Ubuntu系统使用快速入门实践(六)——Ubuntu深度学习环境配置(2)
Ubuntu系统使用快速入门实践系列文章
下面是Ubuntu系统使用系列文章的总链接,本人发表这个系列的文章链接均收录于此
Ubuntu系统使用快速入门实践系列文章总链接
下面是专栏地址:
Ubuntu系统使用快速入门实践系列文章专栏
文章目录
- Ubuntu系统使用快速入门实践系列文章
-
- Ubuntu系统使用快速入门实践系列文章总链接
- Ubuntu系统使用快速入门实践系列文章专栏
- 前言
- Ubuntu系统使用快速入门实践(六)——Ubuntu深度学习环境配置(2)
-
- 3.安装CUDA
-
- 3.1 简介
- 3.2 注意
- 3.3 安装流程
-
- 报错
- 3.4 配置环境变量
- 3.5 更新环境变量
- 3.6 验证安装
- 注意
-
- 关于nvcc -V与nvidia-smi命令显示的CUDA版本不一致问题。
- 三个库间的依赖关系
- 4.安装cuDNN
-
- 4.1 简介
- 4.2 安装流程
- 4.3 下载安装包
- 4.4 执行安装命令
-
- 4.4.1 进入对应安装文件夹
- 4.4.2 解压
- 4.4.3 复制文件 + 权限修改
- 4.5 测试安装
- 5.安装深度学习框架Pytorch
-
- **ERROR**
- 卸载
- 补充
- 训练报错
-
- GLIBCXX_3.4.29 not found
-
- 方法一
- 方法二
- symbol lookup error
前言
Ubuntu是一个以桌面应用为主的Linux发行版操作系统,也是大多数人第一个接触到的Linux系统,尤其是从事理工科研究工作的人,这个系列的文章主要讲述如何使用Ubuntu系统,完成日常的学习、科研以及工作
Ubuntu系统使用快速入门实践(六)——Ubuntu深度学习环境配置(2)
3.安装CUDA
3.1 简介
CUDA,全称ComputeUnified Device Architecture,是一种NVIDIA推出的通用的计算架构,该架构能够使GPU解决复杂的计算问题。
3.2 注意
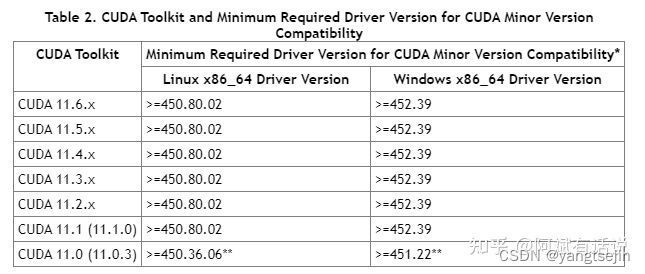
安装CUDA前一定记得在官网查看一下驱动支持的CUDA版本!
这里贴一张CUDA 11的相关表:
3.3 安装流程
进入CUDA官网,选择对应的安装平台,安装类型选择runfile,参考如下:
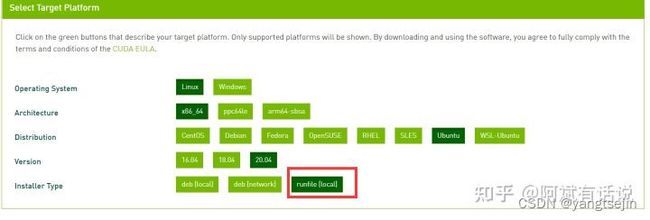
信息确认后会提示安装指令。(wget会默认下载到当前目录)
在安装CUDA时,一定要先考虑Pytorch需要的CUDA版本,一般为 10.2 和 11.3
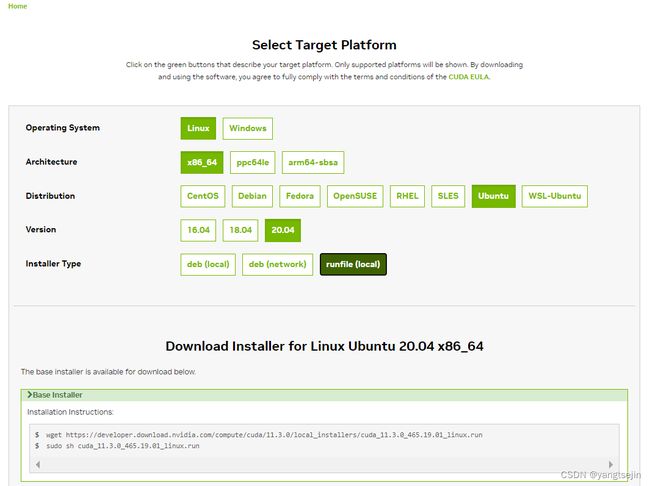
wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
