JAVA-暑假笔记(源自尚硅谷Java教程)
命令行指令
使用WIN+R键显示页面,然后输入 cmd 进入控制台。
基础指令:
Dir : 列出当前目录下的文件及文件夹。 directory
Md : 创建目录 make directory
Rd : 删除目录 remove directory
Cd : 进入指定目录 come directory
Cd .. : 退回至上级目录
Cd\ : 退回至跟根目录
Del : 删除文件 delete directory
目录就是文件夹。
删除一个类的文件时 del *.文件类型
JDK、JRE、JVM三者关系
JDK (Java Development Kit Java开发给工具集):包括Java的开发工具(编译工具:java.exe 打包工具:jar.exe)以及JRE.
JRE(Java Runtime Environment Java运行环境):包括了Java虚拟机以及Java程序所需的核心类库等,如果只想要运行开发好的Java程序,那么只需要安装JRE就可以。
JVM(Java Virtual Machine): 实现了Java程序的跨平台性,对于不同的操作系统提供不同的Java虚拟机。
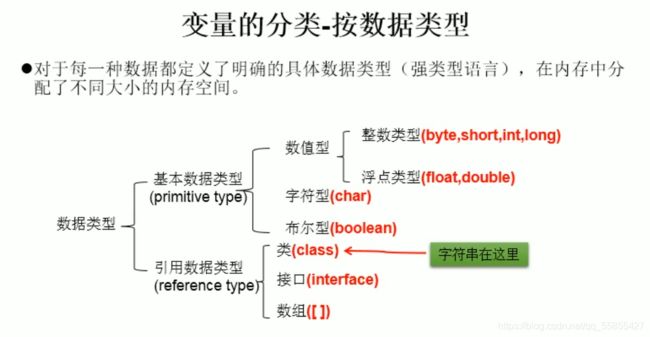
一、数据类型
如果输入类型不匹配的话,编译就会报错。---InputMisMatchException
引用数据类型变量存储的不是null就是地址值(含变量类型)。
1、整形:
Long类型初始化必须写L或者l(但是我没有写也对了,离谱???)

2、浮点型

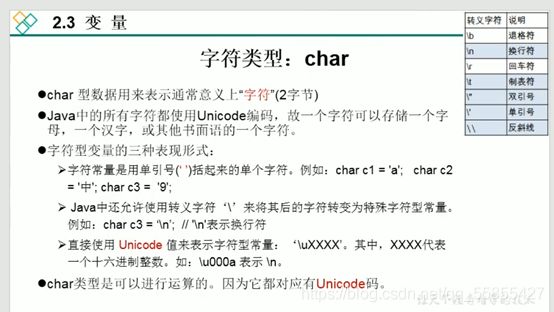
3、字符类型
在用命令行执行程序是,其默认用GBK来读取二进制文件,我们保存java文件时默认保存为UTF-8的二进制文件,所以当我们的代码中出现汉字时,就会出现乱码的情况。解决方法是,将我们的文件保存为ANS文件。
数据容量(表示范围)大小关系:byte、short、char
等于号左边的任意两种类型做运算时,至少要用比最大类型高一级的类型去接收。
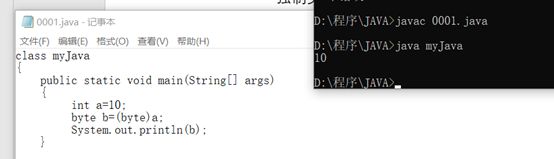
强制类型转换:数据类型 变量名 =(转换类型)变量名;
Java用不同类型的变量去接收数据会报错:

所以需要强制类型转换 :
Java中默认常量整数为int类型,常量小数为double 类型,也就是说一旦涉及到变量加上一个整数至少要用int去接收结果,变量加小数至少要用double去接收。
而之前我所说的在定义long类型的变量并对其进行赋值操作时不写L和l也可以编译的原因是因为编译器将你所提供的数字看成了一个int类型的数字,然后默认做了自动类型提升(容量大的比变量接收容量小的变量的值),但是当你所提供的数字超过了int类型容量的时候,就会报错。例如:

如果改变代码,加上L或者l就可以运行了:

在将浮点型数据赋值给整形数据时为截断取整。
4、String数据类型---字符串型
String数据类型为引用数据类型 S大写
另外获取字符串的某一位置上的字符:变量名+ . +charAt();
str="01234"; char ch=str.charAt(pos)
该类型可以和其他八种基本数据类型做运算,但都是链接运算:+ 。例如:
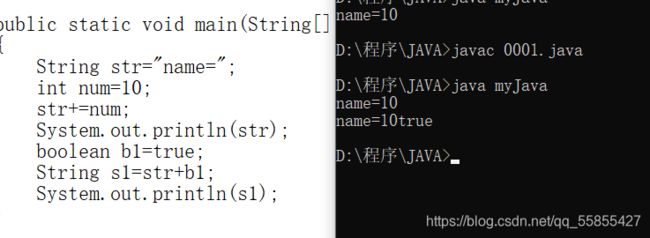
当然连接运算的结果仍是String类型
5、进制

输出的时候以十进制的方式输出

二、算术运算符
1、杂记
java的算术运算符:+ 、- 、* 、/ 、 ++、 -- 、% 、& 、!=、 ==、&&、 &、|、||、^.
^:异或运算符,只要两边的不一样就是真的,一样为假。
short s1=10;
s1+=10; 编译成功。 s1=s1+10; 编译失败。short与常量10(int)的和要用Int类型的变量进行承接。 s1++;编译成功。
&&与& (||与|)虽然运算结果相同,但是他们是有区别的。&&与&的区别:
当左边为真时,&&与&一样:

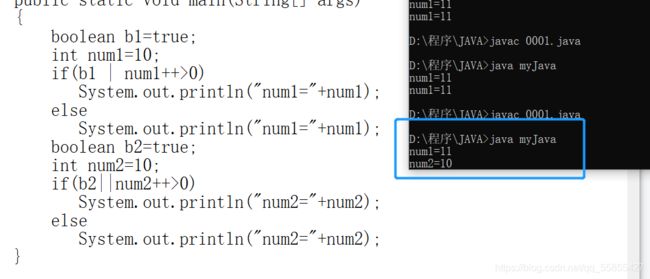
当左边情况为假时,&依旧会进行第二个条件的计算(num1++),而&&则直接结束,不进行num2++操作。所以&&被叫做短路与

类推,||与|的区别,||当左边条件为真时,直接结束运算,不进行num2++计算,而 | 当左边条件为真时,仍然进行num1++运算。所以||被叫做短路或
开发中优先使用短路与和短路或。
2、位运算符(了解即可):

<<(左移运算符):左移几位就乘以2的几次方(空缺用0补齐)
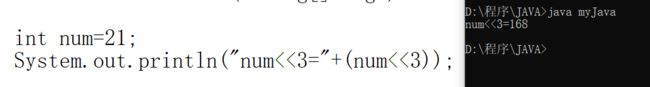
>>(右移运算符):右移几位除以2的几次方(补齐看最高位)。

当然左移和右移都是有一定限度的。
懒得写了,自己看图。
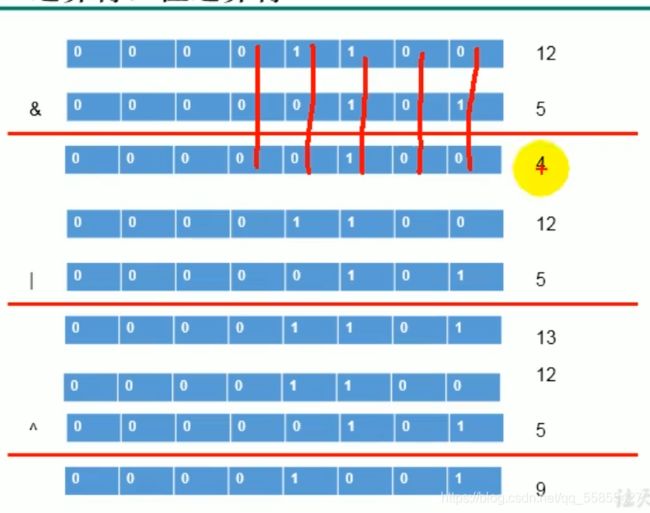
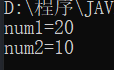
已知:m^n^n=m,用该种方法可以交换两个数的值:
class myJava
{
public static void main(String[] args)
{
int num1=10,num2=20;
num1=num1^num2;
num2=num1^num2;
num1=num1^num2;
System.out.println("num1="+num1);
System.out.println("num2="+num2);
}
}
3、三元运算符(跟c++一样)
4、运算符的优先级

