SpringCloudStream实战拆解以及3.1后新版本特性分析
文章目录
- 一、MQ的水有多深
- 二、一套框架,盲拆所有MQ产品
-
- 2.1:一分钟快速搭建SCS连接RabbitMQ环境。
- 2.2: 一秒切换对接kafka
- 2.3:一秒切换对接RocketMQ
- 三、详解SCS三神器
-
- 3.1 Binder
- 3.2 Binding
- 3.3 Message
- 四、SCS提供的高级功能
-
- 4.1 消息分组消费机制
- 4.2 个性化使用
- 五、SCS框架3.1.x版本之后声明Binding的方式
-
- 5.1 函数式声明Binding
- 5.2 手动发送消息
- 5.3 Binding的多端合流
一体化MQ解决方案-SpringCloudStream 深度解析
楼兰:你的神秘java宝藏
老友聊IT,老王多指教
一、MQ的水有多深
MQ:也就是MessageQueue,消息对列。对列,是一种具有FIFO先进先出特性的数据结构。在互联网中,基于MQ的数据结构,人们封装出了非常多各具特色的分布式消息中间件产品,由此构建出了非常多很有特色的应用场景。例如像我们经常用的QQ和微信,就是很典型的消息中间件。消息可以由生产者发送到MQ中进行排队,然后消息的消费者可以对消息按照顺序进行处理。而在网络应用层面,消息中间件更是实现分布式消息驱动场景的利器。
在当今互联网中,MQ已经不是一个神秘的东西了,关于MQ的作用主要有三个:
-
异步
例子:快递员送快递,早期直接送到客户家签收,这样效率会很低。引入菜鸟驿站后,快递员只需要将快递放到菜鸟驿站,就可以继续派送其他快递去了。客户可以按照自己的时间安排去菜鸟驿站取快递。
作用:异步能提高系统的响应速度、吞吐量。
-
解耦
例子:《Thinking in JAVA》很经典,但是都是英文,我们看不懂。这时引入编辑社,可以将文章翻译成其他语言,这样就可以完成英语与其他语言的交流。
作用:1、服务之间接口,可以减少服务之间的影响,提升应用的稳定性以及可扩展性。
2、接口后可以实现数据分发。生产者发送一个消息后,可以由一个或者多个消费者进行消费,并且消费者的增加或者减少对生产者没有影响。
-
削峰
例子:长江每年都会涨水,但是下游出水口的速度是基本稳定的,所以经常会出现水灾。引入三峡大坝后,可以把高峰期的水储存起来,下游慢慢排水。
所用:让应用可以以稳定的系统资源应对突然的流量冲击。
目前主流的MQ产品有Kafka、RabbitMQ、RocketMQ三个。我们对三个产品做下简单的比较,重点要理解他们的适用场景。

这三种主流产品都非常成熟,也都有各自不同的一些特性功能,适用于不同的业务场景。但是,这会不会给你带来困惑?同样都是MQ,不同场景下要使用不同的产品,而每个产品都有自己的客户端。那岂不是在细分场景下要用好MQ,就需要一套庞大的技术体系?
有没有一套框架可以像用JDBC去连接各种数据库一样,用一套快速简单的标准对接各种各样的MQ产品呢?这就是我们这次要聊到的SpringCloudStream框架(后续简称SCS)。
二、一套框架,盲拆所有MQ产品
SpringCloudStream是SpringCloud家族的一个重要组件。官网地址: https://spring.io/projects/spring-cloud-stream 他是一个基于共享MQ系统,用于构建高度可伸缩的,事件驱动的问服务应用的框架。简单粗暴的理解就是,一个统一的框架标准连接所有的MQ产品。在官网可以看到SCS已经集成了非常多的MQ产品。

我估计你跟我一样,这么多MQ产品,有些连听都没听说过,更别说在系统中用上了。但是有了SCS后,这些就都不用担心了。SCS是如何帮我们连接所有MQ产品的呢?接下来我们就用常见的Kafka,RabbitMQ和RocketMQ为例,开始一段舒心的SCS之旅。
注:以下部分,假定你对于Kafka、RabbitMQ和RocketMQ已经有了初步了解,并且搭建有本地服务。
各组件的版本如下:RabbitMQ版本:3.9.5, RocketMQ版本:4.9.1, Kafka版本:3.0.1。
2.1:一分钟快速搭建SCS连接RabbitMQ环境。
SCS是基于SpringBoot构建的,首先我们创建一个基于Maven的SpringBoot项目。按照Maven应用三板斧,快速搭建基础环境。
注:这里先快速把开发环境构建起来,不用理解每一步的具体含义。后面会做深入分析
1、pom.xml 依赖配置
按照最常用的开发方式引入SpringBoot以及SpringCloud的集成版本控制,并且引入RabbitMQ的SCS集成依赖包。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-dependenciesartifactId>
<version>2.3.4.RELEASEversion>
<type>pomtype>
<scope>importscope>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-dependenciesartifactId>
<version>Hoxton.SR6version>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-stream-binder-rabbitartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
dependencies>
2、启动类 引入核心注解
注意在启动类中引入@EnableBinding注解。
@SpringBootApplication
@EnableBinding({Source.class, Sink.class})
