文件系统理解
先前的博客我写了关于缓冲区的理解,顺便提及了在内存的文件是怎样管理的,本文就来描述在磁盘上的文件是怎么样。但要先了解了解磁盘。
在笔记本上机械磁盘被固态硬盘代替,因为固态硬盘更快,而且方便携带,机械硬盘若是受到外部碰撞,非常容易损坏,但在大型服务器的存储中机械磁盘几乎不会被代替,因为要控制成本,效率虽然会慢,但是这里面存的一般是用户比较旧的数据,例如一年前的聊天记录,你几乎不会再看了,所以没必要追求IO的速度,这点挺巧妙的。
但如果是你立刻可能会看到的,例如刚发的朋友圈,那就会放在大量固态硬盘的存储集群上,既保证效率,又保证成本。
一 认识硬件---磁盘
计算机中唯一有机械运动的设备,存储时会要有机械运动辅助,因为数据都在磁盘的一个一个的磁性区域,要寻找访问这些区域是靠机械运动,所以注定比固态硬盘这些电传输慢,因为电传输的速度貌似是接近光速的。

摔了容易损坏,因为磁头和盘面很接近,若是在在打开状态下摔了电脑,磁头会和高速移动的盘面接触,直接损坏硬件,所以机械磁盘退出便携式笔记本是必然。同理,磁盘内也不能有灰尘,否则在高速运动下,会刮花盘面,逐渐造成数据缺失。
学了这么久的计算机,我们很早前就听说一个常识,那就是计算机内只认识0和1,这是因为计算机内的各个硬件是靠电路链接,比较容易使电路呈现两种状态,通电,断电,假如我们想让计算机再认识一个2,那就要能让电路呈现第三种状态,只能通过电流值,例如某个电流值以下是1,以上是2,但是电流是会出现波动的,如果在传输数据时,一旦电压不稳,你本来想传2,结果变成了1,影响是什么呢,我如果让发电站故障一下,我能影响全世界的运算结果。科学家们解决不了电流稳定的问题,那就只能让电路只表示两种状态,由此计算机内一切的数据都是二进制。总而言之,所以硬盘接收到的也只能是0和1,但是磁盘不是靠电存的,但是一定要有两种状态能分别表示0,1。如下,初识磁盘的储存过程。
首先磁盘收到来自内存的电信号,接收来自内存的数据以及存储位置,磁头拿到位置后进行定位,定位后磁盘如何存储数据,储存规则: 可以认为磁盘就是一个个小的有磁性的区域,这个磁性区域有N级和S级,规定N级在上,S级在下,这个磁性区域表示1,相反表示0,如果我们通过某种手段把这个磁性区域的磁级逆置了,就相当于往该区域写了个1或0。

那读数据估计就是和磁头有关了,磁头判断该区域的上方是N级还是S级,从而判断这个磁性区域是1还是0。
而要销毁这个磁铁的磁力,只能烧毁,不能直接删除文件达到删除磁盘上的数据的目的吗?不行,因为我们删除一个文件不是删数据,而是更改一些属性数据。在解释文件系统和文件系统拓展时会提及,到时候我们就能理解为什么删除一个文件很快。而下载一个文件则很慢。
二 对磁盘的抽象理解
先前已经大致了解了磁盘的大体结构,工作原理,可是磁盘上有那么多的磁性区域,我存储和读写数据如何寻址?
设计上规定:磁盘的基本单位是一个扇区,下面是一块盘面的扇区图。一个扇区大小是512字节,一个磁道内会有多个扇区,一个完整的空心圆弧就是一个磁道,这样多个磁道就变成了一个完整盘面。

