Kubernetes 的用法和解析 -- 2
一.集群常用指令
1.1 基础控制指令
# 查看对应资源: 状态
$ kubectl get -n -o wide
[root@kube-master ~]# kubectl get pods -n kuboard -o wide
# 查看对应资源: 事件信息
$ kubectl describe -n
[root@kube-master ~]# kubectl describe pods kuboard-v3-5fc46b5557-7zj2p -n kuboard
# 查看pod资源: 日志
$ kubectl logs -f [CONTINER_NAME] -n
[root@kube-master ~]# kubectl logs -f kuboard-etcd-xxwwp -n kuboard
# 创建资源: 根据资源清单
$ kubectl apply[or create] -f .yaml
[root@kube-master ~]# kubectl apply -f mysql.yaml
# 删除资源: 根据资源清单
$ kubectl delete -f .yaml
[root@kube-master ~]# kubectl delete -f mysql.yaml
# 修改资源: 根据反射出的etcd中的配置内容, 生产中不允许该项操作, 且命令禁止
$ kubectl edit -n
[root@kube-master ~]# kubectl edit pods kuboard-etcd-xxwwp -n kuboard
1.2 命令实践
# 查看node状态
$ kubectl get node # -o wide 显示更加详细的信息
# 查看service对象
$ kubectl get svc
# 查看kube-system名称空间内的Pod
$ kubectl get pod -n kube-system
# 查看所有名称空间内的pod
$ kubectl get pod -A
# 查看集群信息
$ kubectl cluster-info
[root@kube-master ~]# kubectl cluster-info dump
# 查看各组件信息
$ kubectl -s https://api-server:6443 get componentstatuses
[root@kube-master ~]# kubectl -s https://192.168.58.149:6443 get pods -A
# 查看各资源对象对应的api版本
$ kubectl explain pod
# 查看帮助信息
$ kubectl explain deployment
$ kubectl explain deployment.spec
$ kubectl explain deployment.spec.replicas6.3 备注(问题处理)
问题一 查看各组件信息,可能会发现错误
$ kubectl -s https://192.168.96.143:6443 get componentstatuses
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
问题一解决
$ vim /etc/kubernetes/manifests/kube-scheduler.yaml
10 spec:
11 containers:
12 - command:
13 - kube-scheduler
14 - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
15 - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
16 - --bind-address=127.0.0.1
17 - --kubeconfig=/etc/kubernetes/scheduler.conf
18 - --leader-elect=true
19 - --port=0 # 将此行注释或删除
$ vim /etc/kubernetes/manifests/kube-controller-manager.yaml
10 spec:
11 containers:
12 - command:
13 - kube-controller-manager
14 - --allocate-node-cidrs=true
15 - --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
16 - --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
17 - --bind-address=127.0.0.1
18 - --client-ca-file=/etc/kubernetes/pki/ca.crt
19 - --cluster-cidr=10.244.0.0/16
20 - --cluster-name=kubernetes
21 - --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
22 - --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
23 - --controllers=*,bootstrapsigner,tokencleaner
24 - --kubeconfig=/etc/kubernetes/controller-manager.conf
25 - --port=0 # 将此行注释或删除
$ systemctl restart kubelet
$ kubectl -s https://192.168.96.143:6443 get componentstatuses
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}二.Yaml语法解析
YAML是一个类似 XML、JSON 的标记性语言。它强调以数据为中心,并不是以标识语言为重点。因而YAML本身的定义比较简单,号称"一种人性化的数据格式语言"。
YAML的语法比较简单,主要有下面几个:
1、大小写敏感
2、使用缩进表示层级关系
3、缩进不允许使用tab,只允许空格( 低版本限制 )
4、缩进的空格数不重要,只要相同层级的元素左对齐即可
5、'#'表示注释YAML支持以下几种数据类型:
1、纯量:单个的、不可再分的值
2、对象:键值对的集合,又称为映射(mapping)/ 哈希(hash) / 字典(dictionary)
