HttpComponents: 领域对象的设计
1. HTTP协议
1.1 HTTP请求
HTTP请求由请求头、请求体两部分组成,请求头又分为请求行(request line)和普通的请求头组成。通过浏览器的开发者工具,我们能查看请求和响应的详情。 下面是一个HTTP请求发送的完整内容。
POST https://track.abc.com/v4/track HTTP/1.1
Host: track.abc.com
Connection: keep-alive
Content-Length: 2048
Pragma: no-cache
Cache-Control: no-cache
sec-ch-ua: "Google Chrome";v="87", " Not;A Brand";v="99", "Chromium";v="87"
Accept: application/json, text/javascript, */*;
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Content-Type: application/x-www-form-urlencoded;charset=UTF-8
Origin: https://class.abc.com
Sec-Fetch-Site: same-site
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://class.abc.com/
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: HJ_UID=1fafb8b2-2a34-9cbe-e6ba-b8b4aabab4a1; _SREF_45=
d=2020&t=1609310840140
按照上面的理论,我们可以将这一个完整的请求拆分为3部分,请求行、请求头、请求体。
1. 请求行
POST https://track.abc.com/v4/track HTTP/1.1
POST用于指定请求的方法,此外还可以有OPTOINS GET HEAD PUT DELETE TRACE CONNECT等,更多详细解释可以参见RFC 2616。后面跟的https://track.abc.com/v4/track是我们要访问的资源URI。最后的HTTP/1.1指定了HTTP协议的版本,HTTP/1.1是目最常见的版本。
2. 请求头
Host: track.abc.com
Connection: keep-alive
Content-Length: 2048
Pragma: no-cache
Cache-Control: no-cache
Accept: application/json, text/javascript, */*;
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Content-Type: application/x-www-form-urlencoded;charset=UTF-8
Referer: https://class.abc.com/
Accept-Encoding: gzip, deflate, br
Cookie: HJ_UID=1fafb8b2-2a34-9cbe-e6ba-b8b4aabab4a1; _SREF_45=
| Header | 说明 |
|---|---|
| Host | 指定要访问的域名。请求行的域名会在客户端访问时转换为具体的IP。 Nginx是通过请求头的Host来将请求转发到不同的域名配置的。 |
| Connection | 用于指定连接保持的策略,这里的keep-alive是期望服务器保持连接,在后续的请求中直接复用当前连接。 |
| Pragma | 设置代理服务器(varnish)是否允许缓存,设置为no-cache时代理即使发现有缓存也会回源上层服务器。 |
| Cache-Control | 类是Pragma,不同的是这个请求体是HTTP 1.0时代的规范,请这个头同时支持做为响应头,但Pragma不能。 |
| Accept | 指定支持的MIME-TYPE |
| Content-Type | 指定请求内容类型以及编码 |
| Referer | 上一页地址 |
| Accept-Encoding | 支持的压缩方式 |
| Cookie | 符合当前请求的Cookie值 |
HTTP请求是无状态的,Java服务端的Session都是通过Cookie保存会话标识来实现的。 Chrome新版本加了Cookie跨域的逻辑,SameSite设置会影响Cookie上报,对应逻辑查看SameSite对应的笔记。
3. 请求体
d=2020&t=1609310840140
请求体的格式可以通过Content-Type指定,日常我们常用的有两种格式:
- Form表单提交,上面我们给定的就是Form表单提交的数据格式,通过
&符合切割字段,通过=连接字段名和字段值。 - JSON请求体,一般我们在SpringBoot后端通过@ResponseBody接收
