python | 内存管理
目录
python引用机制
Python引用计数
引用计数器原理
获取引用计数: getrefcount()
增加引用计数
减少引用计数
内存泄漏与内存溢出
标记清除 # 主要用于解决循环引用。
引用计数机制的优点:
引用计数机制的缺点
垃圾回收
回收原则
gc机制
效率问题
三种情况触发垃圾回收
分代(generation)回收 --启动垃圾回收的时候确定有哪些对象
Python缓冲池(内存池)
为什么要引入内存池(why)
内存池是如何工作的(how)
整数对象缓冲池
字符串缓存
注意:
字符串的intern机制
python中的内存管理:以引用计数为主,分代回收和标记清除为主的垃圾回收为辅,以及对小整数进行缓存和简单字符串驻留的内存池机制。
python引用机制
Python动态类型
• 对象是储存在内存中的实体。内存中的对象(pycodeobject)包括(引用计数,数据类型,值)
• 我们在程序中写的对象名,只是指向这一对象的引用(reference)
• 引用和对象分离,是动态类型的核心
• 引用可以随时指向一个新的对象(内存地址会不一样
answer = 42
标识符 值
Python引用计数
在Python中,每个对象都有存有指向该对象的引用总数,即引用计数(reference count)。
Python通过引用计数来保存内存中的变量追踪,即记录该对象被其他使用的对象引用的次数。
Python中有个内部跟踪变量叫做引用计数器,每个变量有多少个引用,简称引用计数。当某个对象的引用计数为0时,就列入了垃圾回收队列。
>>> a=[1,2]
>>> import sys
>>> sys.getrefcount(a) ## 获取对象a的引用次数
2
>>> b=a
>>> sys.getrefcount(a)
3
>>> del b ## 删除b的引用
>>> sys.getrefcount(a)
2
>>> c=list()
>>> c.append(a) ## 加入到容器中
>>> sys.getrefcount(a)
3
>>> del c ## 删除容器,引用-1
>>> sys.getrefcount(a)
2
>>> b=a
>>> sys.getrefcount(a)
3
>>> a=[3,4] ## 重新赋值
>>> sys.getrefcount(a)
2
注意:当把a作为参数传递给getrefcount时,会产生一个临时的引用,因此得出来的结果比真实情况+1
引用计数器原理
python中的每个对象维护一个 ob_ref 字段,用来记录该对象当前被引用的次数
每当新的引用指向该对象时,它的引用计数ob_ref加1(引用计数从0开始)
每当该对象的引用失效时计数ob_ref减1, 一旦对象的引用计数为0,该对象可以被回收,对象占用的内存空间将被释放。
获取引用计数: getrefcount()
当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1
>>> from sys import getrefcount 从sys模块导入getrefcount属性,后续可以直接使用getrefcount属性
如果直接导入sys模块,后续使用getrefcount属性需要用sys.getrefcount()
>>> a=[1,2,3]
>>> print(getrefcount(a))
2
>>> b=a
>>> print(getrefcount(b))
3它的缺点是需要额外的空间维护引用计数,这个问题是其次的
最主要的问题是它不能释放对象的“循环引用”的空间
增加引用计数
当一个对象A被另一个对象B引用时,A的引用计数将增加
减少引用计数
del删除或重新引用时,引用计数会变化(del只是删除引用
>>> x=[1]
>>> y=[2]
>>> x.append(y)
>>> y.append(x)
>>> getrefcount(x)
3
>>> getrefcount(y)
3
>>> del x
>>> del y内存泄漏与内存溢出
根据引用计数的规律,出现循环引用的情况,内存是无法通过引用计数来释放
这种情况就会造成内存泄漏
内存泄漏:有一部分内存被占用无法释放,进程又无法访问
内存泄漏会导致内存溢出(oom --out of memory):内存不够,程序需要的内存大于系统空闲内存
标记清除 # 主要用于解决循环引用。
标记-清除机制,顾名思义,首先标记对象(垃圾检测),然后清除垃圾(垃圾回收)。
1. 标记:活动(有被引用), 非活动(可被删除)
2. 清除:清除所有非活动的对
>>> a=[1,2]
>>> b=[3,4]
>>> sys.getrefcount(a)
2
>>> sys.getrefcount(b)
2
>>> a.append(b)
>>> sys.getrefcount(b)
3
>>> b.append(a)
>>> sys.getrefcount(a)
3
>>> del a
>>> del b
a引用b,b引用a,此时两个对象各自被引用了2次(去除getrefcout()的临时引用)