三、基本语法
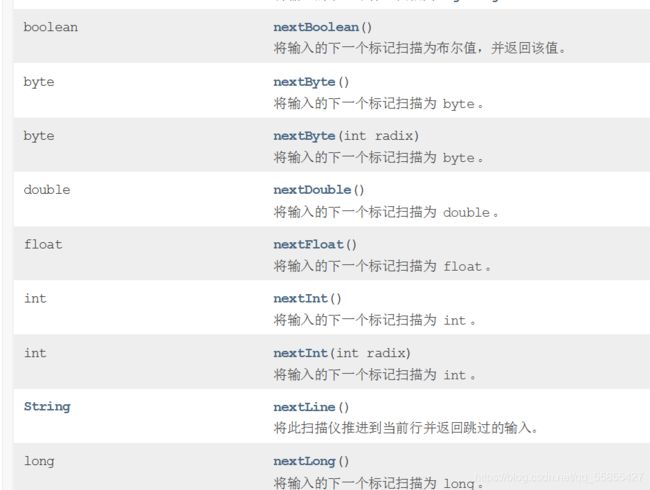
1、从控制台读取输入(int、double、string)
import java.util.Scanner;//类似于c++的#include
class myJava
{
public static void main(String[] args)
{
Scanner scan=new Scanner(System.in);//创建一个类的对象
System.out.print("请输入一个整形数字 :");
int num=scan.nextInt();
System.out.println("您输入的整形数字为 "+num);
System.out.print("请输入一个字符串 :");
String str=scan.next();
System.out.println("您输入的字符串为 :"+str);
System.out.print("请输入一个浮点型数字 :");
double d1=scan.nextDouble();
System.out.println("您输入的浮点型数字为 "+d1);
}
}
/*构造一个Scanner对象,其传入参数为System.in
利用下列方法读取键盘数据:
nextLine( ); //读取一行文本,可带空格
next( ); //读取一个单词
nextInt( ); //读取一个int数值
nextDouble( ); //读取一个double数值
用hasNextInt()和hasNextDouble()检测是否还有表示int或double数值的字符序列 */利用API查找 :
2、一维数组
数组是引用数据类型,引用类型的默认值为null(大致跟c++数组差不多)
数组名储存的是数组的第一个值的地址,数组名被储存在栈区,而数组里面的值储存在堆区、
(1)数组的声明以及初始化(可以写成和c++一样的,但是)
静态初始化:数组的初始化和数组的赋值操作分开进行
int[] arr;//数组的声明
arr =new int [] {1,2,2,4,9};
int arr1[];//单独写一个这也不错
动态初始化:数组的初始化和赋值操作同时进行
int[] arr2=new int[] {1,2,3,4,5};注意,以下语法是错误的:
int[2] arr3=new int[9];
int[] arr3=new int[];
int arr[]; arr={1,2,3};
(2)获取数组长度
arr.length; (没有括号)
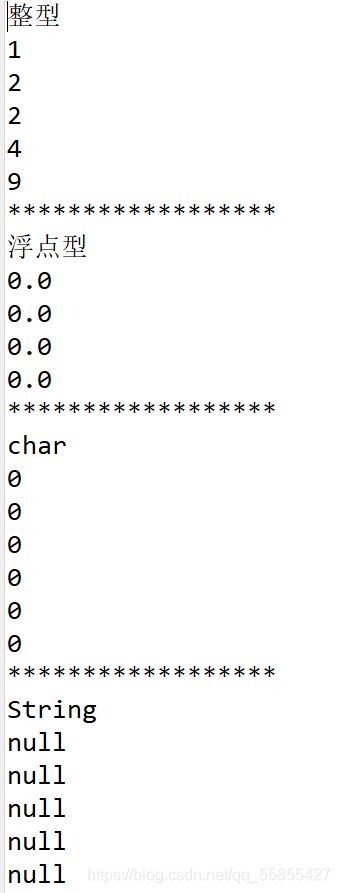
(3)数组的默认初始化的值
整形:0
浮点型:0.0
char : 0 (不是‘0’)
String :null(表示该字符串为空,不等同于“null”)
boolean : false ;
package first_package;
public class first {
public static void main(String[] args) {
int[] arr;
arr =new int [] {1,2,2,4,9};
System.out.println("整型");
for(int i=0;i运行结果如下:
(4)创建确定长度数组
int arr[];
arr=new int[100];
System.out.println(arr.length);//1003、二维数组
跟一维数组一样。
但是跟c++不一样,要写行数,不必写列数,然后给每行确定有多少个元素:
像这样:
int arr[][]=new int [3][];
for(int i=0;i<3;i++)
{
arr[i]=new int[i+1];
for(int j=1;j<=i+1;j++)
{
arr[i][j-1]=j;
}
}
for(int i=0;i<3;i++)
{
for(int j=0;j<=i;j++)
System.out.print(arr[i][j]);
System.out.println();
}
或者写成 int[] arr4[]=....也可以
获取二维数组的行数: arr.length;
获取二维某一行的列数: arr[0].length;
(1)默认初始化值
int arr[][]=new int [3][3];
内层初始化值(arr[0]):地址
外层初始化值:与一维数组初始化值想同
int arr[][]=new int [3][];
内层初始化值(arr[0]):null (此时指针指向的值为空,所以没有地址或者二维数组的元素是一维数组,数组是引用类型,所以默认初始化为空)
外层初始化值:不能调用,会报错
int arr1[]=new int[]{1,2,3,4,5};
int arr2[]=arr1;等同于起别名,他们地址相同,指向了同一个值。
4、对数组的操作(Arrays类)
首先在文件中包括Arrays类:import java.util.Arrays;
返回值类型 函数名 参数列表
(1) 判断两数组是否相同(包括顺序):
boolean equals(int a[],int b[])
(2)输出数组信息
String toString (int a[])
(3) 将指定值填充入数组 (完全替换为同一个数 val)
void fill(int a[],int val)
(4)对数组进行排序
void sort(int[] a)
(5) 对序后的数组进行二分法检索指定的值
int binarySerath(int []a,int key);
package first_package;
import java.util.Arrays;//包括Arrays类
public class first
{
public static void main(String[] args)
{
int arr[]= {1,9,4,7,2,3,8,5,6};
int arr1[]= {1,5,7,8,4,2,3,6,9};
Arrays.sort(arr);//数组排序
System.out.print(Arrays.toString(arr));//数组输出
System.out.println();
boolean Isequals=Arrays.equals(arr1, arr);//比较数组是否相等
System.out.println(Isequals);
int pos=Arrays.binarySearch(arr, 8);//二分法查找
System.out.println(pos);
Arrays.fill(arr, 8);//填充数
System.out.print(Arrays.toString(arr));
}
}
四、面向对象(上)
面向过程强调的是功能行为,以函数为最小单位,考虑怎么做。
面向对象将功能封装进对象,强调具备了功能的对象,以类/对象为最小单位,考虑谁来做。
面向对象更加强调运用人类在日常的逻辑思维中采用的思想方法和原则。如抽象、分类、继承、聚合、多态等。
面向对象的三大特征:封装、继承、多态。
1、基础知识
(1)设计类
设计类就是设计类的成员。
属性=成员变量=field=域、字段
方法=成员方法=函数=method
例如设计Person类:
public class opp001 {
public static void main(String[] args){
Person one=new Person();
one.name="Tom";
System.out.println(one.name);
one.talk();
Person two=one;
System.out.println(two.name);
two.name="hh";
System.out.println(one.name);
}
}
class Person {
String name;
public void talk(){
System.out.println("HELLO WORLD!");
}
}创建示例:Person one=new Person();
如果: Person two=one; 那么在one和two指向的是同一个堆区的地址。
(2)、内存解析
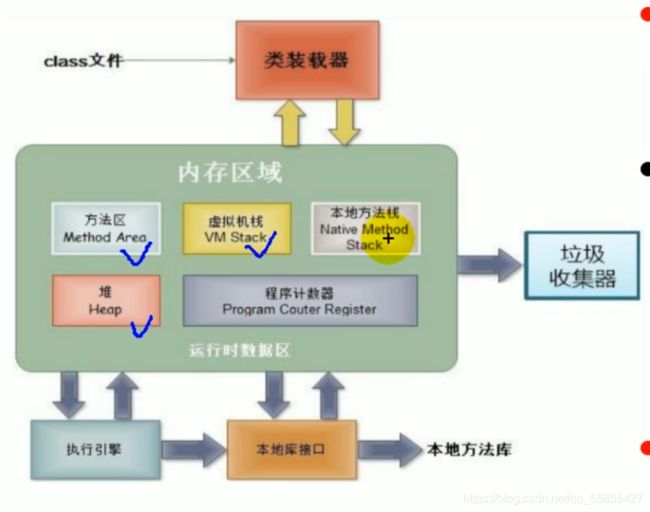
堆(heap):此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都是在这里分配内存。这一点在JAVA虚拟机规范中的描述是:所有的对象实例以及数组都要在堆上分配。
栈(Stack):虚拟机栈。虚拟机栈用于存储局部变量(main方法中的也是)等。局部变量表存放了编译器可知长度的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,是对象在堆内存的首地址)。方法执行完后,自动释放。
方法区(Method Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
也就是说,对象的首地址存在栈区,但是对象的成员存放在堆区。
定义成员方法: 权限修饰符 +返回值类型+方法名+(参数列表)+ { 方法体 }
(3)匿名对象
匿名对象:创建了一个对象,但是没有显形的赋值的对象,即为匿名对象(匿名对象也是存在堆区)。
特征:匿名对象只能调用一次(每个匿名对象都不相同)
package opp001;
public class opp001 {
public static void main(String[] args){
new Person().talk();
new Person().run();
showPerson s=new showPerson();
s.show(new Person());
}
}
class showPerson{
public void show(Person p)
{
p.talk();
p.run();
}
}
class Person {
String name;
public void talk(){
System.out.println("HELLO WORLD!");
}
public void run () {
System.out.println("run");
}
}2、方法
(1)构造并使用类方法(函数)
java没有函数,只有存在于对象的方法
方法一可以调用它本身,以及同处于同一类下的其他方法。(但是main方法是静态的,所以mian只能调用它所在的类的静态方法)
第一种: 所以我们要把方法(函数)写进类里面,然在用到方法是需要先构造类的对象,然后通过对象来实现功能,而且类主函数可以写进不同的文件里面(看方法的权限)
示例:
两个都在文件opp001包下的文件:Array.java (写入类)
ArrayText.java (写入主函数)

