三小时学会Kubernetes:容器编排详细指南
如果谁都可以在三个小时内学会Kubernetes,银行为何要为这么简单的东西付一大笔钱?
如果你心存疑虑,我建议你不妨跟着我试一试!在完成本文的学习后,你就能在Kubernetes集群上运行基于微服务的应用程序。我之所以能保证这一点,是因为我就是这么向客户介绍Kubernetes的。
这份指南与其他文章有何不同之处?
相当多!大多数指南是从Kubernetes概念和kubectl命令这类简单的东西开始的。它们假定读者熟悉应用程序开发、微服务和Docker容器。
而在我们这篇文章中,步骤是:
1、在你的计算机上运行基于微服务的应用程序。
2、为微服务应用程序的每个服务构建容器镜像。
3、介绍Kubernetes。将基于微服务的应用程序部署到Kubernetes管理的集群中。
循序渐进的过程为普通人掌握Kubernetes的简易性提供了必要的深度。没错,当你了解使用Kubernetes的上下文时,一切就变得很简单了。废话不多说,接下来看看我们所要构建的东西。
应用程序演示
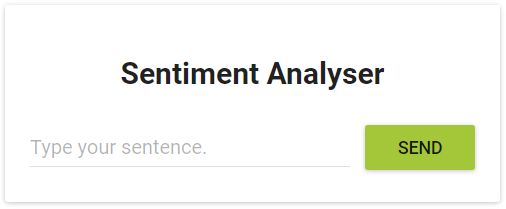
该应用程序只有一个功能:它以一个句子作为输入,使用文本分析计算出句子的情感值。
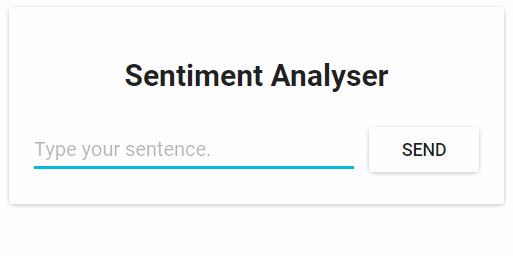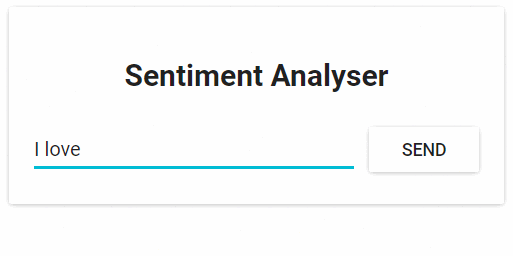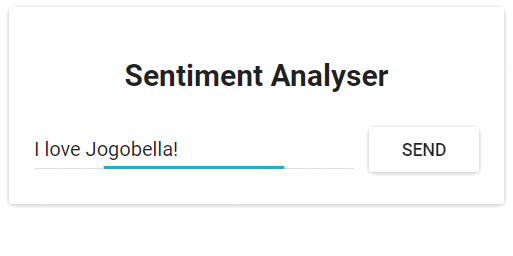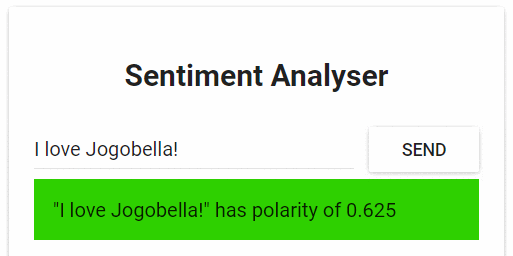
图1.情绪分析web应用程序
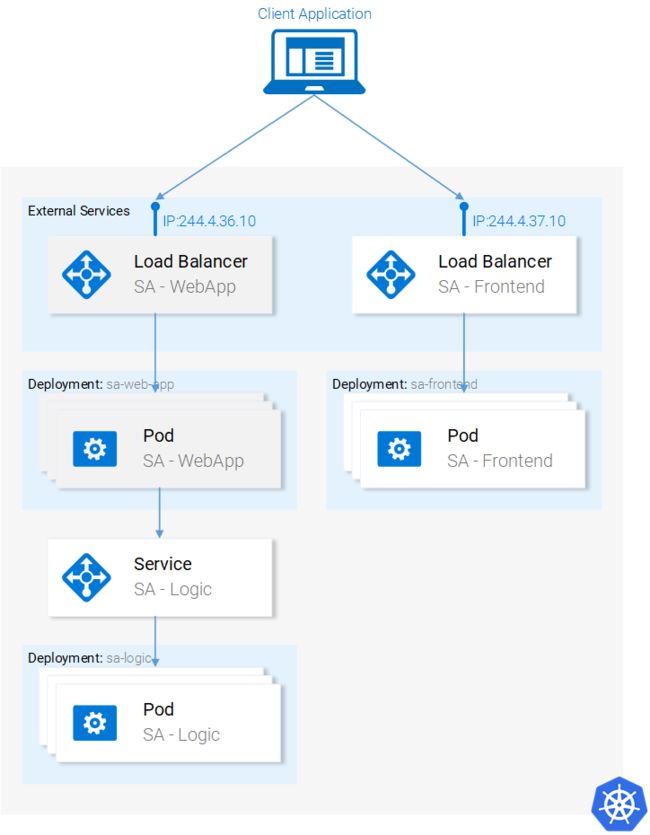
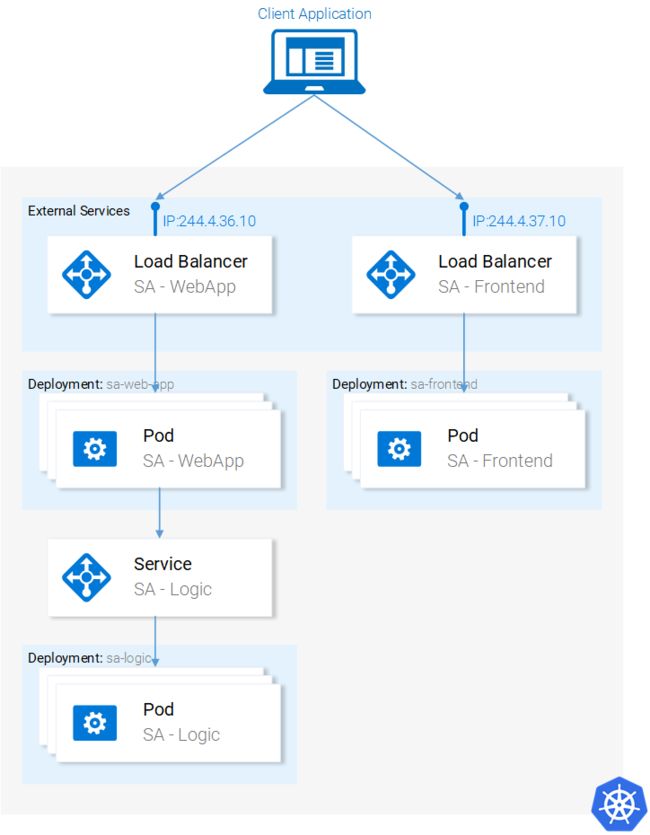
从技术的角度,这个应用程序由三个微服务组成。每个微服务都具有一个特定功能:
SA-Frontend:提供ReactJS静态文件访问的Nginx Web服务器。
SA-WebApp:处理来自前端的JavaWeb应用程序
SA-Logic:执行情绪分析的Python应用程序。
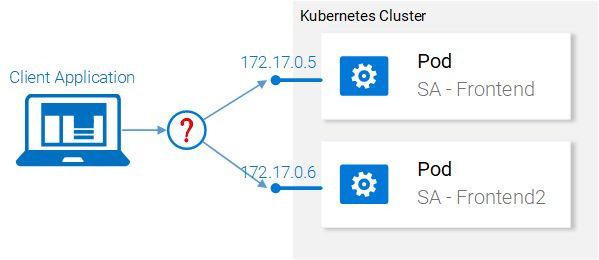
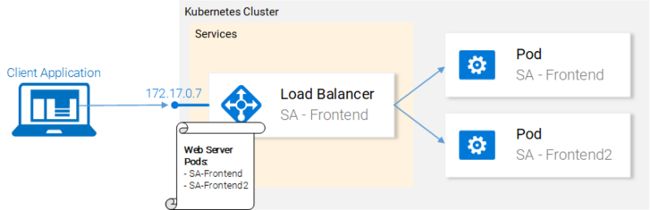
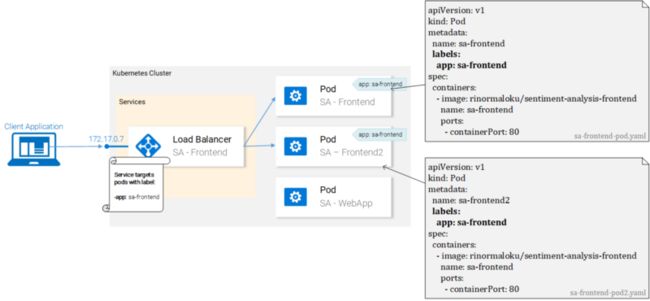
微服务不是孤立存在的,它们可以实现“关注点分离”,但还是需要互相交互,理解这一点非常重要。

图2.情绪分析WebApp中的数据流
通过展示数据在它们之间的流动方式是对这种交互最好的说明:
1、客户端应用程序请求index.html(继而请求ReactJS应用程序的捆绑脚本)
2、用户与应用程序交互会触发对Spring WebApp的请求。
3、Spring WebApp将情绪分析请求转发给Python应用程序。
4、Python应用程序计算情感值并将结果作为响应返回。
5、Spring WebApp将响应返回给React应用程序(然后将信息展示给用户)
所有这些应用程序的代码都可以在本仓库中找到。建议读者现在将代码克隆下来,因为我们即将一起构建出很棒的东西。