执行del之后,对象a,b的引用次数都-1,此时各自的引用计数器都为1,陷入循环引用

标记:找到其中的一端a,因为它有一个对b的引用,则将b的引用计数-1

标记:再沿着引用到b,b有一个a的引用,将a的引用计数-1,此时对象a和b的引用次数全部为0,被标记为不可达(Unreachable)
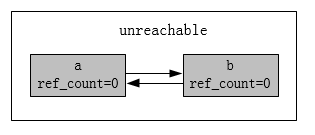
清除: 被标记为不可达的对象就是真正需要被释放的对象
上面描述的垃圾回收的阶段,会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。为了减少应用程序暂停的时间,Python 通过“分代回收”(Generational Collection)以空间换时间的方法提高垃圾回收效率。
引用计数机制的优点:
• 简单
• 实时性
引用计数机制的缺点
• 维护引用计数消耗资源
• 循环引用时,无法回收
垃圾回收
Python的垃圾回收机制采用引用计数机制为主,标记-清除和分代回收机制为辅的策略。其中,标记-清除机制用来解决计数引用带来的循环引用而无法释放内存的问题,分代回收机制是为提升垃圾回收的效率。
回收原则
当Python的某个对象的引用计数降为0时,可以被垃圾回收
gc机制
• GC作为现代编程语言的自动内存管理机制,专注于两件事
• 找到内存中无用的垃圾资源
• 清除这些垃圾并把内存让出来给其他对象使用。
GC彻底把程序员从资源管理的重担中解放出来,让他们有更多的时间放在业务逻辑上。但这并不意味
着码农就可以不去了解GC,毕竟多了解GC知识还是有利于我们写出更健壮的代码
效率问题
垃圾回收时,Python不能进行其它的任务。频繁的垃圾回收将大大降低Python的工作效率。
当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的
次数。当两者的差值高于某个阈值时,垃圾回收才会启动
import gc
print(gc.get_threshold())
(700,10,10) #700即为门阀值,分代回收的间隔都为10次 三种情况触发垃圾回收
• 调用gc.collect()
>>> gc.collect()
2• GC达到阀值时
• 程序退出时
分代(generation)回收 --启动垃圾回收的时候确定有哪些对象
这一策略的基本假设是:存活时间越久的对象,越不可能在后面的程序中变成垃圾。
• Python将所有的对象分为0,1,2三代。
• 所有的新建对象都是0代对象。
• 当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。
• 垃圾回收启动时,一定会扫描所有的0代对象。
• 如果0代经过一定次数垃圾回收,那么就启动对0代和1代的扫描清理。
• 当1代也经历了一定次数的垃圾回收后,那么会启动对0,1,2,即对所有对象进行扫描
Python缓冲池(内存池)
为什么要引入内存池(why)
当创建大量消耗小内存的对象时,频繁调用new/malloc会导致大量的内存碎片,致使效率降低。内存池的作用就是预先在内存中申请一定数量的,大小相等的内存块留作备用,当有新的内存需求时,就先从内存池中分配内存给这个需求,不够之后再申请新的内存。这样做最显著的优势就是能够减少内存碎片,提升效率。
内存池是如何工作的(how)

python的对象管理主要位于Level+1~Level+3层
Level+3层:对于python内置的对象(比如int,dict等)都有独立的私有内存池,对象之间的内存池不共享,即int释放的内存,不会被分配给float使用
Level+2层:当申请的内存大小小于256KB时,内存分配主要由 Python 对象分配器(Python’s object allocator)实施
Level+1层:当申请的内存大小大于256KB时,由Python原生的内存分配器进行分配,本质上是调用C标准库中的malloc/realloc等函数
关于释放内存方面,当一个对象的引用计数变为0时,Python就会调用它的析构函数。调用析构函数并不意味着最终一定会调用free来释放内存空间,如果真是这样的话,那频繁地申请、释放内存空间会使Python的执行效率大打折扣。因此在析构时也采用了内存池机制,从内存池申请到的内存会被归还到内存池中,以避免频繁地申请和释放动作。
整数对象缓冲池
对于[-5,256] 这样的小整数,系统已经初始化好,可以直接拿来用。而对于其他的大整数,系统则提
前申请了一块内存空间,等需要的时候在这上面创建大整数对象。
>>> a=3
>>> print(getrefcount(a))
49
字符串缓存
为了检验两个引用指向同一个对象,我们可以用is关键字。is用于判断两个引用所指的对象是否相同。
当触发缓存机制时,只是创造了新的引用,而不是对象本身。
单个字符,创建之后会存放在字符串驻留区
多个字符,创建之后如果没有特殊字符,就会存放在字符串驻留区
注意:
这对于经常使用的数字和字符串来说也是一种优化的方案
字符串的intern机制
python对于短小的,只含有字母数字的字符串自动触发缓存机制。其他情况不会缓存