一个磁盘会有多个盘面和对应的磁头。

所以如何寻址就变成了如何定位扇区的问题,先来看看机械运动如何确定扇区:一开始就要先确定盘面,确定让哪个磁头运动,随后磁头沿着半径运动就是在确定磁道,沿着圆弧方向就是在确定扇区。这种确定磁头,确定磁道,最后确定扇区的定位扇区方式称为CHS(英文首字母),访问磁盘的消耗:磁头确定磁道,以及盘面自转帮磁头确定扇区,所以说访问磁盘的效率取决于机械运动,读取数据的消耗似乎比找到数据的消耗还小,所以为了提高效率,一定要把数据尽量放一起,就不用进行太多的机械运动。

噢,我知道了机械运动如何确定扇区,但是我告诉了磁盘什么数据让磁盘知道我要访问哪个扇区呢?要解释得再来看看对磁盘的抽象理解。
我们已经知道磁盘实质上就是一个个的扇区,先把所有的扇区按顺序像数组一样整齐排列。此时我们把磁盘抽象为一个线性的大数组,那每个扇区天然就有个下标。这些下标就是扇区编号。
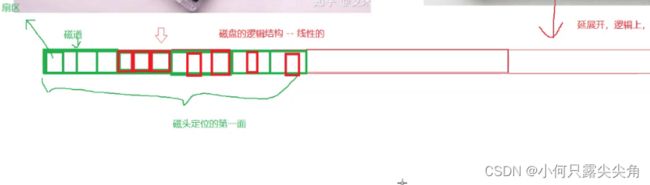
我们认为各个磁道上的扇区数量是一样的,虽然外侧的圆圈更大,但为了方便理解,我们就认为外侧的扇区比较稀疏,内侧的扇区比较密集,所以扇区数量一样。而扇区编号就是书本上提到的LBA地址,所以设计者肯定是让磁盘能根据磁道号找到对应的磁道,根据扇区编号找到扇区,从而读取数据。转换如下。

为什么还要弄一个LBA地址出来呢,你直接用个CHS地址不行吗,有一种解释是:LBA让os不用关心磁盘结构?磁盘内部有一个控制器,它负责将LBA地址转为CHS地址让磁头去访问,但对于os来说自己只使用LBA地址,就不用关心地址转换,更不用关心磁盘结构是什么,反正只要拿着这个LBA地址,磁盘会把数据给我,其它的我不关心。(老实说这里的解释我还是有点模糊,毕竟没经历太多)
显然os不需要定义一个这么大的数组,只需要知道一个扇区多大,然后磁盘总容量多少,这样就知道了总扇区数,除以盘面,甚至可知每个盘面的扇区数,再由磁道数得知每个磁道上平均的扇区数,当然,本文是在每个磁道扇区数一致的情况下讨论的,如果不一致,那肯定要多记录一些参数。
磁盘也有寄存器,用来快速获取cpu的指令,先告诉磁盘写还是读,再告诉磁盘读写的地址,以前是通过数据寄存器一点点传,因为最后要等寄存器数据存到了磁盘的位置,才可以继续从内存读到寄存器,现在来理解就是,计算机内还有个DMA芯片,负责IO,磁盘可以和DMA芯片合作,直接读内存数据导入到磁盘,中间不经数据寄存器,但速度快不了多少,因为时间消耗主要是写到磁盘。

三 文件系统
磁盘划分
我们现在只知道怎么写,但是不知道能不能写,因为不知道这个扇区有没有被占用,所以需要文件系统来管理。首先来看看磁盘空间是如何被管理的——分区管理。

可是这实际上是一个个的扇区啊,那我怎么表示D盘有哪些扇区,很简单,用start记录起始扇区下标,end记录区域内最后一个扇区下标,然后每个分区分别初始化两个下标就可以实现分区了,而给定一个分区的容量和扇区大小,就知道这个区域内有多少扇区了,然后先前分区的end下标+1就是下一个分区的起始扇区下标,然后加上扇区数量就是下一个分区的end扇区下标。