sudo sh cuda_11.3.0_465.19.01_linux.run
安装时一直选择yes,
安装块完成时后,在 NVIDIA Accelerated Graphics Driver 时选择否,没必要再安装英伟达驱动
报错
**Error:**执行安装脚本以后可能会提示系统有多个驱动需要移除,提示如下:

选择Continue,然后输入 accept
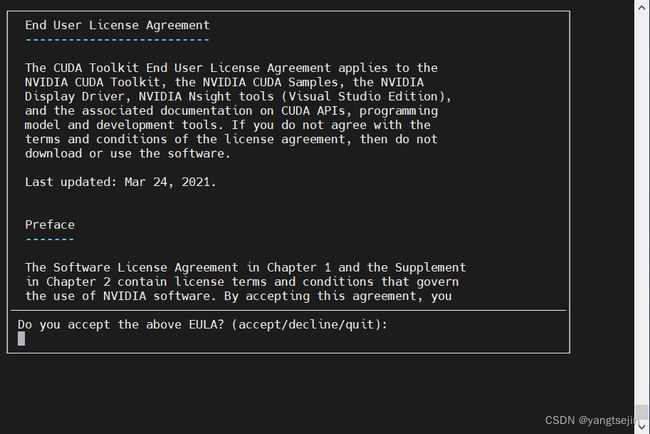
按空格取消勾选第一个Driver,然后Install
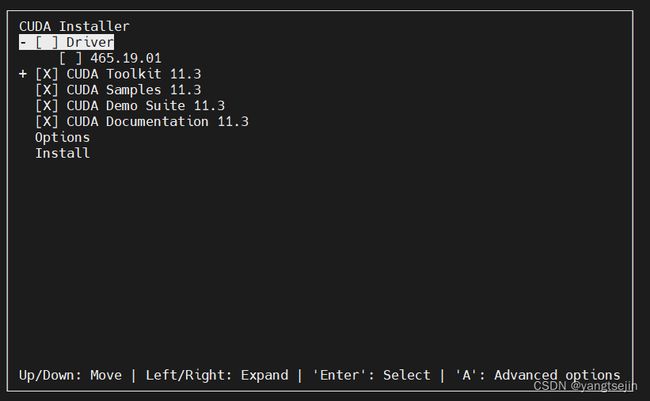
执行
sudo apt install nvidia-cuda-toolkit
安装CUDA工具包
Test:
nvcc -V
实际上,执行该命令出现CUDA的release以及version就证明runtime API cuda安装完毕
但这不一定就是最终的版本,因为CUDA与cuDNN之间存在依赖关系!
3.4 配置环境变量
如果能够成功执行脚本,安装CUDA驱动,那么就需要手动配置环境变量,参考如下:
法一
终端输入以下指令:
# 需指定CUDA加速版本,如cuda-11.3
export PATH="/usr/local/cuda-xxx/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-xxx/lib64:$LD_LIBRARY_PATH"
法二
执行以下指令,然后在UI界面添加法一中的两条指令。
sudo gedit ~/.bashrc
# 需指定CUDA加速版本,如cuda-11.3
export PATH="/usr/local/cuda-11.3/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH"
该方法与法一并无本质区别
注意:
如果存在第一次安装成功,重启后使用命令nvcc -V 又不起作用的情况,那么多半是环境变量的设置问题
3.5 更新环境变量
source ~/.bashrc
3.6 验证安装
nvcc -V
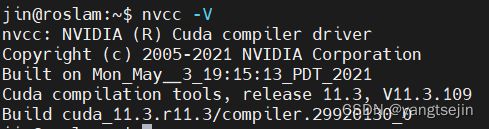
注意
关于nvcc -V与nvidia-smi命令显示的CUDA版本不一致问题。
由于cuda存在runtime API 与 nvidia drive API两个版本,前者是CUDA Toolkit安装的,称之为CUDA加速版本;而后者是Nvidia driver安装的,成为CUDA驱动版本,因此通常情况下,两者的版本不一致,前者版本都会低于后者。但在实际使用中,cuda版本是基于前者的,也就是runtime CUDA,这个CUDA才是用于深度学习的加速计算的。
三个库间的依赖关系
这里需要说明一下,我们不仅要注意 CUDA与nvidia driver 的关系,
还需要注意 cuDNN与CUDA以及Pytorch与CUDA的依赖关系,这三个库的版本要相互匹配才能正常使用!!
