【论文精读】MAKE-A-VIDEO:TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA
MAKE-A-VIDEO:TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA
-
- 数据集
- Abstract
- 1、Introduction
- 2、Method
-
- pipeline
- (1)Text-to-image Model
- (2)Spatiotemporal Layers
- (3)伪3D卷积层
- (4)伪3D注意力层
- (5)插帧网络
- (6)训练
- 总结
数据集
LAION数据集
训练图像模型2.3B data
训练视频模型10M
相当大。
Abstract
1.学习这个世界看起来是什么样的
符合文本-图像对的描述
2.学习这个世界是如何运动的
无监督视频序列
make video的三个好处:
①加速了训练过程,不需要从头开始训练视觉或多模态的表示.
②不要求成对的文本-视频数据
③继承了图像生成模型的vastness(广度)
基于T2I,使用一个新的时间空间模块,实现T2V。
1、首先,解码了U-NET和attention tensors。
2、第二,设计了时空的pipeline去生成一个高帧率高分辨率的视频
用一个视频解码器插值模型和两个超分模型。
创新点:
1、新颖的时间空间解码模块。
2、设计的空间时间的pipeline,插值模型和超分模型。
1、Introduction
基于无监督学习在无标记的视频数据上学习真实的运动
文本并不能完整描述视频的运动
Make a video可以对其进行推算,可以在无描述的情况下学习动作。

2、Method
pipeline
FPS 帧率
spatiotemporal decoder
输出一个16帧,64×64的图像组,给到后面的插帧网络
frame interpolation
插帧网络,对图像组进行插帧。
spatiotemporal Super-resolution 时间超分网络
spatial Super-resolution 空间超分网络
两层超分网络

(1)Text-to-image Model
DALLE-2
上方:text encoder→CLIP objective→img解码
下方:text encoder→prior网络(输出一个enbeddings(嵌入层))→decoder(生成图像)

(2)Spatiotemporal Layers
主要贡献
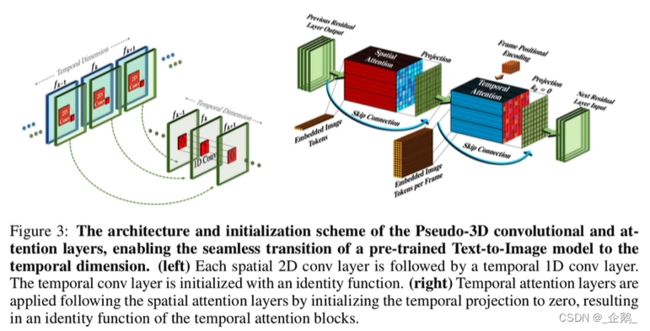
(3)伪3D卷积层
受可分离卷积的启发,在原来的2D卷积上,在时间维度扩展了1D的卷积,让信息能在时间维度做共享。权重由前面训完初始化过来的。模型在一开始可能产生不同的图像,因为缺少时间上的约束。但是在后续在时间上,会具有一致性。
代码解析:
定义一个2D的卷积
定义一个1D的卷积
用dirac初识它
temporal的卷积层变成identity function
空间卷积,每帧都是独立的,所以【BF,C,H,W】
时间卷积是ID的卷积在不同的帧上,所以把帧f放在最后一堆,CHW放到Batch上
(4)伪3D注意力层
将空间上的attention扩展到了时间维度。
代码解析:
以前是HW上做attenrion,现在在f上加了一层attention
实现在时间上做信息交互。
attention函数:
初始化空间上的attetion
初始化时间上的attention
进入维度的tensor
将空间维度展开。
为什么用伪?这样参数量小。3D参数量太大了。
在VDM和CogVideo上都有。
Frame rate conditioning(帧速率调节)
损失函数:混合模型 hybrid loss
MSE+KLD
(5)插帧网络
输入到unit里,不再是三个channel,而是四个channel。然后多了一个binary channel去判断该帧是否是被mask的。
中间插帧的帧数是可变的。
(6)训练
上方的每一个部分都是单独训练的。
prior网络只接受输入,只在文本-图像对上训练,类似于DALLE-2的训练方式
decoder网络和超分网络,首先在图像上做训练,不需要文本。需要注意的是,这个解码器接收CLIP decoder解码器作为输入。用CLIP magen enbedding做输入。
在原模型训练好后,我们需要扩充temporal的维度。扩展完后,我们需要在未标记的video上做fine-turn。我们需要做16张从原始数据上的采样。训完后再训插帧网络。
总结
DELL-2
D:decoder,不考虑时间。
Dt与时间有关系,扩展为时间维度上。
16帧:原始视频随机帧率16帧。
插帧网络:Dt训练完后,用Dt fine-turn插帧网络。