一篇搞懂python的内存管理
目录
python的内存管理
一、引用计数
1.1 python是一种动态类型, 所以需要引用计数
1.2 引用计数
1.3 引用计数无法解决 循环引用
二、垃圾回收
2.1 垃圾回收,为了解决引用计数的弊端
2.2 垃圾回收,产生的效率问题
2.3 什么时候垃圾回收
2.4 垃圾回收是怎么回收
2.4.1 怎么找到垃圾 --> 分代回收
2.4.2 怎么清除垃圾 ---> 标记清除, 清除循环引用的垃圾
2.4.3 内存泄露
2.4.4 内存溢出
三、内存池机制
3.1 小整数池 [-5,256]之间
3.2 字符串驻留区(对于多个字符,含有特殊字符,是不放在驻留区的;对于单个字符,都放在驻留区)
python的内存管理
引用计数为主,分代回收和清除标记为辅的垃圾回收方式,进行内存回收管理
还引用了小整型缓冲池以及常用字符串驻留区的方式进行内存分配管理
一、引用计数
1.1 python是一种动态类型, 所以需要引用计数
动态类型: 不使用显示数据类型来声明变量,且确定一个变量的类型 是在第一次给它赋值的时候确认的
1.2 引用计数
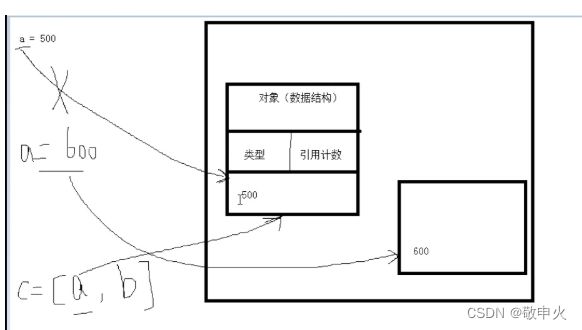
引用计数: 统计了有哪些变量引用 指向了当前对象
当有新的引用指向变量,引用计数+1
当有无效的引用发生的时候,引用计数-1
当对象的引用计数为0的时候,销毁对象1.3 引用计数无法解决 循环引用
引用计数可以解决大部分内存释放的问题,但是无法解决循环引用问题
删除x,y 引用,引用计数都减1, 但是引用计数并没有归0,
在内存中就不能被释放,程序又不能访问这片空间,造成内存泄露。>>> from sys import getrefcount
>>> x = [1, 2]
>>> y = [3, 4]
>>> x.append(y)
>>> x
[1, 2, [3, 4]]
>>> y.append(x)
>>> y
[3, 4, [1, 2, [...]]]
>>> x
[1, 2, [3, 4, [...]]]
>>> del x
>>> del y
>>> x
Traceback (most recent call last):
File "", line 1, in
NameError: name 'x' is not defined
>>> y
二、垃圾回收
2.1 垃圾回收,为了解决引用计数的弊端
垃圾回收的作用(gc机制): garbage collection
1. 找到内存中无用的垃圾资源
2. 清除这些垃圾并把内存让出来给其他对象使用
2.2 垃圾回收,产生的效率问题
效率问题:
垃圾回收,python不能进行其他的任务。频繁的垃圾回收将大大降低python的工作效率。
2.3 什么时候垃圾回收
什么时候垃圾回收:
1. 手动调用gc.collect()
2. GC达到阀值时
python在运行时, 记录其中分配对象和取消分配对象的次数,当两者的差值高于某个阀值时,垃圾回收才会启动
>>> gc.get_threshold() # threshold 门限,阀限
(700, 10, 10) 700这个阀值
3. 程序退出时
>>> import gc
>>> gc.get_threshold() # threshold 门限,阀限
(700, 10, 10)
>>> gc.collect()
57
>>> gc.collect()
0
>>> 2.4 垃圾回收是怎么回收
垃圾回收: 1. 找到垃圾 2. 回收垃圾
2.4.1 怎么找到垃圾 --> 分代回收
每一次只会检查新建对象
新建对象 ---> 0代成员 ---> 每一次垃圾回收的时候,都会被检查
>>> gc.get_threshold() # threshold 门限,阀限
(700, 10, 10)
当0代成员,经历10次垃圾回收,依然存活 -----> 1代成员
1 代成员有什么特权: 0代成员扫描10次,才会扫描一次 1代成员
1代成员扫描10次,依然存活 ----> 2代成员
1代扫描10,才会扫描 2代成员
最多只有 3代(0代,1代,2代)2.4.2 怎么清除垃圾 ---> 标记清除, 清除循环引用的垃圾
采用分代回收,来扫描指定的对象,当检测到时垃圾的时候(标记对象),然后再清除垃圾(垃圾回收)。
主要用于解决循环引用。
1. 标记: 活动(有被引用),非活动(可被删除)
2. 清除: 清除所有非活动的对象2.4.3 内存泄露
什么是内存泄露:(占着茅坑不拉屎) 有一部分内存无法被回收释放,进程又无法访问
2.4.4 内存溢出
内存溢出(out of memory): 内存不够用,程序需要的内存大于系统空间的内存
三、内存池机制
>>> from sys import getrefcount
>>> a = 1
>>> b =2
>>> getrefcount(a)
799
>>> getrefocunt(b)
Traceback (most recent call last):
File "", line 1, in
NameError: name 'getrefocunt' is not defined
>>> getrefcount(b) ----> 这些为什么有这么多的引用呢?
99
>>> c = 200
>>> getrefcount(c)
3
>>> d = 500 ----> python 中分别创建两个500对象
>>> f = 500
>>> getrefcount(d)
2
>>> getrefcount(f)
2
>>>
>>> g = 1
>>> getrefcount(g)
800
>>> h = 1
>>> getrefcount(h)
805
>>> id(g)
140339374065568
>>> id(h)
140339374065568
>>> id(f)
140339374748784
>>> id(d)
140339374748464
>>>
==============
以上情形的出现,因为python有个内存池机制。
小整数池(-5 ~ 256 ),已经全部创建好了 3.1 小整数池 [-5,256]之间
浮点型的没有
>>> a = 1.1
>>> b = 1.1
>>> getrefcount(a)
2
>>> getrefcount(b)
23.2 字符串驻留区(对于多个字符,含有特殊字符,是不放在驻留区的;对于单个字符,都放在驻留区)
当字符串中含有多个字符时,不是有特殊字符。有特殊字符,就不保留在驻留区;无特殊字符,就保留在驻留区 驻留区 相当于 缓存一样,创建一个字符串。先去驻留区查看,是否有一样的,若有一样的,就直接引用。没有一样的,才新建对象
单个字符的案例
==============
>>> str1 = "中"
>>> str2 = "中"
>>> id(str1)
140339374898512
>>> id(str2)
140339374898752
>>>
=========多个字符案例
===============
含有特殊字符 ----> 不放在驻留区
=============
>>> str1 = "abc'"
>>> str2 = "abc'"
>>> id(str1)
140339374939416
>>> id(str2)
140339374939472
==========================不含有特殊字符 ----> 就放在驻留区
=====================
>>> str2 = "abc"
>>> str1 = "abc"
>>> id(str2)
140339375551632
>>> id(str1)
140339375551632
>>> 驻留区有边界
================
>>> str1 = "a" * 20
>>> str2 = "a" * 20
>>> str1 is str2
True
>>> str2 = "a" * 21
>>> str1 = "a" * 21
>>> str1 is str2
False
>>>
========================