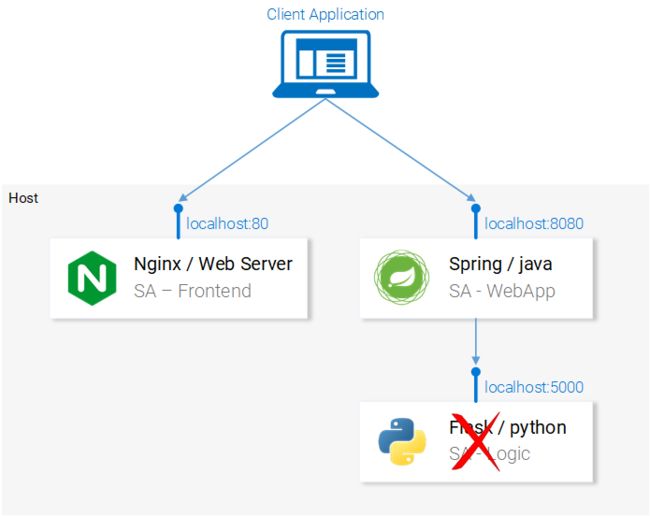
1. 在你的计算机上运行基于微服务的应用程序
我们需要启动所有三项服务。就从最具吸引力的前端应用程序开始吧。
为本地开发设置React
要启动React应用程序,你需要在计算机上安装NodeJS和NPM。安装完成后,使用终端定位到sa-frontend目录。输入以下命令:
npm install
这会下载该React应用程序依赖的所有JavaScript,并将其放置在node_modules文件夹中(依赖关系定义在package.json文件中)。在处理完所有依赖关系后,执行下一条命令:
npm start
搞定!我们的React应用程序启动了,默认情况下你可以通过localhost:3000对其进行访问。你可随意修改代码并立即在浏览器上看到效果,这是通过模块热替换(Hot Module Replacement)实现的,从而大大降低了前端开发的难度!
发布我们的React应用
在生产环境中,我们需要将应用程序构建成静态文件,并使用Web服务器提供访问。
要构建该React应用程序,请在终端中定位到sa-frontend目录。然后执行以下命令:
npm run build
这会在项目树中生成一个名为build的文件夹。该文件夹包含了我们的ReactJS应用程序所需的静态文件。
用Nginx提供静态文件访问
安装并启动Nginx服务器。然后将sa-frontend/build文件夹的内容移动到[nginx安装目录]/html中。这样,生成的index.html文件可以在[nginx安装目录]/html/index.html(这就是Nginx的默认访问文件)中访问到。
默认情况下,Nginx服务器会监听80端口。可通过修改[nginx安装目录]/conf/nginx.conf文件中的server.listen参数来指定其他端口。
使用浏览器打开localhost:80,ReactJS应用程序将会出现
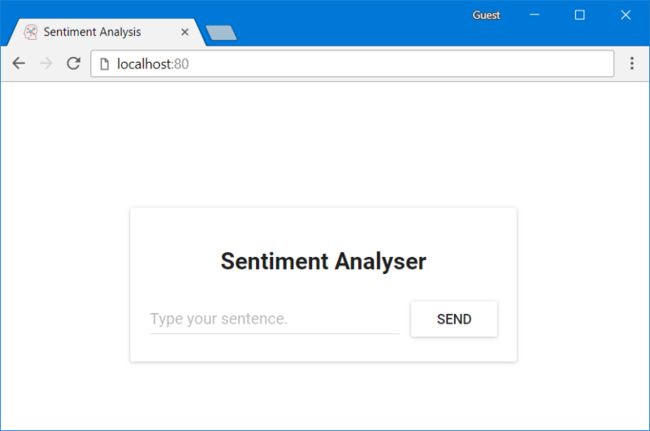
图3.Nginx提供的React应用程序页面
在“Type your sentence.”字段中进行输入,然后按下Send按钮,将返回一个404错误(可在浏览器控制台中查看)。但为什么会这样呢?我们来看一下代码。
查看代码
在App.js文件中我们可以看到,按下Send按钮会触发analyzeSentence方法。该方法的代码如下所示(使用#注释的各行在脚本下放进行说明):
analyzeSentence(){
fetch('http://localhost:8080/sentiment',{ //#1
method:'POST',
headers:{
'Content-Type':'application/json'
},
body:JSON.stringify({
sentence:this.textField.getValue()#2
})
})
.then(reponse => reponse.json())
.then(data=>this.setState(data));#3
}
#1:进行POST调用的URL(应用程序会监听该URL的调用)
#2:发送给应用程序的请求主体,如下所示:
{
sentence:"I like yogobella!"