1.2 HTTP响应
类似于HTTP请求,HTTP响应同样由响应头、响应内容两部分组成。 响应头有分为两类: 状态行、 响应头。 下面是一个HTTP响应的完整内容:
HTTP/1.1 200 OK
Date: Wed, 30 Dec 2020 06:47:20 GMT
Content-Length: 0
Connection: keep-alive
Server: nginx/1.14.0
Access-Control-Allow-Origin: https://class.abc.com
Access-Control-Allow-Methods: POST, GET, OPTIONS, DELETE
Access-Control-Max-Age: 86400
Access-Control-Allow-Headers: x-requested-with,Authorization,Cookie
Access-Control-Allow-Credentials: true
Set-Cookie: HJ_SSID_45=hsrein-fe2d-455c-a765-ce1b76647d4c; Domain=.abc.com; Expires=Wed, 30-Dec-2020 07:17:20 GMT; Path=/
Set-Cookie: _SREF_45=""; Domain=.abc.com; Expires=Thu, 01-Jul-2021 06:47:20 GMT; Path=/
Set-Cookie: HJ_CSST_45=0; Domain=.abc.com; Expires=Wed, 30-Dec-2020 07:17:20 GMT; Path=/
X-Via: 1.1 PS-000-01AdS239:3 (Cdn Cache Server V2.0)
X-Ws-Request-Id: 5fec2278_PS-000-01yOO242_18720-46076
{
"hj_vt": 1
}
1. 状态行
HTTP/1.1 200 OK
状态行有3部分组成,HTTP/1.1标识HTTP协议的版本号,200是我们的HTTP响应的状态码,OK是HTTP响应的描述。
目前的状态码分为5类:
| 状态码 | 描述 |
|---|---|
| 1xx | 请求已经接收,后台内部处理中 |
| 2xx | 请求成功 |
| 3xx | 重定向,需要客户端(浏览器)发起后续操作 |
| 4xx | 客户端错误 |
| 5xx | 服务端错误 |
2. 响应头
Date: Wed, 30 Dec 2020 06:47:20 GMT
Connection: keep-alive
Server: nginx/1.14.0
Access-Control-Allow-Origin: https://class.aaa.com
Set-Cookie: HJ_SSID_45=hsrein-fe2d-455c-a765-ce1b76647d4c; Domain=.bbb.com; Expires=Wed, 30-Dec-2020 07:17:20 GMT; Path=/
X-Via: 1.1 PS-000-01AdS239:3 (Cdn Cache Server V2.0)
X-Ws-Request-Id: 5fec2278_PS-000-01yOO242_18720-46076
| Header | 说明 |
|---|---|
| Date | 响应内容生成的时间 |
| Connection | 连接复用策略 |
| Access-Control-Allow-Origin | 允许跨域,https://class.aaa.com页面发起到当前接口跨域请求 |
| Set-Cookie | 向客户端写入Cookie |
2. 领域对象设计
设计良好的系统有清晰划分和边界,层层递进,领域对象设计很考验架构师的全局观。随意的继承、组合,很快就会变的不可维护,导致项目失败。
所谓的架构就是定义划分和边界,让系统的增长不受限于当初的定义的能力,具体的技术只是帮助实现这个定义的手段。
2.1 HttpMessage
HTTP请求和HTTP响应都继承了HttpMessage,HttpMessage提供HTTP头各种操作(读取、写入、遍历等)。
以下的代码是对HttpMessage的基本操作:
HttpMessage ht = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
ht.addHeader("Set-Cookie", "c1=a; path=/; domain=localhost");
ht.addHeader("Set-Cookie", "c2=b; path=\"/\", c3=c; domain=\"localhost\"");
Header h1 = ht.getFirstHeader("Set-Cookie");
System.out.println(h1);
Header h2 = ht.getLastHeader("Set-Cookie");
System.out.println(h2);
