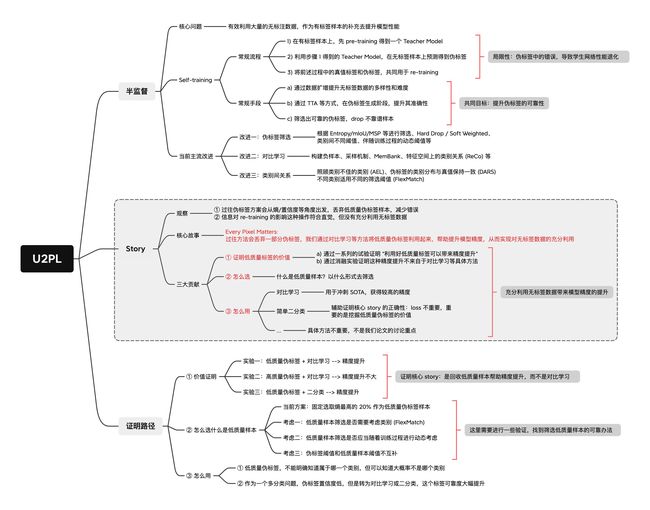
Paper Reading: (U2PL) 基于不可靠伪标签的半监督语义分割

目录
- 简介
- 目标/动机
- 方法
-
-
- Pseudo-Labeling
- Using Unreliable Pseudo-Labels
- 补充知识
-
- InfoNCE Loss
- OHEM
-
- 实验
-
- Comparison with Existing Alternatives
- Ablation
-
- Effectiveness of Using Unreliable Pseudo-Labels
- Alternative of Contrastive Learning
- 总结
-
- 附录
-
- U2PL 与 negative learning 的区别
- U2PL 技术蓝图
简介
题目:《Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels》, CVPR’22,
U2PL: 基于不可靠伪标签的半监督语义分割
日期:2022.3.14
单位:上海交通大学, 香港中文大学, 商汤科技
论文地址:https://arxiv.org/abs/2203.03884
GitHub:https://github.com/Haochen-Wang409/U2PL/
项目地址:https://haochen-wang409.github.io/U2PL/
作者PR:https://zhuanlan.zhihu.com/p/474771549
- 作者
(第一位作者找不到
同等贡献,王浩辰,个人主页:https://haochen-wang409.github.io/

王昊辰,中国科学院自动化研究所多模态人工智能系统国家重点实验室智能感知与计算研究中心二年级博士生。 在张兆祥教授的指导下。2022年6月获得上海交通大学机械工程学院学士学位。
研究重点是计算机视觉和模式识别, 特别是在以下主题上:图像感知、标签高效学习、无监督表示学习

- 其他作者
Yujun Shen ,目前是蚂蚁研究院的高级研究科学家,领导 Interatcion 智能实验室。 他的研究重点是计算机视觉和深度学习,特别是生成模型和 3D 视觉。