public class SCSApplication {
public static void main(String[] args) {
SpringApplication.run(SCSApplication.class);
}
}
3、application.properties 配置文件
在配置文件中,只需要简单的目标配置,甚至都不需要指定MQ的服务地址。
spring.cloud.stream.bindings.output.destination=scstreamExchange
spring.cloud.stream.bindings.input.destination=scstreamExchange
spring.cloud.stream.bindings.input.group=stream
spring.cloud.stream.bindings.input.content-type=text/plain
这样,基础的开发框架就搭建成功了。接下来搭建消息发送者和消息生产者。
4、创建一个发送消息的Controller
@RestController
public class SendMessageController {
@Autowired
private Source source;
@GetMapping("/send")
public Object send(String message) {
MessageBuilder<String> messageBuilder = MessageBuilder.withPayload(message);
source.output().send(messageBuilder.build());
return "message sended : "+message;
}
}
5、声明一个消息消费者
@Component
public class MessageReceiver {
@StreamListener(Sink.INPUT)
public void process(Object message) {
System.out.println("received message : " + message);
}
}
到这里,整个MQ应用环境就搭建完成了。接下来可以启动应用,然后访问测试接口发送消息。http://localhost:8080/send?message=123 。
当然,要保证本地的RabbitMQ服务正常启动了。
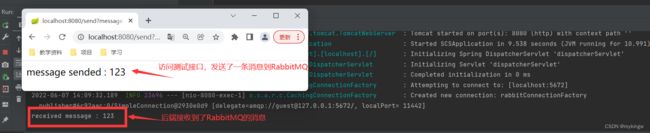
如果你对RabbitMQ有点基础的了解,也可以去RabbitMQ的管理控制台确认一下,这个简单的应用程序是如何实现RabbitMQ的消息收发的。

实际上他的实现过程就是在本地的RabbitMQ中创建了一个scstreamExchange的交换机。应用中的Source组件就是往这个交换机中发送消息。然后,在scstreamExchange这个交换机上,也声明并绑定了一个队列,scstreamExchange.stream队列。应用中的消息监听器Sink组件,就是消费这个队列上的消息。
当然,如果你对RabbitMQ一点也不了解,那也没关系,至少通过这个不超过十行代码的应用,就可以完成与RabbitMQ的消息交互。你只需要知道,这个应用当中的Source消息生产者和Sink消息消费者,是解耦的。在实际应用中,可以将他们拆分到不同的应用当中,实现消息的异步消费。这就够了。
你不需要理解与RabbitMQ交互的细节,甚至连RabbitMQ服务地址,SCS中都提供了默认的配置。你所要关注的,只有业务。
2.2: 一秒切换对接kafka
如果只是简化与RabbitMQ的交互过程,那么还体现不出SCS的强大。如果需要将上面的简单应用改为对接Kafka,那么整个业务代码不需要做任何改动,只需要修改pom.xml中的maven依赖,将RabbitMQ的SCS依赖替换成Kafka的SCS依赖即可。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-stream-binder-kafkaartifactId>
dependency>
接下来,重新启动示例应用,再次访问发送消息接口。消息就会改由Kafka来转发。

同样,如果你熟悉Kafka产品,也能看到实际上SCS框架在Kafka上申请了一个scstreamExchange的Topic,并对这个Topic声明了一个消费者。

2.3:一秒切换对接RocketMQ
接下来对接RocketMQ就简单了,同样是修改pom.xml中的maven依赖,代码不需要做任何改动。
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-stream-rocketmqartifactId>
<version>2021.1version>
<exclusions>
<exclusion>
<groupId>org.apache.rocketmqgroupId>
<artifactId>rocketmq-aclartifactId>
exclusion>
<exclusion>
<groupId>org.apache.rocketmqgroupId>
<artifactId>rocketmq-clientartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.rocketmqgroupId>
<artifactId>rocketmq-clientartifactId>
<version>4.9.1version>
dependency>
<dependency>
<groupId>org.apache.rocketmqgroupId>