4.安装cuDNN
4.1 简介
cuDNN是一个用于深度神经网络DNN的GPU加速库,可以在GPU上实现并行计算,显著提高性能。
4.2 安装流程
进入cuDNN官网。
需要注册登录才能下载
4.3 下载安装包
选择和系统CUDA匹配的cuDNN版本。
由于本次配置CUDA 为10.3,因此安装11.x系列的cuDNN.
这里选择for Linux.

选择 Local Installer for Linux x86_64 (Tar)
4.4 执行安装命令
4.4.1 进入对应安装文件夹
cd ....
4.4.2 解压
tar -zxvf cudnn-11.1-linux-x64-v8.0.5.39.tgz
4.4.3 复制文件 + 权限修改
解压后进入文件夹,有include和lib64两个文件夹
cd cuda
sudo cp ./include/cudnn*.h /usr/local/cuda-11.3/include
sudo cp -P ./lib64/libcudnn* /usr/local/cuda-11.3/lib64
sudo chmod a+r /usr/local/cuda-11.3/include/cudnn*.h /usr/local/cuda-11.3/lib64/libcudnn*
官网安装教程在这里。
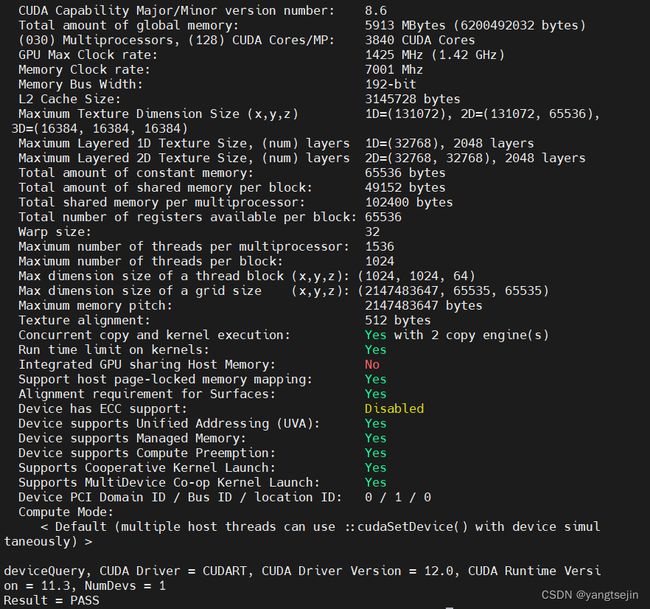
4.5 测试安装
cd /usr/local/cuda/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
最后出现Result = PASS,即表示安装成功,如下图所示
5.安装深度学习框架Pytorch
如想要Ubuntu下的Pycharm也可以使用Anaconda虚拟环境
参考:
Ubuntu 系统Pycharm 使用 Anaconda的python环境
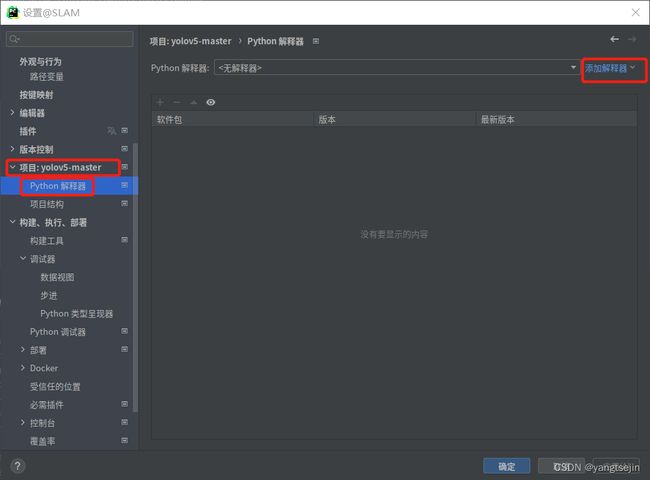
点击Ubuntu下的Pycharm中的文件,然后选择设置
点击项目下的Python解释器,点击添加解释器,本地解释器
File->settings->project:()->Project Interpreter
选择Conda环境,设置虚拟环境的位置,选择Python版本(一般情况默认即可)
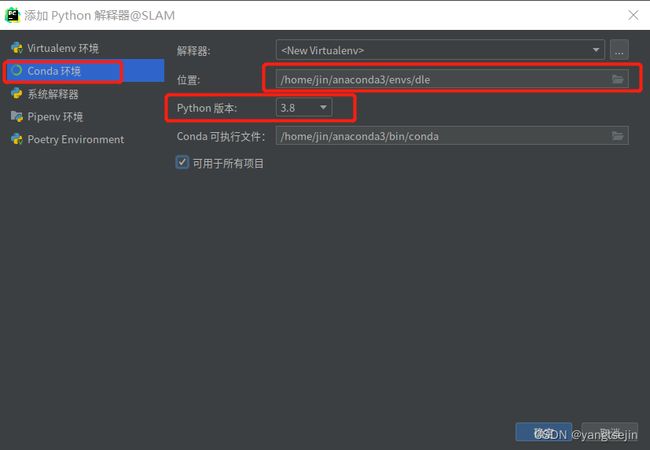
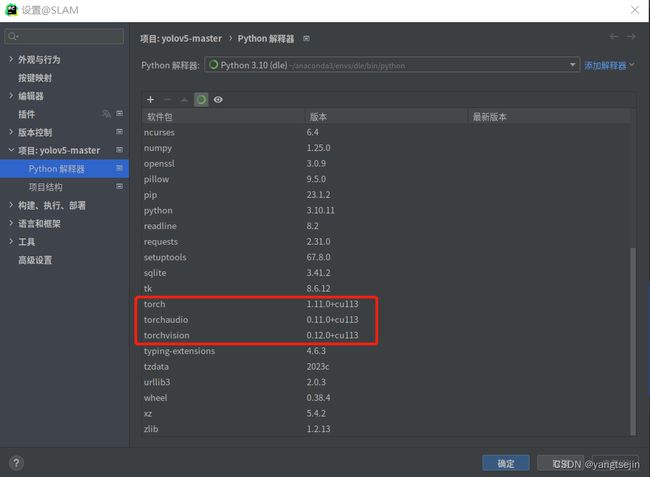
打开终端,进入刚创建的conda环境,再进行Pytorch的安装
注意:pytorch要在CUDA之后再安装,否则识别不到CUDA
进入官网,选择相关属性,参考如下:

然后切换到虚拟环境(注意这里安装一定要安装到conda的虚拟环境下面),执行安装命令即可,参考如下:
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
