【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(3)- 数据倾斜处理、分区示例
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 四、Rebalance 示例
-
- 1、实现
- 2、验证
- 五、物理分区
-
- 1、自定义分区
- 2、随机分区
- 3、Rescaling
- 4、广播
- 5、具体示例1
-
- 1)、测试文件数据
- 2)、实现代码
- 3)、验证
- 6、具体示例2
本文主要介绍Flink 的常用的operator 数据倾斜处理、数据分区 及详细示例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。本文maven依赖和User bean参考【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(1)- window join中的依赖。
本专题分为四篇文章介绍,即
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(1)- window join
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(2)- interval join
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(3)- 数据倾斜处理、分区示例
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例-完整版
四、Rebalance 示例
主要用于解决数据倾斜的情况。数据倾斜不一定时刻发生,验证的时候结果不一定能很明显。
1、实现
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author alanchan
*
* 数据倾斜,出现这种情况比较好的解决方案就是rebalance(内部使用round robin方法将数据均匀打散)
*/
public class TestRebalanceDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<Long> longDS = env.fromSequence(0, 10000);
// 下面的操作相当于将数据随机分配一下,有可能出现数据倾斜
DataStream<Long> filterDS = longDS.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long num) throws Exception {
return num > 10;
}
});
// transformation
// 没有经过rebalance有可能出现数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result1 = filterDS.map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();// 子任务id/分区编号
return new Tuple2(subTaskId, 1);
}
// 按照子任务id/分区编号分组,并统计每个子任务/分区中有几个元素
}).keyBy(t -> t.f0).sum(1);
// 调用了rebalance解决了数据倾斜
SingleOutputStreamOperator<Tuple2<Integer, Integer>> result2 = filterDS.rebalance().map(new RichMapFunction<Long, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long value) throws Exception {
int subTaskId = getRuntimeContext().getIndexOfThisSubtask();// 子任务id/分区编号
return new Tuple2(subTaskId, 1);
}
}).keyBy(t -> t.f0).sum(1);
// sink
result1.print("result1");
result2.print("result2");
// execute
env.execute();
}
}
2、验证
好像不太明显,从结果来看。
result1:3> (6,625)
result1:11> (1,625)
result1:2> (8,625)
result1:12> (0,625)
result1:7> (9,625)
result1:15> (3,615)
result1:1> (4,625)
result1:4> (14,625)
result1:7> (12,625)
result1:15> (7,625)
result1:1> (13,625)
result1:16> (2,625)
result1:13> (11,625)
result1:9> (10,625)
result1:16> (5,625)
result1:9> (15,625)
result2:3> (6,625)
result2:2> (8,626)
result2:9> (10,623)
result2:9> (15,624)
result2:15> (3,623)
result2:15> (7,624)
result2:11> (1,624)
result2:4> (14,625)
result2:16> (2,623)
result2:16> (5,625)
result2:13> (11,626)
result2:1> (4,623)
result2:1> (13,625)
result2:12> (0,624)
result2:7> (9,626)
result2:7> (12,624)
五、物理分区
Flink 也提供以下方法让用户根据需要在数据转换完成后对数据分区进行更细粒度的配置。

1、自定义分区
DataStream → DataStream
使用用户定义的 Partitioner 为每个元素选择目标任务。
dataStream.partitionCustom(partitioner, "someKey");
dataStream.partitionCustom(partitioner, 0);
2、随机分区
DataStream → DataStream
将元素随机地均匀划分到分区。
Java
dataStream.shuffle();
3、Rescaling
DataStream → DataStream
将元素以 Round-robin 轮询的方式分发到下游算子。如果你想实现数据管道,这将很有用,例如,想将数据源多个并发实例的数据分发到多个下游 map 来实现负载分配,但又不想像 rebalance() 那样引起完全重新平衡。该算子将只会到本地数据传输而不是网络数据传输,这取决于其它配置值,例如 TaskManager 的 slot 数量。
上游算子将元素发往哪些下游的算子实例集合同时取决于上游和下游算子的并行度。例如,如果上游算子并行度为 2,下游算子的并发度为 6, 那么上游算子的其中一个并行实例将数据分发到下游算子的三个并行实例, 另外一个上游算子的并行实例则将数据分发到下游算子的另外三个并行实例中。再如,当下游算子的并行度为2,而上游算子的并行度为 6 的时候,那么上游算子中的三个并行实例将会分发数据至下游算子的其中一个并行实例,而另外三个上游算子的并行实例则将数据分发至另下游算子的另外一个并行实例。
当算子的并行度不是彼此的倍数时,一个或多个下游算子将从上游算子获取到不同数量的输入。
请参阅下图来可视化地感知上述示例中的连接模式:
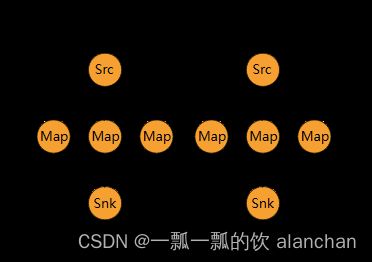
dataStream.rescale();
4、广播
DataStream → DataStream #
将元素广播到每个分区 。
dataStream.broadcast();
5、具体示例1
1)、测试文件数据
i am alanchan
i like flink
and you ?