(单属商汤科技的没列出:Jingjing Fei、 Wei Li、 Guoqiang Jin、 Liwei Wu)
商汤科技的执行研究总监,也是商汤智慧城市集团(SCG)研发共享技术中心(STC)的负责人
-
通讯作者
-
摘要
半监督语义分割的关键是为未标记图像的像素分配足够的伪标签。一种常见的做法是选择高度自信的预测作为伪GT,但这会导致一个问题,即大多数像素可能由于其不可靠性而被闲置。我们认为,每个像素对模型训练都很重要,甚至其预测也是模糊的。直观地说,不可靠的预测可能会在top类别(即概率最高的类别)中混淆,然而,它应该确信像素不属于其余类别。因此,这样的像素可以令人信服地被视为那些最不可能的类别的负样本。基于这一见解,我们开发了一个有效的管道,以充分利用未标记的数据。具体地说,我们通过预测的熵来分离可靠和不可靠的像素,将每个不可靠像素推送到由负样本组成的类别队列中,并设法用所有候选像素训练模型。考虑到训练进化,预测变得越来越准确,我们自适应地调整可靠不可靠分区的阈值。在各种基准和训练环境中的实验结果表明,我们的方法优于最先进的替代方法。
本篇文章认为,半监督任务的关键在于充分利用无标签数据,提出U2PL,基于「 Every Pixel Matters」的理念,有效利用了包括不可靠样本在内的全部无标签数据,来提升算法精度。
Self-training: 样本筛选导致训练不充分
半监督学习的核心问题在于有效利用无标注样本,作为有标签样本的补充,以提升模型性能。
经典的 self-training 方法大多遵循着 supervised learning → pseudo labeling → re-training 的基本流程,但学生网络会从不正确的伪标签中学习到错误的信息,因而存在 performance degradation 的问题。
常规作法是通过样本筛选的方式只留下高置信度预测结果,但这会将大量的无标签数据排除在训练过程外,导致模型训练不充分。此外,如果模型不能较好地预测某些 hard class,那么就很难为该类别的无标签像素分配准确的伪标签,从而进入恶性循环。
如果模型不能令人满意地预测某个类别(例如,图1中的椅子),则很难为关于此类的像素分配准确的伪标签,这可能导致训练不足且绝对不平衡。要充分利用未标记的数据,每个像素都应该得到适当的利用。
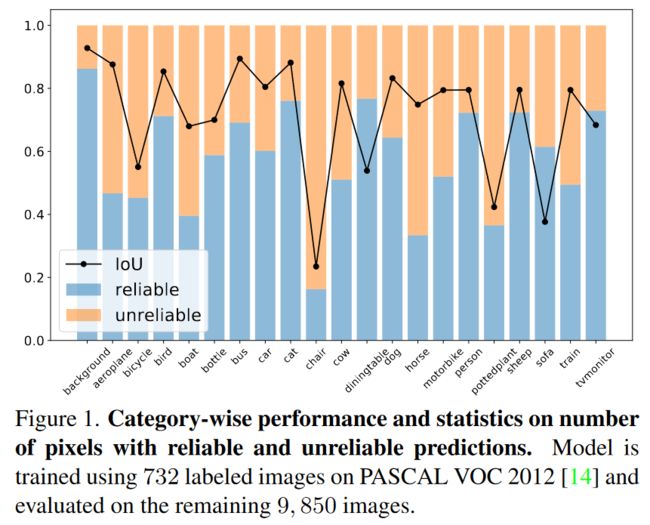
图1。分类性能和像素数量统计数据,具有可靠和不可靠的预测。使用PASCAL VOC 2012上的732张标记图像对模型进行训练,并对其余9850张图像进行评估。
如上所述,直接使用不可靠的预测作为伪标签将导致性能下降。在本文中,我们提出了一种使用不可靠伪标签的替代方法。我们将我们的框架。
首先,我们观察到,不可靠的预测通常只在少数类中而不是在所有类中混淆。以图2为例,带有白叉的像素在摩托车和人类上接收到相似的概率,但模型非常确定该像素不属于汽车和火车类。基于这一观察结果,我们重新考虑将混淆的像素作为那些不太可能的类别的负样本。具体来说,在从未标记的图像中获得预测后,我们使用每像素熵作为度量(见图2a)将所有像素分为两组,即可靠像素和不可靠像素。所有可靠的预测都用于导出正伪标签,而具有不可靠预测的像素则被推入充满负样本的内存库。为了避免所有负伪标签只来自类别的子集,我们为每个类别使用一个队列。这样的设计确保了每个类别的负样本的数量是平衡的。同时,考虑到伪标签的质量随着模型的精度越来越高而变得越来越高,我们提出了一种自适应调整阈值的策略来划分可靠和不可靠像素。
目标/动机
- Every Pixel Matters
具体来说,预测结果的可靠与否,我们可以通过熵 (per-pixel entropy) 来衡量,低熵表示预测结果可靠,高熵表示预测结果不可靠。我们通过 Figure 2 来观察一个具体的例子,Figure 2(a) 是一张蒙有 entropy map 的无标签图片,高熵的不可靠像素很难被打上一个确定的伪标签,因此不参与到 re-training 过程,在 FIgure 2(b) 中我们以白色表示。

图2:关于不可靠伪标签的说明。(a) 从未标记图像预测的逐像素熵,其中低熵像素和高熵像素分别指示可靠和不可靠的预测。(b) 仅来自可靠预测的逐像素伪标签,其中白色区域内的像素未分配伪标签。(c) 可靠预测的类别概率(即黄叉),该概率对于监督类人员足够有信心。(d) 不可靠预测的类别概率(即白十字),徘徊在摩托车和人之间,但有足够的信心不属于汽车和火车。
我们分别选择了一个可靠的和不可靠的预测结果,在 Figure 2© 和 Figure 2(d) 中将它们的 category-wise probability 以柱状图的形式画出。黄色十字叉所表示的像素在 person 类上的预测概率接近于 1,对于这个预测结果模型非常确信,低熵的该像素点是典型的 reliable prediction。而白色十字叉所表示的像素点在 motorbike 和 person 两个类别上都具有不低的预测概率且在数值上较为接近,模型无法给出一个确定的预测结果,符合我们定义的 unralibale prediction。对于白色十字叉所表示的像素点,虽然模型并不确信它具体属于哪一个类别,但模型在 car 和 train 这两个类别上表现出极低的预测概率,显然很确信不属于这些类别。
因而,我们想到即使是不可靠的预测结果,虽然无法打上确定的伪标签,但仍可以作为部分类别的负样本,从而参与到模型的训练,从而让所有的无标签样本都能在训练过程中发挥作用。
方法