第一个文件代码如下:
package opp001;//写入类
public class Array {
public void showArr(int arr[])
{
for(int i=0;i第二个文件代码如下:
package opp001;
public class ArrayText {
public static void main(String[] args)
{
int arr[]= {1,2,3,4};
Array array=new Array();//构造Array类的对象
array.showArr(arr); //利用对象完成功能
}
}
第二种:将方法直接写进main方法所在的类中,如果是非静态的就构造与main方法所在类的对象,然后使用;如果是静态的可以通过“类名.”的方式直接使用。
public class methodUse {
public static void main(String[] args) {
methodUse s=new methodUse();
s.show();
}
public void show() {
System.out.println("????");
}
}
(2)方法的重载
在同一个类中,允许存在一个以上的同名方法。(和c++一样:返回值不能决定重载)
方法名和参数列表可以确定一个方法。
(3)可变个数形参的方法
a.可变个数形参的形式:数据类型 + ... (三个点,无空格)+变量名
public void show(String ... str)
b.可调用可变个数形参的方法是,传入的参数个数可以是:0,1,2......
c.可变个数形参的方法与本类中方法名相同、形参不同的方法之间构成重载
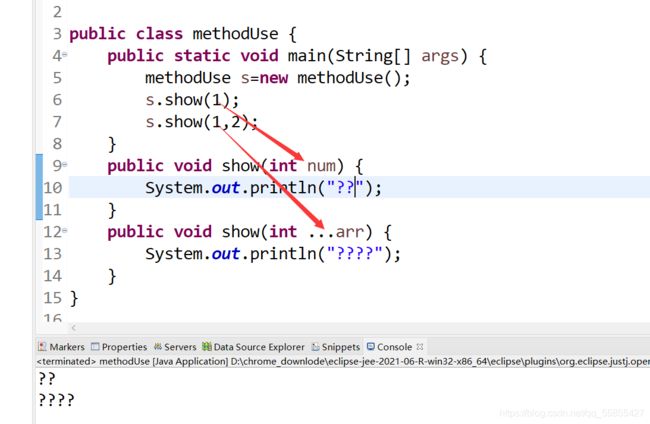
但是,当传进的参数为不可变个数的形参时,优先选择不可变个数形参。
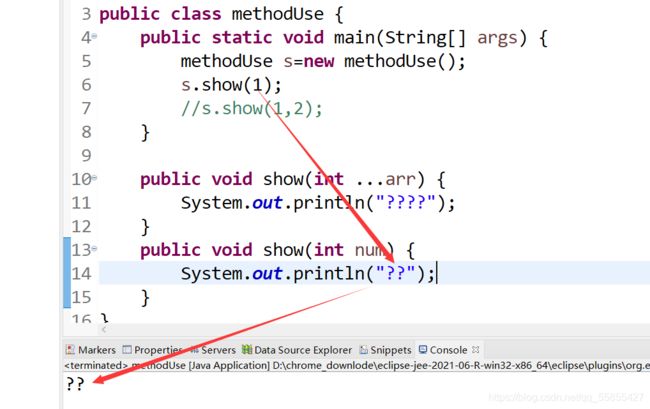
d.可变个数形参的方法有本类中方法名相同,形参类型也相同的数组之间不构成重载。(两者不能同时存在)
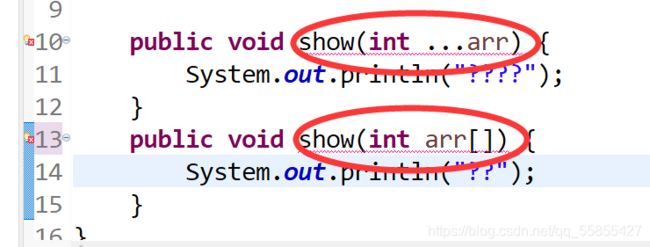
e.可变个数形参在方法的形参列表中,必须声明在末尾
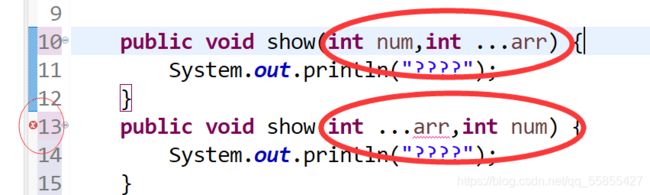
f.可变个数形参在方法的形参中,最多只能声明一个可变形参