<artifactId>rocketmq-aclartifactId>
<version>4.9.1version>
dependency>
从这个maven依赖中就能看出, kafka和RabbitMQ是亲儿子,RocketMQ是厂商自己拉扯大的。所以客户端版本匹配需要注意下。
使用Maven重新编译后,就可以重新访问发送消息的接口。这次消息就会通过RocketMQ发送给后端。

同样如果你了解RocketMQ产品,那么可以去RocketMQ的Console控制台上查看他的实现机制。自动创建了一个scstreamExchange的Topic,并声明了一个stream消费者组。
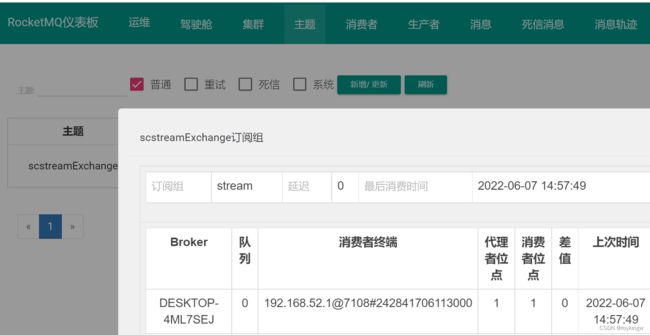
在这个简单的实验过程中可以看到,SCS框架以一种标准化的方式提供了与MQ对接的功能,而与具体的MQ产品交互的细节,都被隐藏在框架之中。在这个过程中,如果你对相关MQ产品比较熟悉,那么可以大致揣测出他的实现方式。但是,就算你对这些MQ产品一无所知,通过SCS框架,也完全不影响基础的编程开发。这正是SCS框架的强大之处。
三、详解SCS三神器
SCS框架抽象出了一个非常简洁的MQ模型,来对接各种MQ产品。这个模型其实非常简单,只包含以下三个组件:
- Destination Binder: 负责集成外部消息系统的组件。
- Destination Binding: 由Binder创建,负责沟通外部消息系统、消息发送者和消息消费者的桥梁。
- Message:消息发送者与消息消费者沟通的简单数据结构。
可以看到,这个模型非常简单,使用时也非常方便。但是简单,也意味着SCS中的这些概念模型,与实际MQ产品中的概念是有比较大的区别的。例如,在RabbitMQ中有Exchange交换机、Queue队列等这些概念,但是在SCS中并没有对应的概念。在使用具体产品时,需要非常注意这些模型之间的对应关系。
接下来会以RabbitMQ作为示例,分别了解这些核心概念。
3.1 Binder
SCS通过Binder定义一个外部消息服务器。默认情况下,SCS会使用对应的SpringBoot插件来构建Binder。所以,对于RabbitMQ来说,SCS默认就支持spring-boot-starter-amqp组件中提供的RabbitMQ的服务配置信息。这些配置信息,在application.properties配置文件中,都以spring.rabbitmq开头。而这一组配置,都是有默认值的。
spring.rabbitmq.host=local
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.virtual-host=/
如果你熟悉RabbitMQ就会知道,这其实就是一组默认的RabbitMQ服务。这也就是为什么在之前的示例中,都没有指定服务器地址,但是SCS也能正常工作的原因。
对于Kafka和RocketMQ,也同样会使用默认的服务。
另外,在SCS中,也可以支持按照自己的方式配置多个Binder访问不同的外部消息服务器。这些配置的方式都是通过spring.cloud.stream.binders.[bindername].environment.[props]=[value]的方式进行配置。另外,如果配置了多个Binder,也可以通过spring.cloud.stream.default-binder属性指定默认的Binder。例如:
spring.cloud.stream.binders.testbinder.environment.spring.rabbitmq.host=localhost
spring.cloud.stream.binders.testbinder.environment.spring.rabbitmq.port=5672
spring.cloud.stream.binders.testbinder.environment.spring.rabbitmq.username=guest
spring.cloud.stream.binders.testbinder.environment.spring.rabbitmq.password=guest
spring.cloud.stream.binders.testbinder.environment.spring.rabbitmq.virtual-host=/
spring.cloud.stream.default-binder=testbinder
通过这个方式,就配置了一个名为testbinder的Binder,并且将他指定成了默认的Binder。environment后面的这些props就是跟具体MQ产品相关的属性了。
3.2 Binding
Binding是SCS中实际进行消息交互的桥梁。在SCS中,就是通过Binding和Binder建立绑定关系,然后客户端就只需要通过Binding进行实现的消息收发了。
在SCS框架中,配置Binding需要首先对他进行声明。当前版本的SCS框架中,声明Binding的方式是在应用中引入@EnableBinding注解。引入这个注解后,应用会向Spring容器中注入一个Binding接口的实例对象。在SCS中,默认提供了Source、Sink、Process三个接口对象,分别代表消息的生产者、消费者和中间处理者。这三个对象都是简单的接口,可以直接拿来使用。
//消息生产者
public interface Source {
String OUTPUT = "output";//Binding对象名
@Output(Source.OUTPUT)
MessageChannel output(); //发送消息工具
}
//消息消费者
public interface Sink {