}
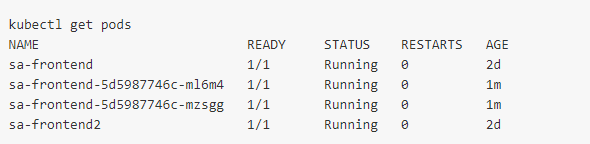
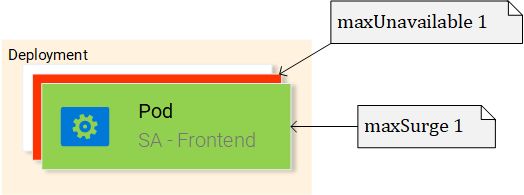
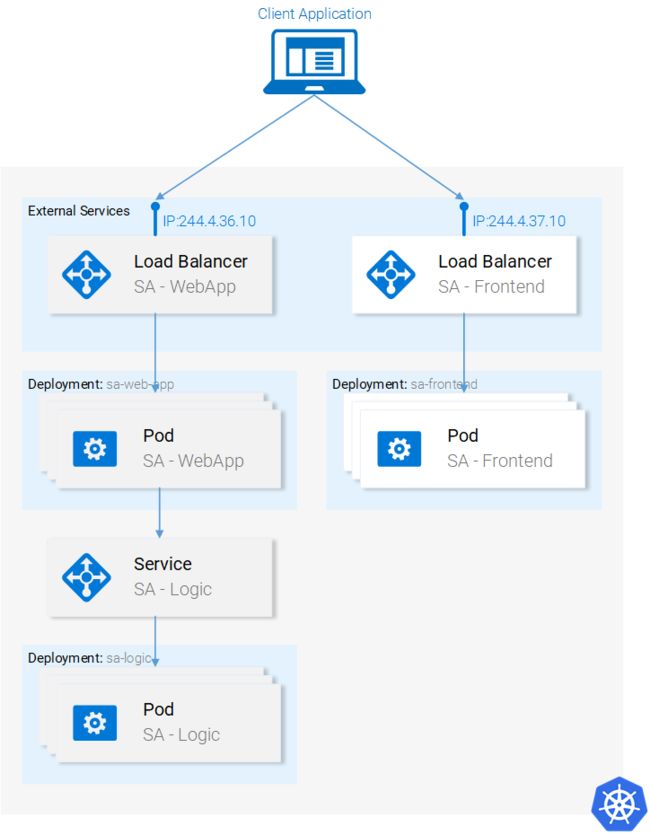
#3使用响应来更新组件状态。这会触发组件的重新渲染。在收到的数据(即包含输入句子机器情感值的JSON对象)后,如下定义的polarityComponent组件的条件得到了满足,从而进行了显示:
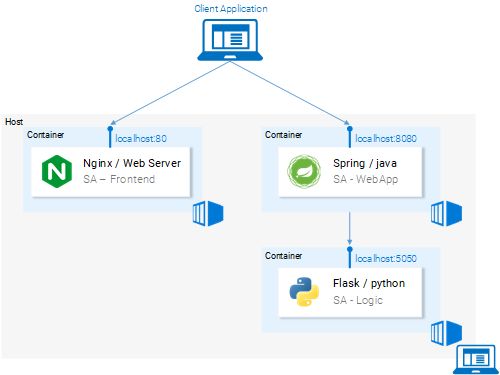
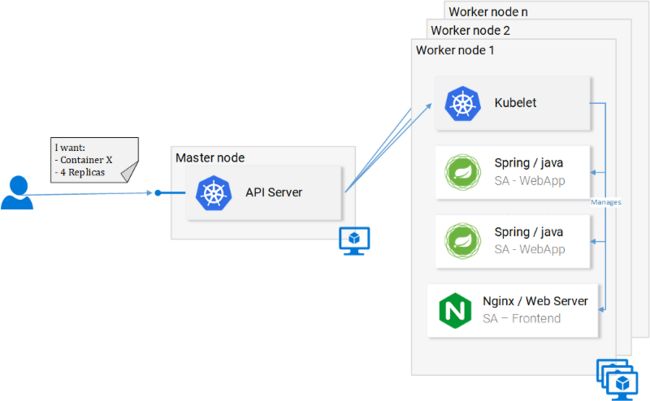
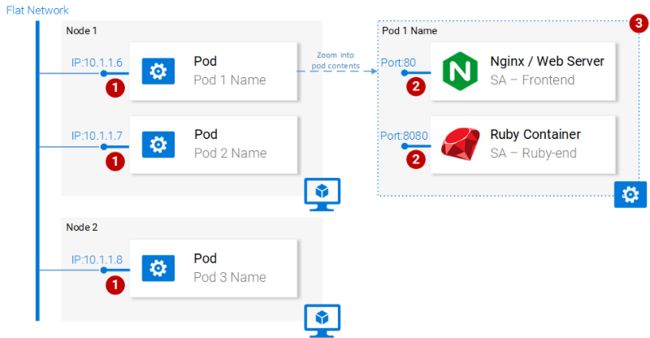
const polarityComponent=this.state.polarity!==undefined? polarity={this.state.polarity}/> : null; 一切看起来都是对的。那么我们遗漏什么了?如果你猜是因为我们没有设置任何东西来监听localhost:8080,那么恭喜你,答对了!我们需要启动Spring Web应用程序来监听该端口! 图4.Spring WebApp微服务缺失 设置Spring Web应用程序 要启动该Spring应用程序,你需要安装JDK8和Maven(还需要设置其环境变量)。安装完成后,我们继续进行下一步。 将应用程序打成Jar包 在终端中定位到sa-webapp目录并输入以下命令: maven install 这将在sa-webapp目录中生成一个名为target的文件夹。我们的Java应用程序会被打包成'sentiment-analysis-web-0.0.1-SNAPSHOT.jar'放在target文件夹中。 启动我们的Java应用程序 定位到target目录并使用以下命令启动该应用程序: java -jar sentiment-analysis-web-0.0.1-SNAPSHOT.jar 糟糕!我们碰到了一个错误。应用程序启动失败了,唯一的线索是堆栈跟踪中的异常信息: Error creating bean with name 'sentimentController': Injection of autowired dependencies 这里面的重点信息是SentimentController中的sa.logic.api.url占位符。我们来看一下! 查看代码 @CrossOrigin(origins = "*") @RestController public class SentimentController { @Value("${sa.logic.api.url}") // #1 private String saLogicApiUrl; @PostMapping("/sentiment") public SentimentDto sentimentAnalysis( @RequestBody SentenceDto sentenceDto) { RestTemplate restTemplate = new RestTemplate(); return restTemplate.postForEntity( saLogicApiUrl "/analyse/sentiment", // #2 sentenceDto, SentimentDto.class) .getBody(); } } 1、SentimentController有一个名为saLogicApiUrl的字段。字段值由sa.logic.api.url参数定义。 2、字符串saLogicApiUrl与“/analyse/sentiment”拼接形成发送情绪分析请求的URL。 定义该参数 Spring默认的参数源是application.properties(位于sa-webapp/src/main/resources中)。但是,它不是定义参数的唯一方法,也可以使用前面的命令来实现: java -jar sentiment-analysis-web-0.0.1-SNAPSHOT.jar --sa.logic.api.url=SA.LOGIC.API的路径 这个参数要使用我们的Python应用程序运行的地址进行初始化,这样就可以让Spring Web应用程序知道在运行时要将消息转发到哪里。 为了简单起见,我们将在localhost:5000上运行Python应用程序。请记住这一点! 运行如下命令,我们就可以转移到最后一个服务——Python应用程序。 java -jar sentiment-analysis-web-0.0.1-SNAPSHOT.jar --sa.logic.api.url=http://localhost:5000 设置Python应用程序 要启动Python应用程序,我们需要安装Python3和Pip(还需要设置其环境变量)。 安装依赖项 在终端中定位到sa-logic/sa目录(仓库)并输入以下命令: python -m pip install -r requirements.txt python -m textblob.download_corpora 启动应用 使用Pip安装依赖项后,我们即可通过执行以下命令来启动应用程序: python sentiment_analysis.py * Running on http://localhost:5000/ (Press CTRL+C to quit) 现在,我们的应用程序已经启动并在localhost的5000端口上监听HTTP请求。 查看代码 我们来检查一下代码以了解SA Logic这个Python应用程序中发生了什么。 from textblob import TextBlob from flask import Flask,request,jsonify app=Flask(__name__)#1 @app.route("/analyse/sentiment",method=['POST'])#2 def analyse_sentiment(): sentence=request.get__json()['sentence']#3 polarity=TextBlob(sentence).sentences[0].polarity#4 return jsonify(#5 sentence=sentence, polarity=polarity ) if__name__=='__main__': app.run(host='localhost',port=5000)#6 1、实例化一个Flask对象。 2、定义POST请求的路径。 3、从请求主体中提取“sentence”参数。 4、实例化一个匿名TextBlob对象并获取第一个句子(这里只有一个)的polarity。 5、将包含sentence和polarity内容的响应返回给调用者。 