oracle 混合分区表,手把手教你19c新特性:混合分区表
![]()
今天向大家介绍19c新特性:混合分区表。简单来讲,可以认为是将之前的分区表和外部表结合起来,当然混合分区表的功能不只这些。更多详细信息,大家可以点击下方“阅读原文”了解详细内容。一般情况下,我们使用分区表,是将各个分区对应不同的表空间,各个表空间可以对应不同位置、不同种类的存储,但一般都为常规文件系统。而19c当中的混合分区表,在建表的时候,直接可以使用外部表属性,将“冷”数据直接定位在廉价存储、HDFS或者公有云存储上。
在今天的例子中,我们创建一个混合分区表,将2019年的数据放在数据库内,将2019年之前的数据放在公有云当中(Oracle对象存储)。并且在文章后面,给大家留了作业,先向大家说明如何搭建Hadoop环境,然后请大家将文件放在HDFS当中创建混合分区表。

我们创建两个文本文件,用来作为混合分区表的外部数据源,并且将这两个文本文件上传到Oracle公有云当中的对象存储,如下图所示:

然后我们在Linux当中将Oracle对象存储挂载进来,在Linux当中的oracle用户下用/u01/txt与Oracle公有云OCI中的Bucket对应。

我们可以通过cat命令查看这两个文件中的内容,我们可以看到2017年和2018年分别有2条记录。

然后我们进入SQL Plus,创建一个用户叫做henry,并且来到orclpdb1这个PDB。

因为一会儿我们创建的混合分区表包含外部表部分,所以我们先创建一个目录对象,指向OCI公有云对象存储在本系统中的挂载点/u01/txt。
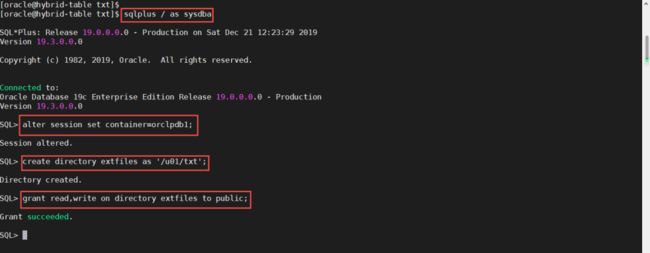
因为建表的脚本有点长,我将它写入一个SQL文件,这样方便大家查看。大家观察下面的创建表语句,在定义分区的部分,如果使用external location就表示这是外部分区。分区表创建之后,我们可以通过select语句进行查询,我们会发现刚才在文件系统中看到的4条记录,都出现在结果当中了。
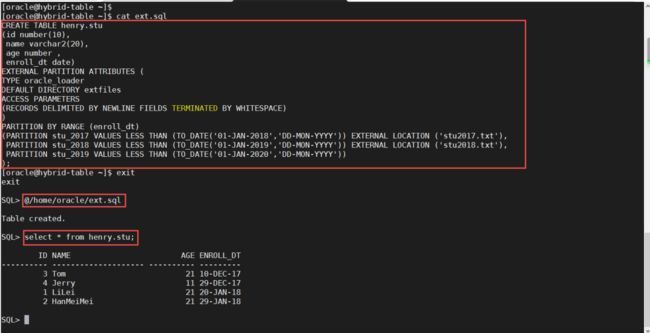
与以前版本的外部表不同,以前版本的外部表都是以查询为目的,不会对里面的数据进行更改,而在19c的混合分区表中,可以对其中的数据进行更改,这种更改包括插入、更新和删除。我们现在向“数据库内分区”插入数据看看。2019年这个分区是数据库内的分区。
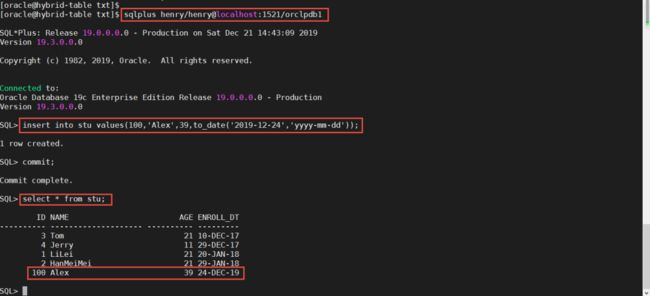
接下来,我们向外部分区插入数据看看。2017年和2018年的数据是被定义在外部分区上,我们对这个分区插入数据,大家会看到如下结果。