String INPUT = "input"; //Binding对象名
@Input(Sink.INPUT)
SubscribableChannel input();//消息接收工具
}
//即是发送者,又是接收者。代表一个中间处理步骤
public interface Processor extends Source, Sink {
}
当然,如果这些默认的接口不够用,你也可以照样声明自己的接口,通过自己的接口声明新的Binding对象。
接下来,就需要在Spring应用的某一个合适的位置通过@EnableBinding注解声明这个Binding对象。例如最为常见的是放到启动类上声明。
@SpringBootApplication
@EnableBinding({Source.class, Sink.class})//声明Binding
public class SCSApplication {
public static void main(String[] args) {
SpringApplication.run(SCSApplication.class);
}
}
在示例中,通过Source和Sink接口,就声明出了两个Binding,对象名分别是output和input。
完成声明后的Binding对象,就可以直接来用了。比如通过source.output()方法获取MessageChannel对象,进而发送消息。然后通过@StreamListener(Sink.INPUT)注解声明消息消费者。使用方式在示例中有,就不再过多赘述。
但是,默认的Binding对象由于缺少很多关键的属性配置,在某些环境下会出现很多问题。比如,在RabbitMQ中,如果不经任何配置,就会声明出一个默认的Exchange和Queue。但是默认的名字会非常奇怪,而且很多细节功能都不好用。所以,通常都要对这个Binding进行配置。配置的方式都是在application.properties中配置。这些配置都是按照spring.cloud.stream.bindings.[bindingname].[props]=[value]这样的格式指定的。例如:
spring.cloud.stream.bindings.output.destination=scstreamExchange
#指定binder。
spring.cloud.stream.bindings.output.binder=testbinder
spring.cloud.stream.bindings.input.destination=scstreamExchange
spring.cloud.stream.bindings.input.group=stream
spring.cloud.stream.bindings.input.content-type=text/plain
#指定binder。
spring.cloud.stream.bindings.input.binder=testbinder
其中,通过binder属性可以指定对应的Binder。如果不指定的话,就会使用默认的Binder。通过这样的简单配置,就指定了output这个Binding对应的Exchange交换机是scstreamExchange,input也对应这同一个交换机,所属的消费者组是stream。
关于消费者组,如果你熟悉Kafka或者RocketMQ,相信你就不会陌生。同属一个组的多个消费者实例,会共同消费同一份消息副本。但是在RabbitMQ中,却是没有消费者组这个概念的。接下来,应用启动后,在RabbitMQ中,就会声明一个scstreamExchange,并且在这个交换机上绑定一个scstreamExchange.stream的队列。这样,当有多个消费者实例启动时,这些消费者实例都会一起绑定在这个队列上,这样同一个消费者组的多个示例,还是会共同消费这一个队列上的同一个消息副本,从而变相的实现了分组消费机制。
这里的这些属性是SCS中通用的配置属性,对所有支持的MQ产品都会生效。例如:
spring.cloud.stream.bindings.input.consumer.max-attempts=3
这个配置属性就可以指定input这个消费者的消息最大重试次数。默认值是3。通过SCS框架,就以一种统一的方式定义了所有支持的MQ产品中的消息重试次数,尽管在不同的MQ产品中实现消息重试的配置方式是不一样的。
3.3 Message
SCS中,有了Binder和Binding之后,就相当于有了完整的消息传输通道了。接下来就可以传递消息了。但是不同的MQ产品中对于消息的定义其实也是不相同的,例如RocketMQ中的消息有tag,key,自定义属性等。而在RabbitMQ的消息中也有messageId,headers头信息等。SCS框架就需要对这些消息类型进行统一。统一后的消息类型是这样的:
public interface Message<T> {
T getPayload();
MessageHeaders getHeaders();
}
其中Payload就是消息实体,在SCS中定义成了一个泛型,也就是说可以直接传递对象。MessageHeaders就是消息的头部属性,可以认为是消息的补充属性。这样,不同的MQ产品下,就可以通过不同的MessageHeaders属性来代表各自的消息差异,而消息内容就可以通过Payload统一。例如如果你熟悉RabbitMQ产品的话,就知道,RabbitMQ中有一个非常重要的概念routingKey。通过routingKey可以定制Exchange与Queue之间的路由关系。这个routingKey在RabbitMQ的实现包中就可以通过在Headers当中指定一个routingkey属性来实现。
