python 爬虫 m3u8 视频文件 加密解密 整合mp4
文章目录
-
- 一、完整代码
- 二、视频分析
-
- 1. 认识m3u8文件
- 2. 获取密钥,构建解密器
- 3. 下载ts文件
- 4. 合并ts文件为mp4
- 三、总结
一、完整代码
完整代码如下:
import requests
from multiprocessing import Pool
import re
import os
from tqdm import tqdm
from Crypto.Cipher import AES
# 创建临时文件夹
dirs = 'ts_list_need_to_merge/'
os.makedirs(dirs, exist_ok=True)
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'http://www.kpd510.me',
'Referer': 'http://www.kpd510.me/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
def parse_m3u8_text(m3u8_text):
m3u8_text = m3u8_text.split()
encode_info = [line for line in m3u8_text if line.startswith('#EXT-X-KEY:')][0]
pattern = r"#EXT-X-KEY:METHOD=(.*),URI=\"(.*)\""
## 获得加密method 和 key.key的url
match = re.search(pattern, encode_info)
if match:
method = match.group(1)
key_url = match.group(2)
else:
raise '解析失败'
## 获得ts文件url
ts_list = [line for line in m3u8_text if line.endswith('ts')]
return method, key_url, ts_list
def decrypt_content_and_save_file(filename, content, decrypter):
with open(filename, mode='wb') as f:
f.write(decrypter.decrypt(content))
def merge_ts_to_mp4(filename, ts_file_list):
with open(filename, mode='ab') as f1:
for ts_file in ts_file_list:
with open(ts_file, mode='rb') as f2:
f1.write(f2.read())
print(filename, '完成!')
def process_one_url(ts_url, key):
decrypter = AES.new(key, AES.MODE_CBC)
filename = dirs + os.path.split(ts_url)[-1]
content = requests.get(ts_url, headers=headers).content
decrypt_content_and_save_file(filename, content, decrypter)
return filename
def download_method_1(ts_list, key):
# 普通次序一个一个下载,耗时11分钟
ts_file_list = []
for ts_url in tqdm(ts_list):
filename = process_one_url(ts_url=ts_url, key=key)
ts_file_list.append(filename)
return ts_file_list
def download_method_2(ts_list, key, processes_nums=2):
# 多进程下载, 耗时1分钟
class CallBack:
def __init__(self, nums) -> None:
self.pbar = tqdm(total=nums)
self.filenames = []
def callback(self, filename):
self.pbar.update(1)
self.filenames.append(filename)
callback = CallBack(len(ts_list))
pool = Pool(processes=processes_nums)
for ts_url in ts_list:
pool.apply_async(process_one_url, (ts_url, key), error_callback=print, callback=callback.callback)
pool.close()
pool.join()
callback.pbar.close()
return [dirs + os.path.split(ts_url)[-1] for ts_url in ts_list]
if __name__ == "__main__":
m3u8_url = 'https://play.bo262626.com/20231108/xV1bY9Cn/700kb/hls/index.m3u8'
response = requests.get(m3u8_url, headers=headers)
m3u8 = response.text
method, key_url, ts_list = parse_m3u8_text(m3u8)
key_url = 'https://play.bo262626.com' + key_url
ts_list = ['https://play.bo262626.com' + item for item in ts_list]
key = requests.get(key_url, headers=headers).content
ts_file_list = download_method_2(ts_list, key=key, processes_nums=10)
merge_ts_to_mp4('test.mp4', ts_file_list)
二、视频分析
1. 认识m3u8文件
m3u8的结构详细分析可以看这个链接m3u8 文件格式详解 - 简书 (jianshu.com),这里我们只简要介绍一下;
相信无论多小白都应该知道如何打开开发者模型解析得到下面的结果;
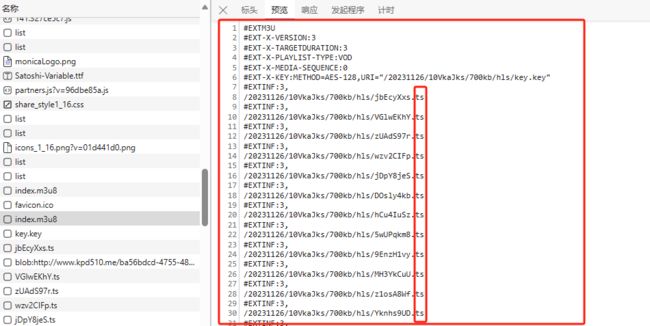
要注意的是,只有预览里面包含了ts信息的才算是我们需要的m3u8文件;大家可以看到左侧有两个index.m3u8,其中一个是没有ts信息的,所以我们直接忽略掉;现在我们先下载来,再来具体分析一下m3u8文件以及里面的内容分别表达什么意思;
下载代码如下:
import requests
import re
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'http://www.kpd510.me',
'Referer': 'http://www.kpd510.me/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
response = requests.get('https://play.bo262626.com/20231108/xV1bY9Cn/700kb/hls/index.m3u8', headers=headers)
m3u8 = response.text
m3u8文件的实质是一个视频的url列表,其中ts是计算器可以直接播放的视频格式文件,但是直接下载是可能被加了密的文件,我们需要m3u8文件内容信息进行解密;
我们可以这样理解,m3u8把一个完整的mp4视频切割成了很多的小块,每一个小块在m3u8都是ts文件格式,并在m3u8中采取了加密的措施,至于为什么要加密,这里就不多介绍;
在一般的视频爬取中,我们只需要考虑两个部分,一个是EXT-X-KEY,一个是ts;

其中EXT-X-KEY包含了ts的加密方式,ts包含了ts文件的下载地址;
在红色部分也就是EXT-X-KEY部分,我们可以从METHOD中获取到采取的加密方式是AES-128,同时看到URI的地址/20231126/10VkaJks/700kb/hls/key.key,这也就是AES加密密匙的地址:key.key,接下来我们写一个文件来对m3u8文件解析,目的是提取出红色部分和蓝色部分;
代码如下:
def parse_m3u8_text(m3u8_text):
m3u8_text = m3u8_text.split()
encode_info = [line for line in m3u8_text if line.startswith('#EXT-X-KEY:')][0]
pattern = r"#EXT-X-KEY:METHOD=(.*),URI=\"(.*)\""
## 获得加密method 和 key.key的url
match = re.search(pattern, encode_info)
if match:
method = match.group(1)
key_url = match.group(2)
else:
raise '解析失败'
## 获得ts文件url
ts_list = [line for line in m3u8_text if line.endswith('ts')]
return method, key_url, ts_list
## 在这里我们直接把m3u8文本丢进去就可以获得
## method, key_url, ts_list
method, key_url, ts_list = parse_m3u8_text(m3u8)
## method = 'AES-128'
## key_url = '/20231108/xV1bY9Cn/700kb/hls/key.key'
## ts_list = ['...ts', '...ts', ...]
2. 获取密钥,构建解密器
因为构建解密器我们需要密钥,而密钥存储在key.key中,首先我们需要解析key_url获取密钥;
在这里可以明显的看到key_url = '/20231108/xV1bY9Cn/700kb/hls/key.key'这不是一个完整的url,我们在这里加上获取m3u8请求的主域名便好;
代码如下:
headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'http://www.kpd510.me',
'Referer': 'http://www.kpd510.me/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
key_url = 'https://play.bo262626.com' + key_url
key = requests.get(key_url, headers=headers).content
# 这里我们得到key = b'388d590fabfeabcf' 是一个二进制结果
得到了密钥,再结合加密方式AES-128,我们就可以构建一个解密器,构建解密器代码如下:
from Crypto.Cipher import AES
## 这里网络爬取视频一般是MODE_CBC模式
decrypter = AES.new(key, AES.MODE_CBC)
这里要提起的是网络上的m3u8文件采取的加密一般是AES.MODE_CBC模式,在后续操作中如果这里出问题就换MODE一个一个试就好;
3. 下载ts文件
由于有许多的ts文件,我们有三种方法,第一是简单的requests请求一个一个下,这也是最费时的一种;第二个是多进程或者多线程的方式下载;第三个是采用协程的方式;接下来我们一个个实现;
在开始之间,ts_list存在同样的问题,就是需要重构url,这里代码如下:
ts_list = ['https://play.bo262626.com' + item for item in ts_list]
# 这里得到:
# ['https://play.bo262626.com/20231108/xV1bY9Cn/700kb/hls/o3jSJ9mc.ts',
# 'https://play.bo262626.com/20231108/xV1bY9Cn/700kb/hls/GNHDlClJ.ts',
# 'https://play.bo262626.com/20231108/xV1bY9Cn/700kb/hls/zKym5c6V.ts',
# 'https://play.bo262626.com/20231108/xV1bY9Cn/700kb/hls/4ll4NQH3.ts',
# 'https://play.bo262626.com/20231108/xV1bY9Cn/700kb/hls/RwUOniSQ.ts' ...]
再测试一下解密器是否可以:
import os
from tqdm import tqdm
dirs = 'ts_list_need_to_merge/'
os.makedirs(dirs, exist_ok=True)
def decrypt_content_and_save_file(filename, content):
with open(filename, mode='wb') as f:
f.write(decrypter.decrypt(content))
def process_one_url(ts_url, key):
decrypter = AES.new(key, AES.MODE_CBC)
filename = dirs + os.path.split(ts_url)[-1]
content = requests.get(ts_url, headers=headers).content
decrypt_content_and_save_file(filename, content, decrypter)
return filename
test_content = requests.get(ts_list[0], headers=headers).content
decrypt_content_and_save_file('test.ts', test_content)
## 打开视频看是否能打开
## 如果能打开说明解密没问题
直接requests: 代码如下
def download_method_1(ts_list, key):
# 这里弄一个filename_list 方便后续合并ts到mp4
ts_file_list = []
for ts_url in tqdm(ts_list):
filename = process_one_url(ts_url=ts_url, key=key)
ts_file_list.append(filename)
return ts_file_list
# 下载测试
ts_file_list = download_method_1(ts_list, key)
实现挺慢的,不合理;
多进程: 代码如下
def download_method_2(ts_list, key, processes_nums=2):
class CallBack:
def __init__(self, nums) -> None:
self.pbar = tqdm(total=nums)
self.filenames = []
def callback(self, filename):
self.pbar.update(1)
self.filenames.append(filename)
callback = CallBack(len(ts_list))
pool = Pool(processes=processes_nums)
for ts_url in ts_list:
pool.apply_async(process_one_url, (ts_url, key), error_callback=print, callback=callback.callback)
pool.close()
pool.join()
callback.pbar.close()
return [dirs + os.path.split(ts_url)[-1] for ts_url in ts_list]
ts_file_list = download_method_2(ts_list, key=key, processes_nums=10)
爬取巨快,1分钟下载20多分钟的视频;
4. 合并ts文件为mp4
在完成前面的步骤后,直接ab的方式把所有的文件按顺序加入就好;
def merge_ts_to_mp4(filename, ts_file_list):
with open(filename, mode='ab') as f1:
for ts_file in ts_file_list:
with open(ts_file, mode='rb') as f2:
f1.write(f2.read())
merge_ts_to_mp4('test.mp4', ts_file_list)
后续如果需要删除'ts_list_need_to_merge/'这个临时文件夹里面的所有内容,直接运行下面代码
import send2trash
send2trash.send2trash('ts_list_need_to_merge/') # send2trash.send2trash(dirs)
三、总结
别在图书馆测试这段代码!