如果您没有公有云环境,您完全可以将本地文件系统作为您的外部数据文件存储位置,或者像本节作业中描述的,您创建一个Hadoop环境,将HDFS作为外部数据文件的存储位置。

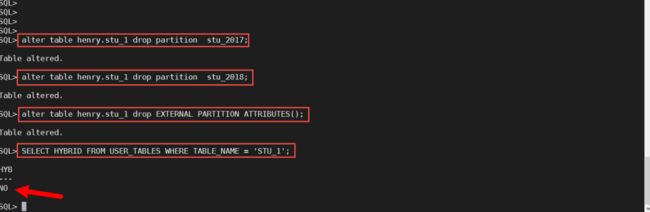
当不想使用混合分区表时,只要将他的外部分区都删除,然后再删除它的外部分区属性,那么就可以将混合分区表转换为普通分区表了。在下面的实验中,我们先创建一个混合分区表,然后看看它的属性,接下来将它的所有外部分区都删除,再删除它的外部分区属性,之后再看看这个表的属性。
第一步:创建一个混合分区表
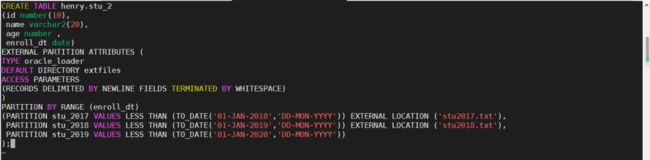
我们先创建一个带有5个分区的混合分区表,前两个分区是外部分区,后三个分区是普通数据库内分区。
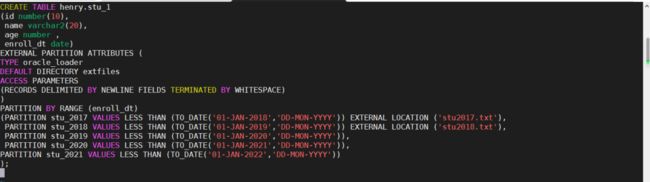
第二步:看看这个表的分区属性
通过查询,我们发现,刚创建的stu_1是一个混合分区表。

第三步:删除所有外部分区,并删除分区属性
在我们的例子中,stu_1有两个外部分区,我们先将这两个外部分区都删除,然后在删除这个表的外部分区属性。这时候查看表的混合分区属性时,就会得到下图中的“NO”,表示这个表已经不是一个混合分区表了。

Automatic Data Optimization (ADO),自动数据优化策略。在之前版本的数据库中就向大家提供了,我们可以设定策略,比如对于很久不访问的数据进行压缩。在19c的混合分区表中,也可以使用这项技术,但仅限于数据库内的分区。我们在下面的例子中,为2019这个数据库内分区设定数据压缩策略,对那些6个月没有修改的数据进行压缩。
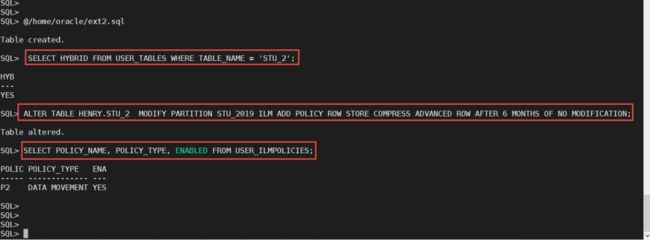
关于ADO的更多信息,大家可以参考:https://docs.oracle.com/en/database/oracle/oracle-database/19/vldbg/ilm-strategy-heatmap-ado.html#GUID-59C132D6-D36B-4B5E-B0CA-948C1B0E6836

