MySQL物理文件结构和SQL执行流程
我们可以登录已安装的mysql 服务 ,进入MYSQL 命令:mysql -h 【ip】-u【用户名】 -p
- MYSQL 物理文件结构
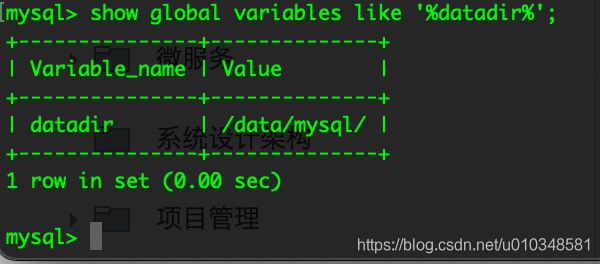
进入目录

mysql.err:错误日志文件
mysql.pid:记录mysqld进程的id,用于锁
ib_buffer_pool 缓存池,存放部分最近的查询记录和索引等,可以通过show variables like 'innodb%pool%'查看相关参数
ibdata1 innodb:表空间,如果采用innodb引擎,会默认10M大小
ib_logfile0: 事务日志文件,是确保事务的redo和undo,主要是确保事务的前滚和后滚,不是用来恢复用
ib_logfile1: 事务日志文件,是确保事务的redo和undo,不是用来恢复用
auto.cnf:记录mysql数据库实例的server_uuid,安装的时候初始化,master和slave的server_uuid不能一样
ibtmp1:临时表空间
mysql-bin.000001:二进制日志文件,用于恢复,主从数据同步等
mysql-bin.index: 二进制日志文件索引,存放二进制日志文件列表
mysqld_safe.pid:存放mysqld_safe脚本的进程id
performance_schema:系统数据库目录
sys:系统数据库目录
- 日志文件
MySQL通过日志记录了数据库操作信息和错误信息。
常用的日志文件包括错误日志、二进制日志、查询日志、慢查询日志和事务Redo 日志、中继日志等。
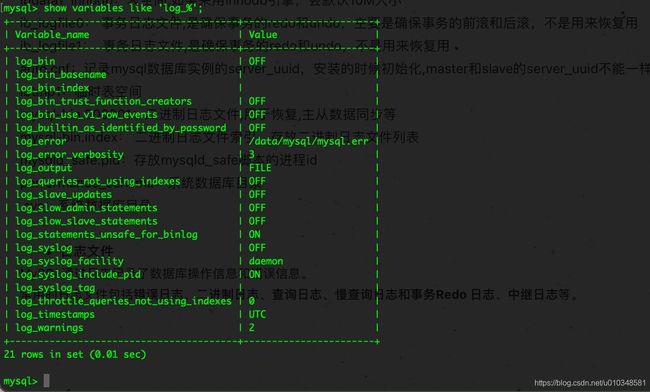
可以通过命令查看当前数据库中的日志使用信息
show variables like 'log_%';
错误日志(errorlog)
默认是开启的,而且从5.5.7以后无法关闭错误日志,错误日志记录了运行过程中遇到的所有严重的错误
信息,以及 MySQL每次启动和关闭的详细信息。
默认的错误日志名称:hostname.err。
错误日志所记录的信息是可以通过log-error和log-warnings来定义的,其中log-err是定义是否启用错
误日志的功能和错误日志的存储位置,log-warnings是定义是否将警告信息也定义至错误日志中。
二进制日志(bin log)
默认是关闭的,需要通过以下配置进行开启。:
log-bin=mysql-bin
其中mysql-bin是binlog日志文件的basename,binlog日志文件的完整名称:mysql-bin-000001.log
binlog记录了数据库所有的ddl语句和dml语句,但不包括select语句内容,语句以事件的形式保存,描述了数据的变更顺序,binlog还包括了每个更新语句的执行时间信息。如果是DDL语句,则直接记录到binlog日志,而DML语句,必须通过事务提交才能记录到binlog日志中。
binlog主要用于实现mysql主从复制、数据备份、数据恢复。
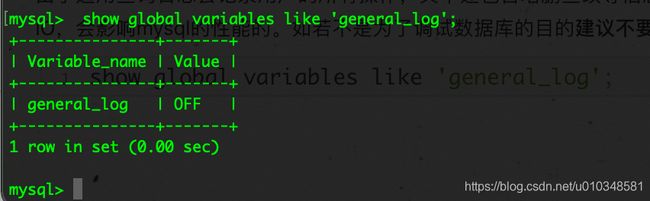
通用查询日志(general query log)
默认情况下通用查询日志是关闭的。
由于通用查询日志会记录用户的所有操作,其中还包含增删查改等信息,在并发操作大的环境下会产生大量的信息从而导致不必要的磁盘IO,会影响mysql的性能的。如若不是为了调试数据库的目的建议不要开启查询日志。