# 我这里的CUDA版本为11.3,使用下面的命令
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113
pip换源参考:Ubuntu系统使用快速入门实践(二)——Ubuntu常用命令 中pip换源一节

注意:
使用conda命令安装可能会出现只安装CPU版本的Pytorch的问题,最好使用pip命令安装,安装的一定是GPU版本的Pytorch
测试安装,检查是否支持GPU驱动
输入命令
python
>>> import torch
>>> torch.cuda.is_available()
# Use exit() or Ctrl-D (i.e. EOF) to exit
>>> exit()
得到结果 True

这就表示安装成功
这时打开Pycharm即可看到安装好的torch
ERROR
UserWarning: CUDA initialization: CUDA unknown error…
当然,出现这个错误时,验证gpu版本的命令也会出现false,别担心~~
首先我们利用以下命令查看pytorch支持的CUDA版本:
torch.version.cuda
如果和你的CUDA版本不匹配的话,那就得重新下CUDA或PyTorch~~
如果版本一致,那执行以下命令即可:
sudo apt-get install nvidia-modprobe
卸载
若要卸载Pytorch,则输入下面的命令
pip uninstall torch
pip3 uninstall torchvision
补充
若出现莫名的报错,可尝试将训练集和验证集所在文件夹的.cache文件删除,重新开始训练
训练报错
GLIBCXX_3.4.29 not found
参考:
ImportError: /lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.29’ not found
轻松解决报错:/lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.29‘ not found
无root权限解决ImportError: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.29‘ not found问题
训练YOLOv5时出现下面的报错
ImportError: /lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.29' not found (required by /home/jin/anaconda3/lib/python3.10/site-packages/matplotlib/_path.cpython-310-x86_64-linux-gnu.so)

解决办法:
方法一