MessageBuilder<String> messageBuilder = MessageBuilder.withPayload(message).setHeader("routingkey","info");
Message接口下,实际上也是有很多实现类的,简单看一下MessageBuilder的build方法,就能看到,这种方式是可以构建ErrorMessage和GenericMessage两种不同的消息的。
public Message<T> build() {
if (!this.modified && !this.headerAccessor.isModified() && this.originalMessage != null && !this.containsReadOnly(this.originalMessage.getHeaders())) {
return this.originalMessage;
} else {
return (Message)(this.payload instanceof Throwable ? new ErrorMessage((Throwable)this.payload, this.headerAccessor.toMap()) : new GenericMessage(this.payload, this.headerAccessor.toMap()));
}
}
有了Binder,Binding和Message这三个工具后,你就可以直接用SCS框架去对接所有支持的MQ产品了。
四、SCS提供的高级功能
4.1 消息分组消费机制
SCS框架不光是统一与各个MQ产品之间的交互方式,还给各个MQ之间设计了一套统一的消费机制,就是分组消费机制。他的基础思想是在生产者实例和消费者实例之间建立一种对应关系,生产者实例发出的消息只会被对应的消费者消费,这样,当应用中有多个生产者实例和多个消费者实例时,就可以建立一种类似于Kafka和RocketMQ的分组消费的机制。
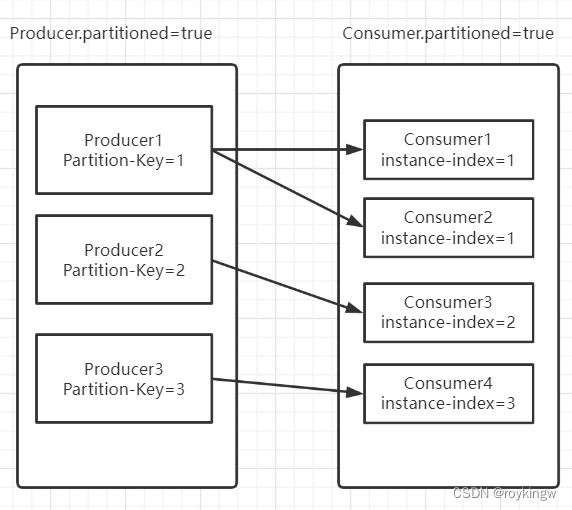
例如,在RabbitMQ的示例应用中,对于生产者output,可以增加如下分区配置:
spring.cloud.stream.bindings.output.destination=scstreamExchange
#指定参与消息分区的消费端节点数量
spring.cloud.stream.bindings.output.producer.partition-count=2
#只有消费端分区ID为1的消费端能接收到消息
spring.cloud.stream.bindings.output.producer.partition-key-expression=1
这就表示当前生产者会有两个分区实例,当前分区实例的分区键是1。
然后,对于消费者input,如果增加以下分区属性:
spring.cloud.stream.bindings.input.destination=scstreamExchange
spring.cloud.stream.bindings.input.group=myinput
#启动消费分区 新版本这个属性已经取消,改为由分区表达式自动判断
spring.cloud.stream.bindings.input.consumer.partitioned=true
#参与分区的消费端节点个数
spring.cloud.stream.bindings.input.consumer.instance-count=2
#设置该实例的消费端分区ID
spring.cloud.stream.bindings.input.consumer.instance-index=1
这也表示当前消费者组会有两个分区实例,当前分区实例的分区键是1。
这时,把应用启动起来,消费者发送的消息,依然能够正常被消费者消费到。但是,如果将消费者的instance-index属性改成0,或者是2,那重启应用后,就无法消费到生产者发出的消息了。也就是说,只有与生产者的分区键匹配的消费者,才能接收到生产者发送过来的消息。如果分区键不匹配,那就接收不到。这里要注意,这并不是表示消息丢失了,而是当前的消费者实例和生产者实例没有对应上,就无法消费对应的消息了。
我们这个示例还太过简单,生产者和消费者的分区键都是直接指定的,不具备实际使用的价值。但是,SCS有更灵活的机制,让生产者可以根据消息本体来产生生产者的分区键,这样,就可以具备真正的分区消费功能了。
这主要涉及到SCS中的producer后的两个关键的配置属性:partition-key-extractor-name和partition-selector-name。
其中,partition-key-extractor-name属性需要指向一个实现了PartitionKeyExtractorStrategy接口的实现类,用来计算从Message中如何产生一个动态的分区Key。这个机制与partition-key-expression配置是互斥的。而partition-selector-name属性需要指向一个实现了PartitionSelectorStrategy接口的实现类,用来计算如何从分区Key中获取一个动态的分区键。
例如,按照以下配置,就可以实现按照消息的轮询接收。即生产者发送消息的分区键会奇数偶数循环,而消费者只接收分区键为奇数的消息。
//step1、增加分区提取器
public class MyPartitionKeyExtractor implements PartitionKeyExtractorStrategy {
public static final String PARTITION_PROP="partition";
@Override
