uber全球用户每天会产生500万条行程,保证数据的准确性至关重要。如果所有的数据都得到有效利用,t通过元数据和聚合的数据可以快速检测平台上的滥用行为,如垃圾邮件、虚假账户和付款欺诈等。放大正确的数据信号能使检测更精确,也因此更可靠。
为了解决我们和其他系统中的类似挑战,Uber Engineering 和 Databricks 共同向Apache Spark 2.1开发了局部敏感哈希(LSH)。LSH是大规模机器学习中常用的随机算法和哈希技术,包括聚类和近似最近邻搜索。
在这篇文章中,我们将讲解Uber如何使用这个强大的工具进行大规模的欺诈行程检测。
为什么使用LSH?
在 Uber Engineering 实现 LSH 之前,我们筛选行程的算法复杂度为 N^2; 尽管精度较高,N^2 的算法复杂度对于 Uber 当前的数据规模过于耗时、密集(volume-intensive),且对硬件要求高。
LSH的总体思路是使用一系列函数(称为 LSH 族)将数据点哈希到桶(buckets)中,使距离较近的数据点位于同一个桶中的概率较高,而距离很远的数据点在不同的桶里。因此, LSH 算法能使具有不同程度重叠行程的识别更为容易。
作为参考,LSH 是一项有大量应用方向的多功能技术,其中包括:
- 近似重复的检测: LSH 通常用于对大量文档,网页和其他文件进行去重处理。
- 全基因组的相关研究:生物学家经常使用 LSH 在基因组数据库中鉴定相似的基因表达。
- 大规模的图片搜索: Google 使用 LSH 和 PageRank 来构建他们的图片搜索技术VisualRank。
- 音频/视频指纹识别:在多媒体技术中,LSH 被广泛用于 A/V 数据的指纹识别。
LSH 在 Uber 的应用
LSH 在 Uber 主要用于欺诈司机的判断,基于空间特性检测相似的行程。Uber 工程师在2016年Spark峰会上介绍了这个用例,讨论我们团队在Spark框架中使用LSH的动机,以便结合所有行程数据并从中筛选欺诈行为。我们在Spark上使用LSH的动机有三个方面:
- Spark是Uber运营的重要组成部分,许多内部团队目前使用Spark进行机器学习、空间数据处理、时间序列计算、分析与预测以及特别的数据科学探索等各种复杂的数据处理。实际上,Uber 在YARN和Mesos上都使用了几乎所有的Spark组件,如MLlib,Spark SQL,Spark Streaming和直接RDD处理; 由于我们的基础架构和工具围绕Spark构建,我们的工程师可以轻松创建和管理Spark应用程序。
- 在具体的机器学习进行之前,Spark可以高效地进行数据清理和特征工程(feature engineering),使数据处理速度极大的提高。Uber收集的大量数据使传统方法解决此问题时难以扩展且速度较慢。
- 我们不需要方程的精确解,因此不需要购买和维护额外的硬件。近似值为我们提供了足够的信息来判断是否存在潜在的欺诈活动,在这种情况下,这些信息足以解决我们的问题。LSH允许我们牺牲一些精度来节省大量的硬件资源。
出于这些原因,在Spark上部署LSH解决此问题是达到我们业务目标的正确选择:可扩展,数据规模和精度。(译注:原文为scale, scale and scale again)
在更高的层面上,我们使用LSH方法有三个步骤。首先,我们通过将每个行程分解为相同大小的区域段,为其创建一个特征向量。然后,我们对Jaccard距离函数使用用MinHash哈希这些特征向量。最后,我们实时的使用批量相似度连接(similarity join in batch)或k-Nearest Neighbor搜索。与检测欺诈的简单暴力算法相比,我们当前的数据集下Spark工作的完成速度提高了整个数量级(从使用N^2方法的约55小时到使用LSH约4小时)。
API教程
为了最好地展示LSH的工作原理,我们将在Wikipedia Extraction(WEX)数据集上使用MinHashLSH 寻找相似的文章。
每个LSH家族都与其度量空间相关。在Spark 2.1中,有两个LSH估计器:
- 基于欧几里德距离的BucketedRandomProjectionLSH
- 基于Jaccard距离的MinHashLSH