2)、实现代码
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestPartitionDemo {
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source
DataStream<String> linesDS = env.readTextFile("D:/workspace/flink1.12-java/flink1.12-java/source_transformation_sink/src/main/resources/words.txt");
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = linesDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
}).setMaxParallelism(4);
// transformation
DataStream<Tuple2<String, Integer>> result1 = tupleDS.global();// 全部发往第一个task
DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast();// 广播
DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward();// 上下游并发度一样时一对一发送
DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle();// 随机均匀发送
DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance();// 再平衡
DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale();// 本地再平衡
DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new AlanPartitioner(), t -> t.f0);// 自定义分区
// sink
// result1.print("result1");
// result2.print("result2");
// result3.print("result3");
// result4.print("result4");
// result5.print("result5");
// result6.print("result6");
result7.print("result7");
// execute
env.execute();
}
private static class AlanPartitioner implements Partitioner<String> {
// 分区逻辑
@Override
public int partition(String key, int numPartitions) {
int part = 0;
switch (key) {
case "i":
part = 1;
break;
case "and":
part = 2;
break;
default:
part = 0;
break;
}
return part;
}
}
}
3)、验证
本示例验证可能比较麻烦,以下数据是基于本应用程序运行结果。
# 1、global,全部发往第一个task
result1:1> (i,1)
result1:1> (am,1)
result1:1> (alanchan,1)
result1:1> (i,1)
result1:1> (like,1)
result1:1> (flink,1)
result1:1> (and,1)
result1:1> (you,1)
result1:1> (?,1)
# 2、broadcast,广播,运行结果较长,下面不列出了
# 3、forward,上下游并发度一样时一对一发送
result3:16> (i,1)
result3:9> (and,1)
result3:4> (i,1)
result3:16> (am,1)
result3:4> (like,1)
result3:16> (alanchan,1)
result3:9> (you,1)
result3:9> (?,1)
result3:4> (flink,1)
# 4、shuffle,随机均匀发送
result4:7> (alanchan,1)
result4:7> (flink,1)
result4:7> (?,1)
result4:14> (i,1)
result4:14> (i,1)
result4:14> (and,1)
result4:16> (am,1)
result4:16> (like,1)
result4:16> (you,1)
# 5、rebalance,上面有示例展示过
result5:6> (and,1)
result5:4> (flink,1)
result5:8> (?,1)
result5:2> (i,1)
result5:3> (like,1)
result5:9> (i,1)
result5:7> (you,1)
result5:10> (am,1)
result5:11> (alanchan,1)
# 6、rescale,本地再平衡运行结果如下,由于数据量较少,效果不明显
result6:1> (i,1)
result6:1> (like,1)
result6:1> (flink,1)
result6:6> (and,1)
result6:6> (you,1)
result6:6> (?,1)
result6:13> (i,1)
result6:13> (am,1)
result6:13> (alanchan,1)
# 7、自定义分区,可见是按照i和and进行了分区,总共有三个分区,i都分在了第二个分区,and分在了第三个分区,其他的都分在了1个分区
result7:2> (i,1)
result7:2> (i,1)
result7:3> (and,1)
result7:1> (like,1)
result7:1> (flink,1)
result7:1> (am,1)
result7:1> (alanchan,1)
result7:1> (you,1)
result7:1> (?,1)
6、具体示例2
import java.util.Arrays;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.datastreamapi.User;
/**
* @author alanchan
*
*/
public class TestPartitionDemo2 {
// 构造User数据源
public static DataStreamSource<User> source(StreamExecutionEnvironment env) {
DataStreamSource<User> source = env.fromCollection(
Arrays.asList(
new User(1, "alan1", "1", "[email protected]", 12, 1000),
new User(2, "alan2", "2", "[email protected]", 19, 200),
new User(3, "alan1", "3", "[email protected]", 28, 1500),
new User(5, "alan1", "5", "[email protected]", 15, 500),
new User(4, "alan2", "4", "[email protected]", 30, 400))
);
return source;
}
// 数据分区示例
public static void mapPartitionFunction6(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
DataStream<User> userTemp = source.map(user -> {
User user2 = user;
user2.setAge(user.getAge() + 5);
return user2;
}).returns(User.class);
// public DataStream partitionCustom(Partitioner partitioner, KeySelector keySelector) {
// return setConnectionType(new CustomPartitionerWrapper<>(clean(partitioner),