6、运行flask对象应用以监听localhost:5000上的请求。 这些服务被设置为相互通信。在继续前请重新打开前端localhost:80,并尝试输入句子! 图6.微服务架构完成了 在下一节中,我们将继续介绍如何在Docker容器中启动服务,因为这是在Kubernetes集群中运行服务的先决条件。 2、为每个服务构建容器镜像 Kubernetes是一个容器编排器。很显然,我们需要容器以便对其进行编排。那么什么是容器?这从Docker的文档中可以得到最好的回答。 容器镜像像是一个轻量级,独立的执行软件包,它包含了软件运行所需的全部内容:代码,运行时,系统工具,系统库,设置等等。不论是基于Linux或是Windows的应用,容器化的软件在任何环境中都能同样运行。 这意味着容器可以在包括生产服务器的任何计算机上无差别地运行。 为了便于说明,我们呢来比较一下如何使用虚拟机与容器来提供我们的React应用程序服务。 通过VM来提供React静态文件访问 使用虚拟机的缺点: 1、资源效率低下,每个虚拟机都有一个完整的操作系统的额外开销。 2、它依赖平台。在你的计算机上正常工作的东西,在生产服务器上有可能无法正常工作。 3、与容器相比,属于重量级产品,且扩展较慢。 图7.虚拟机上的提供态文件访问的Nginx Web服务器 通过容器来提供React静态文件访问 1、在Docker的协助下使用宿主机操作系统,资源利用率较高。 2、平台无关。在你的计算机上正常运行容器在任何地方也都可以正常工作。 3、使用镜像层实现轻量化。 图8.容器中提供静态文件访问的Nginx Web服务器 这些是使用容器最显着的特点和好处。有关容器的更多信息,可阅读Docker文档。 Docker容器的基础构建块是Dockerfile。Dockerfile开头是一个基础容器镜像,后面是有关构建满足应用程序需求的新容器镜像的一系列指令。 在开始定义Dockerfile之前,回忆一下使用Nginx提供静态文件访问的步骤: 1、构建静态文件(npm run build) 2、启动Nginx服务器 3、将sa-frontend项 目中build目录的内容复制到nginx/html中。 在下一节中,你会发现创建一个容器与本地React设置中所做的极其类似。 定义SA-Frontend的Dockerfile SA-Frontend的Dockerfile是执行两个步骤的指令。Nginx团队已经提供了一个Nginx基础镜像,我们只要在它的基础上进行构建即可。这两个步骤是: 1、从基础的Nginx镜像开始。 2、将sa-frontend/build目录复制到容器的nginx/html目录。 转换成Dockerfile看起来是这样的: FROM nginx COPY build /usr/share/nginx/html 是不是很酷?这个文件具有很好的可读性,复述起来就是: 从Nginx镜像开始(不管那些家伙在里面做了什么),将build目录复制到镜像中的nginx/html目录完成! 你可能会问,怎么知道build文件要复制到哪里?也就是/usr/share/nginx/html。很简单,查看Docker Hub上Nginx镜像的文档。 构建并推送容器 在推送镜像之前,我们需要一个容器Registry来托管容器。Docker Hub是一个免费的云容器服务,我们将用其进行演示。在继续之前,你有三项任务: 1、安装Docker CE。 2、在Docker Hub上注册。 3、在终端中执行以下命令进行登录: docker login -u="$DOCKER_USERNAME" -p="$DOCKER_PASSWORD" 完成上述任务后,定位到sa-frontend目录。然后执行以下命令(请把$DOCKER_ID_USER替换成你的Docker Hub用户名,比如rinormaloku/sentiment-analysis-frontend): docker build -f Dockerfile -t $DOCKER_ID_USER/sentiment-analysis-frontend. -f Dockerfile 可以省略,因为我们呢正处在包含Dockerfile的目录中。 要推送镜像,请使用docker push命令: docker push $DOCKER_USER_ID/sentiment-analysis-frontend 在你的Docker Hub仓库中验证一下镜像是否已推送成功。 运行容器 现在,任何人都可以拉取并运行$DOCKER_USER_ID/sentiment-analysis-frontend中的镜像: docker pull $DOCKER_USER_ID/sentiment-analysis-frontend docker run -d -p 80:80 $DOCKER_ID_USER/sentiment-analysis-frontend 我们的Docker容器运行起来了! 在继续之前,需要说明一下容易发生混淆的80:80: 第一个80是宿主机的端口(即我的电脑) 第二个80表示请求所要转发的容器端口。 图9.宿主机到容器的端口映射 它将<宿主机端口>映射到<容器端口>上。这意味着对宿主机80端口的请求将被映射到容器的80端口中,如图9所示。 由于这个端口运行在宿主机(你的计算机)的80端口上,因此可以通过localhost:80进行访问。如果没有原声的Docker支持,你可以通过 动手试试!你应该能够通过它访问到我们的React应用程序了。 Dockerignore文件 正如我们之前所见,构建SA-Frontend的镜像速度很慢,非常非常慢。这是因为构建时需要及那个构建的上下文发送给Docker守护进程。更具体地说,构建上下文表示的是Dockerfile所在目录中构建镜像所需的所有数据。在我们的示例中,SA前端包含以下文件夹: sa-frontend: | .dockerignore | Dockerfile | package.json | README.md ---build ---node_modules ---public \---src 但我们需要的唯一数据都在build文件夹中,上传其他内容是在浪费时间。我们可以通过忽略其他目录来减少构建时间。这就是.dockerignore的目录。对你而言这个文件应该不陌生,因为它与.gitignore类似,只要将所有想忽略的目录都添加到.dockerignore文件中即可,其内容如下所示: node_modules src public .dockerignore文件应与Dockerfile位于同一文件夹中。现在构建镜像只需要几秒钟。 接下来继续说明Java应用程序。 为Java应用程序构建容器镜像 你猜怎么了!你几乎已经学会了创建容器镜像的所有内容!因此这个部分非常短。 打开sa-webapp中的Dockerfile,你会发现有两个关键字: ENV SA_LOGIC_API_URL http://localhost:5000 EXPOSE 8080 ENV关键字是在Docker容器中声明一个环境变量。