会进一步显著缩短。
使用 CPU 卸载来支持放不进 GPU 显存的大模型训练
训练 GPT-2 XL (1.5B) 模型的命令如下:
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-xl \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
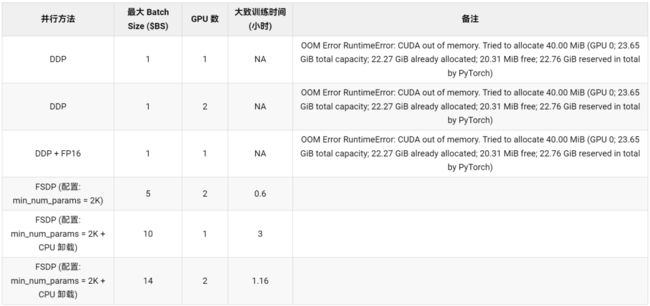
表 2: GPT-2 XL (1.5B) 模型上的 FSDP 基准测试
从表 2 中,我们可以观察到 DDP (带和不带 fp16) 甚至在 batch size 为 1 的情况下就会出现 CUDA OOM 错误,从而无法运行。而开启了 ZeRO- 阶段 3 的 FSDP 能够以 batch size 为 5 (总 batch size = 10 (5 2) ) 在 2 个 GPU 上运行。当使用 2 个 GPU 时,开启了 CPU 卸载的 FSDP 还能将最大 batch size 进一步增加到每 GPU 14。开启了 CPU 卸载的 FSDP 可以在单个 GPU 上训练 GPT-2 1.5B 模型,batch size 为 10。这使得机器学习从业者能够用最少的计算资源来训练大模型,从而助力大模型训练民主化。
Accelerate 的 FSDP 集成的功能和限制
下面,我们深入了解以下 Accelerate 对 FSDP 的集成中,支持了那些功能,有什么已知的限制。
支持 FSDP 所需的 PyTorch 版本: PyTorch Nightly 或 1.12.0 之后的版本。
命令行支持的配置:
-
分片策略: [1] FULL_SHARD, [2] SHARD_GRAD_OP
-
Min Num Params: FSDP 默认自动包装的最小参数量。
-
Offload Params: 是否将参数和梯度卸载到 CPU。
如果想要对更多的控制参数进行配置,用户可以利用 FullyShardedDataParallelPlugin ,其可以指定 auto_wrap_policy 、 backward_prefetch 以及 ignored_modules 。
创建该类的实例后,用户可以在创建 Accelerator 对象时把该实例传进去。
有关这些选项的更多信息,请参阅 PyTorch FullyShardedDataParallel 代码。
接下来,我们体会下 min_num_params 配置的重要性。以下内容摘自 [8],它详细说明了 FSDP 自动包装策略的重要性。

FSDP 自动包装策略的重要性
(图源: 链接)
当使用 default_auto_wrap_policy 时,如果该层的参数量超过 min_num_params ,则该层将被包装在一个 FSDP 模块中。官方有一个在 GLUE MRPC 任务上微调 BERT-Large (330M) 模型的示例代码,其完整地展示了如何正确使用 FSDP 功能,其中还包含了用于跟踪峰值内存使用情况的代码。
fsdp_with_peak_mem_tracking.py
我们利用 Accelerate 的跟踪功能来记录训练和评估期间的峰值内存使用情况以及模型准确率指标。下图展示了 wandb 实验台 页面的截图。

wandb 实验台
我们可以看到,DDP 占用的内存是使用了自动模型包装功能的 FSDP 的两倍。不带自动模型包装的 FSDP 比带自动模型包装的 FSDP 的内存占用更多,但比 DDP 少得多。与 min_num_params=1M 时相比, min_num_params=2k 时带自动模型包装的 FSDP 占用的内存略少。这凸显了 FSDP 自动模型包装策略的重要性,用户应该调整 min_num_params 以找到能显著节省内存又不会导致大量通信开销的设置。如 [8] 中所述,PyTorch 团队也在为此开发自动配置调优工具。
需要注意的一些事项
-
PyTorch FSDP 会自动对模型子模块进行包装、将参数摊平并对其进行原位分片。因此,在模型包装之前创建的任何优化器都会被破坏并导致更多的内存占用。因此,强烈建议在对模型调用
prepare方法后再创建优化器,这样效率会更高。对单模型而言,如果没有按照顺序调用的话,Accelerate会抛出以下告警信息,并自动帮你包装模型并创建优化器。FSDP Warning: When using FSDP, it is efficient and recommended to call prepare for the model before creating the optimizer
即使如此,我们还是推荐用户在使用 FSDP 时用以下方式显式准备模型和优化器:
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
+ model = accelerator.prepare(model)
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
- model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(model,
- optimizer, train_dataloader, eval_dataloader, lr_scheduler
- )
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
-
对单模型而言,如果你的模型有多组参数,而你想为它们设置不同优化器超参。此时,如果你对整个模型统一调用
prepare方法,这些参数的组别信息会丢失,你会看到如下告警信息:FSDP Warning: When using FSDP, several parameter groups will be conflated into a single one due to nested module wrapping and parameter flattening.