// clean(keySelector)));
// }
DataStream<User> sink = userTemp.partitionCustom(new Partitioner<Integer>() {
public int partition(Integer key, int numPartitions) {
System.out.println("分区数:" + numPartitions);
if (key < 20)
numPartitions = 0;
else if (key >= 20 && key < 30)
numPartitions = 1;
else if (key >= 0)
numPartitions = 2;
System.out.println("分区数2:" + numPartitions);
return numPartitions;
}
}, new KeySelector<User, Integer>() {
@Override
public Integer getKey(User value) throws Exception {
return value.getAge();
}
});
sink.map((MapFunction<User, User>) user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
}).returns(User.class);
// System.out.println("并行数:" + sink.getParallelism());
// 输出结果,3个区,按照年龄分的
// 当前线程ID:138,user:User(id=3, name=alan1, pwd=3, [email protected], age=33, balance=1500.0)
// 当前线程ID:136,user:User(id=1, name=alan1, pwd=1, [email protected], age=17, balance=1000.0)
// 当前线程ID:138,user:User(id=4, name=alan2, pwd=4, [email protected], age=35, balance=400.0)
// 当前线程ID:140,user:User(id=2, name=alan2, pwd=2, [email protected], age=24, balance=200.0)
// 当前线程ID:140,user:User(id=5, name=alan1, pwd=5, [email protected], age=20, balance=500.0)
sink.print();
}
// lambda数据分区示例
public static void mapPartitionFunction7(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
DataStream<User> userTemp = source.map(user -> {
User user2 = user;
user2.setAge(user.getAge() + 5);
return user2;
}).returns(User.class);
DataStream<User> sink = userTemp.partitionCustom((key, numPartitions) -> {
if (key < 20)
numPartitions = 0;
else if (key >= 20 && key < 30)
numPartitions = 1;
else if (key >= 0)
numPartitions = 2;
return numPartitions;
}, user -> user.getAge());
sink.print();
}
// 按照用户id的奇数和偶数进行分区,如果id=1是单独分区
public static void mapPartitionFunction8(StreamExecutionEnvironment env) throws Exception {
DataStreamSource<User> source = source(env);
DataStream<User> sink = source.partitionCustom(new CusPartitioner(), user -> user.getId());
// 示例分区过程,输出结果如下
// 1> User(id=2, name=alan2, pwd=2, [email protected], age=19, balance=200.0)
// 当前线程ID:90,user:User(id=1, name=alan1, pwd=1, [email protected], age=12, balance=1000.0)
// 当前线程ID:89,user:User(id=3, name=alan1, pwd=3, [email protected], age=28, balance=1500.0)
// 2> User(id=3, name=alan1, pwd=3, [email protected], age=28, balance=1500.0)
// 当前线程ID:88,user:User(id=2, name=alan2, pwd=2, [email protected], age=19, balance=200.0)
// 当前线程ID:89,user:User(id=5, name=alan1, pwd=5, [email protected], age=15, balance=500.0)
// 1> User(id=4, name=alan2, pwd=4, [email protected], age=30, balance=400.0)
// 3> User(id=1, name=alan1, pwd=1, [email protected], age=12, balance=1000.0)
// 当前线程ID:88,user:User(id=4, name=alan2, pwd=4, [email protected], age=30, balance=400.0)
// 2> User(id=5, name=alan1, pwd=5, [email protected], age=15, balance=500.0)
sink.map((MapFunction<User, User>) user -> {
System.out.println("当前线程ID:" + Thread.currentThread().getId() + ",user:" + user.toString());
return user;
}).returns(User.class);
sink.print();
}
public static class CusPartitioner implements Partitioner<Integer> {
@Override
public int partition(Integer key, int numPartitions) {
if (key == 1)
numPartitions = 2;
else if (key % 2 == 0) {
numPartitions = 0;
} else {
numPartitions = 1;
}
return numPartitions;
}
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// source
// transformation
mapPartitionFunction8(env);
// sink
// execute
env.execute();
}
}
以上,本文主要介绍Flink 的常用的operator 数据倾斜处理、数据分区 及详细示例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为四篇文章介绍,即
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(1)- window join
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(2)- interval join
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例(3)- 数据倾斜处理、分区示例
【flink番外篇】2、flink的23种算子window join 和interval join 数据倾斜、分区介绍及详细示例-完整版