缓冲区介绍
一 什么是缓冲区
从c语言就一直听说我们敲键盘是把数据写到缓冲区,然后scanf从缓冲区读,当时也迷迷糊糊,不知道什么是缓冲区,为什么要有缓冲区,而且我在vs上几乎感觉不出来,我只知道我一执行完printf语句,终端窗口上就有显示,哪有什么缓冲不缓冲。
后来在linux下写了代码,发现printf带\n和不带\n在显示的时间上略有差异,此后开始逐渐了解缓冲区,先来认识认识系统缓冲区,首先我们已经知道fprintf,fwrite这些函数内部一定封装了系统调用write,因为文件是存在磁盘上,一个库函数怎么可能绕开操作系统直接把数据干到硬件上呢,必定是通过系统调用把数据给了操作系统,注意:设计者并没有让系统调用直接将数据给硬件,因为这样太慢了,fwrite要等write把数据写到硬件才能返回,所以为了效率,write也只是将数据写到一个系统的缓冲区,仍在内存中,随后系统才刷新到磁盘上,当然这还不够解释printf带\n和不带\n差异,再看看如下代码,用多个函数往显示器这个硬件打印数据。
情况1
#include
#include
#include
#include
int main()
{
printf("我是printf\n");
fprintf(stdout, "我是fprintf\n");
fwrite("我是fwrite\n", strlen("我是fwrite\n"), 1, stdout);
write(1, "我是write\n", strlen("我是write\n"));
return 0;
}
结果如下,打印到显示器上时,按代码顺序。

情况2
不带\n
#include
#include
#include
#include
int main()
{
printf("我是printf");
fprintf(stdout, "我是fprintf");
fwrite("我是fwrite", strlen("我是fwrite"), 1, stdout);
write(1, "我是write", strlen("我是write"));
return 0;
} 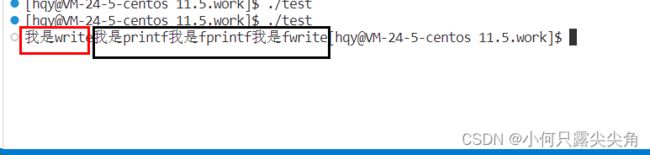
此时从上面对比来看,有两个要点,第一 是显示顺序,第二 是显示都排列在一行了。
原理解释
既然都是往显示器写,显然哪个函数的数据先到系统缓冲区,最后os刷新的时候一定是先刷给显示器。printf,fprintf这几个先调用怎么还比write还慢呢? 这就要再抛出一个知识点了,printf,fprintf,fwrite也不是在内部把数据给了write,让write写到系统缓冲区才返回,这样还是不够快,库函数的设计者为了效率,又弄出了一个缓冲区,称为用户缓冲区,这样fwrite这几个函数只要把数据丢到用户缓冲区就可以返回了。
当然用户缓冲区也是在内存,为什么往用户缓冲区写就比往内核写快呢,这个涉及到进程的身份切换,我举个例子吧,用户缓冲区就像是自己家的地,我想拿来种菜,直接撒种就可以了,而内核缓冲区就像是旁边的公家土地,虽然都很近,但你要种得先让公家同意,然后走流程,获批同意才可以。
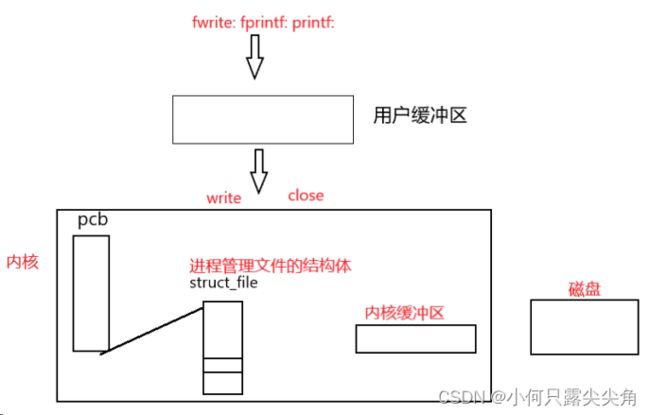
也就是说,虽然fwrite,printf这几个函数先调用,但是它们的数据卡在用户缓冲区了(要用用户刷新策略来理解),可是write则是直接往内核写的,不经过用户缓冲区,所以write打印显示在前面。
用户缓冲区刷新策略
种类1 无缓冲,一有数据就刷新。
种类2 行缓冲,碰到\n,或者进程结束才刷新。
种类3 全缓冲 缓冲区满了,或者进程结束才刷新。
如果用户缓冲区的数据是给显示器的,那就默认行缓冲,如果是给普通文件的,那就默认全缓冲。噢,所以printf不带\n,数据就一直在用户缓冲区,直到进程结束才刷新,而write则早早把数据写给内核缓冲区了。
到这里,还有一点周边概念要说明,linux中每个硬件都被当成文件来管理,也就会给硬件配套一个文件缓冲区,所以往硬件输出信息是独立的,但是如果open用同一方式打开一个文件,此时会有多个文件描述符,但只有一个缓冲区,如下代码,此时write用文件描述3和4写都是往一个文件缓冲区写。
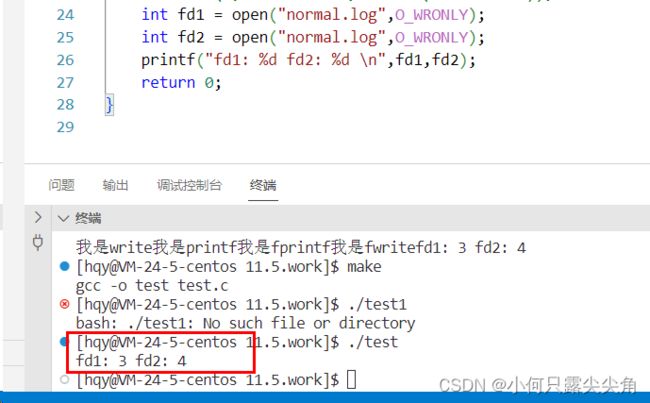
不过有时用户缓冲区也被称为文件缓冲区,大家在一些题目概念上看选项分析即可。
此时我们已经大致了解了缓冲区,接下来要结合更多情况来抛出一些结论。
二 再谈缓冲区
打印情况3
int main()
{
printf("我是printf");
fprintf(stdout, "我是fprintf");
fwrite("我是fwrite", strlen("我是fwrite"), 1, stdout);
write(1, "我是write", strlen("我是write"));
close(1);
return 0;
}
此时只有write的显示。
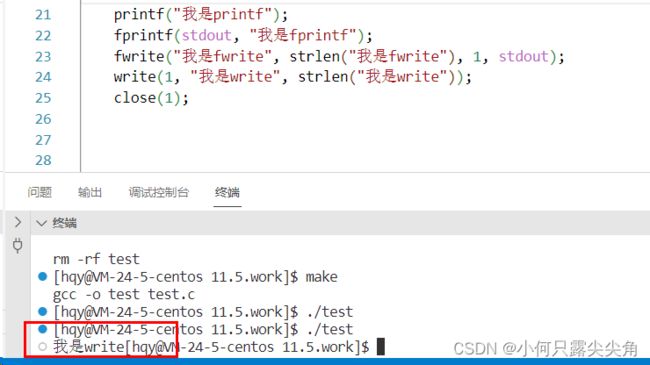
如果已经看懂了第一大点,就具备了理解这个现象的知识,只是需要再点一下,close是系统调用,系统调用在关闭文件时,一定会刷新内核缓冲区,实际上进程结束时也一定执行了close,凭什么你说close关闭文件,就要刷新缓冲区,我就不刷新,因为os不做无意义的事,只要维护了,就一定要把缓冲区用到极致,所以不影响write显示。
那为什么printf,fprintf打印不显示,因为close看不见用户缓冲区,刷新不了,用户缓冲区就像是用户自己malloc出来的空间,难道让内核设计之初就考虑哪块内存会有硬件的数据,然后执行close的时候,提前刷新到对应硬件的内核缓冲区,以免丢失,os凭什么还要帮你保存呢,你自己都不想保存,直接就close了,也不看看自己的用户缓冲区有没有数据,万一你就是不是保存到硬件上呢,那我os不是白费功夫,做得越多,错的越多,不做了!
所以进程结束时想调用write写数据到文件的内核缓冲区,结果一看,内核没了,那没办法,数据就只能随着整个进程的销毁被丢弃了。
打印情况4
int main()
{
printf("我是printf\n");
fprintf(stdout, "我是fprintf\n");
fwrite("我是fwrite\n", strlen("我是fwrite\n"), 1, stdout);
write(1, "我是write\n", strlen("我是write\n"));
fork();
return 0;
}
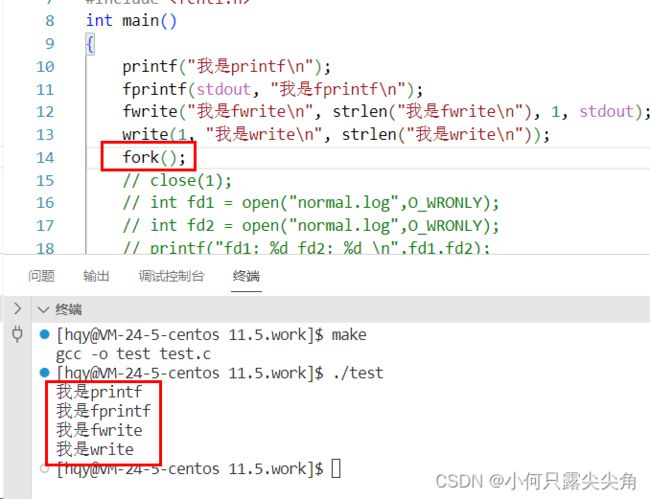
情况4比情况1多了一行fork,如图显示输出到显示器没区别,但是如果没带\n呢。

先前已经说过printf不带\n是卡在用户缓冲区,在进程结束才会刷新,缓冲区的数据也是数据,是数据子进程也会看到,那为什么会有两份呢,写时拷贝! 刷新完数据应该是对缓冲区做了修改,例如清空,以免和下次写的混淆,你都要清空父子进程共享的数据了,子进程能同意吗,父进程必须拷贝一份,然后改自己的那一份。不过文件描述符是共用的,因为没修改,strcut_file和对应缓冲区也是共用的,或许是因为这是属于操作系统的,不属于进程,不影响进程独立性,所以不会发生写实拷贝。
打印情况 5
这是最后一种情况了,了解完后,我们对缓冲区的认识就比较全了,就可以从容地探究为什么要有缓冲区,以及缓冲区在哪的问题了。
用户缓冲区刷新策略曾提过全缓冲,也就是往普通文件写是全缓冲,为什么显示器是行缓冲呢,因为方便观看,挤成一堆谁看得明白,反正设计的大佬不喜欢,所以就默认往显示器输入时为行缓冲。
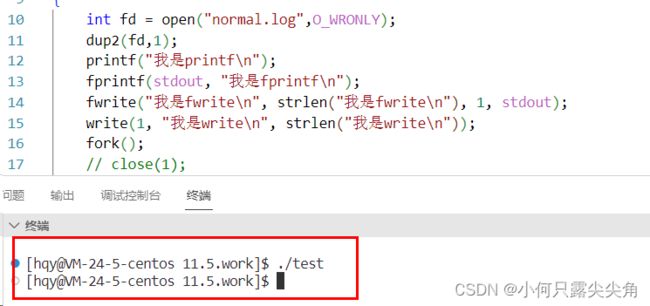
上篇博客-文件原理曾详细提及过重定向,就是用dup2,我们试着用一下,此时printf变成往一个普通文件normal.log文件。好像没什么问题,printf,fprintf,fwrite写的数据到了用户缓冲区,然fork创建子进程,父进程刷新时写时拷贝,所以往文件写了两份。write不复制,原因这是系统内的缓冲区,属于操作系统,多个用户共享。
错了,printf是带\n的,按理说应该是早就被刷新到内核了,最后创建子进程的时候,用户缓冲区应该是啥都没有的。
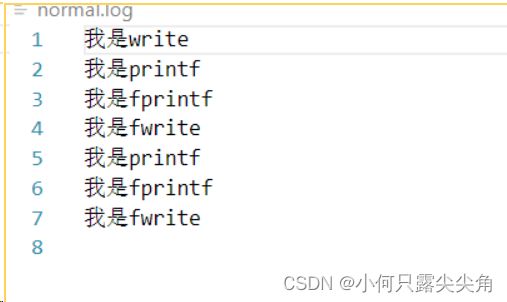
原理:因为此时变成了全缓冲,就算遇到\n用户缓冲区也不会刷新,我想os是能分辨出用户缓冲区是往显示器还是往一个普通的文件刷新的,应该在对应的struct_file结构体内有存文件标识,所以才会采用不同的默认刷新策略。

先前有篇博客进程终止和进程等待写过exit和 _exit,当时说不会刷新缓冲区,到现在,进一步来说,不会刷新的是用户缓冲区,但是会刷新系统缓冲区。
三 为什么要有缓冲区
1 能提高使用者效率
如果有大量的printf语句,缓冲区可以先保存输出结果,然后函数调用就返回了,然后根据刷新策略再刷新,可以减少调用系统接口的次数,虽然最后还是要写到系统缓冲区,但是调用一次write写一百个字符,和调用一百次write一次性写完,我想效率还是前者快一点。
2 还有配合格式化
将输入的常量字符串转换格式保存下来,然后对不符合标准的字符做处理,然后再刷新。
四 缓冲区在哪
我们已经知道内核缓冲区在os内核里了,那用户缓冲区在哪呢?我们说用户缓冲区是用户自己维护的一个空间,可是还是有点不太透彻。这就得好好说说什么是用户缓冲区了,我们知道fflush是会刷新缓冲区的,可是参数却只有FILE*这个指针,难道说缓冲区在FILE*内部吗?确实如此,那就是说缓冲区其实就是一段一段mallc出来的空间,然后一个个指针被FILE结构体保存。

c语言的库函数fopen每打开一个文件都会返回一个FILE结构体,这个FILE结构体内一定包含了一个文件描述符,同时内部维护了一个用户缓冲区,file对象是open一次创建一个吗,是的,那与之相关的内核缓冲区也是open一次创建一份吗,不是,是所有file共用一个内核缓冲区,后面我写匿名管道实现通信,我们会发现打开一个文件就只有一个缓冲区,学linux真的需要回顾,真的会有不少遗漏的知识点。
可是如果我从文件读数据到内核缓冲区,然后我又写入数据到内核,此时写入数据是否会和读入数据是否会冲突,我有种假设,首先read读数据到内核,会立刻给上层,此时是不允许写的,那这些数据被写入数据覆盖也没事了,可是如果又调用read,那之前写入内核缓冲区的数据会如何处理,是立刻刷新呢,还是保留,这就和内核的刷新策略有点关系了,我猜测是刷新,保留的话维护起来挺麻烦的。
五 跨平台性
我们用的函数,大都是对系统调用的封装,例如fopen是对open的封装,但open是linux的系统调用,如果说fopen封装了open,那为什么能在windows下跑呢,因为我不觉得windows和linux的系统调用会设计的一模一样。实际上是库的设计者写了两份代码,一份是封装了linux的系统调用接口,还有一份是封装了windows的系统调用接口,我们只要安装对应平台的语言库,就可以实现一句fopen在linux能使用,windows下也能使用,这就是跨平台性。