我们需要对词数的实特征向量进行处理,因此,这种情况下我们选择使用MinHashLSH。
加载原始数据
首先,我们需要启动一个EMR(Elastic MapReduce弹性MapReduce)集群,并将WEX数据集挂载为一个EBS(Elastic Block Store 弹性块存储)卷。此过程额外的细节可以通过亚马逊的EMR和EBS相关文档。
在建立Spark集群并挂载WEX数据集后,我们根据集群大小将一个WEX数据样本上传到HDFS。在Spark shell中,我们加载HDFS样本数据:
// Read RDD from HDFS
import org.apache.spark.ml.feature._ import org.apache.spark.ml.linalg._ import org.apache.spark.sql.types._ val df = spark.read.option("delimiter","\t").csv("/user/hadoop/testdata.tsv") val dfUsed = df.select(col("_c1").as("title"), col("_c4").as("content")).filter(col("content") !== null) dfUsed.show()
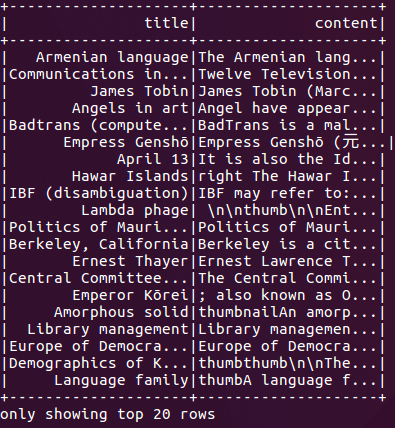
图1:维基百科中的文章以标题和内容表示。
图1显示了我们上方代码的结果,按标题和内容显示文章。我们将使用该内容作为我们的哈希键,并在后面的实验中大致找到类似的维基百科文章。
准备特征向量
MinHash用于快速估计两个数据集的相似度,是一种非常常见的LSH技术。在Spark中实现的MinHashLSH,我们将每个数据集表示为一个二进制稀疏向量。在这一步中,我们将把维基百科文章的内容转换成向量。
使用以下代码进行特征工程,我们将文章内容分割成单词(Tokenizer),创建单词计数的特征向量(CountVectorizer),并删除空的文章:
// Tokenize the wiki content
val tokenizer = new Tokenizer().setInputCol("content").setOutputCol("words") val wordsDf = tokenizer.transform(dfUsed) // Word count to vector for each wiki content val vocabSize = 1000000 val cvModel: CountVectorizerModel = new CountVectorizer().setInputCol("words").setOutputCol("features").setVocabSize(vocabSize).setMinDF(10).fit(wordsDf) val isNoneZeroVector = udf({v: Vector => v.numNonzeros > 0}, DataTypes.BooleanType) val vectorizedDf = cvModel.transform(wordsDf).filter(isNoneZeroVector(col("features"))).select(col("title"), col("features")) vectorizedDf.show()
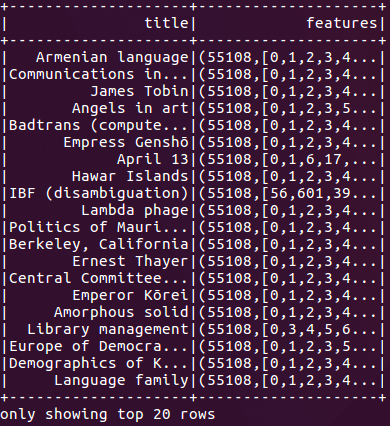
图2:在对代码进行特征工程之后,维基百科文章的内容被转换为二进制稀疏矢量。
LSH模型的拟合和查询
为了使用MinHashLSH,我们首先用下面的命令,在我们的特征数据上拟合一个MinHashLSH模型:
val mh = new MinHashLSH().setNumHashTables(3).setInputCol("features").setOutputCol("hashValues") val model = mh.fit(vectorizedDf)
我们可以用我们的LSH模型进行多种类型的查询,但为了本教程的目的,我们首先对数据集执行一次特征转换:
model.transform(vectorizedDf).show()