为什么要分区呢?首先是安全,由于分区了,每个区域都会有自己的管理系统,这样一个系统被破坏就不会影响其它区域的系统,查资料还说因为以前的病毒经常会破坏c盘,所以只能分区,让c盘承受伤害。还有个原因是好管理,下面再细说。
如果我们的文件系统能管理200个G,那就可以把这套系统复制到其它分区,假如大小为150个G,就能管理150个G,因为200个G内文件的各种属性可以被管理,那150G的文件属性也没问题。
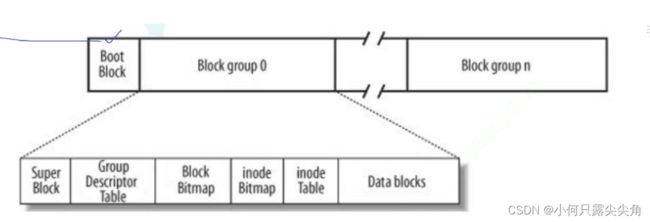
分区后又分成一个个Block group(分组)。每个group block大小可能为10g。Boot Block存的是os开机后需要的管理信息,让在内存的os知道磁盘的分区情况等,有点抽象,简单理解就是存了os,可以不理会。
为什么要再划分呢?首先文件系统肯定要加载到内存,因为文件系统本质上是os的一部分,因为磁盘也是硬件,当然要被os管理,如果你不分区分组,要加载到内存的文件系统是会占用许多内存的,分区分组后,我们进程使用了哪个文件,将文件所在分区的文件系统加载到内存即可,能省一点是一点啦。还有就是和分区原因有个公共点,那就是方便管理,如何理解方便管理呢?会在文件系统拓展解释如何文件做增删改查时顺便抛出解释。
BlockGroup内部介绍
终于要开始讲文件系统了。
1 super block(超级块)
首先规定着各分组中的文件系统内的GDT,Data Blocks等信息的占用的空间,分布顺序,剩余空间,还有整个分区的基本使用情况,也就是下图的内容。

不会存在每个组上,只会存两三份,一方面是为了保险起见,多存几份,免得丢失后,os不知道磁盘的当前分区的各个分组的边界,这样就无法将inode编号转为具体扇区编号,下面介绍还有很多操作需要超级块内的信息,如果没了,那些操作都做不了了,整个分区就完蛋了,还有一方面是不能存太多份,可以理解为每次创建文件后超级块内某些信息要修改,存太多份超级块维护成本太高。
2 Group Descriptor Table(GDT)
块组描述符。 虽然下面Block Bitmap和inode Bitmap已经描述了inode Table和Data Blocks的使用情况,但是若要统计还剩下多少个,或者说剩余有效空间大小,就得遍历Block Bitmap和inode Bitmap,这比较浪费时间,所以就用Group Descriptor Table保存了,使用了一个,GDT内部的记录inode数量的变量就--,想知道数据块空间剩余,用block剩余数量*一个块大小即可。
3 InodeTable
一个文件的属性会被分配128字节,所以一个扇区会存在多个文件的属性,如何区分,就是用属性中的inode值。
那inode值哪来,谁分配的,首先磁盘所有分区的inode范围是被规定好的,那由一个文件一个inode编号得出,能创建的文件是有限的,inode给各个组的分配也是规定好的,所以当要创建文件时,会先看在哪个分区创建,然后遍历分区内的小组,先在GDT看看当前组还有没有inode剩余,没有就去下个组,然后遍历inode Bitmap,有空位就用这个,然后加上当前组的起始inode(超级块存着),就是分配给文件的inode编号了。
inode表内部存多个文件的属性,内部结构应该是类似哈希表的。如何查文件inode编号,如下图。

