Node.js 工作线程与子进程:应该使用哪一个
Node.js 工作线程与子进程:应该使用哪一个
并行处理在计算密集型应用程序中起着至关重要的作用。例如,考虑一个确定给定数字是否为素数的应用程序。如果我们熟悉素数,我们就会知道必须从 1 遍历到该数的平方根才能确定它是否是素数,而这通常非常耗时且计算量极大。
因此,如果我们在 Node.js 上构建此类计算量大的应用程序,我们可能会阻塞正在运行的线程很长时间。由于 Node.js 的单线程特性,不涉及 I/O 的计算密集型操作将导致应用程序停止,直到该任务完成。
因此,在构建需要执行此类任务的软件时,我们不会使用 Node.js。但是,Node.js 引入了工作线程 和子进程的概念 来帮助在 Node.js 应用程序中进行并行处理,以便我们可以并行执行特定进程。在本文中,我们将了解这两个概念并讨论何时使用它们。
Node.js 中的工作线程是什么
Node.js 能够有效地处理 I/O 操作。然而,当它遇到任何计算量大的操作时,它会导致主事件循环冻结。
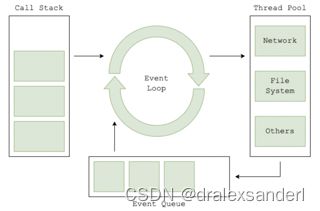
当 Node.js 发现异步操作时,它将其“离岸”到线程池。但是,当它需要运行计算量大的操作时,它会在其主线程上执行该操作,这会导致应用程序阻塞,直到操作完成。因此,为了缓解这个问题,Node.js 引入了工作线程的概念,以帮助从主事件循环中卸载 CPU 密集型操作,以便开发人员可以以非阻塞方式并行生成多个线程。
它通过启动一个隔离的 Node.js 上下文来实现此目的,该上下文包含自己的 Node.js 运行时、事件循环和事件队列,该上下文在远程 V8 环境中运行。这在与主事件循环断开连接的环境中执行,从而允许主事件循环释放。

如上所示,Node.js 创建独立的运行时作为工作线程,其中每个线程独立于其他线程执行,并通过消息通道将其进程状态传达给父线程。这允许父线程继续照常执行其功能(不会被阻塞)。通过这样做,我们可以在 Node.js 中实现多线程。
在 Node.js 中使用工作线程有什么好处
正如我们所看到的,使用工作线程对于 CPU 密集型应用程序非常有益。事实上,它有几个优点:
- 性能改进:我们可以将计算繁重的操作转移到工作线程,这可以释放主线程,从而使我们的应用程序能够响应更多请求。
- 提高并行性:如果我们有一个大型进程,希望将其分成子任务并并行执行,则可以使用工作线程来执行此操作。例如,如果我们要确定 1,999,3241,123 是否为质数,则可以使用工作线程检查范围内的除数 -(WT1 中为 1 到 100,000,WT2 中为 100,001 到 200,000,等等)。这将加快我们的算法并导致更快的响应。
什么时候应该在 Node.js 中使用工作线程
如果我们考虑一下,我们应该只使用工作线程来运行与父线程隔离的计算密集型操作。
在工作线程中运行 I/O 操作是没有意义的,因为它们已经被转移到事件循环中。因此,当我们需要在隔离环境中执行计算量大的操作时,请考虑使用工作线程。
如何在 Node.js 中构建工作线程
如果所有这些听起来对我们很有吸引力,那么让我们看看如何在 Node.js 中实现工作线程。考虑下面的代码片段:
const {
Worker,
isMainThread,
parentPort,
workerData,
} = require("worker_threads");
const { generatePrimes } = require("./prime");
const threads = new Set();
const number = 999999;
const breakIntoParts = (number, threadCount = 1) => {
const parts = [];
const chunkSize = Math.ceil(number / threadCount);
for (let i = 0; i < number; i += chunkSize) {
const end = Math.min(i + chunkSize, number);
parts.push({ start: i, end });
}
return parts;
};
if (isMainThread) {
const parts = breakIntoParts(number, 5);
parts.forEach((part) => {
threads.add(
new Worker(__filename, {
workerData: {
start: part.start,
end: part.end,
},
})
);
});
threads.forEach((thread) => {
thread.on("error", (err) => {
throw err;
});
thread.on("exit", () => {
threads.delete(thread);
console.log(`Thread exiting, ${threads.size} running...`);
});
thread.on("message", (msg) => {
console.log(msg);
});
});
} else {
const primes = generatePrimes(workerData.start, workerData.end);
parentPort.postMessage(
`Primes from - ${workerData.start} to ${workerData.end}: ${primes}`
);
}
上面的代码片段展示了一个可以利用工作线程的理想场景。要构建工作线程,我们需要从库中导入Worker、IsMainThread、parentPort和 workerDataworker_threads 。这些定义将用于创建工作线程。
上面的代码创建了一种算法,可以查找给定范围内的所有素数。它将主线程中的范围分成不同的部分(上面示例中的五个部分),然后使用 new Worker() 来创建一个工作线程来处理每个部分。工作线程执行 else块,该块在分配给该工作线程的范围内查找素数,并最终使用 parentPort.postMessage() 将结果发送回父(主)线程。
Node.js 中的子进程是什么
子进程与工作线程不同。虽然工作线程在同一进程中提供隔离的事件循环和 V8 运行时,但子进程是整个 Node.js 运行时的单独实例。每个子进程都有自己的内存空间,并通过消息流或管道(或文件、数据库、TCP/UDP 等)等 IPC(进程间通信)技术与主进程进行通信。
在 Node.js 中使用子进程有什么好处
在 Node.js 应用程序中使用子进程会带来很多好处:
- 改进的隔离性:每个子进程都在自己的内存空间中运行,提供与主进程的隔离。这对于可能存在资源冲突或需要分离的依赖性的任务是有利的。
- 提高可扩展性:子进程在多个进程之间分配任务,这使我们可以利用多核系统并处理更多并发请求。
- 提高鲁棒性:如果子进程由于某种原因崩溃,它不会随之崩溃我们的主进程。
- 运行外部程序:子进程允许我们将外部程序或脚本作为单独的进程运行。这对于需要与其他可执行文件交互的场景非常有用。
什么时候应该在 Node.js 中使用子进程
所以,现在我们知道子进程给图片带来的好处了。了解何时应该在 Node.js 中使用子进程非常重要。根据我的经验,当我们想在 Node.js 中执行外部程序时,我建议我们使用子进程。
比如存在一种使用场景:我们必须从 Node.js 服务中运行外部可执行文件。不可能在主线程内执行二进制文件。因此,我们必须使用一个子进程来执行二进制文件。
如何在 Node.js 中构建子进程
在 Node.js 中创建子进程的方法有多种,可以使用 spawn() 、fork()、exec() 与 execFile() 等方法。
const { spawn } = require('child_process');
const child = spawn('node', ['child.js']);
child.stdout.on('data', (data) => {
console.log(`Child process stdout: ${data}`);
});
child.on('close', (code) => {
console.log(`Child process exited with code ${code}`);
});
我们所要做的就是从child_process模块导入一个 spawn() 方法,然后通过传递 CLI 参数作为参数来调用该方法。
如何在工作线程和子进程之间进行选择
现在我们知道什么是子进程和工作线程,那么了解何时使用这些技术很重要。它们都不是适合所有情况的灵丹妙药。这两种方法都适用于特定条件。
在以下情况下使用工作线程:
- 我们正在运行 CPU 密集型任务。如果我们的任务是 CPU 密集型的,那么工作线程是一个不错的选择。
- 我们的任务需要线程之间的共享内存和高效通信。工作线程具有对共享内存和用于通信的消息系统的内置支持。
在以下情况下使用子进程:
- 我们正在运行需要隔离并独立运行的任务,特别是当它们涉及外部程序或脚本时。每个子进程都在自己的内存空间中运行。
- 我们需要使用 IPC 机制(例如标准输入/输出流、消息传递或事件)在进程之间进行通信。子进程非常适合此目的。
总结
并行处理正在成为现代系统设计的一个重要方面,特别是在构建处理非常大的数据集或计算密集型任务的应用程序时。因此,在使用 Node.js 构建此类应用程序时,考虑工作线程和子进程非常重要。
如果我们的系统没有采用正确的并行处理技术进行正确设计,我们的系统可能会因过度耗尽资源而表现不佳(因为生成这些资源也会消耗大量资源)。
因此,对于软件工程师和架构师来说,清楚地验证需求并根据本文中提供的信息选择正确的工具非常重要。