3、数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)补充说明:
1、书写yaml切记: 后面要加一个空格
2、如果需要将多段yaml配置放在一个文件中,中间要使用---分隔
举个例子,通过声明式配置yaml 创建名称空间
$ vim namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: webserver
$ kubectl apply -f namespace.yaml
# 如果通过命令行创建
$ kubectl create namespace webserver
# 删除名称空间[注意,这将删除名称空间下的所有资源]
$ kubectl delete namespace webserver三.k8s中的Pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元; Pod 中会启动一个或一组紧密相关的业务容器, 各个业务容器相当于Pod 中的各个进程, 此时就可以将Pod 作为虚拟机看待; 在创建 Pod 时会启动一个init容器, 用来初始化存储和网络, 其余的业务容器都将在init容器启动后启动, 业务容器共享init容器的存储和网络; Pod 只是一个逻辑单元, 并不是真实存在的“主机”, 这种类比主机的概念可以更好的符合现有互联网中几乎所有的虚拟化设计; 像之前运行在虚拟机中的 nginx、mysql、php均可以使用对应的镜像运行出对应的容器在Pod中, 来类比虚拟机中运行这三者;
对于 Pod 而言, 在运行的过程中, k8s为了控制其生命周期的状态, 增加了容器探测指针、资源限额、期望状态保持、多容器结合、安全策略设定、控制器受管、故障处理策略 等; Pod在平时是不能够被单独创建的, 而是需要使用控制器对其创建, 这样可以时刻保持Pod的期望状态;
在Kubernetes中所有的资源均可通过命令行参数或者资源清单[yaml/json]的方式进行创建和修改, 但由于Kubernetes属于声明式资源控制集群, 故大多管理Kubernetes集群的方式采用资源配置清单; 资源配置清单可以很好的追溯资源的原型和详细的配置, 且配合版本控制能够完成更好的溯源、回滚、发布等操作; 所以课程中所有的资源创建和修改都会采用资源配置清单的方式, 除部分命令行操作以外;
Pod API 对象
问题:
通过yaml文件创建pod的时候里面有容器,这个文件里面到底哪些属性属于 Pod 对象,哪些属性属于 Container?
解决:
共同特征是,它们描述的是"机器"这个整体,而不是里面运行的"程序"。
容器可选的设置属性包括:
Pod是 k8s 项目中的最小编排单位。将这个设计落实到 API 对象上,容器(Container)就成了 Pod 属性里一个普通的字段。
把 Pod 看成传统环境里的"虚拟机机器"、把容器看作是运行在这个"机器"里的"用户程序",那么很多关于 Pod 对象的设计就非常容易理解了。
凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的
比如:
配置这个"机器"的网卡(即:Pod 的网络定义)
配置这个"机器"的磁盘(即:Pod 的存储定义)
配置这个"机器"的防火墙(即:Pod 的安全定义)
这台"机器"运行在哪个服务器之上(即:Pod 的调度)
kind:指定了这个 API 对象的类型(Type),是一个 Pod,根据实际情况,此处资源类型可以是Deployment、Job、Ingress、Service等。
metadata:包含Pod的一些meta信息,比如名称、namespace、标签等信息.
spec:specification of the resource content 指定该资源的内容,包括一些container,storage,volume以及其他Kubernetes需要的参数,以及诸如是否在容器失败时重新启动容器的属性。可在特定Kubernetes API找到完整的Kubernetes Pod的属性。
ˌ
specification----->[spesɪfɪˈkeɪʃn]
"name": 容器名称
"image": 容器镜像
"command": 容器启动指令
"args": 指令参数
"workingDir": 工作目录
"ports": 容器端口
"env": 环境变量
"resource": 资源限制
"volumeMounts": 卷挂载
"livenessProbe": 存活探针
"readinessProbe": 就绪探针
"startupProbe": 启动探针
"livecycle": 钩子函数
"terminationMessagePath": 容器的异常终止消息的路径,默认在 /dev/termination-log
"imagePullPolicy": 镜像拉去策略
"securityContext": 安全上下文
"stdin": 给容器分配标准输入,类似docker run -i
"tty": 分配终端
3.1 创建一个pod
$ vim nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
ports:
- containerPort: 80
$ kubectl apply -f nginx.yaml3.2 pod是如何被创建的
step1: kubectl 向 k8s api server 发起一个create pod 请求
step2: k8s api server接收到pod创建请求后,不会去直接创建pod;而是生成一个包含创建信息的yaml。
step3: apiserver 将刚才的yaml信息写入etcd数据库。
step4: scheduler 查看 k8s api,判断:pod.spec.Node == null,若为null,表示这个Pod请求是新来的,需要创建;因此先进行调度计算,找到最适合的node。并更新数据库
step5: node节点上的Kubelet通过监听数据库更新,发现有新的任务与自己的node编号匹配,则进行任务创建
3.3 创建一个单容器pod
$ vim mysql.yaml
apiVersion: v1
kind: Pod
metadata:
name: mysql
labels:
name: mysql
spec:
restartPolicy: OnFailure
containers:
- name: mysql
image: mysql:5.7