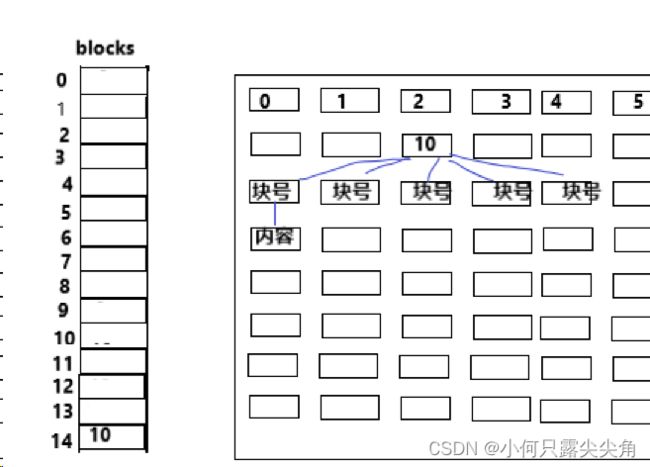
这就是文件属性和内容分开存的含义,而且文件属性一定存着文件内容占了哪些块,还有文件属性内没有文件名,那我们平时找文件都是用文件名,如何和inode对应,简单理解就是目录文件的内容中会保存自己目录下的文件名和inode对应关系,没错目录也是个文件。那inode如何找到自己的内容块,在inode内有一个数组,这个数组内存的就是内容块编号。

0下标到11下标中存块号,这些块号对应的块存文件内容,后面存的块号对应的块存的不是文件内容,而是专门存块号。12下标和13下标对应的块专门存块号,又称二级索引,大约能存2048个块号,能存内容8mb。但是不意味着文件最大只有8mb。