这让我们呢可以在启动容器时制定情绪分析API的URL。 其次,EXPOSE关键字暴露了我们呢稍后要访问的端口。但是,我们在SA-Frontend的Dockerfile中并没有那么做。好问题,原因是它仅仅用于文档的目的,换句话说,它仅仅是为了给阅读Dockerfile的人提供相关信息用的。 你对容器镜像的构建和推送应该比较熟悉了。如果遇到任何困难,请阅读sa-webapp目录中的README.md文件。 为Python应用程序构建容器镜像 sa-logic的Dockerfile中没有新的关键字。现在你可以称自己为Docker专家了。 要构建和推送容器镜像,请阅读sa-logic目录中的README.md。 测试容器化的应用程序 你会信任没有经过测试的东西吗?我是不会。接下来让我们对这些容器进行一轮测试。 1、运行sa-logic容器并配置其监听5050端口: docker run -d -p 5050:5000 $DOCER_ID_USER/sentiment-analysis-logic 2、运行sa-webapp容器并配置其监听8080端口(因为我们修改了Python应用监听的端口,我们需要覆盖SA_LOGIC_API_URL环境变量): docker run -d -p 8080:8080 $DOCKER_USER_ID/sentiment-analysis-web-app -e SA_LOGIC_API_URL='http://localhost:5050' 3、运行sa-frontend容器: docker run -d -p 80:80 $DOCKER_USER_ID/sentiment-analysis-frontend 注意:如果你修改了sa-webapp的端口,或者使用的是docker-machine ip,则需要修改sa-frontend中App.js文件的analyzeSentence方法,以便从新的IP或端口获取数据。然后你需要重新构建,并使用更新后的镜像。 图10.运行在容器中的微服务 思考题:为什么要用Kubernetes? 在本节中,我们了解了Dockerfile、如何使用它来构建镜像以及将其推送到Docker Registry的命令。此外,我们还学会了如何通过忽略无用文件以减少发送给构建上下文的文件数量。最后,我们在容器中将应用程序运行了起来。那么为什么要使用Kubernetes?这一点将在下一节中深入探讨,你不妨先思考一下: 我们的情绪分析Web应用成了世界热点,突然每分钟有一百万个分析情绪的请求,sa-webapp和sa-logic遭遇了巨大的负载。我们要如何扩展容器? Kubernetes介绍 我可以保证且毫不夸张地说,到文章结束时,你会问自己:“为何我们不称它为Supernetes(译者注:借用Superman)?” 图11、Supernetes 本文从开始到现在,已经覆盖了如此多的背景和知识。你可能担心现在会是最难的部分,但实际上它最简单。学习Kubernetes之所以令人生畏,唯一原因是因为“其他的一切”,而我们已经很好地学完了这些东西。 Kubernetes是什么? 在从容器启动我们的微服务之后,我们碰到了一个问题,下面我们以问答形式进一步阐述它: 问:如何进行容器扩展? 答:再启动一个。 问:如何在它们之间分担负载?如果服务器已经使用到极限,并且我们的容器需要另一台服务器,怎么办?如何计算最佳的硬件利用率? 答:啊……呃……(我Google一下)。 问:如何在不影响任何内容的情况下进行更新?如果需要,该如何退到可工作的版本? Kubernetes解决了所有这些问题(以及其他更多问题!)。我可以用一句话来介绍Kubernetes:“Kubernetes是一个容器编排器,他对底层基础设施(容器运行的地方)进行了抽象”。 我们对容器编排器有一个模糊的概念。后文的实践中会看到它,但这是我们第一次说到“对底层基础设施进行抽象”,这点需要做个详细说明。 对底层基础设施进行抽象 Kubernetes提供了一套简单的用于发送请求的API,对底层基础设置进行抽象。Kubernetes会尽其最大能力来满足这些请求。比如说,可以简单地请求“Kubernetes启动4个x镜像的容器”,然后Kubernetes会找出利用率不足的节点,在这些节点中启动新的容器。 图12.发送到API服务器的请求 对开发者这意味着什么?意味着他无须关心节点的数量,容器在哪启动以及它们之间如何通信。他无须处理硬件优化,也无须担心节点宕机(根据墨菲定律,节点一定会宕机),因为他可以将新节点添加到Kubernetes集群中。Kubernetes会在正常运转的节点上启动容器。它会尽其最大能力来做到这一点。 在图12中,我们可以看到一些新的东西: API服务器:与集群交互的唯一途径。用于启动或停止容器(误,实为pod),检查当前状态,日志等。 Kubelet:监控节点内容器(误,实为pod),并与主节点进行通信。 Pod:一开始可以将Pod当容器看待。 对Kubernetes的介绍到此为止,再深入的话会分散我们的关注点,如有需要有大量有用的资源可供大家学习,比如官方文件(困难模式)或是Marko Lukša编写的《Kubernetes in Action》。 云服务提供商标准化 Kubernetes强力推动的另一个项是,将云服务提供商(CSP)标准化。这是一个大胆的声明,我们用一个例子来说明: – 某个Azure、Google云平台或其他CSP的专家在一个全新的CSP中开展项目,但他对此毫无经验。这会造成很多后果,比如可能会错过最后期限;公司可能需要购买更多资源等等。 但这对Kubernetes根本不是问题。因为不论是哪个CSP,发送给API服务器的执行命令都是相同的。你以声明方式从API服务器请求所需要的东西,Kubernetes抽象并实现了CSP的对该请求的动作。 很显然,这是个非常强大的功能。对于公司来说,这意味着不需要与CSP捆绑在一起。只需要计算出在另一个CSP上的支出,然后就可以进行迁移。专业知识、资源都还在,而且可以更便宜! 说了这么多,下一节我们将把Kubernetes付诸实践。 Kubernetes实践-----Pod 把微服务运行在容器中,虽然行得通,但是设置过程相当繁琐。我们还提到这个解决方案不具有可扩展性和弹性,而Kubernetes则可解决这些问题。本文后续部分,我们会把服务迁移成图13所示的最终结果,由Kubernetes来编排容器。 图13.运行在Kubernetes管理的集群中的微服务 本文将使用Minikube进行本地调试,不过所有东西在Azure和Google云平台中都可正常工作。 安装并启动Minikube 请按照官方文档来安装Minikube。在Minikube安装过程中,还将安装Kubectl。这是向Kubernetes API服务器发出请求的客户端。 