Header[] hs = ht.getHeaders("Set-Cookie");
System.out.println(hs.length);
遍历所有HTTP头:
HeaderIterator it = ht.headerIterator("Set-Cookie");
while (it.hasNext()) {
System.out.println(it.next());
}
通过BasicHeaderElementIterator解析HTTP头:
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
response.addHeader("Set-Cookie", "c1=a; path=/; domain=localhost");
response.addHeader("Set-Cookie", "c2=b; path=\"/\", c3=c; domain=\"localhost\"");
HeaderElementIterator it = new BasicHeaderElementIterator(response.headerIterator("Set-Cookie"));
while (it.hasNext()) {
HeaderElement elem = it.nextElement();
System.out.println(elem.getName() + " = " + elem.getValue());
NameValuePair[] params = elem.getParameters();
for (int i = 0; i < params.length; i++) {
System.out.println(" " + params[i]);
}
}
2.2 HTTP请求
HttpCore使用HttpRequest表示HTTP请求,我们可以通过下面这段代码创建一个最简单的HTTP请求:
HttpRequest request = new BasicHttpRequest("GET", "/index.html", HttpVersion.HTTP_1_1);
System.out.println(request.getRequestLine().getMethod()); // 输出 GET
System.out.println(request.getRequestLine().getUri()); // 输出 /index.html
System.out.println(request.getProtocolVersion()); // 输出 HTTP/1.1
System.out.println(request.getRequestLine().toString()); // 输出 GET /index.html HTTP/1.1
1. HttpRequest
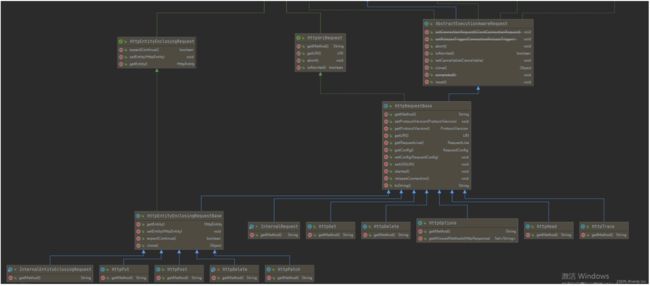
HttpCore提供了大量实现类,下面的图片是httpcore:4.4.13版本下的类继承结构
HttpMessage提供了HTTP头和HTTP协议版本号相关的操作。HttpRequest在HttpMessage的基础上额外提供了请求行。AbstractExecutionAwareRequest实现HttpMessage、HttpRequest,额外实现HttpExecutionAware查看是否取消、接收Cancellable对象取消请求。HttpUriRequest继承自HttpRequest,额外提供了获取HTTP方法、URI,运行取消执行(abort方法),以及查询是否已经取消(isAborted方法)HttpEntityEnclosingRequest继承自HttpRequest,额外提供携带请求体的能力(setEntity(HttpEntity entity))BasicHttpRequest提供了HttpRequest最基本的实现,对于只需要请求行、HTTP头的请求,可以直接使用。

2. HttpGet、HttpPost、HttpPut、HttpDelete等
HttpRequest的4个主要实现类中AbstractExecutionAwareRequest、HttpUriRequest共同做为HttpRequestBase的基类,提供不包含请求体的HTTP请求实现,我们常用的有HttpGet、HttpDelete、HttpOptions、HttpHead、HttpTrace。
HttpRequestBase组合HttpEntityEnclosingRequest提供实现类HttpEntityEnclosingRequestBase,它是所有包含请求体的HTTP请求实现,包括HttpPut、HttpPost、HttpDelete、HttpPatch。
2.3 HTTP响应
HttpCore使用HttpResponse表示HTTP响应,同样继承自HttpMessage,额外提供了状态行、响应体(HttpEntity)。通过下面的代码可以创建一个最简单的HTTP响应:
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
System.out.println(response.getProtocolVersion()); // 输出 HTTP/1.1
System.out.println(response.getStatusLine().getStatusCode()); // 输出 200
System.out.println(response.getStatusLine().getReasonPhrase()); // 输出 OK
System.out.println(response.getStatusLine().toString()); // 输出 HTTP/1.1 200 OK
1. HttpResponse
HttpResponse提供了获取状态行、状态码、状态描述,以及响应内容的方法。

2. BasicHttpResponse
HttpResponse只提供了两个实现类,常用的BasicHttpResponse封装普通HTTP响应,HttpResponseProxy供代理服务器使用。

2.4 HttpEntity
HttpCore抽象了HttpEntity表示请求体/响应体,回想一下,前面我们学习的HttpRequest有部分是实现了HttpEntityEnclosingRequest的可以携带HttpEntity向服务器提交数据。 HttpResponse都包含一个setEntity和getEntity方法,当然RFC文档定义,部分响应如302跳转不应该包含HttpEntity。
HttpCore官方将HttpEntity分为3类:
| 类型 | 说明 |
|---|---|
| streamed | 请求体内容来自于InputStream或者程序生成,因为流无法重复读取,导致HttpEntity内容只能被消费一次 |
| self-contained | 请求体内容存储在内存中,可以反复读取 |
| wrapping | 装饰器模式,请求体内容来自其他HttpEntity,额外包装处理后对外提供 |
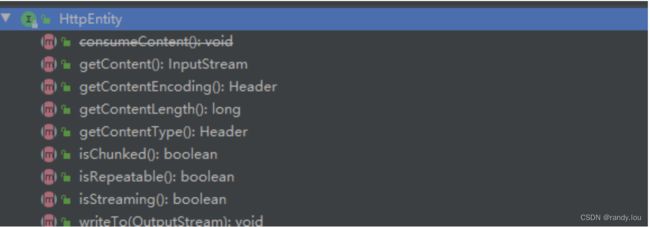
1. HttpEntity定义
HttpEntity的核心作用就是表示请求体,请求体会被用在输入和输出,基本上这也就确定了HttpEntity的接口定义。
- 我们要从请求体读取数据,于是定义了
InputStream HttpEntity#getContent() - 我们要将请求体发送到服务端(写到输出流),于是定义了
void HttpEntity#writeTo(OutputStream) - 服务端需要知道我们发送的是图片还是文本,于是定义了
Header HttpEntity#getContentType() - 服务端需要知道我们发送的文本用什么编码,于是定义了
Header HttpEntity#getContentEncoding()
创建HttpEntity要提供ContentType对象,用于定于HttpEntity包含的内容及编码,后面的HTTP协议拦截器会协助我们处理HTTP头和HttpEntity的关系。
- 发送
HttpEntity的时候HTTP协议拦截器会自动从HttpEntity读取ContentType,并在HttpRequest下添加HTTP头Content-Type。 - 接收
HttpResponse初始化HttpEntity时,通过HTTP协议拦截器自动从Content-Type头读取并设置HttpEntity的ContentType。
HttpEntity有大量的实现类,我们来看一个最简单的HttpEntity初始化:
StringEntity myEntity = new StringEntity("important message", Consts.UTF_8); // 默认ContentType是text/plain
System.out.println(myEntity.getContentType()); // 输出 Content-Type: text/plain; charset=UTF-8
System.out.println(myEntity.getContentLength()); // 将字符串转为字节数组后的长度
System.out.println(EntityUtils.toString(myEntity)); // 构造函数传入的字符串
System.out.println(EntityUtils.toByteArray(myEntity).length); // 将字符串转为字节数组后的长度
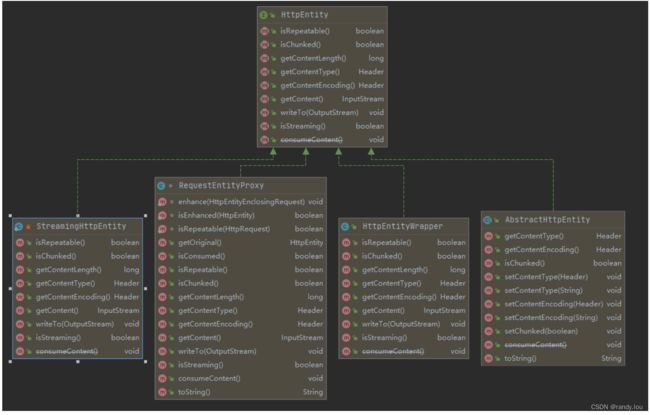
HttpEntity有4组实现类:
-
RequestEntityProy,用于实现代理服务器 -
StreamingHttpEntity,提供Body对象,将Body.writeTo方法写OutputStream,适用于生成InputStream开销大的场景 -