imagePullPolicy: IfNotPresent
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
resources:
limits:
memory: "1024Mi"
cpu: "1000m"
ports:
- containerPort: 3306
nodeSelector:
kubernetes.io/hostname: kub-k8s-node2
# nodeName: kub-k8s-node2
$ kubectl apply -f mysql.yaml
# 字段解析
restartPolicy:
pod 重启策略,可选参数有:
1、Always:Pod中的容器无论如何停止都会自动重启
2、OnFailure: Pod中的容器非正常停止会自动重启
3、Never: Pod中的容器无论怎样都不会自动重启
imagePullPolicy:
镜像拉取策略,可选参数有:
1、Always:总是重新拉取
2、IfNotPresent:默认,如果本地有,则不拉取
3、Never:只是用本地镜像,从不拉取
nodeSelector:
节点选择器:可以指定node的标签,查看标签指令:
nodeName:
节点名称: 可以指定node的名称进行调度
$ kubectl get node --show-labels3.4 创建一个多容器pod
#vim lnmp.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: nginx-many
namespace: default
labels:
app: nginx
spec:
restartPolicy: OnFailure
containers:
- name: nginx
image: nginx:1.16.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
- name: php-fpm
image: php:8.0-fpm-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9000
$ kubectl apply -f lnmp.yaml
# 字段解析
nodeSelector:
节点选择器:可以指定node的标签,查看标签指令:
$ kubectl get node --show-labels配置节点标签
添加标签
kubectl label nodes node3 name=value
删除标签
kubectl label nodes node3 name-
3.5 Pod容器的交互
3.5.1 创建pod,并做本地解析
vim host-alias.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: centos
labels:
name: centos
spec:
containers:
- name: centos
image: centos:7
command:
- "tail"
- "-f"
- "/dev/null"
hostAliases:
- ip: "192.168.100.128"
hostnames:
- "master"
- "k8s-master"
- "apiserver"
# 字段解析
command:
启动容器时执行的指令,类似于docker run -it 镜像 tail -f /dev/null
hostAliases:
在容器中的/etc/hosts文件中配置本地解析3.5.2 pod共享进程
[root@kube-master prome]# kubectl delete -f pod.yml
pod "website" deleted
[root@kube-master prome]# vim pod.yml #修改如下。最好是提前将镜像pull下来。
---
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
spec:
shareProcessNamespace: true #共享进程名称空间
containers:
- name: test-web
image: daocloud.io/library/nginx
ports:
- containerPort: 80
- name: busybox
image: daocloud.io/library/busybox
stdin: true
tty: true
# 创建
[root@kube-master prome]# kubectl apply -f pod.yml
pod/website created1. 定义了 shareProcessNamespace=true
表示这个 Pod 里的容器要共享进程(PID Namespace)如果是false则为不共享。
2. 定义了两个容器:
一个 nginx 容器
一个开启了 tty 和 stdin 的 busybos 容器在 Pod 的 YAML 文件里声明开启它们俩,等同于设置了 docker run 里的 -it(-i 即 stdin,-t 即 tty)参数。此 Pod 被创建后,就可以使用 shell 容器的 tty 跟这个容器进行交互了。
# 我们通过kubectl可以查看到
# kubectl exec -it website -c busybox -- ps aux
PID USER TIME COMMAND
1 root 0:00 /pause
7 root 0:00 nginx: master process nginx -g daemon off;
35 101 0:00 nginx: worker process
36 root 0:00 sh
66 root 0:00 ps aux
在busybox中可以查看到nginx的进程3.5.3 pod共用宿主机namespace
# 刚才的都是pod里面容器的Namespace,并没有和本机的Namespace做共享,接下来我们可以做与本机的
# Namespace共享,可以在容器里面看到本机的进程。
[root@kub-k8s-master prome]# kubectl delete -f pod.yml
pod "website" deleted
[root@kub-k8s-master prome]# vim pod.yml #修改如下
---
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
spec:
hostNetwork: true #共享宿主机网络
