Chatglm2-6b-lora&ptuning微调实践2
Chatglm2-6B-lora&ptuning微调实践2
- 1 . 参考教程
- 2. 实践环境
- 3. 微调实战
-
- 3.1 环境安装
- 3.2 单gpu微调
-
- 3.2.1 lora微调
-
- **注意事项**
- 1. lora微调代码
- 2. lora微调代码所在位置
- 3.终端运行展示
- 3.2.2 ptuning 微调
- 指标评估(BLEU分数和汉语ROUGE分数)
- 模型预测
- API 服务
- 命令行测试
- 浏览器测试
- 注意事项
- 导出微调模型
- 注意事项
1 . 参考教程
1.https://github.com/hiyouga/ChatGLM-Efficient-Tuning
2.https://github.com/km1994/LLMsNineStoryDemonTower/blob/main/ChatGLM2-6B/PEFT_finetune.md
2. 实践环境
autodl
小白强力推荐!
3. 微调实战
3.1 环境安装
- github项目代码
conda create -n py310_chat python=3.10
source activate py310_chat
git clone https://github.com/hiyouga/ChatGLM-Efficient-Tuning.git
cd ChatGLM-Efficient-Tuning
pip install -r requirements.txt
- chatglm2-6b权重下载
要使用最新的
git lfs install # 这个不能省略,我就在这里遇到了坑
git clone https://huggingface.co/THUDM/chatglm2-6b
- 数据集介绍
[
{
"instruction": "保持健康的三个提示。",
"input": "",
"output": "以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。"
},
{
"instruction": "三原色是什么?",
"input": "",
"output": "三原色通常指的是红色、绿色和蓝色(RGB)。它们是通过加色混合原理创建色彩的三种基础颜色。在以发光为基础的显示设备中(如电视、计算机显示器、智能手机和平板电脑显示屏), 三原色可混合产生大量色彩。其中红色和绿色可以混合生成黄色,红色和蓝色可以混合生成品红色,蓝色和绿色可以混合生成青色。当红色、绿色和蓝色按相等比例混合时,可以产生白色或灰色。\n\n此外,在印刷和绘画中,三原色指的是以颜料为基础的红、黄和蓝颜色(RYB)。这三种颜色用以通过减色混合原理来创建色彩。不过,三原色的具体定义并不唯一,不同的颜色系统可能会采用不同的三原色。"
},
...
]
3.2 单gpu微调
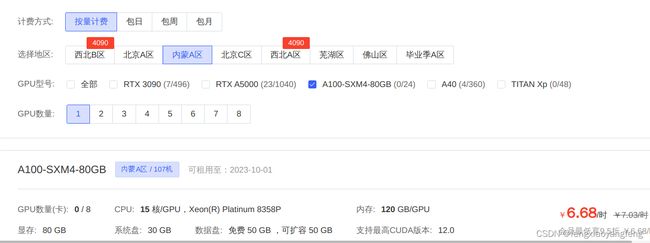
autodl分布式微调,支持NVlink链接的,目前只有带SXM的V100和A100
这个很紧缺,而且贵。没有租到,用的是单卡的。

3.2.1 lora微调
为了方便,直接代码写进sh文件。直接 sh train_sft_6blora.sh 运行, 也方便修改。 在本地pycharm远程连接时,命令行总是报错。还是写进文件方便。
注意事项
- 权重路径
这里注意,指定文件夹时末尾不要加斜杆,举例 /root/autodl-tmp/ChatGLM2-6b/ 这种是错误的,末尾的6b不要在加斜杆“/”
-
绝对路径
如果遇到报错,对应的模型路径用绝对路径 /root/autodl-tmp/ChatGLM2-6b -
权重上传
权重我是通过公网网盘的形式,先上传到百度网盘,然后上传到autodl的autodl-tmp目录下
1. lora微调代码
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python ./src/train_bash.py \
--model_name_or_path /root/autodl-tmp/ChatGLM2-6b \
--stage sft \
--do_train \
--dataset alpaca_gpt4_zh \
--dataset_dir /root/ChatGLM-Efficient-Tuning/data \
--finetuning_type lora \
--output_dir path_to_sft_check_p_tuning \
--overwrite_cache \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--use_v2
per_device_train_batch_size 和 gradient_accumulation_steps可以根据你的gpu大小自由调整,这里我的数据分别是16 和1 是用了7.5h左右跑完
2. lora微调代码所在位置
3.终端运行展示
# autodl 终端运行示例
root@autodl-container-bac311933c-e79d5ee2:~/ChatGLM-Efficient-Tuning# sh train_sft_6b
结果保存在对应的目录:

3.2.2 ptuning 微调
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python ./src/train_bash.py \
--model_name_or_path /root/autodl-tmp/ChatGLM2-6b \
--stage sft \
--do_train \
--dataset alpaca_gpt4_zh \
--dataset_dir /root/ChatGLM-Efficient-Tuning/data \
--finetuning_type p_tuning \
--output_dir path_to_sft_check_p_tuning \
--overwrite_cache \
--per_device_train_batch_size 16 \ # 根据显存大小自由调整
--gradient_accumulation_steps 4 \ # 根据显存大小自由调整
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--use_v2 \
--fp16
指标评估(BLEU分数和汉语ROUGE分数)
checkpoint_dir 路径要写对,相对路径报错,就用绝对路径
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path /root/autodl-tmp/ChatGLM2-6b \
--do_eval \
--dataset alpaca_gpt4_zh \
--checkpoint_dir ./path_to_sft_checkpoint/checkpoint-2000 \
--output_dir path_to_eval_result \
--per_device_eval_batch_size 8 \
--max_samples 50 \
--predict_with_generate \
--use_v2
模型预测
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path /root/autodl-tmp/ChatGLM2-6b \
--do_predict \
--dataset alpaca_gpt4_zh \
--checkpoint_dir ./path_to_sft_checkpoint/checkpoint-1000 \
--output_dir path_to_predict_result \
--per_device_eval_batch_size 8 \
--max_samples 50 \
--predict_with_generate \
--use_v2
API 服务
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python src/api_demo.py \
--model_name_or_path /root/autodl-tmp/ChatGLM2-6b \
--checkpoint_dir ./path_to_sft_checkpoint/checkpoint-2000 \
--use_v2
命令行测试
#!/bin/bash
CUDA_VISIBLE_DEVICES=0 python src/cli_demo.py \
--model_name_or_path /root/autodl-tmp/ChatGLM2-6b \
--checkpoint_dir ./path_to_sft_checkpoint/checkpoint-2000 \
--use_v2
浏览器测试
python src/web_demo.py \
--model_name_or_path path_to_your_chatglm_model \
--finetuning_type lora \
--checkpoint_dir path_to_checkpoint
注意事项
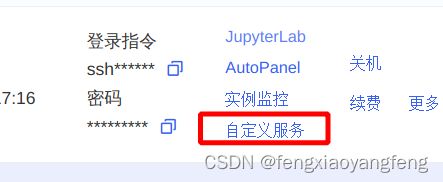
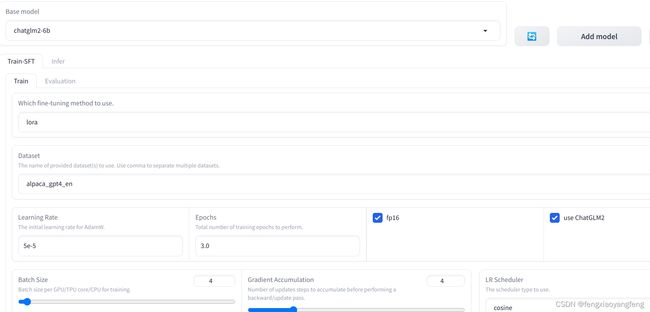
这里autodl要求指定端口6006,位置在 控制台→自定义服务 ,点击就能打开。
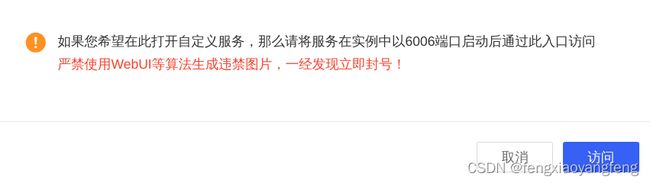
点击访问,出现如下界面,在base model里填写模型绝对路径:

导出微调模型
#!/bin/bash
python src/export_model.py \
--model_name_or_path /root/autodl-tmp/ChatGLM2-6b \
--checkpoint_dir ./path_to_sft_checkpoint/checkpoint-2000 \
--output_dir /root/autodl-tmp/path_to_export \
--use_v2
注意事项
上面导出模型时,如果用–output_dir ./path_to_export 可能会报错,因为这样是导出到系统盘,系统盘autodl默认是25G大小。 /root/autodl-tmp/path_to_export是导出到数据盘,默认是50G大小
这里查看说明autodl各个盘的说明 https://www.autodl.com/docs/env/