执行命令minikube start来启动Minikube,完成后执行kubectl get nodes可获得如下输出: Minikube提供了一个只有一个节点的Kubernetes集群,但别忘了我们并不关心节点的数量,Kubernetes已经将其抽象掉了,并且这对学习Kubernetes并不重要。在下一节中,我们将从我们的第一个Kubernetes资源——Pod开始。 Pod 我喜欢容器,现在你也喜欢容器。那么为什么Kubernetes决定把Pod当作最小的可部署计算单元呢?Pod是做什么的?Pod可以由一个甚至是一组共享相同运行环境的容器组成。 有需要在一个Pod中运行两个容器么?一般会像本示例所做的这样,一个Pod中只运行一个容器。但是,如果两个容器需要共享数据卷,或者它们需要进行进程间通信,或者以其他方式紧密耦合,用Pod就能做到。另外一点,Pod可以让我们不受Docker容器的限制,如果需要的话,我们可以使用其他技术来实现,比如Rkt。 图14.Pod属性 总结来说,Pod的主要属性是(如图14所示): 1、每个Pod在Kubernetes集群中都有一个唯一的IP地址 2、Pod可以包含多个容器。这些容器共享形同的端口空间,因此它们可以通过localhost进行通信(由此可见,它们不能使用相同的端口),与其他Pod的容器进行通信必须使用其Pod的ip地址。 3、Pod中的容器共享相同的数据卷,相同的ip地址,端口空间,ipc命名空间。 容器拥有独立的文件系统,不过它们可以使用Kubernetes资源卷来共享数据。 对于我们来说这些信息已经足够了,如果你想了解更多,请查看官方文档。 Pod定义 以下是第一个Pod sa-front的清单(mainfest)文件,后面是对各个要点的解释。 apiVersion:v1 kind:pod #1 metadata: name:sa-frontend #2 spec: #3 containers: -image:rinormaloku/sentiment-analysis-frontend #4 name:sa-frontend #5 ports: -containerPort:80 #6 1、Kind指定我们想要创建的Kubernetes资源的种类。在这个例子中是Pod。 2、Name:定义资源的名称。我们将它命名为sa-frontend 3、Spec:是用于定义自愿的期望状态的对象。Pod Spec最重要的参数是容器的数组。 4、Image:是要在Pod中启动的容器镜像 5、Name:是Pod中容器的唯一名称。 6、ContainerPort:容器所要监听的端口。这只是面向读者的一个提示信息(删除该端口并不会限制访问)。 创建SA前端Pod 上述Pod定义在resource-manifests/sa-frontend-pod.yaml文件中。你可以在终端找那个定位其所在目录,或者在命令行中提供完整路径。然后执行以下命令: kubectl create pod -f sa-frontend-pod.yaml pod "sa-frontend" created 要检查Pod是否正在运行,请执行以下命令: 如果其状态扔是ContainerCreating,则可以使用--watch参数执行上述命令,以便在Pod处于Running状态时获得更新信息。 从外部访问应用程序 为了从外部访问应用程序,正常来说,我们需要创建一个service类型的Kubernetes资源(这是后文的内容),但为了快速调试,我们使用另一个方法,也就是端口转发: 在浏览器中打开127.0.0.1:88即可访问我们的React应用程序。 向上扩展的错误方法 我们说过Kubernetes的主要功能之一是可扩展性,为了说明这一点,我们来运行另一个Pod。为此,创建另一个Pod资源,其定义如下: 通过执行以下命令来创建新的Pod: 通过执行以下命令验证第二个Pod是否正在运行: 现在有两个Pod在运行了! 注意:这不是最终的解决方案,它的问题很多。我们将在Kubernetes的Deployment资源环节对此进行改进。 Pod总结 提供静态文件服务的Nginx Web服务器运行在两个不同的Pod中。现在有两个问题: 如何将其暴露给外界,以便通过URL进行访问? 如何在它们之间进行负载均衡? 图15.服务之间的负载均衡 Kubernetes为此提供了Service资源。我们在下一节对其进行说明。 Kubernetes实践----------Service Kubernetes的Service资源为提供相同功能服务的一组Pod充当入口。如图16所示,此类资源负责发现服务和负责平衡,任务繁重。 图16.Kubernetes Service维护着Ip地址 我们的Kubernetes集群是由多个具有不同功能性服务的Pod组成的(前端,SpringWeb App和Flask Python应用程序)。那么问题来了,Service如何知道要定位到哪些Pod?也就是说,他如何生成Pod的端点列表? 答案是,通过标签(Labels)来实现的,这是一个两步过程: 1、将标签应用于所有我们希望Service定位的Pod上 2、为我们的Service应用一个“筛选器(selector)”,以定义要定位哪个标记的Pod。 图17.带有标签的Pod及其清单 可以看到,Pod被打上了“app:sa-frontend”标签,而Service也是用同一标签来定位Pod。 标签 标签为组织Kubernetes资源提供了一种简单的方法。它们的表现形式为键值对,可以应用于所有资源。修改Pod的清单文件以匹配此前图17中所示的示例。完成修改后保存文件,并使用以下命令来应用: 这里出现了一个警告(apply与create的不同)。下一行可以看到“sa-frontend”和“sa-frontend2”Pod配置好了。我们可以通过过滤要显示的Pod来验证Pod是否已打上标签: 验证Pod被打上标签的另一种方法是在上述命令中附加--show-labels参数。这将显示每个Pod的所有标签。 好极了!我们的Pod都被打上标签了,接下来可以用我们的Service来定位它们了。下面开始定义如图18所示的LoadBalancer类型的Service。 图18.使用LoadBalancer Service实现负载均衡 Service定义 Loadbalancer Service的YAML定义如下所示: apiVersion:v1 kind:Service metadata: name:sa-frontend-lb spec: type:LoadBalancer ports: -port:80 protocol:TCP targetPort:80 selector: app:sa-frontend 1、Kind:一个Service 2、Type:规格类型,我们选择LoadBalancer是因为我们要实现Pod之间的负载均衡。 3、Port:指定Service接受请求的端口 4、Protocol:定义通信协议 5、TargetPort:请求转发的端口。 6、Selector:包含选择Pod的参数的对象。 