图3。我们提出的U2PL方法的概述。U2PL包含一个学生网络和一个教师网络,其中教师与学生一起进行动量更新。标记的数据直接输入到学生网络中进行监督训练。给定一个未标记的图像,我们首先使用教师模型进行预测,然后根据像素的熵将其分为可靠像素和不可靠像素。这样的过程被公式化为等式(6)。可靠的预测被直接用作向学生提供建议的伪标签,而每个不可靠的预测都被推入一个类别记忆库memory bank。每个存储器组中的像素被视为对应类的负样本,其公式化为等式(4)。
网络结构上,U2PL 采用 self-training 技术路线中常见的 momentum teahcer 结构,由 teacher 和 student 两个结构完全相同的网络组成,teacher 通过 EMA 的形式接受来自 student 的参数更新。单个网络的具体组成参考的是 ReCo (ICLR’22),包括三个部分: encoder ℎ , decoder f, 表征头g 。
损失函数优化上,有标签数据直接基于标准的交叉熵损失函数 Ls进行优化。无标签数据则先靠 teacher 给出预测结果,然后根据 pixel-level entropy 将预测结果分成 reliable pixels 和 unreliable pixels 两大部分 ,最后分别基于 Lu和 Lc 进行优化。
由于数据集中存在长尾问题,如果只使用一个 batch 的样本作为对比学习的负样本可能会非常受限,因此采用 MemoryBank 来维护一个类别相关的负样本库,存入的是由 teacher 生成的断梯度特征,以先进先出的队列结构维护。
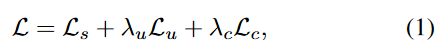

Lc是像素级InfoNCE损失,定义为:

其中,C:类的数量、M:锚像素(Mask?)的数量、N:负样本的总数,
z=g◦ h(x)是表示头的输出,zci:类别c的第i个锚的表示。
每个锚像素后面跟着一个正样本和N个负样本,其表示分别为z+ci和z−cij。
〈·,·〉是来自两个不同像素的特征之间的余弦相似度,其范围限制在−1到1之间(设置M=50,N=256和τ=0.5)。
self-training 不过多说明,重点关注对比学习 Lc 部分,是经典的 InfoNCE Loss。
Pseudo-Labeling
(以下说明来自作者:https://zhuanlan.zhihu.com/p/474771549)

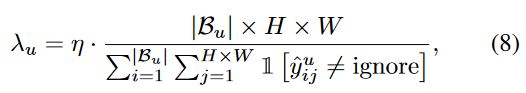
Using Unreliable Pseudo-Labels


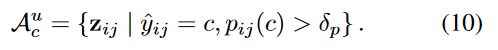
![]()
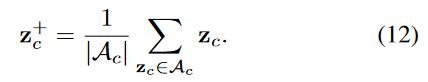
最后是构建 anchor pixel 的 negative sampe,同样的也需要分成有标签样本和无标签样本两个部分去讨论。对于有标签样本,我们明确知道其所属的类别,因此除真值标签外的所有类别都可以作为该像素的负样本类别;而对于无标签样本,由于伪标签可能存在错误,因此我们并不完全却行确信标签的正确性,因而我们需要将预测概率最高的几个类别过滤掉,将该像素认作为剩下几个类别的负样本。这部分对应的是论文中公式 13-16。



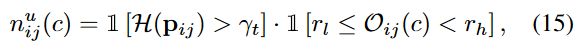
![]()
Oij=argsort(pij),就是排序后的p(负样本)
补充知识
InfoNCE Loss
对比学习常用的损失函数,多应用于自监督领域,就使用而言,可以简单概括为用cosine对一个batch的样本做交叉熵

- NCE
**NCE(noise contrastive estimation,噪声对比估计)**核心思想是将多分类问题转化成二分类问题,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是“噪声对比(noise contrastive)”,从而发现数据中的一些特性。但是,如果把整个数据集剩下的数据都当作负样本(即噪声样本),虽然解决了类别多的问题,计算复杂度还是没有降下来,解决办法就是做负样本采样来计算loss,这就是estimation的含义,也就是说它只是估计和近似。一般来说,负样本选取的越多,就越接近整个数据集,效果自然会更好。

关于温度:温度系数可以来控制模型对负样本的区分度。具体来说,温度系数越大,模型对负样本的区分度越低,可以纳入更多的负样本;温度t越小,正负样本之间区分性越高,会更加关注那些特别困难的负样本,loss越小。一般来说t小的好,可以更聚焦到有难度的负例,但是,温度参数也不是越小越好。由于在进行数据学习时,我们使用的是无监督,负例中有可能会存在一些潜在的正例,如果参数太小会导致比较近的潜在正例被推开,这样是不正确的。
OHEM
OHEM:online hard example mining,在线困难样本挖掘算法训练Region-based Object Detectors
其优点:
1.对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强。
2.当数据集增大,算法可以在原来基础上提升更大。
当我们遇到数据集少,且目标检测positive proposal少时,可以试试OHEM这个trick
实验
- Dataset: PASCAL VOC 2012(train, val)、SBD(add train)、Cityscapes
- backbone: ImageNet上预训练的ResNet-101
- decoder: DeepLabv3+
分割头和表示头 都由两个Conv BN ReLU块组成,其中两个块都保留了特征图分辨率,第一个块将通道数量减半。分割头可以看作是一个像素级分类器,将ASPP模块输出的512维特征映射到C类中。表示头将相同的特征映射到256维表示空间中。
Comparison with Existing Alternatives
本文所有的实验结果均是基于 ResNet-101 + Deeplab v3+ 的网络结构完成的,所采用的的数据集构成和评估方式请参见论文描述。
我们在 Classic VOC, Blender VOC, Cityscapes 三种数据集上均和现存方法进行了对比,在全部两个 PASCAL VOC 数据集上我们均取得了最佳精度。在 Cityscapes 数据集上,由于我们没能很好地解决长尾问题,落后于致力解决类别不平衡问题的 AEL (NeurIPS’21),但我们将 U2PL 叠加在 AEL 上能够取得超越 AEL 的精度,也侧面证明了 U2PL 的通用性。 值得一提的是,U2PL 在有标签数据较少的划分下,精度表现尤为优异。

表1。在不同的划分设定下,与classic PASCAL VOC 2012 val数据集上与最先进的方法进行比较。标记的图像是从原始VOC序列集合中选择的,该集合总共由1464个样本组成。分数表示用于训练的标记数据的百分比,然后是图像的实际数量。来自SBD[18]的所有图像都被视为未标记的数据。“SupOnly”代表在不使用任何未标记数据的情况下进行监督培训。†意味着我们复制这种方法。

表2。在不同的划分设定下,在blender PASCAL VOC 2012 val数据集中与其他最先进方法的比较。所有标记的图像都是从增强VOC序列集中选择的,该序列集总共由10582个样本组成。“SupOnly”代表在不使用任何未标记数据的情况下进行监督培训。†意味着我们复制这种方法。

表3。在不同的分区协议下,与Cityscapes上的最先进方法进行比较。所有标记的图像都是从Cityscapes火车组中选择的,该火车组总共包括2975个样本。“SupOnly”代表在不使用任何未标记数据的情况下进行监督培训。†意味着我们复制这种方法。
Ablation
Effectiveness of Using Unreliable Pseudo-Labels
我们在 PSACAL VOC 和 CItyscapes 等多个数据集的多个划分上验证了使用不可靠伪标签的价值。

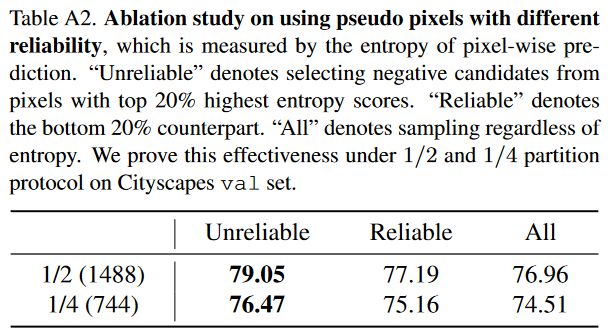
表4。使用具有不同可靠性的伪像素的消融实验,其通过逐像素预测的熵来衡量(见第3.3节)。“不可靠性”表示从熵得分最高20%的像素中选择负样本候选者。“可靠”表示最底层的20%。“全部”表示不考虑熵的采样。
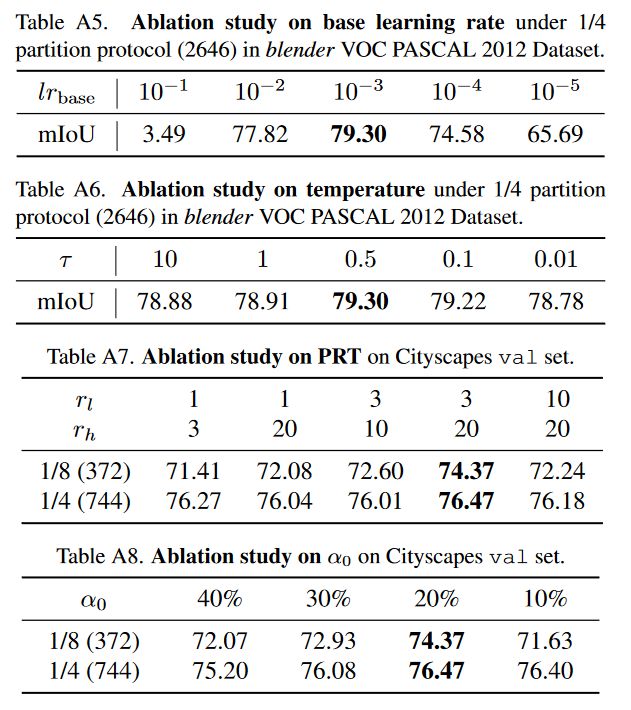
概率等级阈值的有效性。也就是刚刚公式里的rl和rh,rl=3和rh=20在很大程度上优于其他选项。当rl=1时,假阴性候选者不会被过滤掉,导致像素的类内特征被Lc错误地区分。当rl=10时,阴性候选者往往在语义上与相应的锚像素无关,使这种区分的信息量较小。
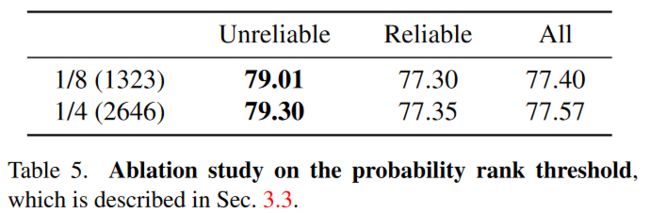
表5。概率等级阈值的消融实验,如第3.3节所述。
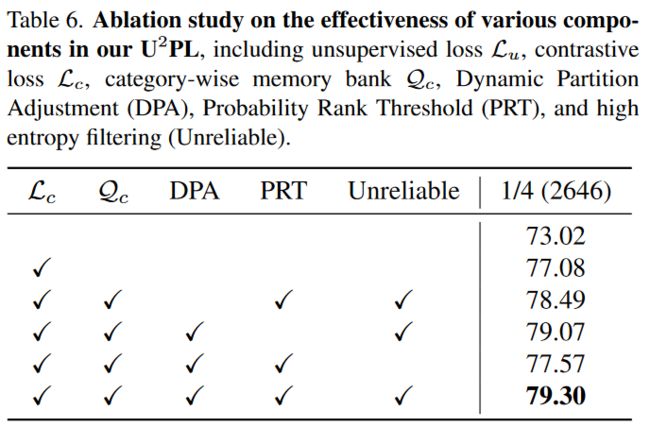
表6。对U2PL中各种成分的有效性进行消融研究,包括无监督损失Lu、对比损失Lc、类别记忆库Qc、动态分区调整(DPA)、概率等级阈值(PRT)和高熵滤波(不可靠)。

表7。方程中α0的消融研究。(7),控制可靠和不可靠像素之间的初始比例
Alternative of Contrastive Learning
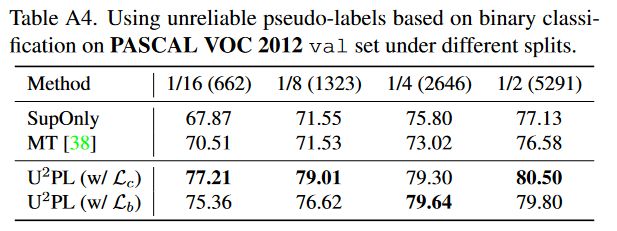
我们增加了通过二分类去利用不可靠样本的对比实验,证明利用低质量伪标签并不是只能通过对比学习去实现,只要利用好低质量样本,即使是二分类方法也能取得不错的精度提升。
总结
- Conclusion
我们提出了一个半监督语义分割框架U2PL,通过在训练中加入不可靠的伪标签,该框架优于许多现有的方法,这表明我们的框架在半监督学习研究中提供了一个新的有前途的范式。我们的消融实验证明了这项工作的洞察力是相当扎实的。定性结果为其有效性提供了直观的证明,尤其是在语义对象或其他模糊区域之间的边界上具有更好的性能。与完全监督的方法相比,我们的方法的训练是耗时的[5,6,29,35,46],这是半监督学习任务的常见缺点[9,20,21,33,43,48]。由于标签的极度缺乏,半监督学习框架通常需要及时付出代价才能获得更高的准确性。未来可以对他们的训练优化进行更深入的探索。
- 可视化

图4。PASCAL VOC 2012价值集的定性结果。所有模型都是在混合器集的1/4分割协议下训练的,该协议包含2466个标记图像和7396个未标记图像。(a) 输入图像。(b) 相应图像的手动注释标签。(c) 只有标记的图像用于训练,而没有任何未标记的数据。(d) 香草对比学习框架,其中所有像素都用作负样本,无需熵滤波。(e) 我们U2PL的预测。黄色矩形突出显示了通过充分使用不可靠的伪标签来促进分割结果。
附录
附录A:再产生结果的更多细节将在中给出
附录B:中从两个角度给出更多关于Cityscapes的结果
附录C:提供了对比学习的替代方案,以证明我们的主要见解不仅仅依赖于对比学习
附录D:更多超参数的PASCAL VOC 2012和Cityscapes消融研究
附录E:特征空间上的可视化为U2PL的有效性提供了视觉证明

表A1。U2PL中使用的超参数摘要。
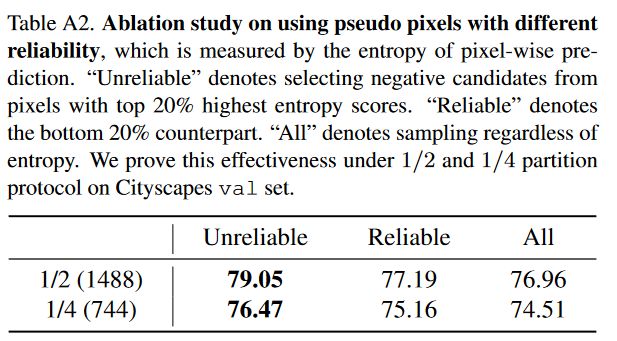
表A2。使用不同可靠性的伪像素的消融研究,通过逐像素预测的熵来衡量。“不可靠”表示从熵得分最高20%的像素中选择负面候选者。“可靠”表示最底层的20%。“全部”表示不考虑熵的采样。我们在Cityscapes val集的1/2和1/4分区协议下证明了这种有效性。
U2PL不受对比学习的限制。二进制分类也是使用不可靠伪标签的充分方式,即使用二进制交叉熵损失(BCE)Lb而不是对比损失。对于第i个锚点zci属于c类,我们简单地使用其负样本{z−cij}Nj=1和正样本zc+来计算BCE损失:


表A3。在不同的分区协议下,在Cityscapes val集上使用基于二进制分类的不可靠伪标签。

表A4。在不同拆分下,在PASCAL VOC 2012 val集上使用基于二进制分类的不可靠伪标签。
- 更多的消融的实验
TabA5:lr的消融;TabA6:温度系数的消融
TabA7/8:对Cityspace数据集的概率等级阈值和α0进行了研究。
U2PL 与 negative learning 的区别
negative learning 选用的负样本依旧是高置信度的可靠样本,相比之下U2PL 则提倡充分利用不可靠样本而不是把它们过滤掉。
比如说预测结果 p=[0.3,0.3,0.2,0.1,0.1]T 由于其不确定性会被 negative learning 方法丢弃,但在 U2PL 中却可以被作为多个 unlikely class 的负样本,实验结果也发现 negative learning 方法的精度不如 U2PL。
U2PL 技术蓝图
这里贴出技术蓝图,便于大家更好地理解论文的核心 story 和实验设计