14号数组内的类似三级索引,这个对应的块专门用来存二级索引的,如下图,10号块内存块号,这些块号指向的块存的还是块号,最后指向的才是内容,这样就能映射一百万个块,差不多4G了。
4 DataBlocks
存文件内容,是以块为单位的,大小是4kb,也就是说哪怕你文件只有一个字节,也要给你分配4kb,原因:虽然磁盘的基本单位是扇区,但是os在访问时却是以4kb为单位,一次刚好访问一个数据块的文件内容,就是为了减少io次数,提高效率,而且这最多只会多读一个块,但磁头运动次数大大减少了,效率还是会提高的。
所有文件内容都在这个DataBlocks内,这该如何查找呢?
从前面超级块的介绍得出,显然我们能从中知道一个分组的起始扇区编号,以及分组内各区域的起始扇区编号。而且一开始整个空间的大小,各个区域空间也是超级块规定好的,显然Data Blocks内的块数也是可知的,所以每个数据块天然就有了自己的编号。编号作用:知道Data Blocks的起始扇区编号和数据块大小,只要再知道数据块编号,那任意数据块的扇区编号也就知道了,就能让磁盘找到了。所以文件属性只要存了数据块编号,就能转为数据块的扇区编号,然后找到文件内容。当然还可以用来和bitmap上面的比特位进行映射,如下。
由上得,inode和数据块数量是规定好的,所以会出现inode分配完了,但数据块还有,inode还有但是数据块没了,没办法解决。
5 Block Bitmap和inode Bitmap
Block Bitmap和inode Bitmap分别标记inode和数据块是否被占用,比特位的位置分别和inode编号和block编号映射起来,比特位上的内容表示inode,block是否被使用,由此得我们删除文件时只要将对应这个位图上的比特位清0,然后在超级块以及GDT内修改inode和block剩余就可以了,所以删除一个文件的速度比较快。什么!你说为什么不删内容,没必要,直接让下个使用该空间的文件覆盖写就可以了,就算没覆盖完,显示文件内容时也不会影响,因为文件有大小的嘛,你别把垃圾数据算成文件大小,显示文件内容就按文件大小来显示即可。
周边问题解释1
inode编号如何与bitmap下标对应? 首先整个分区分组的inode的数量,起始inode数值是确定的,组内的inode范围也就知道了(超级块存着),也就可以提前设置位图来管理所有的inode的。
周边问题解释2
规定:inode值是在一个区内是唯一的,但在其它区,可能会重复,因为我们可以判断文件在哪个区,所以没必要让不同区的inode值不一样,诶你是怎么判断文件所在区的呢?简单理解就是分区的文件系统会被加载到内存中,os通过管理这个文件系统来管理整个分区,而这个文件系统会被加载到某个目录下,这个动作称为挂载,我们创建文件时也会有个路径,或许这个路径就是属于某个分区的文件系统管理,在这下面创建的都属于这个分区,所以说我们根据路径可以判断分区。
而为了让一个分区内的文件具有唯一的标识符,所以组和组之间的inode值范围是不一样的,保证分配时不会出现一个inode标识两个文件,inode怎么判断属于哪个组呢,很简单,前面说了每个组的inode范围是知道的,所以用inode编号可以判断在哪个组,而且和block编号一样,都能被转为具体的扇区编号,此时inode值不仅在一个分区内用来标识文件,还可以用来判断所在分组,减少检索范围。
周边问题解释3
由此得而且文件属性和文件内容应该是要在一个块组内的,因为各个分组的数据块编号是会重合的,仅仅凭借文件属性内存的数据块号是无法区分在哪个分组的。
四 文件系统拓展
当我们大致了解了文件系统内的各个字段,接下来就开始用对这些字段的了解来解释一些问题。但还需要一点点知识准备。
1 理解目录
我们一般访问文件都是只用文件名,例如cat test.c,找文件不是用inode吗,系统如何将文件名转为inode呢?靠目录。目录也是文件,所以有自己的属性,里面有权限信息,而内容存的是目录下的文件名和inode的映射关系。
好,目录也是个文件,要访问文件内容就要先找到文件,找文件又要inode,那我怎么获取目录的inode,从上级目录中找,因为目录名和自己的inode就保存在上级目录文件的内容中,噢,所以找一个文件要带路径。
诶,不对啊,到时候我们要一直找到根目录的,难道说根目录的inode操作系统知道?我觉得差不多可以这样理解,所以找到一个文件必须要有路径,例如/usr/bin/test,此时就是现在根目录下找到usr目录的inode,然后再找到bin目录的inode,然后在bin文件内容找到test文件的inode,最后找到文件属性和内容。
那用相对路径如何查找,有相对路径的前提是先找到当前目录,然后再解析相对路径,找到分叉点,再根据路径继续找文件名和indoe的映射关系,由上得,这样太慢了,所以目录dentry缓存会记录历史上常用的目录的inode。
目录常识底层解释
所以说目录下不能有同名文件,因为文件名和inode是kv映射的,文件名就是key。
创建文件要把文件名和inode写到目录的数据块中,没有"w"权限,就不能创建文件,肯定是先拿到目录文件内的权限信息了,判断后不让往数据块写。
同理,没有"r"权限,无法ls查看目录下的文件,因为此时不让读目录文件的数据块了,也就拿不到文件的文件名和inode,更拿不到文件的属性。
没有"x"权限,也无法cd进入该目录,去查看目录文件属性,发现目录的权限没有"x",也就不让cd了。
2 对磁盘格式化后做了什么
按我们现在的理解就是会把文件系统上的bitmap那些字段都清空,还有就是格式化可能会用其它的文件系统来格式化,也就是说下图的文件系统字段重新写入,因为每个文件系统对分区,分组的要求可能不一样,所以一旦格式化,要改所有的文件系统信息。
3 新建文件要做什么
先用路径判断分区(文件系统周边问题解释中曾提及),然后去GDT看组内有无剩余的inode,然后去inode Bitmap里看哪个比特位是空的,最后要加上当前组的inode起始编号,这就是分配inode的过程。还要分配数据块,也是如此,先去GDT看看有无剩余,再去数据块位图找空数据块的编号,然后把块号填入到属性中,随后就直接跳转到对应数据块写数据了。
4 那如何查找一个文件
现在我们就知道cat test.c,是由路径找到目录文件内容(虽然我们没有明显写路径,但是环境变量提供了,你试试查看其它目录下的文件,就一定要带路径),再提供对应文件的inode值,然后用inode值确认分组,在分组内的inode Table找到文件属性,文件属性内有数据块编号,前面已经提过如何用数据块编号跳转到对应扇区。
5 删除文件要做什么
删除一个文件,也就是删属性和内容,所以要先查找文件(参考前面查找文件)。至于删除文件的操作,先前在5 Block Bitmap和inode Bitmap介绍曾提及过,也就是改一改位图上的比特位。
6 修改一个文件做什么
修改一个文件本质就是先查找文件属性和内容,然后再修改,所以具体操作和查找文件相同。
由此得对文件做增删改查本质上是要对这些位图做增删查改,所以当然是位图越小越好,不然分配inode遍历位图比较费时间,所以要分区分组,把管理区域变小,才能快速遍历位图实现增删改查。
五 软硬链接
1 建立软链接
1 ln -s d1(目录) d2(目录)
此时会创建一个软链接,名字为d1,是和d1链接。目录d1,d2是已经创建的,目录也是文件,也可以被链接。

会认为是要在d2下创建一个软链接和d1链接,但又没写文件名,所以会默认在d2目录下面创建一个d1文件,然后作为d1目录的软链接,但是我们写的目标文件和源文件都没带路径,这个时候出来的软链接会有问题。而且我们可以看到的是此时这个软链接名为d1,然后inode为786508,和d1的inode值786460不同,这说明软链接文件和被链接的文件是两个不同的文件。

而如果链接对象是一个已经存在的文件,然后后面又不写路径和文件名,则会认为要在当前路径下创建一个软链接名为test.c,会引发引发命名冲突,因为软链接其实还是文件,文件名和inode要存到目录文件的内容中,所以不能重复。

![]()
老老实实带完整路径再测试一下。此时的颜色就正常了。
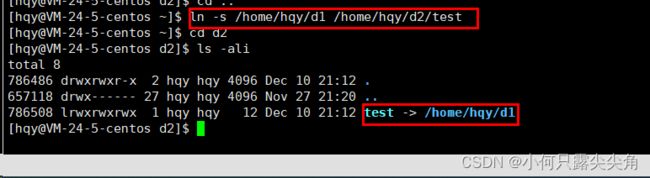
也可以正常使用。先进入d1目录查看目录下的文件,再cd d2目录下的软链接,ls查看出的文件信息是一样的。注意:我此时是用一个软链接和一个目录进行连接,才可以对软链接使用cd命令,估计是cd内部做了判断,会去获取软链接内存的路径,看看指向文件是否是目录,是目录的话,cd test就被转换成cd /home/hay/d1。
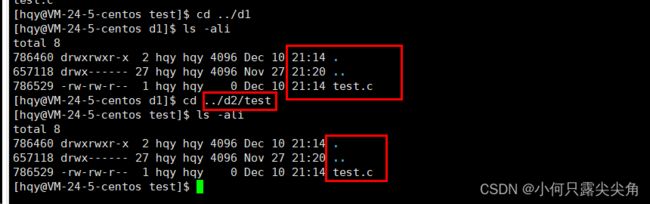
不带路径是默认在当前目录下创建软链接,前面不正常应该算是写了路径又没写完整。

如果目标文件d4不存在,会创建一个目标文件d4去链接,我本来想测试目录去链接目录,现在看来没有这种情况,或许是ln命令规定创建一个链接文件作为其它目录文件,普通文件的软链接,而不是目录以及普通文件做别人的软链接,这一点我也是运气好才理解清楚。

2 软链接的本质和应用
软链接的本质:在文件内容中存了指向文件的路径,就像是windows下的快捷方式,为什么不能存inode,因为要用路径判断分区和获取inode,再用inode判断分组找文件,所以不如直接给路径。
软链接使用场景:可以简化使用难度,有时候我们要在当前目录下运行一个可执行文件test,但是其路径太深,每次运行都要带路径。

我们就可以用软链接简化,直接./test就可以了,值得说明的是既然软链接内存的是被链接文件的路径,如果我们修改了这个文件的路径,此时软链接会失效。

如果此时用硬链接呢?
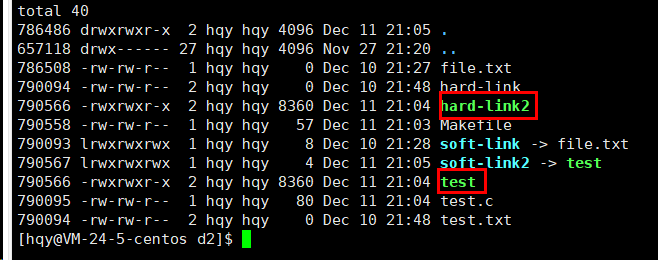
也可以跑,那我就有点疑惑了,那用硬链接和用软链接好像没区别啊?有没有种情况硬链接无法使用,只能软链接上,当然有,这就要结合软硬链接的本质来说了,硬链接如何查看文件内容呢?先通过自身的路径判断分区,然后解析路径获得inode,最终找到inode,问题就出在用自身路径判断分区上,这就规定了硬链接必须和被链接文件在同一个分区,而软链接则不需要。

3 建立硬链接
ln 源文件 路径+硬链接名。
对于硬链接的使用有几点要说明,1 首先被链接文件绝对不能是目录,bash会检查,不是权限的问题,而是直接的硬性要求,直接杜绝这种情况,因为容易造成环路问题。

此时如果执行find / -name test.c,如果找到了这个硬链接,那就会跳转到root继续找,一直死循环。让find禁止对硬链接搜索治标不治本,如果很多函数都有这个问题,难道一个个禁止对硬链接操作吗,所以就直接禁止对目录进行硬链接了。
2 如果是对test.c文件做硬链接,此时d2是个目录,不会认为是d2这个目录做test.c的硬链接,而是认为你没写目标文件名,然后在d2目录下创建一个test.c的目标文件,作为硬链接。和软链接情况类似。
4 软链接的本质和应用
如下图,硬链接的本质是在特定目录的文件内容上增加了文件名和inode的映射关系,是在哪个目录文件的内容增加呢? 就是硬链接名前面的路径指定的目录,如果不写就是在当前目录下增加。

软连接,硬链接的第一个区别就出来了,前者为不同文件,后者为同一文件——由被链接文件的inode的值和软硬链接文件的inode比较可得,再次证明文件属性内无文件名,如果保存了,那从文件属性内取得的文件名应该是一样的。还有个小细节,我们会发现file.txt的属性有个数值从1变成了2,这个数称为硬链接数,是什么呢?我们可以测试一下,我们发现rm删除了test.txt后,这个数-1了。

其实就是inode内的引用计数,也就是用来记录有多少个文件名和inode数值对应,(注意:由于文件属性是struct inode,所以有时候称inode是指文件属性,而struct inode内还有个变量叫inode number,所以有时候称inode是指文件标识符inode数),那为什么inode内会有一个引用计数呢,可能就是为了服务于硬链接,免得rm文件直接就删了,而其它文件名还指向这个文件呢。
硬链接场景:.和..就是一种硬链接,.和当前目录链接,..和上级目录链接,/的引用计数由.和子目录的..和自己构成,那为何不用软连接呢,软链接也可以和目录链接啊,我想可能是因为软链接是单独的文件,属性是和链接文件不一样的,对就是因为属性,或者说是权限属性,.和..作为硬链接的话,权限信息是不变的,而作为软链接的话,权限会发生改变,就可能使得我本来有权限访问目录,却没有权限用你这个软链接,所以就直接用硬链接。
诶,不对啊,你前面不是说不能对目录进行硬链接吗,那.和..不就是对目录进行链接吗,不用担心,前面的环路问题是因为搜索时会对硬链接也进行搜索,os规定.和..不被搜索,就不会出问题,毕竟os是规则的制定者,有大把的方式绕开规则,我们就不行了,当然.和..的作用也很大,使得linux产生了相对路径的概念,方便我们作路径跳转。
这篇博客中的软硬链接用到了不少文件系统的内容,为了完整性,只好放一起了,第一次写这么长的博客。