HttpEntityWrapper,装饰器模式,主要用于实现压缩、解压

-
AbstractHttpEntity,最实用的实现,它是我们常用的StringEntity、InputStreamEntity、BasicHttpEntity、FileEntity、ByteArrayEntity等的父类
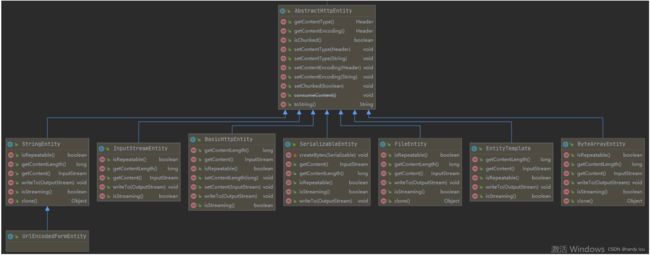
1. BasicHttpEntity
BasicHttpEntity提供无参构造函数,默认表示空的HttpEntity。 通过BasicHttpEntity#setContent传入InputStream,BaiscHttpEntity#setContentLength设置HttpEntity长度,能构造出有实际能容的HttpEntity。
我们看一个简单的示例:
BasicHttpEntity e = new BasicHttpEntity();
e.setContent(new ByteArrayInputStream("helloworld".getBytes()));
e.setContentLength(-1);
2. ByteArrayEntity
ByteArrayEntity属于self-contained的HttpEntity,只需要提供byte数组即可构建。
我们看一个简单的示例:
ByteArrayEntity myEntity = new ByteArrayEntity(new byte[] {1,2,3}, ContentType.APPLICATION_OCTET_STREAM);
3. StringEntity
StringEntity也是self-contained的HttpEntity, 有3种构造方式:
HttpEntity myEntity1 = new StringEntity(sb.toString()); // 默认MIME-TYPE为text/plain,默认编码 ISO-8859-1
HttpEntity myEntity2 = new StringEntity(sb.toString(), Consts.UTF_8); // 默认MIME-TYPE为text/plain,自己指定编码
HttpEntity myEntity3 = new StringEntity(sb.toString(), ContentType.create("text/plain", Consts.UTF_8)); // 自己字段MIME-TYPE和编码
4. InputStreamEntity
通过InputStream构建,允许传入要读取的字节数(-1表示不限)。比较使用的场景是前端提交一个文件后我们拿到一个输入流,通过这个流我们再上传到文件到分布式文件系统。
我们看一个简单的示例:
InputStream instream = getSomeInputStream();
InputStreamEntity myEntity = new InputStreamEntity(instream, 16);
5. FileEntity
通过提供一个File对象构建,是self-contained类型的HttpEntity。
我们看一个简单的示例:
HttpEntity entity = new FileEntity(staticFile,ContentType.create("application/java-archive"));
6. BufferedHttpEntity
BufferedHttpEntity继承自HttpEntityWrapper,使用装饰器模式,将其他类型的HttpEntity转为self-contained类型,内部实现是将其他类型的HttpEntity内容读取并缓存在内存中。
我们看一个简单的示例:
myNonRepeatableEntity.setContent(someInputStream);
BufferedHttpEntity myBufferedEntity = new BufferedHttpEntity(myNonRepeatableEntity);
2. EntityUtils
通过InputStream HttpEntity#getContent()太过底层,使用麻烦。 HttpCore提供了EntityUtils帮助我们消费HttpEntity。 EntityUtils主要提供3类方法:
consume、consumerQuietly用于关闭HttpEntity的输入流,以便是否资源,在我们不需要HttpEntity的内容的时候使用。toByteArray将HttpEntity内容转换为字节数字,适用于传输非文本内容的场景,比如图片。toString系列,用于将HttpEntity的内容转换为字符串,可以使用HttpEntity字段的编码信息,或者自己指定编码
2.5 HTTP协议处理器
通常复杂而多变的逻辑都会采用责任链模式或者拦截器模式分而治之,HttpCore中的HTTP协议就是通过拦截器链完成的。
HttpCore中将拦截器划分为两类:
HttpRequestInterceptor,请求拦截器HttpResponseInterceptor,响应拦截器