hostIPC: true #共享ipc通信
hostPID: true #共享宿主机的pid
containers:
- name: test-web
image: daocloud.io/library/nginx
ports:
- containerPort: 80
- name: busybos
image: daocloud.io/library/busybox
stdin: true
tty: true
# 创建pod
[root@kub-k8s-master prome]# kubectl apply -f pod.yml
pod/website created
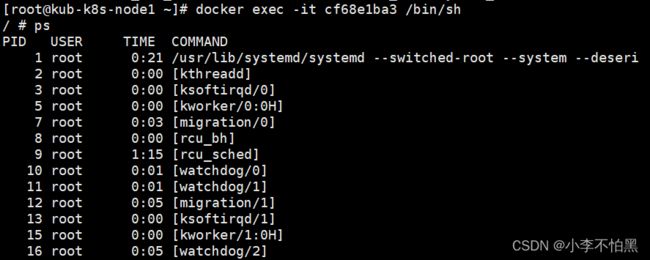
定义了共享宿主机的 Network、IPC 和 PID Namespace。这样,此 Pod 里的所有容器,会直接使用宿主机的网络、直接与宿主机进行 IPC 通信、看到宿主机里正在运行的所有进程。
3.6 钩子函数lifecycle
kubernetes 在主容器启动之后和删除之前提供了两个钩子函数:
post start:容器创建之后执行,如果失败会重启容器
pre stop:容器删除之前执行,执行完成之后容器将成功删除,在其完成之前会阻塞删除容器的操作
钩子函数有三种定义方式
第一种 exec 执行指令
第二种 在容器中请求端口
第三种 向容器发起http请求
lifecycle:
postStart:
exec:
command:
- cat
- /etc/hostslifecycle:
postStart:
tcpSocket:
port: 8080 lifecycle:
postStart:
httpGet:
path: / # URI地址
port: 80 # 端口号
host: 192.168.96.10 # 主机地址
scheme: HTTP一个钩子函数的示例:
$ cat nginx-lifecycle.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-lifecycle
namespace: default
labels:
app: nginx
spec:
containers:
- name: nginx-lifecycle
image: nginx:1.16.1
ports:
- containerPort: 80
protocol: TCP
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo 'this is a nginx-lifecycle test page
' > /usr/share/nginx/html/index.html"]
preStop:
exec:
command: ["/usr/sbin/nginx", "-s", "quit"]
$ kubectl apply -f nginx-lifecycle.yaml
pod/pod-lifecycle created四.容器监控检查及恢复机制
在 k8s 中,可以为 Pod 里的容器定义一个健康检查"探针"(Probe)。kubelet 就会根据这个 Probe 的返回值决定这个容器的状态,而不是直接以容器是否运行(来自 Docker 返回的信息)作为依据。这种机制,是生产环境中保证应用健康存活的重要手段。
4.1 命令模式探针
Kubernetes 文档中的例子:
[root@kube-master ~]# cd prome/
[root@kube-master prome]# vim test-liveness-exec.yaml
---
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: test-liveness-exec
spec:
containers:
- name: liveness
image: daocloud.io/library/nginx
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 50
livenessProbe: #探针,健康检查
exec: #类型
command: #命令
- cat
- /tmp/healthy
initialDelaySeconds: 5 #健康检查,在容器启动5s后开始执行
periodSeconds: 5 #每5s执行一次
它在启动之后做的第一件事是在/tmp目录下创建了一个healthy文件,以此作为自己已经正常运行的标志。而30s过后,它会把这个文件删除掉。
与此同时,定义了一个这样的 livenessProbe(健康检查)。它的类型是 exec,它会在容器启动后,在容器里面执行一句我们指定的命令,比如:"cat /tmp/healthy"。这时,如果这个文件存在,这条命令的返回值就是 0,Pod就会认为这个容器不仅已经启动,而且是健康的。这个健康检查,在容器启动5s后开始执行(initialDelaySeconds: 5),每5s执行一次(periodSeconds: 5)。创建Pod:
[root@kube-master prome]# kubectl apply -f test-liveness-exec.yaml
pod/test-liveness-exec created查看 Pod 的状态:
[root@kube-master prome]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-configmap 1/1 Running 0 16h
nginx-pod 1/1 Running 0 12h
test-liveness-exec 1/1 Running 0 75s由于已经通过了健康检查,这个 Pod 就进入了 Running 状态。
然后30 s 之后,再查看一下 Pod 的 Events:
[root@kube-master prome]# kubectl describe pod test-liveness-exec发现,这个 Pod 在 Events 报告了一个异常:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Unhealthy 54s (x9 over 3m34s) kubelet, kub-k8s-node1 Liveness probe failed: cat: /tmp/healthy: No such file or directory
这个健康检查探查到 /tmp/healthy 已经不存在了,所以它报告容器是不健康的。那么接下来会发生什么呢?