public Object extractKey(Message<?> message) {
return message.getHeaders().get(MyPartitionKeyExtractor.PARTITION_PROP);
}
}
//step2、增加分区键计算器
public class MyPartitionSelectorStrategy implements PartitionSelectorStrategy {
@Override
public int selectPartition(Object key, int partitionCount) {
return Integer.parseInt(key.toString()) % partitionCount;
}
}
//step3、在application.properties中添加生产者的分区配置
spring.cloud.stream.bindings.output.destination=scstreamExchange
spring.cloud.stream.bindings.output.binder=testbinder
#指定参与消息分区的消费端节点数量
spring.cloud.stream.bindings.output.producer.partition-count=2
#只有消费端分区ID为1的消费端能接收到消息
#spring.cloud.stream.bindings.output.producer.partition-key-expression=1
#动态生成分区键
spring.cloud.stream.bindings.output.producer.partition-key-extractor-name=com.roy.partition.MyPartitionKeyExtractor
spring.cloud.stream.bindings.output.producer.partition-selector-name=com.roy.partition.MyPartitionSelector
//step4、发送消息时,给消息添加个动态增长的index属性。
//index生成工具
@Bean
public AtomicInteger index(){
return new AtomicInteger(0);
}
//step5、在发送消息时,连续发送四条消息。
@RestController
public class SendMessageController {
@Autowired
private Source source;
@Autowired
private AtomicInteger index;
@GetMapping("/sendPartitionBatch")
public Object sendPartitionBatch(String message) {
for (int i = 0; i < 4; i++) {
MessageBuilder<String> messageBuilder = MessageBuilder.withPayload(message).setHeader(MyPartitionKeyExtractor.PARTITION_PROP,index.incrementAndGet());
source.output().send(messageBuilder.build());
}
return "message sended : "+message;
}
}
这样,在发送消息时,会发送四条消息,而消费者只会收到两条partition属性为奇数的消息。而如果有另外一个消费者的应用实例,指定的instance-index为偶数,则会收到另外的两条消息。
这种分组消费的机制,是可以在所有已对接的MQ产品上实现的,但是,其实现方式肯定是不同的。例如在RabbitMQ中,本来是不存在这样的分组消费机制的,而他的实现方式,是在scstreamExchange交换机上,给每个partition创建一个队列,而消费者就是通过绑定不同的队列来实现这种分组消费的机制。
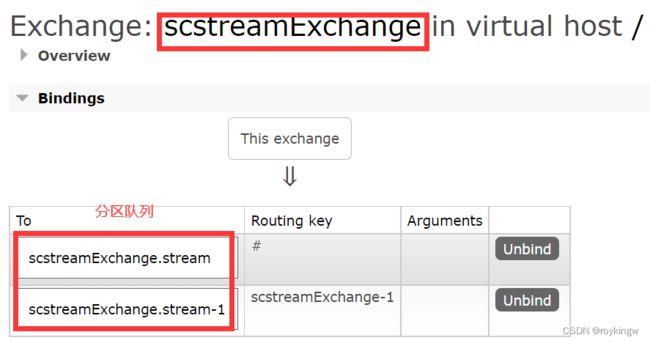
关于其他MQ产品比如Kafka,RocketMQ产品,如何实现这种分组消费的机制,感兴趣的同学可以自行尝试去摸索一下。也是一个很重要的MQ产品使用经验。
4.2 个性化使用
SCStream其实自身实现了一套事件驱动的流程。这种流程,对于各种不同的MQ产品都是一样的。但是,毕竟每个MQ产品的实现机制和功能特性是不一样的,所以,SCStream还是提供了一套针对各个MQ产品的兼容机制。例如在 在RabbitMQ的实现中,所有个性化的属性配置实现都是以spring.cloud.stream.rabbit开头,支持对binder、producer、consumer进行单独配置。
#绑定exchange
spring.cloud.stream.binding..destination=fanoutExchange
#绑定queue
spring.cloud.stream.binding..group=myQueue
#不自动创建queue
spring.cloud.stream.rabbit.bindings..consumer.bindQueue=false
#不自动声明exchange(自动声明的exchange都是topic)
spring.cloud.stream.rabbit.bindings.
.consumer.declareExchange=false
#队列名只声明组名(前面不带destination前缀)
spring.cloud.stream.rabbit.bindings.