g.可变个数形参的参数可以当做数组使用
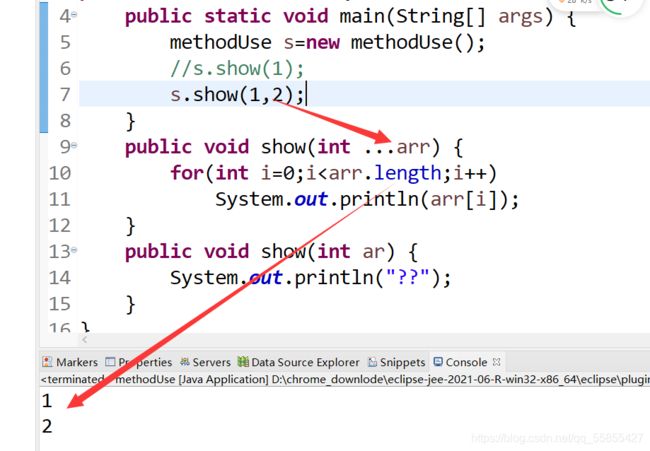
(4)变量的赋值
如果是基本数据类型的话,那么赋值就是传递变量中储存的数据值,
如果是引用数据类型,那么赋值就是传递值所在的 地址。
(5)方法中的参数传递(跟c++一样)
如果是基本数据类型的话,那么传递就是传递变量中储存的数据值,
如果是引用数据类型,那么传递就是传递值所在的地址。
2、封装与隐藏
(1)封装性的体现
a :将成员变量私有化,然后提供公共的方法(Set、Get...)来操作该成员变量,而不能直接对该变量进行操作。(跟c++类似)
b :方法的私有化,例如在Arrays类中的每一个方法都需要一个交换两个位置上的值得操作,该操作就是一种方法,但是该方法只能在Arrays类中使用。
c :单例模式。。。。
(2)权限修饰符
a.Java规定的4中权限(从小到大排列):private、缺省(啥也不写)、protected 、public
b、4种权限可以用来修饰类及类的内部结构、属性、方法、构造器、内部类
c、具体的,四种权限都可以用来修饰类的内部结构、属性、方法、构造器、内部类。而修饰类的话,只能使用缺省、public
d. 不同包的非子类只有public 可用