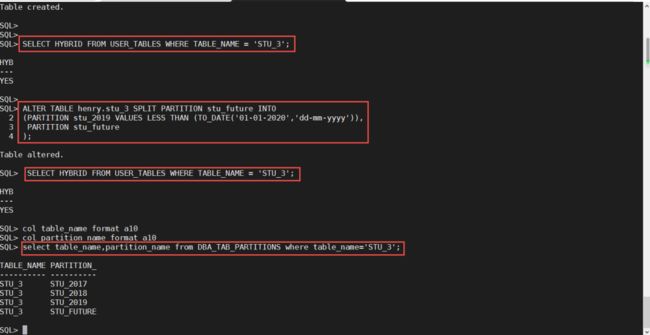
在混合分区表当中,我们可以像之前版本的数据库一样,对于默认分区进行拆分。比如下面的例子当中,2018年之后的数据都将进入默认分区stu_future。我们现在对这个分区进行拆分,拆分成2019分区和stu_future,stu_future将继续作为默认分区。
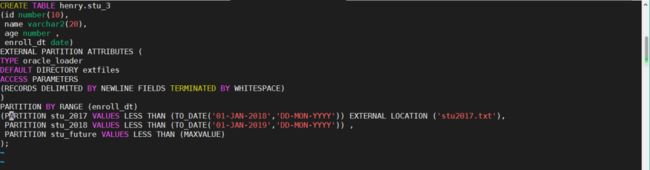
我们在创建stu_3之后,查询一下它的混合分区属性,发现他是混合分区表。然后我们将它的默认分区拆分成2019分区和stu_future分区,将2019年之后的数据都放入默认分区stu_future。我们再次查询这个表的混合分区属性,发现它还是混合分区表,最后看看这个混合分区表的分区信息,我们发现新添加的2019分区已经显示出来了。
讲到这里,混合分区表的简单功能就为大家介绍完了,如果想了解更多信息,请点击下方的“阅读全文”获取更多资讯。

在上面的例子中,我们将外部数据放在Oracle公有云中的对象存储当中,如果您没有公有云环境,您可以将外部数据放在本地文件系统或者放在HDFS当中,下面就为大家展示如何安装Hadoop2.10.0,本次使用的是和数据库同一台机器,创建只有一个节点的Hadoop集群。
这里只告诉大家如何创建Hadoop环境,如何将外部数据文件放在HDFS当中,并创建混合分区表,那就是留给大家的作业了。

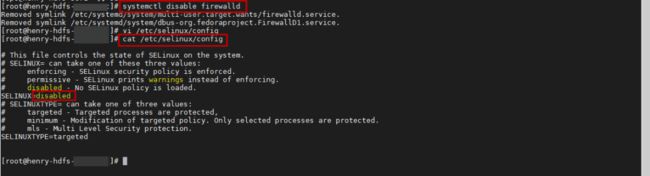
第一步:关闭防火墙及disable selinux然后重启操作系统,使用reboot命令
第二步:创建用于存储数据的路径,并设定访问权限

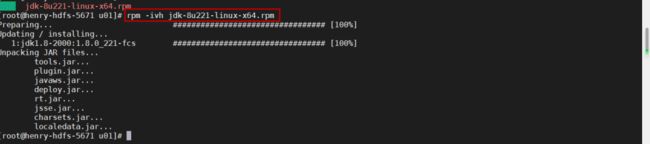
第三步:下载并安装JDK
如果您的操作系统没有安装JDK,或者JDK版本与Hadoop 2.10.0不兼容,您可以卸载之前的JDK,然后安装JDK8u221。JDK可以来到下方地址进行下载。
https://www.oracle.com/java/technologies/jdk8-downloads.html

下载之后,使用root用户安装即可。
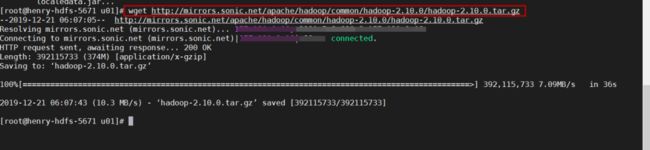
第四步:下载hadoop2.10.0并安装
您可以来到Apache的官网进行下载,具体文件地址如下:
http://mirrors.sonic.net/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
第五步:解压文件
![]()
第六步:修改配置文件
有4个配置文件要修改,它们在Hadoop解压路径下,比如我的文件位置是/u01/hadoop-2.10.0/etc/hadoop
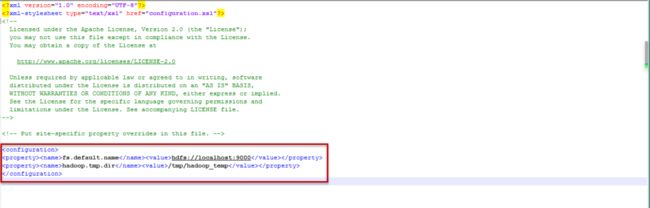
core-site.xml
这个文件主要设置服务访问地址和临时文件夹
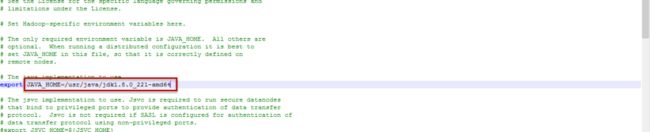
hadoop-env.sh
这个文件主要设置JDK的位置
hdfs-site.xml
这个文件主要设置HDFS对应的本地存储路径,请确保这个路径是空的,不然后面格式化和启动时会出错,遇到错误也别怕,将这个路径中的内容删除,并重启服务即可。在这个文件中也设定了文件的备份系数,目前我们保持为1.

mapred-site.xml
这个文件主要设置job tracker地址。

第七步:设定路径访问权限
我们在上面的设置中,将/u01/hdfs作为本地存储位置,为了能让oracle用户对应的数据库可以访问hdfs,我们干脆将这个路径的所有者设定为oracle。
![]()
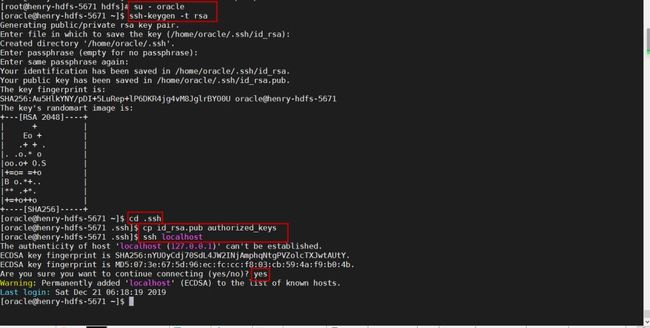
第八步:设定免密登录
第九步:格式化namenode

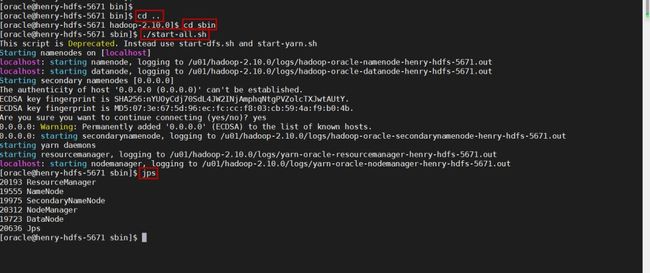
第十步:启动hadoop并查看状态
注意脚本的位置,不是在bin中,而是在sbin当中。当启动脚本执行完毕,使用jps命令查看一下各个服务的状态,如果没问题,应该出现和下图一样的服务进程。如果出现datanode没有启动,可以尝试重新format namenode,然后再次重启服务。Hadoop在安装和使用的时候,可能会遇到比较多的问题,所以请细心操作,遇到问题可以在网路上搜寻,一般都会找到满意的答案。
第十一步:放一个文件测试一下
为了方便操作,修改一下环境变量,将hadoop的bin放入其中
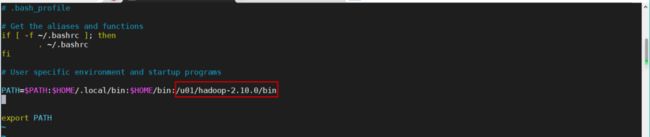
我们创建一个文件叫做hello.txt传入HDFS,然后在HDFS当中查看文件内容。
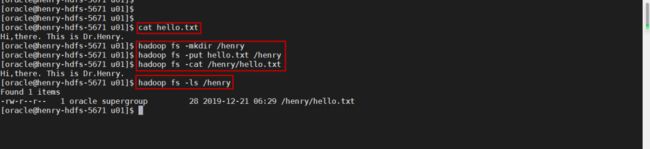
HDFS的环境就为大家准备好了,请大家将数据文件放入HDFS,然后创建混合分区表吧。
今天的内容就到这里,感谢您的点阅,谢谢。您可以点击下方的“阅读原文”,查询官方文档,获取更多讯息。
手把手系列文章:
扫描下方QR Code即刻预约ADW演示
编辑:殷海英