.consumer.queueNameGroupOnly=true
#绑定rouytingKey
spring.cloud.stream.rabbit.bindings.
.consumer.bindingRoutingKey=myRoutingKey
#绑定exchange类型
spring.cloud.stream.rabbit.bindings..consumer.exchangeType=
#绑定routingKey
spring.cloud.stream.rabbit.bindings.
.producer.routingKeyExpression='myRoutingKey'
具体的属性配置可以参看官方的github仓库。仓库地址:https://github.com/spring-cloud/spring-cloud-stream-binder-rabbit
五、SCS框架3.1.x版本之后声明Binding的方式
之前的示例中,我们是使用的SpringCloud的统一版本,这其中SCS框架的版本是3.0.6.RELEASE。但是,其实SCS框架在3.1.x往后的新版本中,提供了很多更灵活的功能机制。下面简单分享一下。
依然以RabbitMQ产品为例,首先我们需要更新pom.xml中的SCS框架版本。
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-stream-binder-rabbitartifactId>
<version>3.2.2version>
dependency>
然后我们分享一下下面两个重要的优化机制。
5.1 函数式声明Binding
在3.1.x往后的新版本中,@EnableBinding注解已经被声明为过期了,也就意味着不推荐使用老的方式来声明Binding。其实Binding的概念依然是存在,使用方式也基本一样,只不过Binding的声明方式改变了,改成了一种函数式的声明方式。
在之前的版本中,我们是通过Source、Sink这样的接口来声明Binding,而在新版本中,就不再使用这些自定义的接口,而是改用了jdk中提供的函数式接口来声明Binding。其中,使用 java.util.function.Supplier声明一个不断产生消息的消息源,使用java.util.function.Consumer声明一个接收消息的消费者,然后还可以使用java.util.function.Function声明一个消费完消息后又会发送消息的中间处理者。例如可以按照下面的方式声明一组Binding。
@Configuration
public class PubSubDemo2 {
//Supplier声明一个消息生产者,source就对应source-out-0的生产者binding
@Bean
public Supplier<String> source(){
return ()->{
String message = "FromSource1";
System.out.println("******************");
System.out.println("From Source1");
System.out.println("******************");
System.out.println("Sending value: " + message);
return message;
};
}
//Function方式声明binding,相当于同时声明了一个Producer的Bindng和一个Consumer的Binding。transfer-in-0 表示消费者 transfer-out-0 表示生产者
//其作用就在于,echo-in-0收到的消息,立即就会通过echo-out-0发送出去。
@Bean
public Function<String,String> transfer(){
return message -> {
System.out.println("transfer: "+message);
return "transfer:"+message;
};
}
//Consumer声明一个消息消费者,sink1就对应sink-in-0
@Bean
public Consumer<String> sink() {
return message -> {
System.out.println("******************");
System.out.println("At Sink1");
System.out.println("******************");
System.out.println("Received message " + message);
};
}
}
只需要往Spring容器当中注入几个函数接口实现类,当然,现在还只是声明,还没有被引入。接下来,需要在application.properties文件中引入这几个实现类才行。
spring.cloud.stream.function.definition=source;transfer;sink
这样,就相当于是老版本中使用@EnableBinding注解引入了几个Binidng。只不过,与老版本不同的是,Binding的名字并不是Bean的名字,对于Binding的名字,新版本的SCS框架定制了一套默认的规则。对于消息生产者,需要定义为[函数对象名]-out-0。 其中out就是表示这是一个会不断往外生产消息的消息源。而对于消息消费者,则需要定义为[函数对象名]-in-0。其中in表示这是一个不断接收消息的消费者。而Binding的其他属性,则基本跟老版本差不多。比如
spring.cloud.stream.function.definition=source;transfer;sink
spring.cloud.stream.bindings.source-out-0.destination=test1
spring.cloud.stream.bindings.transfer-in-0.destination=test1
spring.cloud.stream.bindings.transfer-out-0.destination=test2
spring.cloud.stream.bindings.sink-in-0.destination=test2
这样启动完成后,就会不断的从source中产生消息,发送到test1交换机。然后transfer消费到test1上的消息后,转换成transfer:message的格式,继续发送到test2上。最后sink函数收到了test2的消息,打印后,完成消息的处理链路。日志像这样:
******************
From Source1
******************
Sending value: FromSource1
transfer: FromSource1
******************
At Sink1
******************
Received message transfer:FromSource1
5.2 手动发送消息
通过source函数产生的消息是源源不断的,这种使用场景很有限。通常还是会要手动发送消息才行。