(3)封装性总结
Java提供了4种权限修饰符来修饰类及类的内部结构,体现类及类的内部结构在被调用时的可见性的大小。
3、构造器(和c++相似)
Java的构造器要对每一个对象赋值,即便是空值也需要赋值。
在继承中,父类一般都要有一个空构造器,以便对父类中的属性赋值。(否则就会报错)
(1)构造器的作用
a. 创建对象
b. 初始化对象的信息
(2)构造器的特点
a.如果没有显式的服能够以构造器的话,则系统默认提供一个空参的构造器。
b.定义构造器的格式:权限修饰符 +类名+(形参列表)
c.一个类中定义的多个构造器,彼此之间形成重载
d.一旦我们显式的定义了类的构造器之后,系统就不再提供默认的空参构造器
e.一个类中,至少会有一个构造器
4、Javabean
JavaBean是一种Java语言写成的可重用组件
所谓JavaBean,是指复合如下标准的Java类 :
a.类是公共的
b.有一个无参的公共的构造器
c.有属性,且有对应的get和set方法。
5、this
当方法或者构造器的参数名与类的属性名相同时,必须使用this来表明哪一个变量是否为属性(因为就近原则)。
使用方法如下: this.属性名 this.方法名
另外还可以通过this+(参数列表)的方式来调用构造器。
例如:

另外,this+(参数列表)必须写在构造器的最开始,而且每个构造器最多只能用一个其他构造器,器不能造成死循环。
6、package(包)
(1)为了更好的实现项目中的类的管理,提供包的概念、
(2)使用package声明类或接口所属的包,声明在源文件的首行。
(3)包,属于标识符,遵循标识符的命名规则,规范,见名知意。
(4) 命名的时候,每“ .”一次,就代表一层文件目录。
补充: 同一个包下,不能命名同名的接口、类。不同的包下可以。
7、inport(导入)
(1)在源文件中使用import显式的导入指定包下的类或接口
例如使用Arrays类是需要导入该包(编译器自动导入,或者鼠标放在上面,然后手动导入):

(2)声明在包的声明和类的声明之间。
(3)如果需要导入多个类或接口,那么久并列显显式多个inport语句即可(跟c++类似)
(4)举例,可以使用“java.util.*”的方式,一次性导入util包下的所有的类或接口
比如Scanner和Arrays同属一个util包,那么我们可以直接导入util包:
import java.util.*;相当于:
import java.util.Arrays;
import java.util.Scanner;(5)如果导入的类或接口是java.lang包下的,或者是当前包下的,则可以省略import语句。例如:String类和System
(6)如果在代码中使用不同包下的同名的类,那么就需要使用,类的全类名的方式指明调用的是 哪个类。
比如在两个包里面都有Dog类,当我们需要在另一个类(importText)里面需要使用的时候那么一个可以导入,另一个就必须写全名(包名+“.”+类名);