再次查看一下这个 Pod 的状态:
[root@kube-master prome]# kubectl get pod test-liveness-exec
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 4 5m19s这时发现,Pod 并没有进入 Failed 状态,而是保持了 Running 状态。这是为什么呢?
RESTARTS 字段从 0 到 1 的变化,就明白原因了:这个异常的容器已经被 Kubernetes 重启了。在这个过程中,Pod 保持 Running 状态不变。 #注 k8s 中并没有 Docker 的 Stop 语义。所以如果容器被探针检测到有问题,查看状态虽然看到的是 Restart,但实际却是重新创建了容器。
这个功能就是 Kubernetes 里的Pod 恢复机制,也叫 restartPolicy。它是 Pod 的 Spec 部分的一个标准字段(pod.spec.restartPolicy),默认值是 Always,即:任何时候这个容器发生了异常,它一定会被重新创建。
小提示:
Pod 的恢复过程,永远都是发生在当前节点上,而不会跑到别的节点上去。事实上,一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。这也就意味着,如果这个宿主机宕机了,这个 Pod 也不会主动迁移到其他节点上去。
4.2 http get方式探针
[root@kube-master prome]# vim liveness-httpget.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: daocloud.io/library/nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe: #探针,健康检查
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3创建该pod
[root@kube-master prome]# kubectl create -f liveness-httpget.yaml
pod/liveness-httpget-pod created查看当前pod的状态
[root@kub-k8s-master prome]# kubectl describe pod liveness-httpget-pod
...
Liveness: http-get http://:http/index.html delay=1s timeout=1s period=3s #success=1 #failure=3
...
登陆容器
# 测试将容器内的index.html删除掉
[root@kub-k8s-master prome]# kubectl exec -it liveness-httpget-pod /bin/bash
root@liveness-httpget-pod:/# mv /usr/share/nginx/html/index.html index.html
root@liveness-httpget-pod:/# command terminated with exit code 137
# 可以看到,当把index.html移走后,这个容器立马就退出了。此时,查看pod的信息
[root@kub-k8s-master prome]# kubectl describe pod liveness-httpget-pod
...
Normal Killing 49s kubelet, kub-k8s-node2 Container liveness-exec-container failed liveness probe, will be restarted
Normal Pulled 49s kubelet, kub-k8s-node2 Container image "daocloud.io/library/nginx" already present on machine
...
看输出,容器由于健康检查未通过,pod会被杀掉,并重新创建
[root@kubemaster prome]# kubectl get pods
NAME READY STATUS RESTARTS AGE
lifecycle-demo 1/1 Running 1 34h
liveness-httpget-pod 1/1 Running 1 5m42s
#restarts 为 1重新登陆容器,发现index.html又出现了,证明容器是被重拉了。
[root@kube-master prome]# kubectl exec -it liveness-httpget-pod /bin/bash
root@liveness-httpget-pod:/# cat /usr/share/nginx/html/index.html4.3 POD 的恢复策略
Pod 恢复策略:
可以通过设置 restartPolicy,改变 Pod 的恢复策略。一共有3种:
1. Always: 在任何情况下,只要容器不在运行状态,就自动重启容器;
2. OnFailure: 只在容器 异常时才自动重启容器;
3. Never: 从来不重启容器。
实际使用时,需要根据应用运行的特性,合理设置这三种恢复策略。
五.投射数据卷 Projected Volume
注:Projected Volume 是 Kubernetes v1.11 之后的新特性
5.1 什么是Projected Volume
在 k8s 中,有几种特殊的 Volume,它们的意义不是为了存放容器里的数据,"而是为容器提供预先定义好的数据。"
从容器的角度来看,这些 Volume 里的信息仿佛是被 k8s "投射"(Project)进入容器当中的。
5.2 k8s 支持的 Projected Volume 方式
Secret
ConfigMap
Downward API