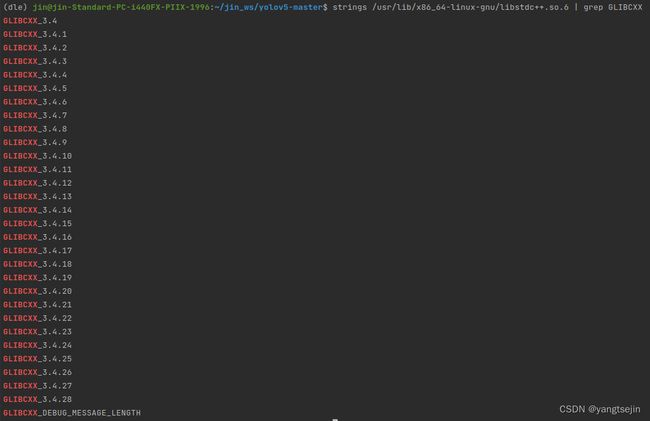
第一步:使用如下命令查看是否缺失文件(一般来讲肯定是缺失的)
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX
结果如下
第二步:使用如下命令查看当前系统中是否有其他同类型的文件,找一个版本较高的。
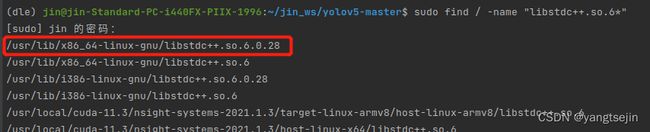
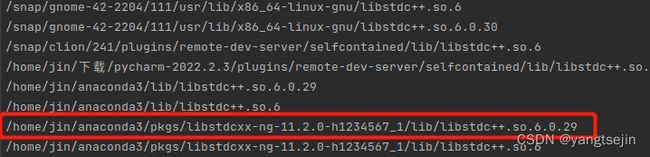
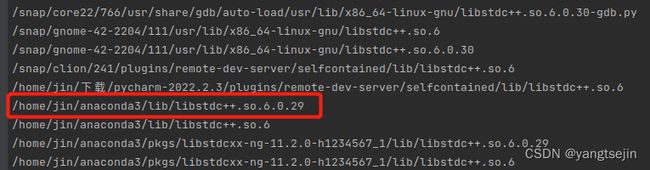
sudo find / -name "libstdc++.so.6*"
(注意这个命令需要权限,我就直接退出我的账号进入管理员账户弄了)
如图,可以看到有更高版本的同类型文件
指定加载库的路径
根据我们上面找到的路径,我们直接在终端中修改指定加载库的路径:
nano ~/.bashrc
# 添加下面的代码
export LD_LIBRARY_PATH=
"/home/jin/anaconda3/lib:$LD_LIBRARY_PATH"
# 或者使用命令
echo 'export LD_LIBRARY_PATH="/home/jin/anaconda3/lib:$LD_LIBRARY_PATH"' >>~/.bashrc
注意:引号里面再加引号时,应该单引号里面套双引号
添加后记得更新
source ~/.bashrc
方法二
第一步,点此链接下载(明确文件路径):下载
第二步,移除现有软连接
sudo rm /usr/lib/x86_64-linux-gnu/libstdc++.so.6
第三步,cd到下载路径下再执行
sudo mv libstdc++.so.6.0.29 /usr/lib/x86_64-linux-gnu/
第四步,重新建立软连接
sudo ln -s /usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.29 /usr/lib/x86_64-linux-gnu/libstdc++.so.6
这个方法我试完了好像并不成功
symbol lookup error
参考:
Can’t launch VS Code from Linux terminal: symbol lookup error #51937
解决完上面的GLIBCXX_3.4.29的错误后,打开vscode时又出现下面的symbol lookup error

/usr/share/code/bin/../code: symbol lookup error: /lib/x86_64-linux-gnu/libwayland-client.so.0: undefined symbol: ffi_type_uint32, version LIBFFI_BASE_7.0
解决办法:
将vscode卸载,然后再重新安装即可正常使用