在SCS中,可以直接使用Spring容器中的StreamBridge组件往Binding中发送消息。SCS框架会在启动过程中注入这个实例。例如接下来,我们可以尝试把之前的source替换成通过一个Controller发送消息。
step1、去掉关于source的声明以及配置。
step2、在配置文件中声明一个名为output的Topic。
spring.cloud.stream.bindings.output.destination=test1
这就相当于直接引入了一个Binding,不需要声明。注意:不经过函数声明的Binding,就没有-out 或者 -in的规则。
step3、配置一个Controller,测试往output上发消息。
@RestController
public class PubController {
@Resource
private StreamBridge streamBridge;
//直接发消息到output 这个binding
@RequestMapping("send")
public Object send(String message){
streamBridge.send("output",message);
return "Message sended :"+message;
}
}
这样启动应用后,访问这个Controller发送消息,就可以通过output这个Binding将消息发送到test1上,后续依然由transfer、sink完成后续的消息路由。
5.3 Binding的多端合流
关于SCS新版本中这个莫名其妙的Binding规则。前面的两个部分还比较好理解,最后的一个数字是什么意思呢?他代表的是一个数据的传输通道。这个数据通道代表的是一组数据来源,在RabbitMQ中可以理解为队列。以RabbitMQ的消费者举例,通常一个消费者实例都只处理一个队列的消息,这就是一个数据通道,这个数据通道的索引就可以用0表示。
那有0就意味着可以有1或者更多。如果一个消费者要同时处理多个队列的消息,那就需要设置多个通道。这是一种什么场景?例如下面的示例就通过一个Function,统一处理多个数据通道的消息。
step1、声明Binding函数。
@Configuration
public class GatherConsumer {
//例如这样的Function,就需要声明gather-in-0和gather-in-1。
//如果输出的是个Tuple,那就同样需要声明gather-out-0和gather-out-1
@Bean
public Function<Tuple2<Flux<String>,Flux<String>>, Flux<String>> gather(){
return tuple -> {
Flux<String> t1 = tuple.getT1();
Flux<String> t2 = tuple.getT2().map(str-> "gather2:"+str);
// return Flux.merge(t1,t2);
return Flux.combineLatest(t1,t2,(str1,str2) -> "gather1:"+str1+";"+str2);
};
}
@Bean
public Consumer<String> gatherEcho(){
return message -> {
System.out.println("received message from gatherCosuer : "+message);
};
}
}
这个gather函数就通过一个Tuple2函数,接收了两个通道的消息,通道都是以Flux组成。关于Flux是一种响应式编程的实现方式,后面会单独说明。 然后,这个gather函数,实际上就相当于声明出了两个输入通道,分别对应gather-in-0和gather-in-1两个Binding。同时,他的返回泛型只有一个通道,相当于声明了一个gather-out-0的Binding。
后面的gatherEcho就是设计用来接收gather-out-0输出的消息。
step2、配置Binding的Destination
在application.properties里配置这些Binding的目标。
#声明两个普通Binding,用来往gather的两个输入通道里发消息
spring.cloud.stream.bindings.gather1.destination=gatherExchange1
spring.cloud.stream.bindings.gather2.destination=gatherExchange2
#声明Binding函数
spring.cloud.stream.function.definition = gather;gatherEcho
#声明gather的第一个接收数据通道
spring.cloud.stream.bindings.gather-in-0.destination=gatherExchange1
spring.cloud.stream.bindings.gather-in-0.group=gather1
#声明gather的第二个接收数据通道
spring.cloud.stream.bindings.gather-in-1.destination=gatherExchange2
spring.cloud.stream.bindings.gather-in-1.group=gather2
#声明gather的输出数据通道
spring.cloud.stream.bindings.gather-out-0.destination=gatherOutExchange
#声明gatherEcho通道,处理gather的输出消息
spring.cloud.stream.bindings.gatherEcho-in-0.destination=gatherOutExchange
spring.cloud.stream.bindings.gatherEcho-in-0.group=gatherEcho
step3、然后配置一个Controller,往gather的两个输入通道里发消息。
@RequestMapping("sendGatherMessage")
public Object sendGatherMessage(String mess1,String mess2){
streamBridge.send("gather1",mess1);
streamBridge.send("gather2",mess2);
return "Gather Message sended :"+mess1+"; "+mess2;
}
接下来,访问这个接口,会往两个gather1和gather2两个通道上同时发消息,然后经过gather这个Binding,就可以将这两个通道的消息整合后一起发出去。

这里的Flux是Java响应式编程的一个信号通道,代表一个可以发送多个元素的信息源。以往在物联网等领域用得非常多。当MQ与响应式编程结合后,其实也是给MQ带来了另外一片广阔的应用空间。而关于这个空间的故事,且听下回分解。