7、app:sa-frontend定义了要定位的是打了“app:sa-frontend”标签的Pod。 请执行以下命令创建该Service: 可通过执行以下命令来检查Service的状态: 外部IP处于pending状态(不用等了,它不会变的)。这是因为我们使用的是Minikube。如果我们在Azure或GCP这样的云提供商中执行该操作,将获得一个公网IP,以便在全球范围内访问我们的服务。 尽管如此,我们不会因此受阻,Minikube为本地调试提供了一个有用的命令,执行以下命令: 这会在你的浏览器中打开Service的IP地址。在Service收到请求后,它会将其转发给其中一个Pod(哪一个无关紧要)。这种抽象让我们可以使用Service作为入口将多个Pod作为一个单元来看待和交互。 Service总结 本节我们介绍了标签资源,将它们用于Service的筛选器,同时我们定义并创建了一个LoadBalancer Service。这满足了我们扩展应用程序的需求(只需要添加新的打上标签的Pod)并使用Service作用入口实现Pod之间的负载均衡。 Kubernetes实践--------Deployment 应用程序时在不断变化的,Kubernetes的Deployment负责保证这些应用的一致。唯有那些死掉的应用程序才不会改变,否则新的需求会出现,更多的代码会被发布,打包并部署。在这个过程的每一步中,都可能犯错误。 Deployment资源可以自动迁移应用程序版本,实现零停机,并且可以在失败时快速回滚到前一个版本。 Deployment实践 目前,我们有两个Pod和一个用于暴露这两个Pod并在它们之间做负载均衡的Service。我们之前说过,单独部署这些Pod并非理想方案。它要求每个Pod进行单独管理(创建,更新,删除及监控其健康状况)。快速更新和回滚更是不可能!这是无法接受的,而Kubernetes的Deployment资源则解决了这些问题。 图19.当前状态 在继续之前,我说明我们想要实现的目标,因为这将为我们提供一个总览,让我们能够理解Deployment资源的清单定义。我们想要的是: 1、运行rinormaloku/sentiment-analysis-frontend镜像的两个Pod 2、零停机时间部署 3、为Pod打上app:sa-frontend标签,以便sa-frontend-lb Service能发现这些服务 Deployment定义 实现上述所有需求的YAML资源定义 apiVersion:extensions/v1beta1 kind:Deployment metadata: name:sa-frontend spec: replicas:2 minReadySeconds:15 strategy: type:RollingUpdate rollingUpdate: maxUnavailable:1 maxSurge:1 template: metadata: labels: app:sa-frontend sepc: containers: -image:rinormaloku/sentiment-analysis-frontend imagePullPolicy:Always name:sa-frontend ports: -containerPort:80 1、Kind:一个Deployment 2、Replicas是Deployment Spec对象的一个属性,用于定义我们需要运行几个Pod。这里是2个。 3、Type指定了这个Deployment在迁移版本时使用的策略。RollingUpdate策略将保证实现零宕机时间部署。 4、MaxUnavailable是RollingUpdate对象的一个属性,用于指定执行滚动更新时不可用的Pod的最大数(与预期状态相比)。我们的部署具有2个副本,这意味着在终止一个Pod后,仍然有一个Pod在运行,这样可以保持应用程序的可访问性。 5、MaxSurge是RollingUpdate对象的另一个属性,用于定义可以添加到部署中的最大Pod数量(与预期状态相比)。在我们的部署是,这意味着在迁移到新版本时,我们可以添加一个Pod,也就是同时是3个Pod。 6、Template:指定Deployment创建新Pod所用的Pod模版。你马上就发现它与Pod的定义相似。 7、app:sa-frontend是使用该模版创建出来的Pod所使用的标签。 8、ImagePullPolicy设置为Always表示,每次重新部署时都会拉取容器镜像。 老实说,即便是我也会被这堆文字弄糊涂,我们直接用这个示例入手: 跟之前一样,我们来验证一下一切是否正常: 现在运行了4个Pod,有两个是由Deployment部署的,另外两个是我们手动创建的。可使用命令 kubectl delete pod <Pod名 来删除手动创建的那两个。 练习:删除Deployment部署的一个Pod,看看会发生什么。并在阅读下面的解释之前思考一下原因。 说明:删除一个Pod后Deployment将发现当前状态(运行着1个Pod)与预期状态不同(运行着2个Pod),因此它会再启动一个Pod。 除了保证预期状态之外,Deployment还有什么好处?下面我们一一来看下它的优点: 优点#1:零停机时间滚动部署 产品经理提出了一项新的需求:客户希望在前端有一个绿色按钮。开发人员发布完代码,然后提供了我们唯一需要的东西,即容器镜像rinormaloku/sentiment-analysis-frontend:green。现在轮到我们了,作为DevOps,我们必须实现零停机时间部署,前面的努力值得么?让我们拭目以待! 编辑deploy-frontend-pods.yaml文件,修改容器镜像来引入新的镜像: rinormaloku/sentiment-analysis-frontend:green。保存并执行以下命令: 我们可以使用以下命令检查滚动部署的状态: 从输出可知,部署工作已经完成。它完成的方式是这样的,副本被逐一替换。这意味着应用程序始终处于运行状态。在继续之前,我们确认一下更新是否生效。 验证部署 在浏览器上查看更新的内容。执行与之前使用过的同一命令minikube service sa-frontend-lb打开浏览器,我们可以看到该按钮已更新。 图20. 绿色按钮 “滚动更新”的幕后 在应用新的Deployment后,Kubernetes会对新旧状态进行比较。在我们示例中,新状态请求两个使用rinormaloku/sentiment-analysis-frontend:green的Pod。这与当前运行状态不同,因此它会启用RollingUpdate 图21. RollingUpdate替换Pod RollingUpdate会根据我们制定的规则进行操作,即“maxUnavailable:1”和“maxSurge:1”。这意味着部署时只能终止一个Pod,并且只能启动一个新的Pod。该过程会不断重复直到所有的Pod都被更换(见图21) 接下来看看优点#2。 