这个命令为我们提供了哈希值,有利于手动连接(manual joins)和特征生成。

图3: MinHashLSH添加了一个新列来存储哈希。每个哈希表示为一个向量数组。
接下来,我们执行一个近似最近邻(Approximate Nearest Neighbor,ANN)搜索,以找到离我们目标最近的数据点。出于演示的目的,我们搜索的内容能够大致匹配"united states"的文章。
val key = Vectors.sparse(vocabSize, Seq((cvModel.vocabulary.indexOf("united"), 1.0), (cvModel.vocabulary.indexOf("states"), 1.0))) val k = 40 model.approxNearestNeighbors(vectorizedDf, key, k).show()
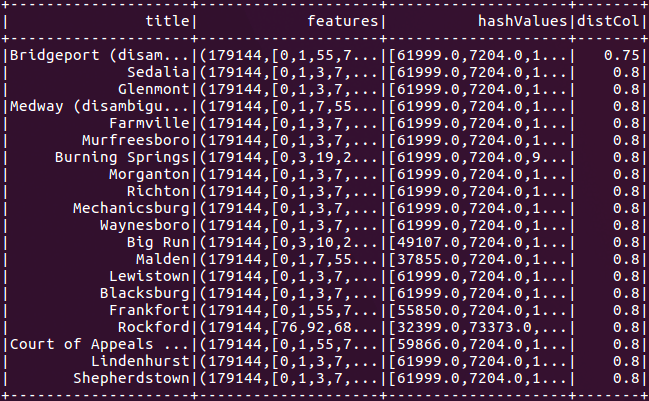
图4:近似最近邻搜索结果,查找维基百科中有关“united states”的文章。
最后,我们运行一个近似相似连接(approximate similarity join),在同一个数据集中找到相似的文章对:
// Self Join
val threshold = 0.8
model.approxSimilarityJoin(vectorizedDf, vectorizedDf, threshold).filter("distCol != 0").show()
虽然我们在下面使用自连接,但我们也可以连接不同的数据集来得到相同的结果。

图5:近似相似连接列出了类似的维基百科文章,并设置哈希表的数量。
图5演示了如何设置哈希表的数量。对于一个近似相似连接和近似最近邻命令,哈希表的数量可以平衡运行时间和错误率(OR-amplification)。增加哈希表的数量会提高准确性,但也会增加程序的通信成本和运行时间。默认情况下,哈希表的数量设置为1。
想要在Spark 2.1中进行其它使用LSH的练习,还可以在Spark发布版中运行和BucketRandomProjectionLSH、MinHashLSH相关的更小示例。
性能测试
为了衡量性能,我们在WEX数据集上测试了MinHashLSH的实现。使用AWS云,我们使用16个executors(m3.xlarge 实例)执行WEX数据集样本的近似最近邻搜索和近似相似连接。
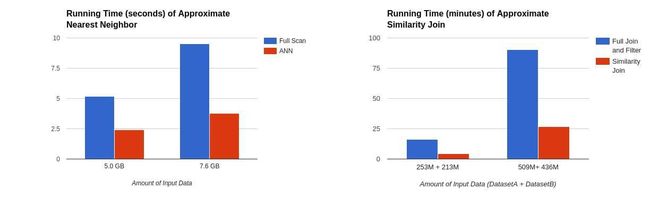
图6:使用numHashTables = 5,近似最近邻的速度比完全扫描快2倍。在numHashTables = 3的情况下,近似相似连接比完全连接和过滤要快3-5倍。
在上面的表格中,我们可以看到哈希表的数量被设置为5时,近似最近邻的运行速度完全扫描快2倍;根据不同的输出行和哈希表数量,近似相似连接的运行速度快了3到5倍。
我们的实验结果还表明,尽管当前算法的运行时间很短,但与暴力方法的结果相比仍有较高的精度。近似最近邻搜索对于40个返回行达到了85%的正确率,而我们的近似相似连接成功地找到了93%的邻近行。这种速度与精度的折中算法,证明了LSH能从每天TB级数据中检测欺诈行为的强大能力。
下一步
尽管我们的LSH模型能够帮助Uber识别司机的欺诈行为,但我们的工作还远远没有完成。通过对LSH的初步实现,我们计划在未来的版本中添加一些新的功能。其中高优先级功能包括:
SPARK-18450:除了指定完成搜索所需的哈希表数量之外,这个新功能使用户能够在每个哈希表中定义哈希函数的数量。这个改变也将同样提供对 AND/OR-compound加强的支持。
SPARK-18082&SPARK-18083:我们想要实现其他的LSH familes函数。这两个更新的实现将能对两个数据点之间的汉明距离(Hamming distance)进行位采样,并提供机器学习任务中常用的余弦距离随机投影符号。
SPARK-18454:第三个功能将改进近似最近邻搜索的API。这种新的多探测(multi-probe )相似性搜索算法,能够在不需要大量的哈希表的情况下提升搜索的质量。
我们将继续开发和扩展当前项目,加入上述以及其他的相关功能,非常欢迎大家的反馈。