告警信息表明,在使用 FSDP 对模型进行包装后,之前创建的参数组信息丢失了。因为 FSDP 会将嵌套式的模块参数摊平为一维数组 (一个数组可能包含多个子模块的参数)。举个例子,下面是 GPU 0 上 FSDP 模型的有名称的参数 (当使用 2 个 GPU 时,FSDP 会把第一个分片的参数给 GPU 0, 因此其一维数组中大约会有 55M (110M / 2) 个参数)。此时,如果我们在 FSDP 包装前将 BERT-Base 模型的 [bias, LayerNorm.weight] 参数的权重衰减设为 0,则在模型包装后,该设置将无效。原因是,你可以看到下面这些字符串中均已不含这俩参数的名字,这俩参数已经被并入了其他层。想要了解更多细节,可参阅本 问题 (其中写道: 原模型参数没有 .grads 属性意味着它们无法单独被优化器优化 (这就是我们为什么不能支持对多组参数设置不同的优化器超参) )。
{
'_fsdp_wrapped_module.flat_param': torch.Size([494209]),
'_fsdp_wrapped_module._fpw_module.bert.embeddings.word_embeddings._fsdp_wrapped_module.flat_param': torch.Size([11720448]),
'_fsdp_wrapped_module._fpw_module.bert.encoder._fsdp_wrapped_module.flat_param': torch.Size([42527232])
}
-
如果是多模型情况,须在创建优化器之前调用模型
prepare方法,否则会抛出错误。 -
FSDP 目前不支持混合精度,我们正在等待 PyTorch 修复对其的支持。
工作原理
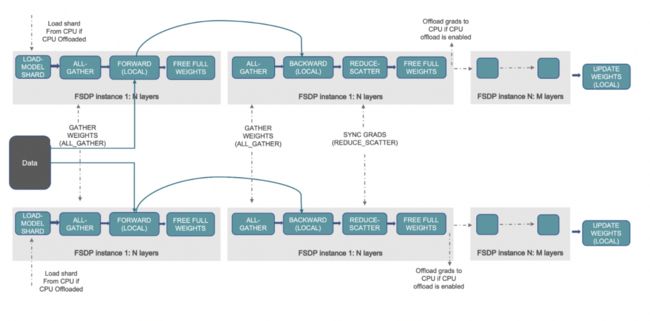
FSDP 工作流
(图源: 链接)
上述工作流概述了 FSDP 的幕后流程。我们先来了解一下 DDP 是如何工作的,然后再看 FSDP 是如何改进它的。在 DDP 中,每个工作进程 (加速器 / GPU) 都会保留一份模型的所有参数、梯度和优化器状态的副本。每个工作进程会获取不同的数据,这些数据会经过前向传播,计算损失,然后再反向传播以生成梯度。接着,执行 all-reduce 操作,此时每个工作进程从其余工作进程获取梯度并取平均。这样一轮下来,每个工作进程上的梯度都是相同的,且都是全局梯度,接着优化器再用这些梯度来更新模型参数。我们可以看到,每个 GPU 上都保留完整副本会消耗大量的显存,这限制了该方法所能支持的 batch size 以及模型尺寸。
FSDP 通过让各数据并行工作进程分片存储优化器状态、梯度和模型参数来解决这个问题。进一步地,还可以通过将这些张量卸载到 CPU 内存来支持那些 GPU 显存容纳不下的大模型。在具体运行时,与 DDP 类似,FSDP 的每个工作进程获取不同的数据。在前向传播过程中,如果启用了 CPU 卸载,则首先将本地分片的参数搬到 GPU/加速器。然后,每个工作进程对给定的 FSDP 包装模块/层执行 all-gather 操作以获取所需的参数,执行计算,然后释放/清空其他工作进程的参数分片。在对所有 FSDP 模块全部执行该操作后就是计算损失,然后是后向传播。在后向传播期间,再次执行 all-gather 操作以获取给定 FSDP 模块所需的所有参数,执行计算以获得局部梯度,然后再次释放其他工作进程的分片。最后,使用 reduce-scatter 操作对局部梯度进行平均并将相应分片给对应的工作进程,该操作使得每个工作进程都可以更新其本地分片的参数。如果启用了 CPU 卸载的话,梯度会传给 CPU,以便直接在 CPU 上更新参数。
如欲深入了解 PyTorch FSDP 工作原理以及相关实验及其结果,请参阅 [7,8,9]。
问题
如果在 accelerate 中使用 PyTorch FSDP 时遇到任何问题,请提交至 accelerate。
但如果你的问题是跟 PyTorch FSDP 配置和部署有关的 - 你需要提交相应的问题至 PyTorch。
参考文献
[1] Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers
[2] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[3] DeepSpeed: Extreme-scale model training for everyone - Microsoft Research
[4] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
[5] Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models
[6] Which hardware do you need to train a 176B parameters model?
[7] Introducing PyTorch Fully Sharded Data Parallel (FSDP) API | PyTorch
[8] Getting Started with Fully Sharded Data Parallel(FSDP) — PyTorch Tutorials 1.11.0+cu102 documentation
[9] Training a 1 Trillion Parameter Model With PyTorch Fully Sharded Data Parallel on AWS | by PyTorch | PyTorch | Mar, 2022 | Medium
[10] Fit More and Train Faster With ZeRO via DeepSpeed and FairScale
[11] https://huggingface.co/blog/zh/pytorch-fsdp