声明:下一部分以小说形式写成,仅供娱乐。 优点#2:回滚到之前的状态 产品经理跑进你的办公室,说他有大麻烦了! “生产环境的应用程序里有一个严重错误!立即恢复到前一个版本!”,产品经理大叫道。 你内心毫无波澜,眼睛眨都没眨一下。你切换到终端应用,输入: 你看了一眼上述Deployment,然后问产品经理:“最新版本有问题,而前一个版本工作正常?” “是的,你在听我说话吗?!”产品经理尖叫起来。 你无视他的存在,心里很清楚要做什么,然后开始输入: 当你刷新页面后,最近的修改被撤消了! 产品经理惊得下巴都掉到了地上。 你成了今天的英雄! 剧终! 没错……好无聊的小说。在Kubernetes出现之前,现实要精彩得多,更富戏剧性、强度也更高,持续的时间也更长。一段美好的旧时光! 大部分命令都是一目了然的,但有个细节需要你自己解读。为什么第一个版本的CHANGE-CAUSE是 如果你的答案是:我们在应用新镜像时使用了--record标示,那么恭喜你,回答正确! 在下一节中,我们将使用到目前为止学到的概念来完成整个架构。 Kubernetes和其他实践 我们已经学习了完成架构所需的全部资源,因此这部分会很快。在图22中,我们将所有仍然需要做的事情灰化了。让我们从最下面开始:部署sa-logic Deployment。 图22. 当前应用程序状态 部署SA-Logic 在终端中定位到resource-manifests目录并执行以下命令: SA-Logic Deployment创建了三个Pod(运行着Python应用程序容器),并给它们打上了app: sa-logic标签。该标签让我们能够使用SA-Logic Service中的筛选器来定位它们。请花点时间打开文件sa-logic-deployment.yaml查看其内容。 由于使用的概念相同,因此无需多言来看看下一项:Service SA-Logic。 Service SA-Logic 这里需要说明一下为什么我们需要这项Service。我们的Java应用程序(运行在SA-WebApp Deployment的Pod中)依赖于Python应用程序完成的情绪分析。但是,与之前全部在本地运行不同,现在我们不再是使用单一一个Python应用程序监听一个端口,而是两个甚至更多。 这就是为什么我们需要一个Service“作为提供相同功能服务的一组Pod的入口”。这意味着我们可以使用Service SA-Logic作为所有SA-Logic Pod的入口。 执行以下命令: 更新后的应用程序状态:我们运行了2个Pod(包含Python应用程序),并且有一个SA-Logic Service作为即将在SA-WebApp Pod中使用的入口。 图23. 更新后的应用程序状态 现在我们需要使用Deployment资源来部署SA-WebApp Pod。 部署SA-WebApp 我们对Deployment已经非常熟悉,不过此处还是有一个新功能。如果你打开sa-web-app-deployment.yaml文件,你会发现这部分是新的: - image:rinormaloku/sentiment-analysis-web-app imagePullPolicy:Always name:sa-web-app env: -name:SA_LOGIC_API_URL value:"http://sa-logic" ports: -containerPort:8080 我们感兴趣的是env属性是做什么的?我们推测它是在Pod中声明环境变量SA_LOGIC_API_URL的值为“http://sa-logic”。但为什么我们将它初始化为http://sa-logic,什么是sa-logic? 这里需要介绍一下kube-dns。 Kube-dns Kubernetes有一个特殊的Pod kube-dns。默认情况下,所有Pod都会将其作为DNS服务器。kube-dns一个重要特性是它会为每个新建的Service创建一条DNS记录。 这意味着当我们创建Service sa-logic时,它获得了一个IP地址。它的名字(与IP一起)会被添加到kube-dns记录中。这使得所有的Pod能够将sa-logic转换为SA-Logic Service的IP地址。 好的,我们继续: 部署SA-WebApp(续) 执行以下命令: 完成。剩下的是使用LoadBalancer Service对外暴露SA-WebApp Pod。以便让我们的React应用程序可以向作为SA-WebApp Pod入口的Service发送HTTP请求。 打开service-sa-web-app-lb.yaml文件,可以看到一切都很熟悉。 无须多想,执行以下命令: 整个架构完成了。不过还有一点没完善。在部署SA-Frontend Pod时,容器镜像将SA-WebApp指向了http://localhost:8080/sentiment。但是现在我们需要将其更新为指向SA-WebApp LoadBalancer(充当SA-WebApp Pod的入口)的IP地址。 解决这个问题让我们有机会再次快速地把从代码到部署的所有内容过一遍(如果你不是遵循以下指南,而是单独做这件事,可能会更有效)。让我们开始吧: 1、执行以下命令获取SA-WebApp Loadbalancer的IP地址: 2、如下所示,在sa-frontend/src/App.js文件中使用SA-WebApp Loadbalancer的IP地址: 3、运行npm build构建静态文件(需要定位到sa-frontend目录) 4、构建容器镜像: docker build -f Dockfile -t $DOCKER_USER_ID/sentiment-analysis-frontend:minikube 5、将镜像推送到Dokcer Hub: docker push $DOCKER_USER_ID/sentiment-analysis-frontend:minikube 6、编辑sa-frontend-deployment.yaml文件以使用新的镜像。 7、执行命令kubectl apply -f sa-frontend-deployment.yaml 刷新一下浏览器,或者再次执行minikube service sa-frontend-lb。现在输入一个句子试试! 文章总结 Kubernetes对团队和项目都非常有益,它简化了部署、可扩展性和弹性,让我们能够使用任意的底层基础设施。从现在开始,我要称它为Supernetes!你觉得如何? 我们在这个系列中介绍的内容: 构建/打包/运行ReactJS、Java和Python应用程序 Docker容器;如何使用Dockerfiles来定义和构建容器 容器Registry;我们使用Docker Hub作为容器的仓库 我们介绍了Kubernetes最重要的部分 Pod Service Deployment 一些新概念,比如零停机时间部署 创建可伸缩的应用程序 在这个过程中,我们将整个微服务应用程序迁移到Kubernetes集群上