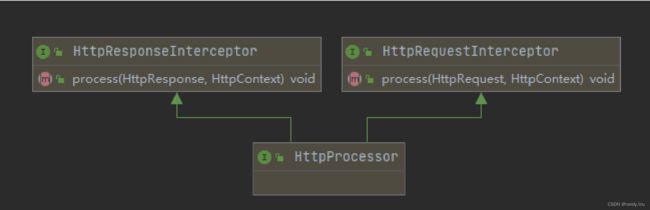
HttpCore定义了大量的拦截器来出来HTTP协议的细节,下面的表格我们列出一些常见的拦截器:
| 拦截器 | 说明 |
|---|---|
| RequestContent | 计算请求体长度,添加Content-Length、Transfer-Content头,添加HTTP版本号 |
| RequestConnControl | 负责在请求中添加Connection头 |
| RequestDate | 负责在请求添加Date头 |
| RequestExpectContinue | 负责添加请求的Expect头 |
| RequestTargetHost | 负责添加请求的Host头 |
| RequestUserAgent | 负责添加请求的User-Agent头 |
| ResponseContent | 计算响应体长度,添加Content-Length、Transfer-Content头,添加HTTP版本号 |
| ResponseConnControl | 负责在响应中添加Connection头 |
| ResponseDate | 负责在响应添加Date头 |
| ResponseServer | 负责添加响应的Server头 |
HTTP拦截器需要配合HttpProcessorBudiler使用,这个Builder会创建一个ImmutableHttpProcessor,ImmutableHttpProcessor会在process方法内循环调用其他HttpProcessor。
HttpProcessor httpproc = HttpProcessorBuilder.create()
.add(new RequestContent())
.add(new RequestTargetHost())
.add(new RequestConnControl())
.add(new RequestUserAgent("MyAgent-HTTP/1.1"))
.add(new RequestExpectContinue(true))
.build();
HttpCoreContext context = HttpCoreContext.create();
context.setTargetHost(HttpHost.create("www.a.com"));
HttpRequest request = new BasicHttpRequest("GET", "/index.html");
request.addHeader("Host","www.a.com");
httpproc.process(request, context);
HeaderIterator it = request.headerIterator();
while (it.hasNext()) {
Header h = it.nextHeader();
System.out.println(h.getName() + ":" + h.getValue());
}
System.out.println(request);
服务端处理逻辑
HttpResponse = <...>
httpproc.process(response, context);
2.6 HttpCoreContext
HTTP请求本身是无状态的,很多场景下我们希望保留状态,比如Java服务端会话需要的JSESSIONID。 HttpCoreContext的目的就是为了解决这个问题。
下面是一个最简单的使用示例:
HttpProcessor httpproc = HttpProcessorBuilder.create()
.add(new HttpRequestInterceptor() {
public void process(
HttpRequest request,
HttpContext context) throws HttpException, IOException {
String id = (String) context.getAttribute("session-id");
if (id != null) {
request.addHeader("Session-ID", id);
}
}
})
.build();
HttpCoreContext context = HttpCoreContext.create();
HttpRequest request = new BasicHttpRequest("GET", "/");
httpproc.process(request, context);
3. 总结

4. 参考资料
- HTTP协议文档 RFC2616 https://tools.ietf.org/html/rfc2616
- HttpComponents文档 https://hc.apache.org/httpcomponents-core-ga/tutorial/html/fundamentals.html