package opp001;
import java.util.*;
/*import java.util.Arrays;
import java.util.Scanner;*/
import bao.Dog;
public class importText {
public static void main(String[] args) {
Dog d=new Dog(1);
opp00.Dog d1=new opp00.Dog();
}
}
(7)如果已经导入java.a包下的类,但是如果需要使用a包下的子包的类的话,仍需要导入(可以理解为子包与父包是并列关系)
(8)import static组合的使用,调用指定类或接口下的静态的属性或方法
8、Eclipse快捷键
Shift + 回车 ---> 在该行下面再创建一个空白行
Ctrl +Shift + 回车--->在该行上面创建一个空白行
Ctrl --->查看源码 或者Ctrl+Shift+t 搜索需要查看的类
Ctrl + D---->选中行,然后删除行
Ctrl +Shit + F--->格式化代码(变整齐)
Tab---->整体后移
Shift+Tab---->整体前移
Alt+/---->单行注释 Alt+\---->取消单行注释
Ctrl+Shift+X--->变成大写
Ctrl+Shift+Y 把当前选中的文本全部变为小写
Ctrl+O --->快速显示 OutLine
Ctrl+T --->快速显示当前类的继承结构
Ctrl+Shift+F--->调整格式
五、面向对象(中)
9、继承(extends)
继承的好处:a. 减少了代码的冗余,提高了代码的复用性
b.便于功能的扩展
c.为之后的多态性的使用提供了前提
继承的格式: class A extends B { };
A: 子类、派生类、subclass B:父类、超类、基类、superclass
继承的特点:
(1)一旦子类A继承父类B以后,子类A就获取了父类B中声明的所有的属性和方法。(包括private权限的属性和方法)
(2)子类继承父类以后,还可以声明自己特有的属性和方法,实现功能的扩展,因此,子类和父类的关系不同于子集和集合的关系
Java关于继承的规定:
(1)一个类可以被多个子类继承。
(2)Java中类是单继承性,一个类只能有一个父类
(3)子类和父类只是相对而言
(4)子类直接继承的父类成为直接父类,间接继承的父类称为间接父类
(5)子类继承父类以后,就获取了直接父类以及间接父类中声明的属性和方法
一般类和Object类的关系:
(1)如果没有显式的声明一个类的父类的话,则此类继承于java.lang.Object
(2) 所有的类(除了java.lang.Object类之外)都直接或者间接的继承于java,lang,Object类
(3)基于(2),所有的类都具有java.lang.Object类所声明的功能。
10、方法的重写
重写:子类继承父类以后,可以对父类同名同 参数的方法进行覆盖操作。
应用:重写以后,当创建子类对象以后,通过子类对象调用子父类中的同名同参数的方法是,实际上执行的是子类重写父类的方法。
重写的规定
声明的方法:权限修饰符 返回值类型 方法名(参数列表) (throws暂时不清楚)异常的类型{ 方法体 }
约定俗称,子类中的叫重的方法,父类中的叫被重写的方法。
(1) 子类重写的方法的方法名誉形参列表与父类被重写的方法的方法名和参数列表一样
(2)子类重写的方法的权限修饰符不小于父类被重写的方法的权限修饰符,但是,子类不能重写父类中声明为private权限的方法(后者该操作不能叫重写)
(3)返回值类型:
a.父类被重写的方法的返回值类型是void,则子类重写的方法的返回值类型只能void
b.父类被重写的方法的返回值类型是A类时,则子类重写的方法的返回值类型可以是A类或者A类的子类
c.父类重写的方法的返回值类型是基本数据类型时,子类重写的方法的方绘制类型只能是跟父类一样的类型
(4)子类重写的方法抛出的异常不能大与父类被重的方法抛出的异常
子类和父类同名同参数的方法要么都声明为static类型(不是重写),或者都不声明为static类型(考虑重写)
11、super
super语句只能在类实例构造函数内部使用(和this相同)
(1)super可用理解为:父类的
(2) super可以用来调用属性、方法、构造器
(3)super的使用(表明父类的作用域)
a.我们可以在子类的方法或者构造器中,通过使用“super.属性”或“super.方法”的方式,显式地调用父类中声明的属性或方式。但是,通常情况下,我们习惯的省略"super.”
b.特殊情况,当子类和父类中定义了同名的属性或者方法是,我们想在子类中调用父类中的属性或者方法时,使用"super."表明调用的是父类中声明的属性 或方法
(4)super和构造器
a.我们可以在子类的构造器中显式的使用“super(形参列表)”的方式调用父类中声明的制定的构造器。
b.“super(形参列表)”的使用必须声明在子类构造器的首行。 无论通过哪个构造器创建子类对象,需要保证优先初始化父类。当子类继承父类后,“继承”父类中所有的属性和方法,因此子类有必要知道父类如何对对象进行初始化。
c.在我们类的构造器中,针对“this(形参列表)”和“super(形参列表)”只能二选一,不能同时出现
d.在构造器的首行,如果没有显示的声明“this(形参列表)”和“super(形参列表)”,则默认的调用父类的空参构造器。如果没有空参构造器,那么就需要显式的调用父类的其他构造器。(一般父类都需要保留空参构造器)
创建对象时,会先自动调用父类的构造函数,再自动调用子类的构造函数,也就是说我们需要在子类的构造器里面包括父类的构造器。 前面我们已经知道在我们定义了一个父类,然后在我们用子类继承父类的时候,我们必须要在子类的构造器开头调用父类的构造器,如果我们不写父类构造器,那么编译器会给我们提供一个默认的空参构造器,那么在我们写子类的构造函数时,编译器会自动默认的帮我们写入super();来调用父类的默认的空参构造器。但是当我们写了父类的构造器时,那么就没有系统提供的默认构造器,也就是说我们需要自己通过super(参数列表)的方式来自己调用父类的构造器。(收藏里面写的好)
12、多态性
(1)理解多态性,可以理解为一个事物的多种形态。
(2)何为多态性:父类的引用指向子类的对象(或者之类的对象赋值给父类的引用)
(3)多态的使用 :虚拟方法调用
有了对象的多态性之后,我们在编译期,只能调用父类中声明且子类中的重写的的方法,但在运行期,我们实际执行的是子类重写的父类的方法。也就是编译 看左边,运行看右边。
(4)多态性的使用前提 :继承和方法的重写
(5)多态性不涉及属性,也就是说如果父类跟子类有相同类型且同名的属性时,利用多态操作的是父类的属性,而不是子类的属性
多态的细节补充: