JAVA架构知识总结
JAVA
- 通讯
-
- 通讯协议
- HTTP
- IO
- 计算机网络面试题
- 设计模式
-
- 七大设计原则
- 设计模式
- JAVA基础加强
-
- 基础
- 多线程
- 登录
- 数据库
- Spring
- spring boot
-
- 和Spring区别
- springboot启动加载
- spring cloud
-
- Ribbon:负载。
- OpenFeign:声明式伪RPC。
- Eureka
- Config
- Hystrix
- GeteWay
- Slueth 链路追踪
- [spring cloud alibaba](https://blog.csdn.net/u011627218/article/details/121909029)
- 算法
- 问题
- 源码分析
- 技术点分析
-
- 网络
- java基础
- spring
- springboot的优势
- 数据库
- 多线程
- spring cloud
通讯
通讯协议
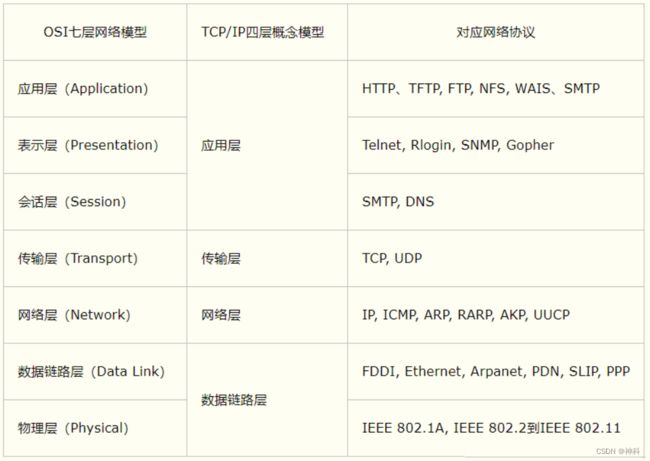
- OSI七层

1.1、物理层:通信道上的原始比特流传输。例如网线、光纤
1.2、数据链路层:物理寻址,同时将原始比特流转变成逻辑传输线路。例如:交换机
1.3、网络层:控制子网的运行,将网路地址转换成物理地址。例如:路由器
1.4、传输层:数据包分隔。例如:TCP协议和UDP协议
1.5、会话层:不同机器上用户之间建立管理通讯。例如:LINUX和WINDOW的传输
1.6、表示层:语法的定义和关联。例如:加密、解密
1.7、应用层:各种应用程序协议。例如:HTTP、FTP
-
负载
2.1、四层负载:LVS、F5
2.2、七层负载:Nginx、Haproxy -
TCP流量控制和拥塞控制
3.1、TCP流量控制:TCP的流量控制由滑动窗口来实现,滑动窗口控制流量取决于接收方的窗口大小。
3.2、拥塞控制:慢启动、拥塞避免、快速重传和快速恢复 -
TCP和UDP区别
4.1、Tcp面向连接,Udp无连接
4.2、Tcp更可靠,面向字节流;Udp快,没有拥塞控制,面向报文
4.3、Tcp保证数据正确性,和数据顺序;Udp不保证
4.4、Tcp请求头20个字节,Udp8个字节 -
TCP长连接和短连接区别
-
TCP连接三次握手和端口四次握手
-
排查TIME_WATI和CLOSE_WAIT:
查看TIME_WAIT状态:netstat -an|grep TIME_WAIT
统计:netstat -ant|awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}'
查看CLOSE_WAIT状态 netstat -n | awk '/^tcp/{++S[$NF]}END{for(a in s) print a,s[a]}' 导致too many open files
- 修改内核参数:


HTTP
- 简介Http
- keep-alive:
2.1、http keep-alive是为了让tcp获得更久一点,在http1.0协议,以便在同一个联机上传多个http,提高socket效率
2.2、tcp keep-alive是TCP的一种检测TCP连接状态的保险机制
/proc/sys/net/ipv4/tcp_keepalive_time 闲置时间超过
/proc/sys/net/ipv4/tcp_keepalive_intvl 尝试发送侦测包
/proc/sys/net/ipv4/tcp_keepalive_probes 尝试这么多次,没有收到ack,丢弃TCP连接
2.3、nginx优化keep-alive
IO
-
select、poll、epoll详解
-
进程之间的通信方式:
2.1、管道
2.2、消息队列
2.3、共享内存
2.4、信号量
2.5、socket -
IO模型
3.1、BIO -> NIO ->AIO
3.1.1、阻塞IO(BIO:
等待阻塞,线程交出CPU
socket.read()
3.1.2、非阻塞IO:
不等待,循环询问不交出CPU
whlie(true){socked.read()}
3.1.3、多路复用IO(NIO):
通过selector.select()去查询每个通道是否有到达时间
轮询每个socket状态是在内核中进行的,非阻塞IO询问socket状态是通过用户线程去进行的
3.1.4、信号驱动IO模型:
用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。一般用UDP,TCP没用
3.1.5、异步IO模型(AIO):
真正的异步IO需要操作系统更强的支持。 IO多路复用模型中,数据到达内核后通知用户线程,用户线程负责从内核空间拷贝数据; 而在异步IO模型中,当用户线程收到通知时,数据已经被操作系统从内核拷贝到用户指定的缓冲区内,用户线程直接使用即可
3.2、Netty:采用NIO
3.2.1、Reactor线程模型
(1)定义:一种时间驱动处理模型,类似于多路复用IO模型,包括三种角色:Reactor、Acceptor和Handler
①Reactor:监听事件,包括建立、读就绪、写就绪等,针对监听到的不同事件,将它们分给对应的线程处理
②Acceptor:处理客户端建立的连接
③Handler:对读写事件进行业务处理
(2)消息处理的流程
①Reactor:通过多路复用器监听IO事件
②如果建立连接事件,由Acceptor线程接受连接,并创建Handler来处理之后连接上的读写事件
③如果是读写事件,则Reactor会调用该连接上的handler进行业务处理
(3)三种模式
①单Reactor单线程模式:由一个线程来进行事件监控和时间处理
②单Reactor多线程模式:对于连接上的读写事件,使用线程池中的线程来进行该连接上的Handler操作,读写事件不会阻塞Reactor线程
③主从Reactor多线程模式:在单Reactor多线程模式的基础上,使用两个Reactor线程分别对建立连接事件和读写事件进行监听,每个Reactor线程拥有一个多路复用器。当主Reactor线程监听到连接建立事件后,创建SocketChannel,然后将SocketChannel注册到子Reactor线程的多路复用器中,使子Reactor线程监听连接的读写事件。
3.2.2、零拷贝
3.2.3、TCP粘包/拆包的原因及解决方法

3.2.4、服务端

3.2.5、客户端

3.2.6、用NIO不用AIO
(1)netty整体架构是reactor模型,AIO是proactor模型
(2)linux系统 AIO不够成熟,处理回调的结果速度更不上处理需求,供不应求,造成处理速度瓶颈,底层实现仍用Epoll,性能没有优势
(3)AIO预先分配缓存区,对连接数量非常大,浪费内存
(4)NIO中将多路请求注册在多路选择复用器上,线程轮询请求状态
(5)AIO每个请求一开始就分配一个线程,导致线程过多
计算机网络面试题
设计模式
七大设计原则
开闭原则
一、定义:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。抽象约束,封装变化
二、优点:提高软件系统的可复用性及可维护性
依赖倒转原则
一、定义:通过要面向接口的编程来降低类间的耦合性。
高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象(High level modules shouldnot depend upon low level modules.Both should depend upon abstractions.Abstractions should not depend upon details. Details should depend upon abstractions)。其核心思想是:要面向接口编程,不要面向实现编程。
二、优点:
单一职责原则
三、定义:不要存在多于一个导致类变更的原因。
接口隔离原则
一、定义:用多个专门的接口,而不是使用单一总接口,客户端不应该依赖它不需要的接口。
迪米特法则
一、定义:一个对象应该对其他对象保持最少的了解
二、优点:降低类之间的耦合
里式替换原则
一、定义:里氏替换原则是继承复用的基础,它反映了基类与子类之间的关系,是对开闭原则的补充,是对实现抽象化的具体步骤的规范。子类可以扩展父类的功能,但不能改变父类原有的功能。也就是说:子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法
二、优点:
里氏替换原则是实现开闭原则的重要方式之一。
它克服了继承中重写父类造成的可复用性变差的缺点。
它是动作正确性的保证。即类的扩展不会给已有的系统引入新的错误,降低了代码出错的可能性。
合成聚合复用原则
一、定义:尽量使用对象组合、聚合、而不是继承关系达到软件复用的目的 聚合:has-a、组合:contains-a、继承:is-a
二、优点:
可以使系统更加灵活,降低类与类之间的耦合度,
一个类的变化对其他类造成的影响相对较少
设计模式
工厂模式
简单工厂:
定义:通过实例化一个工厂类,来获取对应的产品实例。我们不需要关注产品本身如何被创建的细节,只需要通过相应的工厂就可以获得相应的实例。简单工厂包括三种角色:
1.工厂:简单工厂模式的核心,它负责实现创建所有实例的内部逻辑。工厂类的创建产品类 的方法可以被外界直接调用,创建所需的产品对象。
2.抽象产品 :简单工厂模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口。
3.具体产品:是简单工厂模式的创建目标,所有创建的对象都是充当这个角色的某个具体类的实例。
优点:
工厂方法模式
定义:是指定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类,工厂方法让类的实例化推迟到子类中进行 。
优点:
简单工厂是产品的工厂,工厂方法是工厂的工厂
抽象工厂模式
简单工厂解决的是横向的产品族,工厂方法解决的是纵向的产品等级,抽象工厂解决两者
单例模式
一、饿汉式
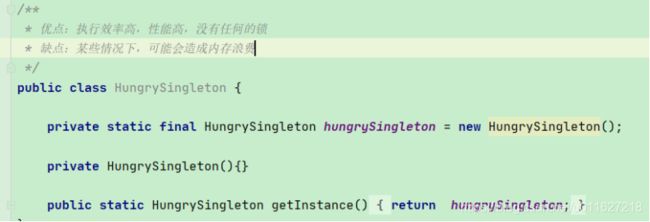

缺点:某种情况浪费内存
二、懒汉式
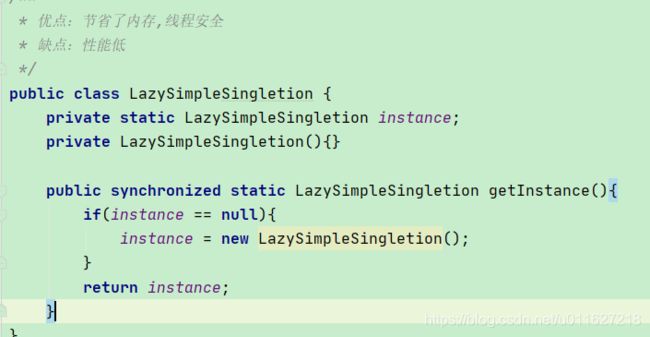
单例模式 懒汉模式注意:
1)、双重校验:两个线程同时竞争锁后,当一个线程竞争到锁后初始化,另外一个线程竞争到后,又去初始化了;
2)、对象属性volitile定义,当一个线程初始化后,指令重排序,先给对象内存空间,另外一个线程判断不为空,返回了结果,第一个线程没有初始化后

内部静态类不是加载class后就调用,不被反射破坏(构造判断)

三、注册式单例
定义:将每一个实例都缓存到统一的容器中,使用唯一标识获取实例
reflect方法不能反射枚举
初始化类就构造枚举

四、ThreadLocal

五、总结
1、优点
(1)在内存中只有一个实例,减少了内存的开销
(2)可以避免对资源的多重占用
(3)设置全局访问点,严格控制访问
2、缺点
(1)没有接口,扩展困难
(2)如果要扩展单例对象,只有修改代码,没有其他途径
3、总结
(1)私有化构造器
(2)保证线程安全
(3)延迟加载
(4)防止序列化和反序列化破坏单例
(5)防御反射攻击单例
模板方法模式
HttpSerlet doget dopost
责任链模式
Tomacat filter
代理模式
静态代理
动态代理
JAVA基础加强
基础
一、Volatile与Synchronized的区别
(1)、volatile只能作用于变量,使用范围较小。synchronized可以用在变量、方法、类、同步代码块等,使用范围比较广。
(2)、volatile只能保证可见性和有序性,不能保证原子性。而可见性、有序性、原子性synchronized都可以包证。
(3)、volatile不会造成线程阻塞。synchronized可能会造成线程阻塞。
(4)、在性能方面synchronized关键字是防止多个线程同时执行一段代码,就会影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized。
多线程
多线程基础知识
三、查看堆栈:
1、jsp:查看当前java进程的pid
2、jstack pid:查看pid对应进程的堆栈信息
四、状态(运行和就绪反了),操作系统层面没有new和terminated状态
五、Thread.start过程:调用native start0方法
java new thread start -> native start0方法 -> JVM->根据不同操作系统 -> OS ->调度算法 ->cpu
-> thread.run -> JVM -> run -> Java ->jvm销毁
六、终止线程
4.1、正常运行结束
4.2、stop:Java的API中明确了Thread.stop()方法已经被弃用了
该方法具有固有的不安全性。用 Thread.stop 来终止线程将释放它已经锁定的所有监视器(作为沿堆栈向上传播的未检查 ThreadDeath 异常的一个自然后果)。如果以前受这些监视器保护的任何对象都处于一种不一致的状态,则损坏的对象将对其他线程可见,这有可能导致任意的行为。stop 的许多使用都应由只修改某些变量以指示目标线程应该停止运行的代码来取代。目标线程应定期检查该变量,并且如果该变量指示它要停止运行,则从其运行方法依次返回。如果目标线程等待很长时间(例如基于一个条件变量),则应使用 interrupt 方法来中断该等待。
输出结果为:i=1,j=0
4.3、interrupt:设置中断标志。(此线程不一定是当前线程,而是指调用该方法的Thread实例所代表的线程),但实际上只是给线程设置一个中断标志,线程仍会继续运行。本质是通过共享变量实现线程间的通信:volitile int interrupted
七、count++
1、count=0 寄存器
2、count++
3、count=1 写入内存
八、迭代
九、dd
CAS
https://blog.csdn.net/u011506543/article/details/82392338
http://www.blogjava.net/mstar/archive/2013/04/24/398351.html
从思想上来说
Synchronized属于悲观锁,悲观地认为程序中的并发情况严重,所以严防死守。
CAS属于乐观锁,乐观地认为程序中的并发情况不那么严重,所以让线程不断去尝试更新。
缺点:
1.CPU开销较大
在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,循环往复,会给CPU带来很大的压力。
2.不能保证代码块的原子性
CAS机制所保证的只是一个变量的原子性操作,而不能保证整个代码块的原子性。比如需要保证3个变量共同进行原子性的更新,就不得不使用Synchronized了。
锁
https://mp.weixin.qq.com/s/9gt1rj5y1V8u_Ge4rVVY4A
Lock
1、ReentrantLock:(轻量级锁)也可以叫对象锁,可重入锁,互斥锁。synchronized重量级锁,JDK前期的版本lock比synchronized更快,在JDK1.5之后synchronized引入了偏向锁,轻量级锁和重量级锁。以致两种锁性能旗鼓相当,看个人喜欢
LOCK.lock(): 此方式会始终处于等待中,即使调用B.interrupt()也不能中断,除非线程A调用LOCK.unlock()释放锁。
LOCK.lockInterruptibly(): 此方式会等待,但当调用B.interrupt()会被中断等待,并抛出InterruptedException异常,否则会与lock()一样始终处于等待中,直到线程A释放锁。
LOCK.tryLock(): 该处不会等待,获取不到锁并直接返回false,去执行下面的逻辑。
LOCK.tryLock(10, TimeUnit.SECONDS):该处会在10秒时间内处于等待中,但当调用B.interrupt()会被中断等待,并抛出InterruptedException。10秒时间内如果线程A释放锁,会获取到锁并返回true,否则10秒过后会获取不到锁并返回false,去执行下面的逻辑
lock和tryLock的区别:
1: lock拿不到锁会一直等待。tryLock是去尝试,拿不到就返回false,拿到返回true。
2: tryLock是可以被打断的,被中断的,lock是不可以。
源码分析:
1.1、构造函数:是否公平锁 true-公平锁,false-非公平锁(默认)
1.2、非公平锁
如果获取到锁,继续(保证吞吐量)
如果没有获取到锁的线程,添加到AQS队列尾部:如果AQS只有当前线程节点,不挂起;否则移除当前线程节点前CACELLED节点,修改其他节点state=SIGNAL,当前线程节点挂起
(1)、cas 乐观锁获取锁并修改:state=0->1,exclusiveOwnerThread =thread;CAS:只允许一个线程进入
(2)、如果有多线程cas 失败,等待线程构造线程节点到AQS队列中:acquire方法
1.2.1、tryAcquire:如果抢占到锁或者重入锁,继续跳出判断acquireQueue
1.2.2、addWaiter(Node.EXCLUSIVE), arg)创建等待线程节点
首次轮询进入enq(node):当前AQS队列没有节点,创建空节点,并指向当前线程节点(双向链表)
1.2.3、acquireQueued:如果AQS只有当前线程节点,不挂起;否则移除当前线程节点去前CACELLED节点,修改其他节点state=SIGNAL,当前线程节点 LockSupport.park(this)阻塞挂起,并自旋直到抢占到锁
1.2.4、如果自旋抢占到锁,1:设置head节点next=null,2:设置当前线程节点为head节点,并设置node.thread=null,node.prev=null
1.2.5、 selfInterrupt:lock获取锁过程中,忽略了中断(即1.2.3、acquireQueued 挂起当前节点时),在成功获取锁之后,再根据中断标识处理中断,即selfInterrupt中断自己,往上传递
1.2.5、unlock:1:释放锁。修改state状态为0,exclusiveOwnerThread =null;2:唤醒AQS消息队列的watstatus =SINGNAL节点
1.2.4.1:释放锁。修改state状态为0,exclusiveOwnerThread =null
1.2.4.2:唤醒AQS消息队列的watstatus =SINGNAL节点
1.3、公平锁
1.4、公平锁和非公平锁区别
1.4.1、lock获取锁。公平锁:AQS没有等待队列才CAS抢占,非公平锁:第一步先CAS抢占,抢占不到在添加到AQS队列尾节点
2、ReentrantReadWriteLock:(可重入读写锁) 需要分析源码 https://www.cnblogs.com/xiaoxi/p/9140541.html
(1)可重入:同一个线程可以重复加锁,每次加锁的时候count值加1,每次释放锁的时候count减1,直到count为0,其他的线程才可以再次获取
(2)读写分离:读写两把不同的锁
(3)读锁可重复获取
1)读锁
2)写锁
(4)可以锁降级(使用逻辑):线程获取写入锁后可以获取读取锁,然后释放写入锁,这样就从写入锁变成了读取锁,从而实现锁降级的特性
(5)不可锁升级(使用逻辑):线程获取读锁是不能直接升级为写入锁的。需要释放所有读取锁,才可获取写
synchronized
一、锁的范围
对象实例锁:实例
类锁:静态方法、类对象
代码块锁:方法
二、锁的存储
2.1、对象头
2.2、打印出来
pom引用
org.openjdk.jol
jol-core
0.10
代码:
System.out.println(ClassLayout.parseInstance(classLayoutDemo).toPrintable())
2.3、缺点,如果锁内容中用到类似hashcode膨胀至重量级锁
三、锁的升级
3.1、偏向锁
在大多数情况下,锁不仅仅不存在多线程的竞争,而且总是由同一个线程多次获得。在这个背景下就设
计了偏向锁。偏向锁,顾名思义,就是锁偏向于某个线程。
当一个线程访问加了同步锁的代码块时,会在对象头中存储当前线程的ID,后续这个线程进入和退出这
段加了同步锁的代码块时,不需要再次加锁和释放锁。而是直接比较对象头里面是否存储了指向当前线
程的偏向锁。如果相等表示偏向锁是偏向于当前线程的,就不需要再尝试获得锁了,引入偏向锁是为了
在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径。(偏向锁的目的是消除数据在无竞争情
况下的同步原语,进一步提高程序的运行性能。)
3.2、轻量级锁
如果偏向锁被关闭或者当前偏向锁已经已经被其他线程获取,那么这个时候如果有线程去抢占同步锁时,锁会升级到轻量级锁。
3.3、重量级锁
多个线程竞争同一个锁的时候,虚拟机会阻塞加锁失败的线程,并且在目标锁被释放的时候,唤醒这些线程;
Java 线程的阻塞以及唤醒,都是依靠操作系统来完成的:os pthread_mutex_lock() ;
升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态
每一个JAVA对象都会与一个监视器monitor关联,我们可以把它理解成为一把锁,当一个线程想要执行一段被synchronized修饰的同步方法或者代码块时,该线程得先获取到synchronized修饰的对象对应的monitor。
monitorenter表示去获得一个对象监视器。monitorexit表示释放monitor监视器的所有权,使得其他被阻塞的线程可以尝试去获得这个监视器
monitor依赖操作系统的MutexLock(互斥锁)来实现的,线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能
任意线程对Object(Object由synchronized保护)的访问,首先要获得Object的监视器。如果获取失败,线程进入同步队列,线程状态变为BLOCKED。当访问Object的前驱(获得了锁的线程)释放了锁,则该释放操作唤醒阻塞在同步队列中的线程,使其重新尝试对监视器的获取。
3.4、总结
偏向锁只有在第一次请求时采用CAS在锁对象的标记中记录当前线程的地址,在之后该线程再次进入同步代码块时,不需要抢占锁,直接判断线程ID即可,这种适用于锁会被同一个线程多次抢占的情况。
轻量级锁才用CAS操作,把锁对象的标记字段替换为一个指针指向当前线程栈帧中的LockRecord,该工件存储锁对象原本的标记字段,它针对的是多个线程在不同时间段内申请通一把锁的情况。
重量级锁会阻塞、和唤醒加锁的线程,它适用于多个线程同时竞争同一把锁的情况。
wait、notify、notifyall
https://www.jianshu.com/p/25e243850bd2?appinstall=0
1、多线程wait 和 notify的判断条件用while,不用if(假死)
(1)if(){…},如果说程序在判断完满足if条件之后,那么就会进入大括号里面,即使在里面等待一段时间之后,我们也是会直接出来。
(2)while(){…}如果说满足了条件,那么就会进入大括号里面,在里面呆了一段时间,要想出来那得先去while判断一下,如果满足,还是不能出来。
2、结尾处的为什么要用notifyAll()方法,不用notify()
其实这是一个对象内部锁的调度问题,要回答这两个问题,首先我们要明白java中对象锁的模型,JVM会为一个使用内部锁(synchronized)的对象维护两个集合,Entry Set和Wait Set,也有人翻译为锁池和等待池,意思基本一致。
对于Entry Set:如果线程A已经持有了对象锁,此时如果有其他线程也想获得该对象锁的话,它只能进入Entry Set,并且处于线程的BLOCKED状态。
对于Wait Set:如果线程A调用了wait()方法,那么线程A会释放该对象的锁,进入到Wait Set,并且处于线程的WAITING状态。
还有需要注意的是,某个线程B想要获得对象锁,一般情况下有两个先决条件,一是对象锁已经被释放了(如曾经持有锁的前任线程A执行完了synchronized代码块或者调用了wait()方法等等),二是线程B已处于RUNNABLE状态。
那么这两类集合中的线程都是在什么条件下可以转变为RUNNABLE呢?
对于Entry Set中的线程,当对象锁被释放的时候,JVM会唤醒处于Entry Set中的某一个线程,这个线程的状态就从BLOCKED转变为RUNNABLE。
对于Wait Set中的线程,当对象的notify()方法被调用时,JVM会唤醒处于Wait Set中的某一个线程,这个线程的状态就从WAITING转变为RUNNABLE;或者当notifyAll()方法被调用时,Wait Set中的全部线程会转变为RUNNABLE状态。所有Wait Set中被唤醒的线程会被转移到Entry Set中。
然后,每当对象的锁被释放后,那些所有处于RUNNABLE状态的线程会共同去竞争获取对象的锁,最终会有一个线程(具体哪一个取决于JVM实现,队列里的第一个?随机的一个?)真正获取到对象的锁,而其他竞争失败的线程继续在Entry Set中等待下一次机会。
耐心看下面这个两个生产者两个消费者的场景,如果我们代码中使用了notify()而非notifyAll(),假设消费者线程1拿到了锁,判断buffer为空,那么wait(),释放锁;然后消费者2拿到了锁,同样buffer为空,wait(),也就是说此时Wait Set中有两个线程;然后生产者1拿到锁,生产,buffer满,notify()了,那么可能消费者1被唤醒了,但是此时还有另一个线程生产者2在Entry Set中盼望着锁,并且最终抢占到了锁,但因为此时buffer是满的,因此它要wait();然后消费者1拿到了锁,消费,notify();这时就有问题了,此时生产者2和消费者2都在Wait Set中,buffer为空,如果唤醒生产者2,没毛病;但如果唤醒了消费者2,因为buffer为空,它会再次wait(),这就尴尬了,万一生产者1已经退出不再生产了,没有其他线程在竞争锁了,只有生产者2和消费者2在Wait Set中互相等待,那传说中的死锁就发生了。
但如果你把上述例子中的notify()换成notifyAll(),这样的情况就不会再出现了,因为每次notifyAll()都会使其他等待的线程从Wait Set进入Entry Set,从而有机会获得锁。
其实说了这么多,一句话解释就是之所以我们应该尽量使用notifyAll()的原因就是,notify()非常容易导致死锁。当然notifyAll并不一定都是优点,毕竟一次性将Wait Set中的线程都唤醒是一笔不菲的开销,如果你能handle你的线程调度,那么使用notify()也是有好处的。
volatile
一、思考
jrt优化成:
if(stop){
while(true){
i++;
}
}
阻止jrt优化:
1、系统参数:-Djava.compiler = NONE
2、synchronized:sout、syschronized()
3、IO:new File(“”)
4、官方说自由加载stop值,Thread.sleep(0)会导致线程切换,资源重新竞争
https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.3
在这段代码中,我们增加Thread.sleep(0)也能生效,这个我认为是和cpu、以及jvm、操作系统等因素有关系。
官方文档上是说,Thread.sleep没有任何同步语义,编译器不需要在调用Thread.sleep之前把缓存在寄存器中的写刷新到给共享内存、也不需要在Thread.sleep之后重新加载缓存在寄存器中的值。编译器可以自由选择读取stop的值一次或者多次,这个是由编译器自己来决定的。
但是在Mic老师认为:Thread.sleep(0)导致线程切换,线程切换会导致缓存失效从而读取到了新的值。
5、volitile定义i变量或者stop变量
二、汇报指令
使用volatile关键字之后,多了一个Lock指令
三、总线锁和缓存锁
1、总线锁
总线锁,简单来说就是,在多cpu下,当其中一个处理器要对共享内存进行操作的时候,在总线上发出一个LOCK#信号,这个信号使得其他处理器无法通过总线来访问到共享内存中的数据,总线锁定把CPU和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,所以总线锁定的开销比较大,这种机制显然是不合适的 。
如何优化呢?最好的方法就是控制锁的保护粒度,我们只需要保证对于被多个CPU缓存的同一份数据是一致的就行。在P6架构的CPU后,引入了缓存锁,如果当前数据已经被CPU缓存了,并且是要协会到主内存中的,就可以采用缓存锁来解决问题。
2、缓存锁
所谓的缓存锁,就是指内存区域如果被缓存在处理器的缓存行中,并且在Lock期间被锁定,那么当它执行锁操作回写到内存时,不再总线上加锁,而是修改内部的内存地址,基于缓存一致性协议来保证操作的原子性。
3、注意:总线锁和缓存锁怎么选择,取决于很多因素,比如CPU是否支持、以及存在无法缓存的数据时(比较大或者快约多个缓存行的数据),必然还是会使用总线锁。
四、缓存一致性
为了达到数据访问的一致,需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,常见的协议有MSI,MESI,MOSI等。最常见的就是MESI协议。
MESI表示缓存行的四种状态,分别是
- M(Modify) 表示共享数据只缓存在当前CPU缓存中,并且是被修改状态,也就是缓存的数据和主内存中的数据不一致
- E(Exclusive) 表示缓存的独占状态,数据只缓存在当前CPU缓存中,并且没有被修改
- S(Shared) 表示数据可能被多个CPU缓存,并且各个缓存中的数据和主内存数据一致
- I(Invalid) 表示缓存已经失效
五、MESI优化 stiore bufferes
Store Bufferes是一个写的缓冲,对于上述描述的情况,CPU0可以先把写入的操作先存储到StoreBufferes中,Store Bufferes中的指令再按照缓存一致性协议去发起其他CPU缓存行的失效。而同步来说CPU0可以不用等到Acknowledgement,继续往下执行其他指令,直到收到CPU0收到Acknowledgement再更新到缓存,再从缓存同步到主内存。
六、MESI优化引发指令重排序
七、不能保证原子性,两个线程i++
八、应用:单例 double判空
hashmap
https://blog.csdn.net/woshimaxiao1/article/details/83661464
一、什么是哈希表
在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下(后面会探讨下哈希冲突的情况),仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
这个函数可以简单描述为:存储位置 = f(关键字) ,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
插入过程如下图所示
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
二、HashMap的实现原理
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。(其实所谓Map其实就是保存了两个对象之间的映射关系的一种集合)
//HashMap的主干数组,可以看到就是一个Entry数组,初始值为空数组{},主干数组的长度一定是2的次幂。//至于为什么这么做,后面会有详细分析。transient Entry
1
2
3
Entry是HashMap中的一个静态内部类。代码如下
static class Entry
final K key;
V value;
Entry
int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
所以,HashMap的总体结构如下:
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
其他几个重要字段
/*实际存储的key-value键值对的个数/transient int size;
/**阈值,当table == {}时,该值为初始容量(初始容量默认为16);当table被填充了,也就是为table分配内存空间后,
threshold一般为 capacityloadFactory。HashMap在进行扩容时需要参考threshold,后面会详细谈到/int threshold;
/**负载因子,代表了table的填充度有多少,默认是0.75
加载因子存在的原因,还是因为减缓哈希冲突,如果初始桶为16,等到满16个元素才扩容,某些桶里可能就有不止一个元素了。
所以加载因子默认为0.75,也就是说大小为16的HashMap,到了第13个元素,就会扩容成32。
*/final float loadFactor;
/*HashMap被改变的次数,由于HashMap非线程安全,在对HashMap进行迭代时,
如果期间其他线程的参与导致HashMap的结构发生变化了(比如put,remove等操作),
需要抛出异常ConcurrentModificationException/transient int modCount;
HashMap有4个构造器,其他构造器如果用户没有传入initialCapacity 和loadFactor这两个参数,会使用默认值
initialCapacity默认为16,loadFactory默认为0.75
我们看下其中一个
public HashMap(int initialCapacity, float loadFactor) {
//此处对传入的初始容量进行校验,最大不能超过MAXIMUM_CAPACITY = 1<<30(230)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();//init方法在HashMap中没有实际实现,不过在其子类如 linkedHashMap中就会有对应实现
}
从上面这段代码我们可以看出,在常规构造器中,没有为数组table分配内存空间(有一个入参为指定Map的构造器例外),而是在执行put操作的时候才真正构建table数组
OK,接下来我们来看看put操作的实现
public V put(K key, V value) {
//如果table数组为空数组{},进行数组填充(为table分配实际内存空间),入参为threshold,
//此时threshold为initialCapacity 默认是1<<4(24=16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,存储位置为table[0]或table[0]的冲突链上
if (key == null)
return putForNullKey(value);
int hash = hash(key);//对key的hashcode进一步计算,确保散列均匀
int i = indexFor(hash, table.length);//获取在table中的实际位置
for (Entry
//如果该对应数据已存在,执行覆盖操作。用新value替换旧value,并返回旧value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//保证并发访问时,若HashMap内部结构发生变化,快速响应失败
addEntry(hash, key, value, i);//新增一个entry
return null;
}
inflateTable这个方法用于为主干数组table在内存中分配存储空间,通过roundUpToPowerOf2(toSize)可以确保capacity为大于或等于toSize的最接近toSize的二次幂,比如toSize=13,则capacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
private void inflateTable(int toSize) {
int capacity = roundUpToPowerOf2(toSize);//capacity一定是2的次幂
/**此处为threshold赋值,取capacity*loadFactor和MAXIMUM_CAPACITY+1的最小值,
capaticy一定不会超过MAXIMUM_CAPACITY,除非loadFactor大于1 */
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
roundUpToPowerOf2中的这段处理使得数组长度一定为2的次幂,Integer.highestOneBit是用来获取最左边的bit(其他bit位为0)所代表的数值.
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : “number must be non-negative”;
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
hash函数
/*这是一个神奇的函数,用了很多的异或,移位等运算
对key的hashcode进一步进行计算以及二进制位的调整等来保证最终获取的存储位置尽量分布均匀/final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
以上hash函数计算出的值,通过indexFor进一步处理来获取实际的存储位置
/**
* 返回数组下标
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
h&(length-1)保证获取的index一定在数组范围内,举个例子,默认容量16,length-1=15,h=18,转换成二进制计算为index=2。位运算对计算机来说,性能更高一些(HashMap中有大量位运算)
所以最终存储位置的确定流程是这样的:
再来看看addEntry的实现:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//当size超过临界阈值threshold,并且即将发生哈希冲突时进行扩容
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
通过以上代码能够得知,当发生哈希冲突并且size大于阈值的时候,需要进行数组扩容,扩容时,需要新建一个长度为之前数组2倍的新的数组,然后将当前的Entry数组中的元素全部传输过去,扩容后的新数组长度为之前的2倍,所以扩容相对来说是个耗资源的操作。
三、为何HashMap的数组长度一定是2的次幂?
我们来继续看上面提到的resize方法
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
如果数组进行扩容,数组长度发生变化,而存储位置 index = h&(length-1),index也可能会发生变化,需要重新计算index,我们先来看看transfer这个方法
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已)
for (Entry
while(null != e) {
Entry
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这个方法将老数组中的数据逐个链表地遍历,扔到新的扩容后的数组中,我们的数组索引位置的计算是通过 对key值的hashcode进行hash扰乱运算后,再通过和 length-1进行位运算得到最终数组索引位置。
HashMap的数组长度一定保持2的次幂,比如16的二进制表示为 10000,那么length-1就是15,二进制为01111,同理扩容后的数组长度为32,二进制表示为100000,length-1为31,二进制表示为011111。从下图可以我们也能看到这样会保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了之前已经散列良好的老数组的数据位置重新调换),个人理解。
还有,数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀
我们看到,上面的&运算,高位是不会对结果产生影响的(hash函数采用各种位运算可能也是为了使得低位更加散列),我们只关注低位bit,如果低位全部为1,那么对于h低位部分来说,任何一位的变化都会对结果产生影响,也就是说,要得到index=21这个存储位置,h的低位只有这一种组合。这也是数组长度设计为必须为2的次幂的原因。
如果不是2的次幂,也就是低位不是全为1此时,要使得index=21,h的低位部分不再具有唯一性了,哈希冲突的几率会变的更大,同时,index对应的这个bit位无论如何不会等于1了,而对应的那些数组位置也就被白白浪费了。
get方法:
public V get(Object key) {
//如果key为null,则直接去table[0]处去检索即可。
if (key == null)
return getForNullKey();
Entry
return null == entry ? null : entry.getValue();
}
get方法通过key值返回对应value,如果key为null,直接去table[0]处检索。我们再看一下getEntry这个方法
final Entry
if (size == 0) {
return null;
}
//通过key的hashcode值计算hash值
int hash = (key == null) ? 0 : hash(key);
//indexFor (hash&length-1) 获取最终数组索引,然后遍历链表,通过equals方法比对找出对应记录
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
可以看出,get方法的实现相对简单,key(hashcode)–>hash–>indexFor–>最终索引位置,找到对应位置table[i],再查看是否有链表,遍历链表,通过key的equals方法比对查找对应的记录。要注意的是,有人觉得上面在定位到数组位置之后然后遍历链表的时候,e.hash == hash这个判断没必要,仅通过equals判断就可以。其实不然,试想一下,如果传入的key对象重写了equals方法却没有重写hashCode,而恰巧此对象定位到这个数组位置,如果仅仅用equals判断可能是相等的,但其hashCode和当前对象不一致,这种情况,根据Object的hashCode的约定,不能返回当前对象,而应该返回null,后面的例子会做出进一步解释。
四、重写equals方法需同时重写hashCode方法
最后我们再聊聊老生常谈的一个问题,各种资料上都会提到,“重写equals时也要同时覆盖hashcode”,我们举个小例子来看看,如果重写了equals而不重写hashcode会发生什么样的问题
public class MyTest {
private static class Person{
int idCard;
String name;
public Person(int idCard, String name) {
this.idCard = idCard;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()){
return false;
}
Person person = (Person) o;
//两个对象是否等值,通过idCard来确定
return this.idCard == person.idCard;
}
}
public static void main(String []args){
HashMap map = new HashMap();
Person person = new Person(1234,"乔峰");
//put到hashmap中去
map.put(person,"天龙八部");
//get取出,从逻辑上讲应该能输出“天龙八部”
System.out.println("结果:"+map.get(new Person(1234,"萧峰")));
}}
实际输出结果:null5
如果我们已经对HashMap的原理有了一定了解,这个结果就不难理解了。尽管我们在进行get和put操作的时候,使用的key从逻辑上讲是等值的(通过equals比较是相等的),但由于没有重写hashCode方法,所以put操作时,key(hashcode1)–>hash–>indexFor–>最终索引位置 ,而通过key取出value的时候 key(hashcode1)–>hash–>indexFor–>最终索引位置,由于hashcode1不等于hashcode2,导致没有定位到一个数组位置而返回逻辑上错误的值null(也有可能碰巧定位到一个数组位置,但是也会判断其entry的hash值是否相等,上面get方法中有提到。)
所以,在重写equals的方法的时候,必须注意重写hashCode方法,同时还要保证通过equals判断相等的两个对象,调用hashCode方法要返回同样的整数值。而如果equals判断不相等的两个对象,其hashCode可以相同(只不过会发生哈希冲突,应尽量避免)。
五、JDK1.8中HashMap的性能优化
假如一个数组槽位上链上数据过多(即拉链过长的情况)导致性能下降该怎么办?
JDK1.8在JDK1.7的基础上针对增加了红黑树来进行优化。即当链表超过8时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
关于这方面的探讨我们以后的文章再做说明。
附:HashMap put方法逻辑图(JDK1.8)
数组长度保持2的次幂原因:
1、扩容h最左边差异0-1,保证得到的新数组索引和老数组索引一致,大大减少了之前已经散列的老数组部分位置重新调换
2、length-1的低位都为1,会使得数组的索引更加均匀
Condition
在使用Lock之前,我们使用的最多的同步方式应该是synchronized关键字来实现同步方式了。配合Object的wait()、notify()系列方法可以实现等待/通知模式。Condition接口也提供了类似Object的监视器方法,与Lock配合可以实现等待/通知模式,但是这两者在使用方式以及功能特性上还是有差别的。Object和Condition接口的一些对比。摘自《Java并发编程的艺术》
一、Condition接口介绍和示例
首先我们需要明白condition对象是依赖于lock对象的,意思就是说condition对象需要通过lock对象进行创建出来(调用Lock对象的newCondition()方法)。consition的使用方式非常的简单。但是需要注意在调用方法前获取锁。
public class ConditionUseCase {
public Lock lock = new ReentrantLock();
public Condition condition = lock.newCondition();
public static void main(String[] args) {
ConditionUseCase useCase = new ConditionUseCase();
ExecutorService executorService = Executors.newFixedThreadPool (2);
executorService.execute(new Runnable() {
@Override
public void run() {
useCase.conditionWait();
}
});
executorService.execute(new Runnable() {
@Override
public void run() {
useCase.conditionSignal();
}
});
}
public void conditionWait() {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "拿到锁了");
System.out.println(Thread.currentThread().getName() + "等待信号");
condition.await();
System.out.println(Thread.currentThread().getName() + "拿到信号");
}catch (Exception e){
}finally {
lock.unlock();
}
}
public void conditionSignal() {
lock.lock();
try {
Thread.sleep(5000);
System.out.println(Thread.currentThread().getName() + "拿到锁了");
condition.signal();
System.out.println(Thread.currentThread().getName() + "发出信号");
}catch (Exception e){
}finally {
lock.unlock();
}
}
}
输出结果:
1 pool-1-thread-1拿到锁了
2 pool-1-thread-1等待信号
3 pool-1-thread-2拿到锁了
4 pool-1-thread-2发出信号
5 pool-1-thread-1拿到信号
如示例所示,一般都会将Condition对象作为成员变量。当调用await()方法后,当前线程会释放锁并在此等待,而其他线程调用Condition对象的signal()方法,通知当前线程后,当前线程才从await()方法返回,并且在返回前已经获取了锁。
二、Condition接口常用方法
condition可以通俗的理解为条件队列。当一个线程在调用了await方法以后,直到线程等待的某个条件为真的时候才会被唤醒。这种方式为线程提供了更加简单的等待/通知模式。Condition必须要配合锁一起使用,因为对共享状态变量的访问发生在多线程环境下。一个Condition的实例必须与一个Lock绑定,因此Condition一般都是作为Lock的内部实现。
await() :造成当前线程在接到信号或被中断之前一直处于等待状态。
await(long time, TimeUnit unit) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
awaitNanos(long nanosTimeout) :造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。返回值表示剩余时间,如果在nanosTimesout之前唤醒,那么返回值 = nanosTimeout - 消耗时间,如果返回值 <= 0 ,则可以认定它已经超时了。
awaitUninterruptibly() :造成当前线程在接到信号之前一直处于等待状态。【注意:该方法对中断不敏感】。
awaitUntil(Date deadline) :造成当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态。如果没有到指定时间就被通知,则返回true,否则表示到了指定时间,返回返回false。
signal() :唤醒一个等待线程。该线程从等待方法返回前必须获得与Condition相关的锁。
signalAll ():唤醒所有等待线程。能够从等待方法返回的线程必须获得与Condition相关的锁。
三、Condition接口原理简单解析
Condition是AQS的内部类。每个Condition对象都包含一个队列(等待队列)。等待队列是一个FIFO的队列,在队列中的每个节点都包含了一个线程引用,该线程就是在Condition对象上等待的线程,如果一个线程调用了Condition.await()方法,那么该线程将会释放锁、构造成节点加入等待队列并进入等待状态。等待队列的基本结构如下所示。
等待分为首节点和尾节点。当一个线程调用Condition.await()方法,将会以当前线程构造节点,并将节点从尾部加入等待队列。新增节点就是将尾部节点指向新增的节点。节点引用更新本来就是在获取锁以后的操作,所以不需要CAS保证。同时也是线程安全的操作。
3.2、等待
当线程调用了await方法以后。线程就作为队列中的一个节点被加入到等待队列中去了。同时会释放锁的拥有。当从await方法返回的时候。一定会获取condition相关联的锁。当等待队列中的节点被唤醒的时候,则唤醒节点的线程开始尝试获取同步状态。如果不是通过 其他线程调用Condition.signal()方法唤醒,而是对等待线程进行中断,则会抛出InterruptedException异常信息。
await方法源码分析
3.2.1、新增等待节点 addConditionWatier()
3.2.2、释放锁 fullyRelease(Node node)
3.2.2.1、release(savedState)
3.2.2.2、释放AQS同步线程锁:tryRelease(arg)
3.2.2.3、唤醒AQS同步线程队列下一个阻塞线程
3.2.3、判断当前线程节点是否是Condition队列
3.2.3.1、判断当前线程节点是否在AQS队列中
3.2.3.2、遍历判断是否是AQS队列(该方法就是从Sync队列尾部开始判断,因为在isOnSyncQueue方法调用该方法时,node.prev一定不为null。但这时的node可能还没有完全添加到Sync队列中(因为node.next是null),这时可能是在自旋中。记得之前说过的enq方法吗,signal的时候会调用这个方法:compareAndSetHead -> compareAndSetTail)
3.3、通知
在调用signal()方法之前必须先判断是否获取到了锁。接着将会唤醒在等待队列中等待最长时间的节点(条件队列里的首节点),在唤醒节点前,会将节点移到同步队列中并且利用LockSupport唤醒节点中的线程。节点从等待队列移动到同步队列如下图所示:
signal方法源码分析
3.3.1、唤醒线程
3.3.1、唤醒线程 -> 将Condition队列线程增加到AQS队列尾部
3.3.1.1、唤醒线程 -> 将Condition队列线程增加到AQS队列尾部 ->实现
被唤醒的线程将从await方法中的while循环中退出。随后加入到同步状态的竞争当中去。成功获取到竞争的线程则会返回到await方法之前的状态。
四、总结
调用await方法后,将当前线程加入Condition等待队列中。当前线程释放锁。否则别的线程就无法拿到锁而发生死锁。自旋(while)挂起,不断检测节点是否在同步队列中了,如果是则尝试获取锁,否则挂起。当线程被signal方法唤醒,被唤醒的线程将从await()方法中的while循环中退出来,然后调用acquireQueued()方法竞争同步状态。
五、利用Condition实现生产者消费者模式
import java.util.LinkedList;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class BoundedQueue {
private LinkedList}
ConcurrentHashMap
https://www.cnblogs.com/zhaojj/p/8942647.html
红黑树空间复杂度O(log n)
链表空间复杂度O(n)
当hash表长度超过64、链表长度超过8,装成红黑树
不直接用红黑树,是因为红黑树维持平衡需要一定的开销,导致插入开销变大。按照keep it simple原则,所以节点少时使用更加简单的链表
put五个阶段
1、初始化阶段
2、第二阶段:如果cas失败自旋put
3、第三阶段
private transient volatile long baseCount; //在没有竞争的条件下,通过cas操作更新元素
private transient volatile CounterCell[] counterCells;//在线程竞争的情况下,存储元素个数
4、第四扩容阶段 ->高位迁移(n-1)&hash
HashMap与ConcurrentHashMap区别
3、计算hash值:
(1)hahsMap
(2)ConcurrentHashMap
与hashmap计算hash基本一样,但多了一步& HASH_BITS,HASH_BITS是0x7fffffff,该步是为了消除最高位上的负符号 hash的负在ConcurrentHashMap中有特殊意义表示在扩容或者是树节点
4、加锁
ConcurrentMap、GuavaCache、ehcache
https://mp.weixin.qq.com/s/QyX3ouEePWBoFsZWhcbVKg
阻塞对列BlockingQueue
抛出异常:add remove element
不抛出异常:off poll peek
阻塞:put take
一、LinkedBlockingDeque
二、ArrayBlokingQueue
CountDownLatch
CountDownLatch、CyclicBarrier、Semaphore区别
https://blog.csdn.net/liangyihuai/article/details/83106584
https://www.cnblogs.com/dolphin0520/p/3920397.html
1)CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;
而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
另外,CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
2)Semaphore其实和锁有点类似,它一般用于控制对某组资源的访问权限。
线程池
。
线程池执行线程Execute其实是创建Worker线程类,通过线程start触发worker的run方法
线程start调用线程实现类run方法
通触发线程实现类run方法调用runWorker(this)调用任务线程run
Future
future.get会等待run方法执行完成返回
happens-before模型
join
Join
1、调用wait方法阻塞主线程
2、源码:thread.cpp主线程运行完
-> javaThread:exit->ensure_join(this)唤醒当前线程阻塞下的线程->lock.notifyall
ThreadLocal
https://blog.csdn.net/u014532775/article/details/100904191
ThreadLocal 其实是为每个线程都提供一份变量的副本, 从而实现同时访问而不受影响。从这里也看出来了它和synchronized之间的应用场景不同, synchronized是为了让每个线程对变量的修改都对其他线程可见, 而 ThreadLocal 是为了线程对象的数据不受其他线程影响, 它最适合的场景应该是在同一线程的不同开发层次中共享数据。
一、get
1.1、获取ThreadLocal值,如果ThreadLocalMap有key返回value
1.2、如果ThreadLocalMap没有key,setInitialValue并返回null值
二、set
2.1、赋值,key是当前线程,如果map value值为null,set value;如果没有map,初始化map
2.2、ThreadLocalMap set方法
2.2.1、从ThreadLocalMap的定义可以看出Entry的key就是ThreadLocal,而value就是值。同时,Entry也继承WeakReference,所以说Entry所对应key(ThreadLocal实例)的引用为一个弱引用。而且定义了装载因子为数组长度的三分之二。
2.2.2、set主要步骤
2.2.2.1、采用线性探测法,寻找合适的插入位置。首先判断key是否存在,存在则直接覆盖。如果key不存在证明被垃圾回收了此时需要用新的元素替换旧的元素
2.2.2.2、不存在对应的元素,需要创建一个新的元素
2.2.2.3、清除entry不为空,但是ThreadLocal(entry的key被回收了)的元素,防止内存泄露
2.2.2.4、如果满足条件:size >= threshold - threshold / 4就将数组扩大为之前的两倍,同时会重新计算数组元素所处的位置并进行移动(rehash)。比如最开始数组初始大小为16,当size >= (16*2/3=10) - (10/4) = 8的时候就会扩容,将数组大小扩容至32.
2.2.3、无论是replaceStaleEntry()方法还是cleanSomeSlots()方法,最重要的方法调用是expungeStaleEntry(),你可以在ThreadLocalMap中的get,set,remove都能发现调用它的身影。
上面rehash的代码结合文章开头的说明理解起来更是容易,当从ThreadLocalMap新增,获取,删除的时候都会根据条件进行rehash,条件如下
(1)、ThreadLocal对象被回收,此时Entry中key为null,value不为null。这时会触发rehash
(2)、当阈值达到ThreadLocalMap容量的三分之二的时候
三、remove:remove的时候回删除旧的entry,然后进行rehash
1、线程隔离机制
2、ThreadMap HASH_INCREMENT(斐波那契函数)
3、ThreadMap key 弱引用
4、线性探测解决hash冲突问题:THreadMap向前查找回收(回收key=null,value!=null,直到没有key value),向后查找替换()
5、怎么解决内存泄漏问题
6、最好用完就remove
AtomicReference和AtomicStampedReference
https://blog.csdn.net/zxl1148377834/article/details/90079882?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
AtomicStampedReference通过时间戳解决CAS ABA问题
AtomicReference是作用是对”对象”进行原子操作
缓存一致性问题
1、
锁优化
1、减少锁的持有时间
2、减少锁的粒度
3、读写锁分离替代独占锁
4、锁的分离:链表
5、锁的粗化
一、比较
1.1、CyclicBarrier 和CountDownLatch比较
CountDownLatch:基于AQS共享模式
CyclicBarrier 基于Condition
二、
登录
一、Session统一存储
二、JWT生成token,基于token验证
2.1、jwt组成
2.1.1、head:
{
"alg": "HS256",
"typ": "JWT"
}
.
加密(摘要(原始数据))->数字签名 、摘要/指纹(Hash值,MD5)、加密(对称加密-HS256、非对称加密-公钥和私钥-RS256/ES256)
.
.
2.1.2、payload
{
"sub": "1234567890",
"name": "John Doe",
"iat": 1516239022
}
.
2.1.3、signature
2.2、
数据库
一、全局Id
数据库自增id、redis(increBy/incr)\mongdb(objectid)、uuid、雪花算法
要求:全局唯一性、有序的递增性、高可用性、时间上的特性
1.1、雪花算法:时间回拨重复问题

1.2、美团leaf
1.2.1、leaf-segment:缓存一次性拿取固定步长数值

1.2.2、leaf-snowflake:解决时间回拨问题
Spring
spring boot
和Spring区别
一、定义
spring框架为开发java引用程序提供全面基础架构支持,如依赖注入和开箱即用模块:spring jdbc、spring mvc、sping security、spring aop
spring boot是spring架构的扩展,消除了配置spring应用程序所需的xml配置要求
二、spring boot特征
1、创建独立的spring应用
BOOT-INF/classes:存放应用编译后的class文件;
BOOT-INF/lib:存放应用依赖的jar包;
META-INF/:存放应用相关元信息,如MANIFEST.MF文件;
org/:存放Spring Boot相关的class文件
2、嵌入式tomcat、jetty、undertow容器
3、提供Starters简化构建配置
4、尽可能自动配置spring 应用
5、提供生产指标、健壮检查和外部化配置
6、完全没有代码生成和xml配置要求
springboot启动加载
一、 注解原理和自动装配原理
1.1、springboot注解和容器初始化
/*
* 1、springboot启动类
*/
@ComponentScan(basePackages = "com.sk.spring.cloud.order.controller")
@SpringBootApplication
public class SpringCloudOrderServer {
public static void main(String[] args) {
SpringApplication.run(SpringCloudOrderServer.class, args);
}
}
/*
* 2、@SpringBootApplication注解
* 是个组合注解
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
//2.1、@SpringBootConfiguration
@SpringBootConfiguration
//2.2、@EnableAutoConfiguration
@EnableAutoConfiguration
//2.3、@ComponentScan
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
}
/*
* 2.1、@SpringBootConfiguration注解
* 相当于@Configuration:相当于@Component
* 作用:使当前类变成配置类,不需要额外的xml配置
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
}
/*
* 2.2、@EnableAutoConfiguration注解
* 开启自动配置
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
//2.2.1、@AutoConfigurationPackage 让包中的类以及子类能够被扫描到spring容器中
@AutoConfigurationPackage
//2.2.2、AutoConfigurationImportSelector
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {
}
/*
* 2.2.1、@AutoConfigurationPackage 让包中的类以及子类能够被扫描到spring容器中
* 开启自动配置
*/
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
//2.2.1.1、Registrar
@Import(AutoConfigurationPackages.Registrar.class)
public @interface AutoConfigurationPackage {
}
/*
* 2.2.1、@AutoConfiguration Package 让包中的类以及子类能够被扫描到spring容器中
* metadata是启动类
* 将主配置类 的所在包及子包里面所有组件扫描加载到spring容器中
*/
static class Registrar implements ImportBeanDefinitionRegistrar, DeterminableImports {
@Override
public void registerBeanDefinitions(AnnotationMetadata metadata, BeanDefinitionRegistry registry) {
//注册类的pakage 例如com.sk.spring.cloud.eureka.server
register(registry, new PackageImports(metadata).getPackageNames().toArray(new String[0]));
}
@Override
public Set<Object> determineImports(AnnotationMetadata metadata) {
return Collections.singleton(new PackageImports(metadata));
}
}
/*
* 2.2.2、AutoConfigurationImportSelector -》ImportSelector类 -》AutoConfigurationImportSelector类
* 继承了DeferredImportSelector -》ImportSelector(method:selectImports 将所有需要导入的组件以全类名的方式返回)
*/
@Override
public String[] selectImports(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return NO_IMPORTS;
}
AutoConfigurationEntry autoConfigurationEntry = getAutoConfigurationEntry(annotationMetadata);
//返回所有组件自动配置类
return StringUtils.toStringArray(autoConfigurationEntry.getConfigurations());
}
/**
* Return the {@link AutoConfigurationEntry} based on the {@link AnnotationMetadata}
* of the importing {@link Configuration @Configuration} class.
* @param annotationMetadata the annotation metadata of the configuration class
* @return the auto-configurations that should be imported
*/
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
AnnotationAttributes attributes = getAttributes(annotationMetadata);
//2.2.2.1、引入系统加载好的类
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
configurations = removeDuplicates(configurations);
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = getConfigurationClassFilter().filter(configurations);
fireAutoConfigurationImportEvents(configurations, exclusions);
return new AutoConfigurationEntry(configurations, exclusions);
}
/*
* 2.2.2.1、引入系统加载好的类
*
*/
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
String factoryTypeName = factoryType.getName();
// 2.2.2.1.1、从META-INF/spring.factories获取需要加载的资源
return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList());
}
/*
* 2.2.2.1、从META-INF/spring.factories获取需要加载的资源
* spring boot 在启动时候,从META-INF/spring.factories获取EnableAutoConfiguration指定的值,自动加载到容器中。
*/
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
Enumeration<URL> urls = (classLoader != null ?
classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
result = new LinkedMultiValueMap<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry<?, ?> entry : properties.entrySet()) {
String factoryTypeName = ((String) entry.getKey()).trim();
for (String factoryImplementationName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
result.add(factoryTypeName, factoryImplementationName.trim());
}
}
}
cache.put(classLoader, result);
return result;
}
catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}
/*
* 2.3、@ComponentScan
* 扫描指定路径包到容器中
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Repeatable(ComponentScans.class)
public @interface ComponentScan {
}
AutoConfigurationImportSelector的selectImports()方法通过SpringFactoriesLoader.loadFactoryNames()扫描所有具有META-INF/spring.factories的jar包。spring-boot-autoconfigure-x.x.x.x.jar里就有一个这样的spring.factories文件。
这个spring.factories文件也是一组一组的key=value的形式,其中一个key是EnableAutoConfiguration类的全类名,而它的value是一个xxxxAutoConfiguration的类名的列表,这些类名以逗号分隔,如下图所示:

这个@EnableAutoConfiguration注解通过@SpringBootApplication被间接的标记在了Spring Boot的启动类上。在SpringApplication.run(…)的内部就会执行selectImports()方法,找到所有JavaConfig自动配置类的全限定名对应的class,然后将所有自动配置类加载到Spring容器中。
1.2、自动配置生效
每一个xxxxAutoConfiguration自动配置类都是在某些条件之下才会生效的,这些条件的限制在Spring Boot中以注解的形式体现,常见的条件注解有如下几项:
@ConditionalOnBean:当容器里有指定的bean的条件下。
@ConditionalOnMissingBean:当容器里不存在指定bean的条件下。
@ConditionalOnClass:当类路径下有指定类的条件下。
@ConditionalOnMissingClass:当类路径下不存在指定类的条件下。
@ConditionalOnProperty:指定的属性是否有指定的值,比如@ConditionalOnProperties(prefix=”xxx.xxx”, value=”enable”, matchIfMissing=true),代表当xxx.xxx为enable时条件的布尔值为true,如果没有设置的情况下也为true。
以ServletWebServerFactoryAutoConfiguration配置类为例,解释一下全局配置文件中的属性如何生效,比如:server.port=8081,是如何生效的(当然不配置也会有默认值,这个默认值来自于org.apache.catalina.startup.Tomcat)。
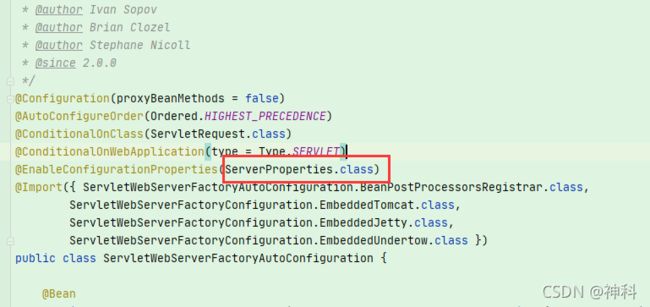
在ServletWebServerFactoryAutoConfiguration类上,有一个@EnableConfigurationProperties注解:开启配置属性
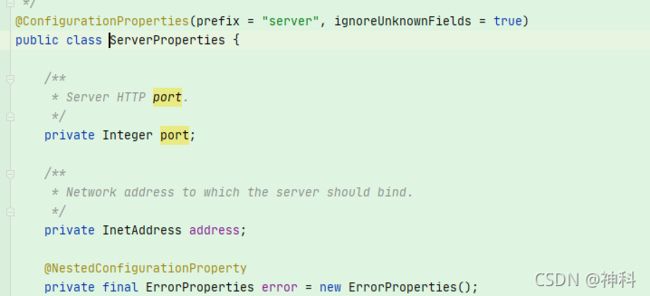
server.port等,通过@ConfigurationProperties注解,绑定到对应的XxxxProperties配置实体类上封装为一个bean,然后再通过@EnableConfigurationProperties注解导入到Spring容器中。
终结:Spring Boot启动的时候会通过@EnableAutoConfiguration注解找到META-INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConfiguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如:server.port,而XxxxProperties类是通过@ConfigurationProperties注解与全局配置文件中对应的属性进行绑定的。

(图片来自:https://afoo.me/posts/2015-07-09-how-spring-boot-works.html)
1.3、springboot配置加载
public ConfigurableApplicationContext run(String... args) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
//监听器
SpringApplicationRunListeners listeners = getRunListeners(args);
listeners.starting();
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
//prepareEnvironment 准备Environment环境对象
ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);
configureIgnoreBeanInfo(environment);
Banner printedBanner = printBanner(environment);
//准备上下文
context = createApplicationContext();
exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
//预刷新上下文
prepareContext(context, environment, listeners, applicationArguments, printedBanner);
//刷新上下文:bean加载、getWebServer创建内置tomcat容器
refreshContext(context);
//刷新之后上下文
afterRefresh(context, applicationArguments);
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);
}
listeners.started(context);
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}
.
2)、
spring cloud
Ribbon:负载。
- 解析配置服务中的列表
- 基于负载均衡算法实现的请求的分发
- ILoadBalancer
- IRule (负载均衡规则):权重机制(区间算法)/定时任务不断发起模拟请求、随机、轮询;
- IPing:每10s,去访问目标服务地址,如果服务不可用,提出无效服务
- ServerList:定时任务,每30s执行一次更新服务列表
- 自定义负载均衡算法:IRule(name.ribbon.NFLoadBalancerRuleClassName)、IPING(name…ribbon.NFLoadBalancerPingClassName)
#pom依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
<version>2.2.3.RELEASE</version>
</dependency>
# 配置指定服务的提供者的地址列表
spring-cloud-order-service.ribbon.listOfServers=\
localhost:8080,localhost:8082
@RestController
public class UserController {
@Autowired
RestTemplate restTemplate;
@Bean
@LoadBalanced
public RestTemplate restTemplate(RestTemplateBuilder restTemplateBuilder) {
return restTemplateBuilder.build();
}
/* @Autowired
LoadBalancerClient loadBalancerClient;*/
@GetMapping("/user/{id}")
public String findById(@PathVariable("id") int id) {
//TODO
// 调用订单的服务获得订单信息
// HttpClient RestTemplate OkHttp JDK HttpUrlConnection
//方式一、LoadBalancerClient
/*
ServiceInstance serviceInstance=loadBalancerClient.choose("spring-cloud-order-service");
String url=String.format("http://%s:%s",serviceInstance.getHost(),serviceInstance.getPort()+"/orders");
return restTemplate.getForObject(url, String.class);
*/
//方式二、 @LoadBalanced
return restTemplate.getForObject("http://spring-cloud-order-service/orders", String.class);
}
}
- 源码解析
public class RibbonLoadBalancerClient implements LoadBalancerClient {
@Override
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
Server server = getServer(loadBalancer);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server, isSecure(server,
serviceId), serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
}
//轮询、随机选择
protected Server getServer(ILoadBalancer loadBalancer) {
if (loadBalancer == null) {
return null;
}
return loadBalancer.chooseServer("default"); // TODO: better handling of key
}
OpenFeign:声明式伪RPC。
- Feign是一种声明式、模板化的HTTP客户端。在Spring Cloud中使用Feign,可以做到使用HTTP请求访问远程服务,就像调用本地方法一样的,开发者完全感知不到这是在调用远程方法,更感知不到在访问HTTP请求。
- 集成Ribbon负载均衡
#pom依赖
<dependency><!--可以支持OKHTTP-->
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
<version>2.2.3.RELEASE</version>
</dependency>
# 配置指定服务的提供者的地址列表
spring-cloud-order-service.ribbon.listOfServers=\
localhost:8080,localhost:8082
#Feign接口
@FeignClient("spring-cloud-order-service")
public interface OrderServiceFeignClient {
@GetMapping("/orders")
String getAllOrder();
}
#接口api
@RestController
public class OpenFeignController {
@Autowired
OrderServiceFeignClient orderServiceFeignClient;
@GetMapping("/test")
public String test(){
return orderServiceFeignClient.getAllOrder();
}
}
- 源码解析
Eureka
- Ribbon问题:服务上下线动态感知、服务调动者维护工作困难
application.properties
server:
port: 8761
eureka:
instance:
hostname: eureka8761 #eureka服务端的实例名称
client:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
service-url:
defaultZone: http://localhost:8761/eureka/
- 集群:eureka两两注册,client配置两个注册中心
- 自动保护机制:保证AP特性
自我保护模式正是一种针对网络异常波动的安全保护措施,使用自我保护模式能使Eureka集群更加的健壮、稳定的运行
机制:如果在15分钟内超过85%的客户端节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,Eureka Server自动进入自我保护机制,此时会出现以下几种情况:
1、Eureka Server不再从注册列表中移除因为长时间没收到心跳而应该过期的服务。
2、Eureka Server仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可用
3、当网络稳定时,当前Eureka Server新的注册信息会被同步到其它节点中。
-注册慢问题 - Eureka配置:
1)、Eureka注册服务慢问题
instance:
# eureka客户需要多长时间发送心跳给eureka服务器,表明它仍然活着,默认为30 秒
lease-renewal-interval-in-seconds: 5
# Eureka服务器在接收到实例的最后一次发出的心跳后,需要等待多久才可以将此实例删除,默认为90秒
lease-expiration-duration-in-seconds: 10
LeaseExpirationDurationInSeconds设置应大于LeaseRenewalIntervalInSeconds
太大,则很可能将流量转发过去的时候,该instance已经不存活了。
太小了,则instance则很可能因为临时的网络抖动而被摘除掉。
2)、Eureka自我保护模式
server:
#自我保护模式,当出现出现网络分区、eureka在短时间内丢失过多客户端时,会进入自我保护模式,即一个服务长时间没有发送心跳,eureka也不会将其删除,默认为true
enable-self-preservation: true
#清理无效节点的时间间隔 默认60秒
eviction-interval-timer-in-ms: 5000
心跳失败的比例在15分钟之内,低于85%,Eureka Server会认为这个实例出现了网络故障,直接剔除这个问题服务,为了减少网络不抖动或者网络稳定的情况下,避免误删除,自动保护机制不会剔除
3)、Eureka不踢出已停的服务节点
(1) Eureka Server端:配置关闭自我保护,并按需配置Eureka Server清理无效节点的时间间隔
eureka.server.enable-self-preservation # 设为false,关闭自我保护
eureka.server.eviction-interval-timer-in-ms # 清理间隔(单位毫秒,默认是60*1000) - 定时任务
(2) Eureka Client端:配置开启健康检查,并按需配置续约更新时间和到期时间
eureka.client.healthcheck.enabled # 开启健康检查(需要spring-boot-starter-actuator依赖)
eureka.instance.lease-renewal-interval-in-seconds # 续约更新时间间隔(默认30秒)
eureka.instance.lease-expiration-duration-in-seconds # 续约到期时间(默认90秒)
4)、zuul间隔多久去拉取注册服务的信息
eureka.client.registry-fetch-interval-seconds
表示eureka client间隔多久去拉取服务注册信息,默认为30秒,对于api-gateway,如果要迅速获取服务注册状态,可以缩小该值,比如5秒
5)、ribbon的饥饿加载
Spring Cloud为每个Ribbon客户端维护了一个相对的子应用环境的上下文,应用的上下文在第一次请求到指定客户端的时候懒加载。不过可以通过如下配置进行修改
ribbon:
eager-load:
enabled: true
clients:
- callback,service-cache,service-singlepoint
按照如上的配置之后,发现鉴权服务启动时就将user服务的Ribbon客户端进行了加载。
6)、zuul的饥饿加载
上面小节解决了auth-Service调用user-Service的Ribbon客户端启动时饥饿加载。网关作为对外请求的入口,zuul内部使用Ribbon调用其他服务,Spring Cloud默认在第一次调用时懒加载Ribbon客户端。zuul同样需要维护一个相对的子应用环境的上下文,所以也需要启动时饥饿加载。
zuul:
ribbon:
eager-load:
enabled: true
- Eureka设计:
4.1、服务注册
Eureka Client会通过发送REST请求的方式向Eureka Server注册自己的服务,提供自身的元数据,比如ip地址、端口、运行状况指标的url、主页地址等信息。Eureka Server接收到注册请求后,就会把这些元数据信息存储在一个双层的Map中。
4.2、服务续约
在服务注册后,Eureka Client会维护一个心跳来持续通知Eureka Server,说明服务一直处于可用状态,防止被剔除。Eureka Client在默认的情况下会每隔30秒发送一次心跳来进行服务续约。
private void initScheduledTasks() {
int renewalIntervalInSecs;
int expBackOffBound;
if (this.clientConfig.shouldFetchRegistry()) {
renewalIntervalInSecs = this.clientConfig.getRegistryFetchIntervalSeconds();
expBackOffBound = this.clientConfig.getCacheRefreshExecutorExponentialBackOffBound();
this.cacheRefreshTask = new TimedSupervisorTask("cacheRefresh", this.scheduler, this.cacheRefreshExecutor, renewalIntervalInSecs, TimeUnit.SECONDS, expBackOffBound, new DiscoveryClient.CacheRefreshThread());
this.scheduler.schedule(this.cacheRefreshTask, (long)renewalIntervalInSecs, TimeUnit.SECONDS);
}
if (this.clientConfig.shouldRegisterWithEureka()) {
renewalIntervalInSecs = this.instanceInfo.getLeaseInfo().getRenewalIntervalInSecs();
expBackOffBound = this.clientConfig.getHeartbeatExecutorExponentialBackOffBound();
logger.info("Starting heartbeat executor: renew interval is: {}", renewalIntervalInSecs);
//创建一个心跳检测的定时任务 TimedSupervisorTask.Run心跳失败衰减重试
this.heartbeatTask = new TimedSupervisorTask("heartbeat", this.scheduler, this.heartbeatExecutor, renewalIntervalInSecs, TimeUnit.SECONDS, expBackOffBound, new DiscoveryClient.HeartbeatThread());
this.scheduler.schedule(this.heartbeatTask, (long)renewalIntervalInSecs, TimeUnit.SECONDS);
this.instanceInfoReplicator = new InstanceInfoReplicator(this, this.instanceInfo, this.clientConfig.getInstanceInfoReplicationIntervalSeconds(), 2);
this.statusChangeListener = new StatusChangeListener() {
public String getId() {
return "statusChangeListener";
}
public void notify(StatusChangeEvent statusChangeEvent) {
if (InstanceStatus.DOWN != statusChangeEvent.getStatus() && InstanceStatus.DOWN != statusChangeEvent.getPreviousStatus()) {
DiscoveryClient.logger.info("Saw local status change event {}", statusChangeEvent);
} else {
DiscoveryClient.logger.warn("Saw local status change event {}", statusChangeEvent);
}
DiscoveryClient.this.instanceInfoReplicator.onDemandUpdate();
}
};
if (this.clientConfig.shouldOnDemandUpdateStatusChange()) {
this.applicationInfoManager.registerStatusChangeListener(this.statusChangeListener);
}
this.instanceInfoReplicator.start(this.clientConfig.getInitialInstanceInfoReplicationIntervalSeconds());
} else {
logger.info("Not registering with Eureka server per configuration");
}
}
4.3、服务同步
Eureka Server之间会互相进行注册,构建Eureka Server集群,不同Eureka Server之间会进行服务同步,用来保证服务信息的一致性 
4.4、获取服务
服务消费者(Eureka Client)在启动的时候,会发送一个REST请求给Eureka Server,获取上面注册的服务清单,并且缓存在Eureka Client本地,默认缓存30秒。同时,为了性能考虑,Eureka Server也会维护一份只读的服务清单缓存,该缓存每隔30秒更新一次。
4.5、服务调用
服务消费者在获取到服务清单后,就可以根据清单中的服务列表信息,查找到其他服务的地址,从而进行远程调用。Eureka有Region和Zone的概念,一个Region可以包含多个Zone,在进行服务调用时,优先访问处于同一个Zone中的服务提供者。
4.6、服务下线
当Eureka Client需要关闭或重启时,就不希望在这个时间段内再有请求进来,所以,就需要提前先发送REST请求(/eureka/apps/{appID}/{instanceID}/status?value=DOWN)给Eureka Server,告诉Eureka Server自己要下线了,Eureka Server在收到请求后,就会把该服务状态置为下线(DOWN),并把该下线事件传播出去。
4.7、服务剔除
有时候,服务实例可能会因为网络故障等原因导致不能提供服务,而此时该实例也没有发送请求给Eureka Server来进行服务下线,所以,还需要有服务剔除的机制。Eureka Server在启动的时候会创建一个定时任务,每隔一段时间(默认60秒),从当前服务清单中把超时没有续约(默认90秒)的服务剔除。
4.8、自我保护
既然Eureka Server会定时剔除超时没有续约的服务,那就有可能出现一种场景,网络一段时间内发生了异常,所有的服务都没能够进行续约,Eureka Server就把所有的服务都剔除了,这样显然不太合理。所以,就有了自我保护机制,当短时间内,统计续约失败的比例,如果达到一定阈值,则会触发自我保护的机制,在该机制下,Eureka Server不会剔除任何的微服务,等到正常后,再退出自我保护机制。
4.8、多级缓存
(registry、readWriteCacheMap、readOnlyCacheMap)保存服务注
册信息,默认情况下定时任务每30s将readWriteCacheMap同步至readOnlyCacheMap,每60s清理超
过90s未续约的节点,Eureka Client每30s从readOnlyCacheMap更新服务注册信息,而客户端服务的
注册则从registry更新服务注册信息。
responseCacheUpdateIntervalMs : readOnlyCacheMap 缓存更新的定时器时间间隔,默认为
30秒
responseCacheAutoExpirationInSeconds : readWriteCacheMap 缓存过期时间,默认为 180 秒
4.9、待整理
1)、Eureka Server如何接收请求
ApplicationsResource、ApplicationResource的Controller
2)、Rureka Client如何注册的
SmartLifeCycle
EurekaServiceRegistry
多节点同步
3)、Rureka Server
4)、Rureka Client如何查询地址
5)、Rureka Server服务延迟
服务上线:90s
readOnly 30s同步一次,clietn30s fetch一次,ribbon 30s更新一次serverList
服务下线的感知
90s
非正常下线:无限趋于240s
Config
开源配置中心:
Apoll:携程
Spring cloud config
nacos:阿里
zookeeper:
- 配置更新设置:
1)、默认git:
/{application}/{profle}/{label} /应用名称/不同配置分组/分支
访问/{application}/{profle}会默认加载/{application}配置文件
2)、本地配置:spring.profiles.active=native
3)、运行更新配置
A、运行手动更新配置
A1、单个业务配置刷新
(1)config服务配置
//1、pom引用
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
//2、配置修改
spring:
cloud:
config:
server:
git:
uri: https://gitee.com/hiytaance/spring-cloud-config-server-learn.git
username:
password:
.
(2) 业务服务配置
//1、pom引用
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
//2、配置修改
management:
endpoints:
web:
exposure:
include: refresh
//3、注解
@RefreshScope
@RestController
public class ConfigController {
@Value("${hello}")
private String txt;
@GetMapping("/config")
public String Config(){
return txt;
}
}
.
(3) post请求刷新配置:http://localhsot:对应业务端口/actuator/refresh
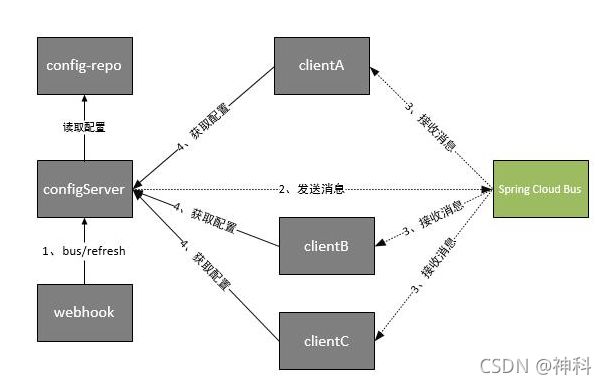
A2、Config配置刷新:Spring cloud Bus
Spring Cloud Bus 利用MQ广播机制在分布式系统中传播消息,目前常用的有Kafka和RabbitMq。
.
步骤1:git配置提交
步骤2:wehhook触发post请求发送bug/refresh给config server端
步骤3:server端接收到请求并发送给Spring cloud bus
步骤4:Spring cloud bus接收到消息广播通知其他客户端
步骤5:其他客户端接收到通知,请求Config Server端获取最新配置
步骤6:全部客户端获取到最新的配置
(1) config服务配置
//1、pom文件
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>
//2、application.properties配置修改
spring:
application:
name: spring-cloud-config-server-9091
cloud:
config:
server:
git:
uri: https://gitee.com/hiytaance/spring-cloud-config-server-learn.git
username: 18725503220
password: "Git503220"
bus:
enabled: true
trace:
enabled: true
refresh:
enabled: true
kafka:
bootstrap-servers: 172.17.17.15:9092
consumer:
group-id: config-server
management:
endpoints:
web:
exposure:
include: bus-refresh
.
(2) 业务服务配置 .
//1、pom添加
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bus-kafka</artifactId>
</dependency>
</dependencies>
//2、application配置修改
spring:
application:
name: order-service
cloud:
bus:
enabled: true
kafka:
bootstrap-servers: 172.17.17.15:9092
consumer:
group-id: order-service
management:
endpoints:
web:
exposure:
include: refresh
//3、添加注解@RefreshScope
.
(3) post请求刷新Config配置到Bus:http://localhsot:Config端口/actuator/bus-refresh
B、运行自动更新配置:
(1) gitee Webhooks
(2)monitor监听:
config服务添加spring-cloud-config-monitor依赖
(3)post:http://localhsot:Config端口/monitor;{“path”:“”} 或者 webhook设置http://localhsot:Config端口/monitor/path=
- 源码解析:
1)、spring Environment

.
1.1、Profiles:
通过profiles进行逻辑分组
public static void main(String[] args) {
AnnotationConfigApplicationContext context=new AnnotationConfigApplicationContext();
context.getEnvironment().setActiveProfiles("dev");
context.register(ProfileConfiguration.class);
context.refresh();
System.out.println(context.getBean(ProfileService.class));
}
.
配置:spring.profiels.active=dev
1.2、Properties:
系统环境变量和系统变量
1.3、源码
1.3.1、初始化:springApplication.run -> prepareEnvironment
a)获取默认的配置文件路径,有4种。
b)遍历所有的路径,拼装配置文件名称。
c)再遍历解析器,选择yml或者properties解析,将解析结果添加到集合MutablePropertySources当中。
/*
* 1、springApplication.run
* 初始化入口
*/
public ConfigurableApplicationContext run(String... args) {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList();
this.configureHeadlessProperty();
SpringApplicationRunListeners listeners = this.getRunListeners(args);
listeners.starting();
Collection exceptionReporters;
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);
//2、prepareEnvironment 准备Environment环境对象
ConfigurableEnvironment environment = this.prepareEnvironment(listeners, applicationArguments);
this.configureIgnoreBeanInfo(environment);
Banner printedBanner = this.printBanner(environment);
context = this.createApplicationContext();
exceptionReporters = this.getSpringFactoriesInstances(SpringBootExceptionReporter.class, new Class[]{ConfigurableApplicationContext.class}, context);
this.prepareContext(context, environment, listeners, applicationArguments, printedBanner);
this.refreshContext(context);
this.afterRefresh(context, applicationArguments);
stopWatch.stop();
if (this.logStartupInfo) {
(new StartupInfoLogger(this.mainApplicationClass)).logStarted(this.getApplicationLog(), stopWatch);
}
listeners.started(context);
this.callRunners(context, applicationArguments);
} catch (Throwable var10) {
this.handleRunFailure(context, var10, exceptionReporters, listeners);
throw new IllegalStateException(var10);
}
try {
listeners.running(context);
return context;
} catch (Throwable var9) {
this.handleRunFailure(context, var9, exceptionReporters, (SpringApplicationRunListeners)null);
throw new IllegalStateException(var9);
}
/*
* 2、prepareEnvironment
* 来准备Environment环境对象
*/
private ConfigurableEnvironment prepareEnvironment(SpringApplicationRunListeners listeners, ApplicationArguments applicationArguments) {
// 2.1、getOrCreateEnvironment 根据上下文,创建一个合适的Environment对象
ConfigurableEnvironment environment = this.getOrCreateEnvironment();
// 2.2、configureEnvironment 配置Environment的propertySource、profiles
this.configureEnvironment((ConfigurableEnvironment)environment, applicationArguments.getSourceArgs());
ConfigurationPropertySources.attach((Environment)environment);
// 2.3、通知监听器,加载配置文件,执行ConfigFileApplicationListener.onApplicationEvent
listeners.environmentPrepared((ConfigurableEnvironment)environment);
this.bindToSpringApplication((ConfigurableEnvironment)environment);
if (!this.isCustomEnvironment) {
environment = (new EnvironmentConverter(this.getClassLoader())).convertEnvironmentIfNecessary((ConfigurableEnvironment)environment, this.deduceEnvironmentClass());
}
ConfigurationPropertySources.attach((Environment)environment);
return (ConfigurableEnvironment)environment;
}
/*
* 2.1、getOrCreateEnvironment
* 根据当前的webApplication类型匹配对应的environment,当前默认的应该就是StandardServletEnvironment ,如果spring webflux,则是StandardReactiveWebEnvironment
*/
private ConfigurableEnvironment getOrCreateEnvironment() {
if (this.environment != null) {
return this.environment;
} else {
switch(this.webApplicationType) {
case SERVLET:
return new StandardServletEnvironment();
case REACTIVE:
return new StandardReactiveWebEnvironment();
default:
return new StandardEnvironment();
}
}
}
/*
* 2.1.1、StandardServletEnvironment.customizePropertySources
* 获取server配置信息
*/
protected void customizePropertySources(MutablePropertySources propertySources) {
//1、加载server init-param配置信息
propertySources.addLast(new StubPropertySource("servletConfigInitParams"));
//2、加载server context-param配置信息
propertySources.addLast(new StubPropertySource("servletContextInitParams"));
//3、加载jndi.properties配置信息
if (JndiLocatorDelegate.isDefaultJndiEnvironmentAvailable()) {
propertySources.addLast(new JndiPropertySource("jndiProperties"));
}
super.customizePropertySources(propertySources);
}
/*
* 2.1.2、StandardEnvironment.customizePropertySources
* 获取系统变量和环境变量
*/
protected void customizePropertySources(MutablePropertySources propertySources) {
propertySources.addLast(new PropertiesPropertySource("systemProperties", this.getSystemProperties()));
propertySources.addLast(new SystemEnvironmentPropertySource("systemEnvironment", this.getSystemEnvironment()));
}
/*
* 2.2、configureEnvironment
* 解析需要的propertySource
*/
protected void configureEnvironment(ConfigurableEnvironment environment, String[] args) {
//将properties中的string属性转换成java合适对象
if (this.addConversionService) {
ConversionService conversionService = ApplicationConversionService.getSharedInstance();
environment.setConversionService((ConfigurableConversionService)conversionService);
}
//配置propertySources:defaultProperties、commandLineArgs(命令行参数:springApplicationCommandLineArgs)
this.configurePropertySources(environment, args);
//配置profiles:environment.getActiveProfiles()
this.configureProfiles(environment, args);
}
/*
* 2.3、ConfigFileApplicationListener.onApplicationEvent
*
*/
public void onApplicationEvent(ApplicationEvent event) {
if (event instanceof ApplicationEnvironmentPreparedEvent) {
//2.3.1、onApplicationEnvironmentPreparedEvent->postProcessEnvironment->addPropertySources
this.onApplicationEnvironmentPreparedEvent((ApplicationEnvironmentPreparedEvent)event);
}
if (event instanceof ApplicationPreparedEvent) {
this.onApplicationPreparedEvent(event);
}
}
/*
* 2.3.1、ConfigFileApplicationListener.addPropertySources
* onApplicationEnvironmentPreparedEvent->postProcessEnvironment->addPropertySources
* 添加RandomValuePropertySource到Environment中的MutablePropertySources中
*/
protected void addPropertySources(ConfigurableEnvironment environment, ResourceLoader resourceLoader) {
//添加RandomValuePropertySource到Environment中的MutablePropertySources中
RandomValuePropertySource.addToEnvironment(environment);
//2.3.1.1、load:加载spring boot配置信息:application.yum、application.properties
(new ConfigFileApplicationListener.Loader(environment, resourceLoader)).load();
}
/*
* 2.3.1.1、load:加载spring boot配置信息:application.yum、application.properties
*/
void load() {
FilteredPropertySource.apply(this.environment, "defaultProperties", ConfigFileApplicationListener.LOAD_FILTERED_PROPERTY, (defaultProperties) -> {
// 定义未处理的数据集合
this.profiles = new LinkedList();
// 定义已处理的数据集合
this.processedProfiles = new LinkedList();
this.activatedProfiles = false;
this.loaded = new LinkedHashMap();
//2.3.1.1.1、加载存在已经激活的 profiles
this.initializeProfiles();
//如果当前有默认配置,增加FilteredPropertySource
while(!this.profiles.isEmpty()) {
//遍历所有initializeProfiles profiles
ConfigFileApplicationListener.Profile profile = (ConfigFileApplicationListener.Profile)this.profiles.poll();
if (this.isDefaultProfile(profile)) {
this.addProfileToEnvironment(profile.getName());
}
// 确定搜索范围,获取对应的配置文件名,并使用相应加载器加载
this.load(profile, this::getPositiveProfileFilter, this.addToLoaded(MutablePropertySources::addLast, false));
// 将处理完的 profile添加到 processedProfiles列表当中,表示已经处理完成
this.processedProfiles.add(profile);
}
//2.3.1.1.2、load.load
this.load((ConfigFileApplicationListener.Profile)null, this::getNegativeProfileFilter, this.addToLoaded(MutablePropertySources::addFirst, true));
this.addLoadedPropertySources();
// 更新 activeProfiles列表
this.applyActiveProfiles(defaultProperties);
});
}
/*
* 2.3.1.1、load:加载spring boot配置信息:application.yum、application.properties
*/
private void initializeProfiles() {
// The default profile for these purposes is represented as null. We add it
// first so that it is processed first and has lowest priority.
this.profiles.add(null);
Binder binder = Binder.get(this.environment);
//判断当前环境是否配置 spring.profiles.active属性
Set<Profile> activatedViaProperty = getProfiles(binder, ACTIVE_PROFILES_PROPERTY);
//判断当前环境是否配置 spring.profiles.include属性
Set<Profile> includedViaProperty = getProfiles(binder, INCLUDE_PROFILES_PROPERTY);
//如果没有特别指定的话,就是 application.properties 和 application- default.properties配置
List<Profile> otherActiveProfiles = getOtherActiveProfiles(activatedViaProperty, includedViaProperty);
this.profiles.addAll(otherActiveProfiles);
// Any pre-existing active profiles set via property sources (e.g.
// System properties) take precedence over those added in config files.
this.profiles.addAll(includedViaProperty);
addActiveProfiles(activatedViaProperty);
// 如果 profiles集仍然为null,即没有指定,就会创建默认的profile
if (this.profiles.size() == 1) { // only has null profile
for (String defaultProfileName : this.environment.getDefaultProfiles()) {
Profile defaultProfile = new Profile(defaultProfileName, true);
this.profiles.add(defaultProfile);
}
}
}
/*
* 2.3.1.2、load.load
* 获取需要遍历的目标路径,再拼接对应路径,选择合适的yml或者properties解析器进行解析
*/
private void load(Profile profile, DocumentFilterFactory filterFactory, DocumentConsumer consumer) {
//2.3.1.2.1、获取需要遍历的目标路径
getSearchLocations().forEach((location) -> {
boolean isDirectory = location.endsWith("/");
Set<String> names = isDirectory ? getSearchNames() : NO_SEARCH_NAMES;
names.forEach((name) -> load(location, name, profile, filterFactory, consumer));
});
}
//2.3.1.2.1、获取需要遍历的目标路径
private Set<String> getSearchLocations() {
//spring.config.additional-location
Set<String> locations = getSearchLocations(CONFIG_ADDITIONAL_LOCATION_PROPERTY);
//spring.config.location
if (this.environment.containsProperty(CONFIG_LOCATION_PROPERTY)) {
locations.addAll(getSearchLocations(CONFIG_LOCATION_PROPERTY));
}
else {
locations.addAll(
asResolvedSet(ConfigFileApplicationListener.this.searchLocations, DEFAULT_SEARCH_LOCATIONS));
}
return locations;
}
.
1.3.2、Spring Cloud Cofig远程配置文件加载到Environment
PropertySourceLocator:Spring Cloud Config client使用Config Server配置的内容。PropertySourceBootstrapConfiguration实现了ApplicationContextInitializer, 他会读取bootstrap.properties,bootstrap.yml等配置文件中Config Server的配置信息,并使用PropertySourceLocator获取Config Server的Environment,最后insertPropertySources将拉取到的PropertySources添加到本应用的Environment中。
ConfigServicePropertySourceLocator#locate方法通过RestTemplate获取Config Server的Environment,并将结果的PropertySource转化为对应的OriginTrackedMapPropertySource。
RefreshScope: 在运行时动态刷新配置值,需要在Bean上添加@RefreshScope,并使用spring-boot-starter-actuator提供的HTTP接口actuator/refresh来刷新配置值。通过actuator/refresh来刷新@RefreshScope标注的类。调用链路 RefreshEndpoint#refresh -> ContextRefresher#refresh -> RefreshScope#refreshAll。efreshScope#refreshAll会销毁@RefreshScope标注的bean(还会发布RefreshScopeRefreshedEvent事件),这样先创建的bean就可以拿到最新的配置值了。
ContextRefresher: ContextRefresher#refresh会刷新Environment的内容,并发布EnvironmentChangeEvent事件
springApplication.run -> prepareEnvironment->applyInitializers(context)->initializer.initialize(context)->PropertySourceBootstrapConfiguration.initialize
/*
* 1、对propertySourceLocators数组进行排序,获取运行的环境上下文ConfigurableEnvironment
*/
@Override
public void initialize(ConfigurableApplicationContext applicationContext) {
List<PropertySource<?>> composite = new ArrayList<>();
//对propertySourceLocators数组进行排序,根据默认的AnnotationAwareOrderComparator
AnnotationAwareOrderComparator.sort(this.propertySourceLocators);
boolean empty = true;
//获取运行的环境上下文
ConfigurableEnvironment environment = applicationContext.getEnvironment();
for (PropertySourceLocator locator : this.propertySourceLocators) {
//1.1、回调所有实现PropertySourceLocator接口实例的locate方法,获得PropertySource
Collection<PropertySource<?>> source = locator.locateCollection(environment);
if (source == null || source.size() == 0) {
continue;
}
List<PropertySource<?>> sourceList = new ArrayList<>();
for (PropertySource<?> p : source) {
sourceList.add(new BootstrapPropertySource<>(p));
}
logger.info("Located property source: " + sourceList);
composite.addAll(sourceList);
//将source添加到PropertySource的链表中
empty = false;
}
//只有propertysource不为空的情况,才会设置到environment中
if (!empty) {
//返回Environment的可变形式,可进行的操作如addFirst、addLast
MutablePropertySources propertySources = environment.getPropertySources();
String logConfig = environment.resolvePlaceholders("${logging.config:}");
LogFile logFile = LogFile.get(environment);
for (PropertySource<?> p : environment.getPropertySources()) {
//移除propertySources中的bootstrapProperties
if (p.getName().startsWith(BOOTSTRAP_PROPERTY_SOURCE_NAME)) {
propertySources.remove(p.getName());
}
}
//将结果放入环境的MutablePropertySources中
insertPropertySources(propertySources, composite);
//重新初始化log系统
reinitializeLoggingSystem(environment, logConfig, logFile);
//设置log级别
setLogLevels(applicationContext, environment);
//处理包含的环境配置
handleIncludedProfiles(environment);
}
}
/*
*1.1、回调所有实现PropertySourceLocator接口实例的locate方法,获得PropertySource
*/
default Collection<PropertySource<?>> locateCollection(Environment environment) {
return locateCollection(this, environment);
}
static Collection<PropertySource<?>> locateCollection(PropertySourceLocator locator,
Environment environment) {
//1.1.1、通过RestTemplate调用一个远程地址获得配置信息,getRemoteEnvironment 。然后把这个配置PropertySources,然后将这个信息包装成一个OriginTrackedMapPropertySource,设置到 Composite 中。
PropertySource<?> propertySource = locator.locate(environment);
if (propertySource == null) {
return Collections.emptyList();
}
if (CompositePropertySource.class.isInstance(propertySource)) {
Collection<PropertySource<?>> sources = ((CompositePropertySource) propertySource)
.getPropertySources();
List<PropertySource<?>> filteredSources = new ArrayList<>();
for (PropertySource<?> p : sources) {
if (p != null) {
filteredSources.add(p);
}
}
return filteredSources;
}
else {
return Arrays.asList(propertySource);
}
}
/*
*1.1.1、回调所有实现PropertySourceLocator接口实例的locate方法,获得PropertySource
*/
@Override
@Retryable(interceptor = "configServerRetryInterceptor")
public org.springframework.core.env.PropertySource<?> locate(
org.springframework.core.env.Environment environment) {
ConfigClientProperties properties = this.defaultProperties.override(environment);
CompositePropertySource composite = new OriginTrackedCompositePropertySource(
"configService");
RestTemplate restTemplate = this.restTemplate == null
? getSecureRestTemplate(properties) : this.restTemplate;
Exception error = null;
String errorBody = null;
try {
String[] labels = new String[] { "" };
if (StringUtils.hasText(properties.getLabel())) {
labels = StringUtils
.commaDelimitedListToStringArray(properties.getLabel());
}
String state = ConfigClientStateHolder.getState();
// Try all the labels until one works
for (String label : labels) {
//远程获取配置
Environment result = getRemoteEnvironment(restTemplate, properties,
label.trim(), state);
if (result != null) {
log(result);
// result.getPropertySources() can be null if using xml
if (result.getPropertySources() != null) {
for (PropertySource source : result.getPropertySources()) {
@SuppressWarnings("unchecked")
Map<String, Object> map = translateOrigins(source.getName(),
(Map<String, Object>) source.getSource());
composite.addPropertySource(
new OriginTrackedMapPropertySource(source.getName(),
map));
}
}
if (StringUtils.hasText(result.getState())
|| StringUtils.hasText(result.getVersion())) {
HashMap<String, Object> map = new HashMap<>();
putValue(map, "config.client.state", result.getState());
putValue(map, "config.client.version", result.getVersion());
composite.addFirstPropertySource(
new MapPropertySource("configClient", map));
}
return composite;
}
}
errorBody = String.format("None of labels %s found", Arrays.toString(labels));
}
catch (HttpServerErrorException e) {
error = e;
if (MediaType.APPLICATION_JSON
.includes(e.getResponseHeaders().getContentType())) {
errorBody = e.getResponseBodyAsString();
}
}
catch (Exception e) {
error = e;
}
if (properties.isFailFast()) {
throw new IllegalStateException(
"Could not locate PropertySource and the fail fast property is set, failing"
+ (errorBody == null ? "" : ": " + errorBody),
error);
}
logger.warn("Could not locate PropertySource: "
+ (error != null ? error.getMessage() : errorBody));
return null;
}
/*
*1.1.2、 EnvironmentController.getEnvironment api接口
*/
public Environment getEnvironment(String name, String profiles, String label,boolean includeOrigin) {
name = Environment.normalize(name);
label = Environment.normalize(label);
//1.1.2.1、调用EnvironmentRepository(MultipleJGitEnvironmentRepository、RedisEnvironmentRepository、JdbcEnvironmentRepository)方法,根据Repository组件获得环境配置信息进行返回。
Environment environment = this.repository.findOne(name, profiles, label,
includeOrigin);
if (!this.acceptEmpty
&& (environment == null || environment.getPropertySources().isEmpty())) {
throw new EnvironmentNotFoundException("Profile Not found");
}
return environment;
}
/*
*1.1.2.1、 getEnvironment api接口
* 默认:MultipleJGitEnvironmentRepository
* EnvironmentRepository ->AbstractScmEnvironmentRepository->MultipleJGitEnvironmentRepository
* 代理遍历每个 JGitEnvironmentRepository,JGitEnvironmentRepository 下使用 NativeEnvironmentRepository 代理读取本地文件
*/
@Override
public Environment findOne(String application, String profile, String label,boolean includeOrigin) {
//遍历所有Git源
for (PatternMatchingJGitEnvironmentRepository repository : this.repos.values()) {
if (repository.matches(application, profile, label)) {
for (JGitEnvironmentRepository candidate : getRepositories(repository,
application, profile, label)) {
try {
if (label == null) {
label = candidate.getDefaultLabel();
}
//1.1.2.1.1、获取git和本地文件
Environment source = candidate.findOne(application, profile,
label, includeOrigin);
if (source != null) {
return source;
}
}
catch (Exception e) {
if (this.logger.isDebugEnabled()) {
this.logger.debug(
"Cannot load configuration from " + candidate.getUri()
+ ", cause: (" + e.getClass().getSimpleName()
+ ") " + e.getMessage(),
e);
}
continue;
}
}
}
}
JGitEnvironmentRepository candidate = getRepository(this, application, profile,label);
if (label == null) {
label = candidate.getDefaultLabel();
}
if (candidate == this) {
return super.findOne(application, profile, label, includeOrigin);
}
return candidate.findOne(application, profile, label, includeOrigin);
}
/*
*1.1.2.1.1、获取git和本地文件口
*
*/
@Override
public synchronized Environment findOne(String application, String profile,
String label, boolean includeOrigin) {
NativeEnvironmentRepository delegate = new NativeEnvironmentRepository(
getEnvironment(), new NativeEnvironmentProperties());
//1.1.2.1.1.1、调用getLocations从GIT远程仓库同步到本地 JGitEnvironmentRepository.getLocations ->refresh
Locations locations = getLocations(application, profile, label);
delegate.setSearchLocations(locations.getLocations());
//使用 NativeEnvironmentRepository 委托来读取本地文件内容
Environment result = delegate.findOne(application, profile, "", includeOrigin);
result.setVersion(locations.getVersion());
result.setLabel(label);
return this.cleaner.clean(result, getWorkingDirectory().toURI().toString(),
getUri());
}
/*
*1.1.2.1.1.1、调用getLocations从GIT远程仓库同步到本地 JGitEnvironmentRepository.getLocations ->refresh
*
*/
/**
* Get the working directory ready.
* @param label label to refresh
* @return head id
*/
public String refresh(String label) {
Git git = null;
try {
git = createGitClient();
if (shouldPull(git)) {
FetchResult fetchStatus = fetch(git, label);
if (this.deleteUntrackedBranches && fetchStatus != null) {
deleteUntrackedLocalBranches(fetchStatus.getTrackingRefUpdates(),
git);
}
// checkout after fetch so we can get any new branches, tags, ect.
checkout(git, label);
tryMerge(git, label);
}
else {
// nothing to update so just checkout and merge.
// Merge because remote branch could have been updated before
checkout(git, label);
tryMerge(git, label);
}
// always return what is currently HEAD as the version
return git.getRepository().findRef("HEAD").getObjectId().getName();
}
catch (RefNotFoundException e) {
throw new NoSuchLabelException("No such label: " + label, e);
}
catch (NoRemoteRepositoryException e) {
throw new NoSuchRepositoryException("No such repository: " + getUri(), e);
}
catch (GitAPIException e) {
throw new NoSuchRepositoryException(
"Cannot clone or checkout repository: " + getUri(), e);
}
catch (Exception e) {
throw new IllegalStateException("Cannot load environment", e);
}
finally {
try {
if (git != null) {
git.close();
}
}
catch (Exception e) {
this.logger.warn("Could not close git repository", e);
}
}
}
Hystrix
Hystrix中的三种降级方案,fallback-> 回退方案(降级处理方案)
/*
* 1、pom引用hystrix依赖包
*/
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
/*
* 2、启动项开启熔断
* @EnableCircuitBreaker
*/
@EnableCircuitBreaker
@ComponentScan(basePackages = {
"com.sk.spring.cloud.user.controller"})
@SpringBootApplication
public class SpingCloudUserServer {
public static void main(String[] args) {
SpringApplication.run(SpingCloudUserServer.class, args);
}
}
一、熔断触发降级
默认10s内,至少发起了20次请求(requestVolumeThreshold),失败率超过50%(errorThresholdPercentage),触犯熔断后,正确请求也被降级。
超过 熔断的恢复时间(熔断5s sleepWindowInMilliseconds),熔断关闭。
//@DefaultProperties(defaultFallback = "fallback") 设置类全局降级
@RestController
public class HystrixController {
@Autowired
RestTemplate restTemplate;
@HystrixCommand(commandProperties = {
@HystrixProperty(name="circuitBreaker.enabled",value ="true"),
@HystrixProperty(name="circuitBreaker.requestVolumeThreshold",value = "5"),
@HystrixProperty(name="circuitBreaker.sleepWindowInMilliseconds",value = "5000"),
@HystrixProperty(name="circuitBreaker.errorThresholdPercentage",value = "50")
},fallbackMethod = "fallback",
groupKey = "",threadPoolKey = "order-service")
@GetMapping("/hystrix/order/{num}")
public String queryOrder(@PathVariable("num")int num){
if(num%2==0){
return "正常访问";
}
//restTemplate默认有一个请求超时时间
return restTemplate.getForObject("http://localhost:8082/orders",String.class);
}
public String fallback(){
return "";
}
}
二、请求超时触发降级
2.1、 timeoutInMilliseconds默认1000
//@DefaultProperties(defaultFallback = "fallback") 设置类全局降级
@RestController
public class HystrixController {
@Autowired
RestTemplate restTemplate;
@HystrixCommand(commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds",value = "3000"),
},fallbackMethod ="timeoutFallback")
@GetMapping("/hystrix/timeout")
public String queryOrderTimeout(){
return restTemplate.getForObject("http://localhost:8082/orders",String.class);
}
public String timeoutFallback(){return "请求超时";}
}
.
2.2、 FeignClient请求超时触发降级
//1、user服务端 请求 order服务,在order服务修增加Feign超时触发降级
/*
* order服务定义接口
*/
@FeignClient(value = "order-service",fallback = OrderFacadeFeignClient.OrderServiceFeignClientFallback.class)
public interface OrderFacadeFeignClient extends OrderFacade {
@Component
class OrderServiceFeignClientFallback implements OrderFacadeFeignClient {
@Override
public String orders() {
return "查询订单失败,请稍候重试";
}
@Override
public int insert(OrderDto dto) {
System.out.println("insert失败");
return -1;
}
}
}
//2、user服务端 请求 order服务,user服务配置
/*
* 2.1、user服务启动项目配置
* @ComponentScan 增加order服务接口扫描
* @EnableFeignClients 增加order服务feign扫描
*/
@EnableCircuitBreaker
@ComponentScan(basePackages = {
"com.sk.spring.cloud.user.controller",
"com.sk.spring.cloud.order.feign"})
@EnableFeignClients(basePackages = "com.sk.spring.cloud.order.feign")
@SpringBootApplication
public class SpingCloudUserServer {
public static void main(String[] args) {
SpringApplication.run(SpingCloudUserServer.class, args);
}
}
/*
* 2.2、user服务api接口
*/
@RestController
public class HystrixFeignController {
//order feign接口
@Autowired
OrderFacadeFeignClient orderFacadeFeignClient;
@GetMapping("/hystrix/feign/order")
public String queryOrder(){
return orderFacadeFeignClient.orders();
}
@PostMapping("/hystrix/feign/order")
public String insertOrder(){
OrderDto orderDto=new OrderDto();
orderDto.setOrderId("GP0001");
return orderFacadeFeignClient.insert(orderDto)>0?"SUCCESS":"FAILED";
}
}
/*
* 2.3、user的application配置
* 开启fegin
*/
feign:
hystrix:
enabled: true
#设置hystrix设置
hystrix:
command:
default: #全局配置, feignclient#method(param)
execution:
timeout:
enable: true
isolation:
thread:
timeoutInMilliseconds: 3000
#设置restTemple请求超时时间
ribbon:
ReadTimeout: 10000
ConnectTimeout: 10000
三、资源隔离触发降级:https://www.cnblogs.com/duanxz/p/9681470.html
3.1、线程池隔离
3.2、信号量隔离
3.3、比较
当请求的服务网络开销较大的时候,或者是请求比较耗时的时候,我们最后好使用线程隔离策略,这样可以保证大量的tomcat容器线程可用,不会由于服务原因导致阻塞和等待状态,快速失败回收
当请求缓存这些服务的时候,我们使用信号量隔离策略,因为这些服务反应快,不会占用线程太长时间,而且减少线程切换的开启,提高了缓存服务的效率
#设置hystrix设置
hystrix:
command:
default: #全局配置, feignclient#method(param)
execution:
timeout:
enable: true
isolation:
thread:
timeoutInMilliseconds: 3000
OrderServiceFeignClient#orders():
execution:
isolation:
strategy: SEMAPHORE
semaphore:
maxConcurrentRequests: 10
OrderServiceFeignClient#insert():
execution:
isolation:
strategy: THREAD
threadpool:
order-service:
coreSize: 2
maxQueueSize: 1000
queueSizeRejectionThreshold: 800
.
3.4、Sentinel 与 Hystrix 的对比
源码解析
一、自定义配置
1.1、可配置化的降级策略
信号量/线程池
HystrixCommandProperty???
1.2、可识别的降级边界
@HystrixCommand
实现HystrixCommand抽象类
public class HystrixCommandService extends HystrixCommand<String>{
int num;
RestTemplate restTemplate;
public HystrixCommandService(int num,RestTemplate restTemplate){
super(HystrixCommand.Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("order-service")).
andCommandPropertiesDefaults(HystrixCommandProperties.Setter().
withCircuitBreakerEnabled(true).
withCircuitBreakerRequestVolumeThreshold(5))); //TODO
this.num=num;
this.restTemplate=restTemplate;
}
@Override
protected String run() throws Exception {
if(num%2==0){
return "正常访问";
}
//发起远程请求
return restTemplate.getForObject("http://localhost:8082/orders",String.class);
}
//如果Hystrix触发了降级,那么将会执行fallback方法
@Override
protected String getFallback() {
return "请求被降级";
}
}
@RestController
public class HystrixCommandController {
@Autowired
RestTemplate restTemplate;
@GetMapping("/hystrix/command/{num}")
public String hystrixCommand(@PathVariable("num")int num){
HystrixCommandService hystrixCommandService=new HystrixCommandService(num,restTemplate);
return hystrixCommandService.execute();//执行
}
}
1.3、数据采集
如何触发熔断->采集数据和统计数据(滑动窗口)
SEMAPHORE (最大并发数)-> AQS->tryAcquire()
1.4、行为干预:触发降级/熔断后,业务降级
1.5、结果干预:fallback()
1.6、自动恢复:熔断后,每隔5s恢复
二、Hystrix工作原理
2.1、滑动窗口:流量控制技术
2.2、代理模式:AOP + RxJava 观察者模式(没看懂,值得学习)
public static void main(String[] args) {
final String[] datas=new String[]{"a","b","c","d"};
final Action0 onComplated=new Action0() {
@Override
public void call() {
System.out.println("on Complated");
}
};
//老师(被观察者)
Observable<String> observable=Observable.defer(new Func0<Observable<String>>() {
@Override
public Observable<String> call() {
Observable observable1=Observable.from(datas);
return observable1.doOnCompleted(onComplated);
}
});
//学生(观察者)
Observer observer=new Observer() {
@Override
public void onCompleted() {
System.out.println("Observer: onCompleted");
}
@Override
public void onError(Throwable throwable) {
System.out.println("Observer: onError");
}
@Override
public void onNext(Object o) {
System.out.println("on Next:"+o);
}
};
observable.subscribe(observer); //建立订阅关系
}
GeteWay
一、实现组件:
OpenResty(nginx+lua)
Kong
Tyk
Zuul
Spring Cloud GateWay
二、配置
2.1、简单配置
spring:
cloud:
gateway:
routes:
- predicates:
- Path=/gateway/**
filters:
- StripPrefix=1
uri: http://localhost:8082/
.
2.2、Predicate
断言:spring cloud predicate

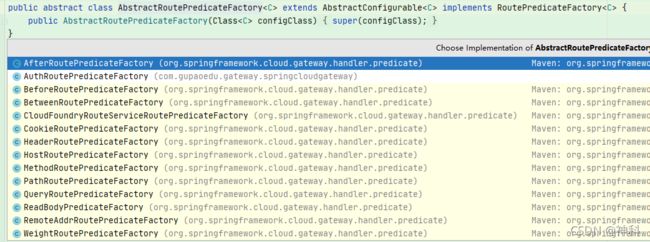
.
自定义断言
/*
* 1、自定义断言
* 类命名以RoutePredicateFactory结尾
* 实现AbstractRoutePredicateFactory类
*/
@Component
public class AuthRoutePredicateFactory extends AbstractRoutePredicateFactory<AuthRoutePredicateFactory.Config>{
public AuthRoutePredicateFactory() {
super(Config.class);
}
private static final String NAME_KEY="name";
private static final String VALUE_KEY="value";
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList(NAME_KEY,VALUE_KEY);
}
@Override
public Predicate<ServerWebExchange> apply(Config config) {
//Header中携带了某个值,进行header的判断
return (exchange->{
HttpHeaders headers=exchange.getRequest().getHeaders();
List<String> headerList=headers.get(config.getName());
return headerList.size()>0;
});
}
public static class Config{
private String name;
private String value;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
}
/*
* 2、application配置
* 设置predicates节点
*/
- id: auth_route
predicates:
- Path=/auth/**
- Auth=Authorization
filters:
- StripPrefix=1
uri: https://www.baidu.com/
2.3、Fiilter
作用:授权认证(拦截器)、限流
2.3.1、GlobalFilter
负载
/*
* 1、pom
*/
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
/*
* 2、application配置
*/
/*
* 2.1、获取eureka注册服务
*/
eureka:
client:
service-url:
defaultZone: http://localhost:9090/eureka
/*
* 2.2、配置负载服务
* 2.2.1、服务名称匹配大小写
* 2.2.2、路由lb
*/
spring:
cloud:
discovery:
locator:
enabled: true
lower-case-service-id: true
spring:
cloud:
gateway:
routes:
- id: lb_route
predicates:
- Path=/lb/**
filters:
- StripPrefix=1
uri: lb://order-service
2.3.2、RouteFIiter


/*
* 1、自定义SkDefine过滤器
*/
/*
* 1.1、自定义filter,继承AbstractGatewayFilterFactory
* 命名以GatewayFilterFactory结尾
*/
@Component
public class SKDefineGatewayFilterFactory extends AbstractGatewayFilterFactory<SKDefineGatewayFilterFactory.Config> {
private static final String NAME_KEY = "name";
private static final Logger log = LoggerFactory.getLogger(SKDefineGatewayFilterFactory.class);
public SKDefineGatewayFilterFactory(){
super(Config.class);
}
@Override
public List<String> shortcutFieldOrder() {
return Arrays.asList(NAME_KEY);
}
@Override
public GatewayFilter apply(Config config) {
return ((exchange, chain) -> {
log.info("[pre] Filter Request, name:"+config.getName());
return chain.filter(exchange).then(Mono.fromRunnable(()->{
log.info("[post]: Response Filter");
}));
});
}
public static class Config{
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
}
/*
* 1.2、application设置
* 设置filters节点
*/
- id: define_route
predicates:
- Path=/define/**
filters:
- StripPrefix=1
- SKDefine=sk
uri: https://www.baidu.com/
/*
* 2、自定义拦截资源 基于redis 实现令牌桶过滤
*/
/*
* 2.1、自定义KeyResolver
*/
@Component
public class IpAddressKeyResolver implements KeyResolver {
@Override
public Mono<String> resolve(ServerWebExchange exchange) {
return Mono.just(exchange.getRequest().getRemoteAddress().getAddress().getHostAddress());
}
}
/*
* 2.2、application配置 过滤器key:vulue-》name和args模式
*/
- id: ratelimiter_route
predicates:
- Path=/ratelimiter/**
filters:
- StripPrefix=1
- name: RequestRateLimiter
args:
deny-empty-key: true
keyResolver: '#{@ipAddressKeyResolver}'
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 2
uri: https://www.baidu.com/
/*
* 2.3、redis设置
* 2.3.1、pom引用redis配置
* 2.3.2、application配置redis
*
*/
/*
* 2.3.1、pom引用redis配置
*/
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
/*
* 2.3.2、application配置redis
*/
spring:
redis:
host: 192.168.134.130
port: 6379
password: winning.2019
限流:429

2.3.3、动态路由
2.3.3.1、actuator
/*
* 1、开启actuator监控
* 1.1、引入actuator pom文件
* 1.2、application配置
*/
/*
*1.1、引入actuator pom文件
*/
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
/*
* 1.2、application配置
*/
management:
endpoints:
web:
exposure:
include: "*"
.
1)、查看路由:get请求 http://ip:端口/actuator/gateway/routes(/routei_d:指定路由信息)
2)、新增路由:post请求 http://ip:端口/actuator/gateway/routes/新增路由id,入参json格式参考下图

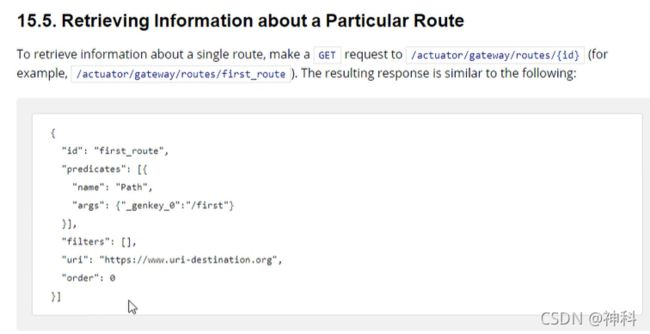
.
.
测试示例:
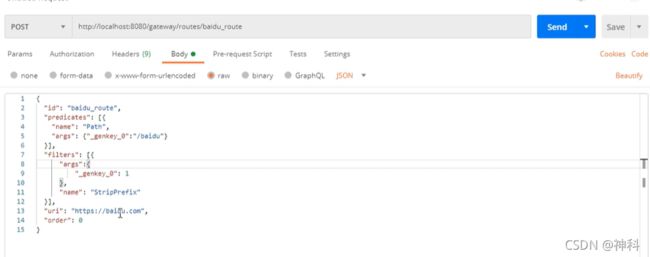
.
3)、刷新路由:post请求 http://ip:端口/actuator/gateway/refresh

.
4)、删除路由:delete请求 http://ip:端口/actuator/gateway/routes/delete_route_id

.
5)、持久化路由信息:
内存缓存:AbstractGatewayControllerEndpoint.save -> RouteDefinitionWriter.save -> RouteDefinitionWriter.save ->InMemoryRouteDefinitionRepository.save
自定义缓存:
/*
* 自定义redis路由持久化缓存
* 命名以RouteDefinitionRepository结尾,实现RouteDefinitionRepository类
*/
@Component
public class RedisRouteDefinitionRepository implements RouteDefinitionRepository {
private final static String GATEWAY_ROUTE_KEY="gateway_dynamic_route";
@Autowired
RedisTemplate<String,String> redisTemplate;
/*
* 获取redis路由配置
*/
@Override
public Flux<RouteDefinition> getRouteDefinitions() {
List<RouteDefinition> routeDefinitionList=new ArrayList<>();
redisTemplate.opsForHash().values(GATEWAY_ROUTE_KEY).stream().forEach((route)->{
routeDefinitionList.add(JSON.parseObject(route.toString(),RouteDefinition.class));
});
return Flux.fromIterable(routeDefinitionList);
}
/*
* 保存路由配置到redis
*/
@Override
public Mono<Void> save(Mono<RouteDefinition> route) {
return route.flatMap(routeDefinition -> {
redisTemplate.opsForHash().put(GATEWAY_ROUTE_KEY,routeDefinition.getId(), JSON.toJSONString(routeDefinition));
return Mono.empty();
});
}
/*
* 删除路由配置到redis
*/
@Override
public Mono<Void> delete(Mono<String> routeId) {
return routeId.flatMap(id->{
if(redisTemplate.opsForHash().hasKey(GATEWAY_ROUTE_KEY,id)){
redisTemplate.opsForHash().delete(GATEWAY_ROUTE_KEY,id);
return Mono.empty();
}
return Mono.defer(()->Mono.error(new Exception("routeDefinition not found:"+routeId)));
});
}
}
Slueth 链路追踪
一、技术选择:Zipkin、Pinpoint、SkyWalking、CAT、Spring Cloud Slueth
二、信息:traceId + spanId+Annotation(client sent、server recieved、server sent、clinet recieved)

三、集成(Zikpin收集)
/*
* 1、添加依赖
*/
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
/*
* 2、安装zipkin
*/
/*
* 3、application配置
*/
sleuth:
sampler:
probability: 1.0 //发送百分比
zipkin:
base-url: http://192.168.216.128:9411/
多线程组件封装!!!
spring cloud alibaba
算法
问题
注册中心对比
配置中心差异对比
1、权限管理
2、高可用特性
3、通信通信
4、数据更新的方法
5、
源码分析
技术点分析
网络
1、断网tcp连接还在吗:https://mp.weixin.qq.com/s/0YFsUWL6e9r_aDrCZeTK3w
java基础
1、ArrayList和LinkList哪个更占用空间
.
一般情况下,LinkedList更占用空间,因为LinkedList是基于双向链表实现的,每个节点需要维护直线前后地址的两个节点。
如果数据量刚好超过ArrayList的临界值时,ArrayList扩容原来数组一般的容量,可能会更占用空间,不过,因为ArrayList的数组变量是用transient关键字修饰的,如果集合本身需要做序列化的话,ArrayList这部分多余的空间不会被序列化
2、String 转int 用 Integer.parseInt,不用Integer.valueOf(内部利用parseInt(s, 10)转换成int,然后Integer.valueOf转换成Integer),减少不必要的装箱拆箱
3、使用Collection.isEnpty检测空,时间复杂度O(1);Collection.size()时间复杂度O(n)
4、使用StringBuilder拼接字符串:一般的字符串拼接在编译器java会进行优化,但是循环中的java编译器无法执行优化,建议使用StringBuilder
5、频繁使用Collection.contains方法使用Set:List的contains时间复杂度O(n),HashSet采用hashmap时间复杂度O(1)
6、反射
当父类注解中用@Inherited修饰,子类getAnnotations()才能获取得到父亲的注解以及自身的注解
Class<Sub> clazz = Sub.class;
System.out.println(Arrays.toString(clazz.getFields())); // 自身和父亲的公有字段
System.out.println(Arrays.toString(clazz.getDeclaredFields())); //自身所有字段
System.out.println(Arrays.toString(clazz.getMethods())); //自身和父亲的公有方法
System.out.println(Arrays.toString(clazz.getDeclaredMethods()));// 自身所有方法
System.out.println(Arrays.toString(clazz.getConstructors())); //自身公有的构造方法
System.out.println(Arrays.toString(clazz.getDeclaredConstructors())); //自身的所有构造方法
System.out.println(Arrays.toString(clazz.getAnnotations())); //获取自身和父亲的注解
System.out.println(Arrays.toString(clazz.getDeclaredAnnotations())); //只获取自身的注解
7、LinkedHashMap怎么保存有序性
spring
1、ImportBeanDefinitionRegistrar动态注册bean
springboot的优势
数据库
1、数据库优化点:索引+锁
2、mybatis查询条件不使用where 1=1
where 1=1 数据库系统无法使用索引
3、
多线程
spring cloud
1、Eureka Client不要在SpringBoot启动类上标注@EnableEurekaClient注解也可以向注册中心注册的原因
1.1、基本配置:springboot工程作为EurekaClient向注册中心的基本配置如下
1)、配置文件设置,Eureka.client.enabled=true(默认true)
2)、springboot启动类标注@EnableEurekaClient
1.2、去掉@EnableEurekaClient也能注册成功的原因
1)、EurekaClientAutoConfiguration 自动配置类和@ConditionalOnProperty注解
@Configuration(proxyBeanMethods = false)
@EnableConfigurationProperties
@ConditionalOnClass(EurekaClientConfig.class)
@Import(DiscoveryClientOptionalArgsConfiguration.class)
//eureka.client.enabled属性值为true会初始化此类
@ConditionalOnProperty(value = "eureka.client.enabled", matchIfMissing = true)
@ConditionalOnDiscoveryEnabled
@AutoConfigureBefore({ NoopDiscoveryClientAutoConfiguration.class,
CommonsClientAutoConfiguration.class, ServiceRegistryAutoConfiguration.class })
@AutoConfigureAfter(name = {
"org.springframework.cloud.autoconfigure.RefreshAutoConfiguration",
"org.springframework.cloud.netflix.eureka.EurekaDiscoveryClientConfiguration",
"org.springframework.cloud.client.serviceregistry.AutoServiceRegistrationAutoConfiguration" })
public class EurekaClientAutoConfiguration {
}
.
2)、EurekaClientAutoConfiguration @Bean注解 装配 EurekaAutoServiceRegistration
@Bean
@ConditionalOnBean(AutoServiceRegistrationProperties.class)
@ConditionalOnProperty(
value = "spring.cloud.service-registry.auto-registration.enabled",
matchIfMissing = true)
public EurekaAutoServiceRegistration eurekaAutoServiceRegistration(
ApplicationContext context, EurekaServiceRegistry registry,
EurekaRegistration registration) {
return new EurekaAutoServiceRegistration(context, registry, registration);
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingRefreshScope
protected static class EurekaClientConfiguration {
}
.
3)、EurekaAutoServiceRegistration类SmartLifecycle start注册
public class EurekaAutoServiceRegistration implements AutoServiceRegistration,
SmartLifecycle, Ordered, SmartApplicationListener {
private static final Log log = LogFactory.getLog(EurekaAutoServiceRegistration.class);
private AtomicBoolean running = new AtomicBoolean(false);
private int order = 0;
private AtomicInteger port = new AtomicInteger(0);
private ApplicationContext context;
private EurekaServiceRegistry serviceRegistry;
private EurekaRegistration registration;
public EurekaAutoServiceRegistration(ApplicationContext context,
EurekaServiceRegistry serviceRegistry, EurekaRegistration registration) {
this.context = context;
this.serviceRegistry = serviceRegistry;
this.registration = registration;
}
@Override
public void start() {
// only set the port if the nonSecurePort or securePort is 0 and this.port != 0
if (this.port.get() != 0) {
if (this.registration.getNonSecurePort() == 0) {
this.registration.setNonSecurePort(this.port.get());
}
if (this.registration.getSecurePort() == 0 && this.registration.isSecure()) {
this.registration.setSecurePort(this.port.get());
}
}
// only initialize if nonSecurePort is greater than 0 and it isn't already running
// because of containerPortInitializer below
if (!this.running.get() && this.registration.getNonSecurePort() > 0) {
//注册
this.serviceRegistry.register(this.registration);
this.context.publishEvent(new InstanceRegisteredEvent<>(this,
this.registration.getInstanceConfig()));
this.running.set(true);
}
}
}