Redis key过期删除机制实现分析
文章目录
- 前言
- Redis key过期淘汰机制
-
- 惰性删除机制
- 定时扫描删除机制
前言
当我们创建Redis key时,可以通过expire命令指定key的过期时间(TTL),当超过指定的TTL时间后,key将会失效。
那么当key失效后,Redis会立刻将其删除么?如果不会,那么何时Redis才将其真正的删除呢?我们来一起一探究竟。
Redis key过期淘汰机制
Redis中的key过期淘汰机制是由两种方式实现:
- 惰性删除机制
- 定时扫描删除机制
两种模式都不会在key达到过期时间后,第一时间删除key,而是等待特定的时机触发淘汰机制,这个很好理解,如果每一个key到达过期时间后,redis都需要第一时间检测到,并将其删除,那么将会消耗大量的资源,去实时的扫描全部key值,这显然是不合理的。
下面我们来看一下两种方式的具体实现机制。
惰性删除机制
惰性删除很简单,就是当有客户端的请求查询该 key 的时候,检查下 key 是否过期,如果过期,则删除该 key。
在此种模式下,触发key淘汰的时机,是将删除过期数据的主动权交给了每次访问请求。
那么Redis具体是如何实现的,我们来一起看一下源码实现。
淘汰删除的具体实现,在db.c的#expireIfNeeded():
int expireIfNeeded(redisDb *db, robj *key) {
/* 通过调用getExpire函数获取key的过期时间。*/
mstime_t when = getExpire(db,key);
mstime_t now;
/* 当过期时间小于0时,表示key没有设置过期时间,直接返回0 */
if (when < 0) return 0; /* No expire for this key */
/* 如果Redis正在进行数据加载,直接返回0,不进行后续的过期检查。 */
if (server.loading) return 0;
/* 获取当前时间,如果当前是在执行Lua脚本中,使用server.lua_time_start作为当前时间;否则,使用系统当前时间mstime作为当前时间 */
now = server.lua_caller ? server.lua_time_start : mstime();
/* 如果Redis是主从复制模式,并且当前节点是从节点,则直接返回当前时间是否大于过期时间,不进行后续的过期操作 */
if (server.masterhost != NULL) return now > when;
/* 如果当前时间小于等于过期时间,则直接返回0,表示key还没有过期 */
if (now <= when) return 0;
/* Delete the key */
/* 增加已过期key的数量统计 */
server.stat_expiredkeys++;
/* 向从节点发送key过期的命令,保证从节点也能及时删除过期的key */
propagateExpire(db,key);
/* 向Redis的事件通知机制发送key过期的事件通知 */
notifyKeyspaceEvent(REDIS_NOTIFY_EXPIRED,
"expired",key,db->id);
/* 删除已过期的key,并返回1表示删除成功 */
return dbDelete(db,key);
}
/* Delete a key, value, and associated expiration entry if any, from the DB */
int dbDelete(redisDb *db, robj *key) {
/* Deleting an entry from the expires dict will not free the sds of
* the key, because it is shared with the main dictionary. */
if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr);
if (dictDelete(db->dict,key->ptr) == DICT_OK) {
return 1;
} else {
return 0;
}
}
上面的源码即Redis执行key淘汰删除的核心过程,具体操作可以参见注释,通过方法名字expireIfNeeded()这是一个检查类型的方法,那么说明是在进行key操作时,会触发该方法进行检查key是否需要进行淘汰删除,那么其调用时机在何时呢?
在db.c的#lookupKeyRead()与lookupKeyWrite():
robj *lookupKeyRead(redisDb *db, robj *key) {
robj *val;
expireIfNeeded(db,key);
val = lookupKey(db,key);
if (val == NULL)
server.stat_keyspace_misses++;
else
server.stat_keyspace_hits++;
return val;
}
robj *lookupKeyWrite(redisDb *db, robj *key) {
expireIfNeeded(db,key);
return lookupKey(db,key);
}
robj *lookupKeyReadOrReply(redisClient *c, robj *key, robj *reply) {
robj *o = lookupKeyRead(c->db, key);
if (!o) addReply(c,reply);
return o;
}
robj *lookupKeyWriteOrReply(redisClient *c, robj *key, robj *reply) {
robj *o = lookupKeyWrite(c->db, key);
if (!o) addReply(c,reply);
return o;
}
上面的代码是调用expireIfNeeded()的上游function,通过名字可以看出,#lookupKeyRead()与lookupKeyWrite()是读取和写入key的方法(不得不说,redis的代码命名非常的优秀,值得我们学习),那么调用该方法的一定就是执行获取key的地方,这里我们以最简单的string的get命令为例:
在t_string.c的#getCommand():
/* string的get命令 */
void getCommand(redisClient *c) {
getGenericCommand(c);
}
int getGenericCommand(redisClient *c) {
robj *o;
/* 通过调用lookupKeyReadOrReply函数查找指定key的值,如果key不存在,则向客户端返回空值并返回REDIS_OK;如果查找到了key的值,则将值保存到变量o中,继续后续的操作 */
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL)
return REDIS_OK;
/* 判断获取到的值的类型是否为字符串类型 */
/* 如果值的类型不是字符串类型,向客户端返回错误响应,并返回REDIS_ERR表示获取失败 */
if (o->type != REDIS_STRING) {
addReply(c,shared.wrongtypeerr);
return REDIS_ERR;
} else {
/* 如果值的类型是字符串类型,向客户端返回获取到的字符串值,并返回REDIS_OK表示获取成功 */
addReplyBulk(c,o);
return REDIS_OK;
}
}
上述就是string get命令的执行过程,我们可以清晰的看到,redis是如何实现惰性淘汰删除机制,其他的数据结构,例如Hash、List、Set、Zset也是如此,这里就不一样贴出源码进行举例说明了,感兴趣的读者可以翻阅redis源码。
这里我们用一张string get命令的时序图,总结一下get命令的执行流程:
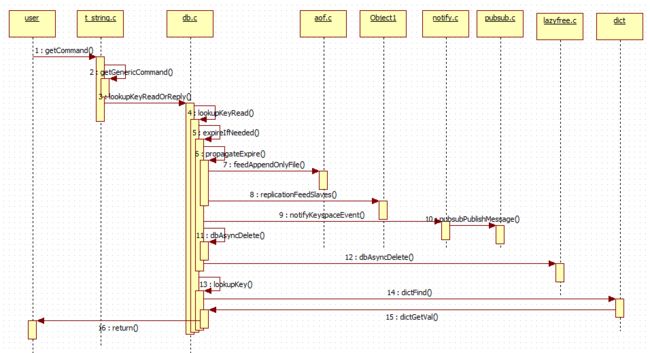
定时扫描删除机制
上面部分我们了解了惰性淘汰删除机制,但是仅仅靠客户端访问来判断 key 是否过期才执行删除肯定不够,因为有的 key 过期了,但未来再也没人访问,那岂不是GG,这些数据要怎么删除呢?
Redis在后台,会启动一个定时任务,定期扫描数据库中的所有key,检查它们的过期时间是否已到期。但是这里需要注意,定时任务并不是一次运行就检查所有的库,所有的键,而是随机检查一定数量的键。
为什么是随机抽查,而不是全量从头到尾扫描一遍?
很好理解,如果redis中的key特别多,如果进行全量扫描,那对redis的性能会存在巨大的影响,如果有一个亿的key,每次定时任务执行都进行全量扫描,CPU岂不是爆炸。

上图的流程图,简单的描述了定时任务的执行逻辑(实际上会复杂很多),还是老规矩,不多逼逼,上源码,Redis具体是如何实现的,我们来一起看一下源码实现。
定时任务的实现在redis.c的#activeExpireCycle():
void activeExpireCycle(int type) {
....此处省略部分前置逻辑
/* 循环redis全部的db */
for (j = 0; j < dbs_per_call; j++) {
....此处省略部分前置逻辑
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
/* 获取dict中设置了TTL的key集合中,计算集合的数量 */
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
....此处省略部分前置逻辑
/* 如果过期的key数量,超过了20,那么扫描数量设置为20 */
if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP; /* ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP = 20 */
/* 循环处理 */
while (num--) {
dictEntry *de;
long long ttl;
/* 获取dict中设置了TTL的key集合中,随机获取一个key */
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
/* 计算TTL剩余时间 */
ttl = dictGetSignedIntegerVal(de)-now;
/* 如果当前的key已经过期,则执行删除操作,并将过期key的数量加1 */
if (activeExpireCycleTryExpire(db,de,now)) expired++;
if (ttl < 0) ttl = 0;
ttl_sum += ttl;
ttl_samples++;
}
....此处省略部分后置逻辑
/* 如果过期的key数量,超过阈值的25%,继续循环,否则退出扫描 */
/* 这也就意味着在任何时候,过期 key 的最大数量等于每秒最大写入操作量除以4 = 5*/
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}
}
上面的代码就是定时任务扫描过期key的执行流程,笔者删除了部分代码,仅保留的核心执行部分,方便读者阅读,核心执行逻辑可以参见注释部分
如果用一句话概括说明定时任务的流程,那么可以总结为:
定时任务循环扫描每个redis数据库,从设置了TTL的key的集合中,随机挑选N个key进行检查,如果过期,干掉,否则跳过,直到过期key的数量小于25%,退出扫描
以上,就是Redis删除过期key的两种实现方式,由于笔者对C的理解很有限,因此仅仅截取了部分源码进行解读,也可能有很多解读不对的地方,望读者见谅。
事实上,仅仅通过惰性删除+定时任务扫描,仍会可能存在很多“漏网之鱼”,毕竟定时任务删除,并非全量扫描,那么如果Redis的使用容量达到了最大内存,Redis会如何操作?
这就涉及到了Redis的key淘汰策略,本篇的内容就此为止,关于Redis的淘汰策略解读,我们下次再聊。