show global variables like 'general_log'; -- 开启方式 #启动开关 general_log={ON|OFF} #日志文件变量,而general_log_file如果没有指定,默认名是host_name.log general_log_file=/PATH/TO/file #记录类型 log_output={TABLE|FILE|NONE}
慢查询日志(slow query log)
默认是关闭的。
#开启慢查询日志 slow_query_log=ON #慢查询的阈值 long_query_time=10 #日志记录文件如果没有给出file_name值, 默认为主机名,后缀为-slow.log。如果给出了文件名, 但不是绝对路径名,文件则写入数据目录。 slow_query_log_file= file_name
记录执行时间超过long_query_time秒的所有查询,便于收集查询时间比较长的SQL语句
重做日志(redo log)
作用
确保事务的持久性。
防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
什么时候产生
事务开始之后就产生redo log,redo log的落盘并不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入redo log文件中。
什么时候释放:
当对应事务的脏页写入到磁盘之后,redo log的使命也就完成了,重做日志占用的空间就可以重用(被覆盖)。
回滚日志(undo log)
作用:
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
什么时候产生:
事务开始之前,将当前是的版本生成undo log,undo 也会产生 redo 来保证undo log的可靠性
什么时候释放:
当事务提交之后,undo log并不能立马被删除,而是放入待清理的链表,由purge线程判断是否由其他事务在使用undo段中表的上一个事务之前的版本信息,决定是否可以清理undo log的日志空间。
中继日志(relay log)
是在主从复制环境中产生的日志。
主要作用是为了从机可以从中继日志中获取到主机同步过来的SQL语句,然后执行到从机中。
InnoDB数据文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息
.ibd:使用独享表空间存储表数据和索引信息,一张表对应一个ibd文件。
ibdata文件:使用共享表空间存储表数据和索引信息,所有表共同使用一个或者多个ibdata文件。
MyIsam数据文件
.frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息
.myd文件:主要用来存储表数据信息。
.myi文件:主要用来存储表数据文件中任何索引的数据树。
- Mysql 逻辑架构图
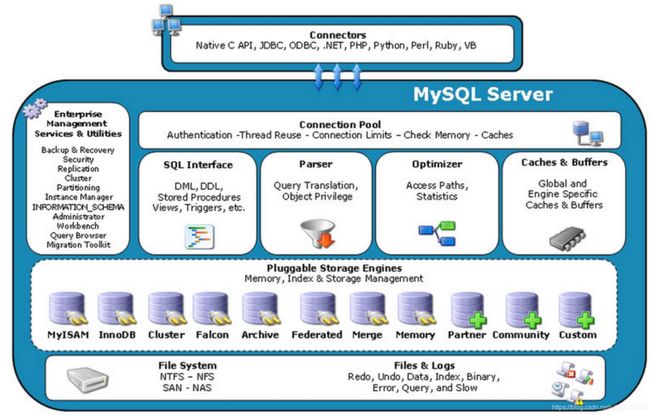
Connectors :连接器,指的是不同语言中与SQL的交互
Management Serveices & Utilities 系统管理和控制工具
Connection Pool: 连接池
管理缓冲用户连接,线程处理等需要缓存的需求。
负责监听对 MySQL Server 的各种请求,接收连接请求,转发所有连接请求到线程管理模块。每一个连接上 MySQL Server 的客户端请求都会被分配(或创建)一个连接线程为其单独服务。而连接线程的主要工作就是负责 MySQL Server 与客户端的通信,接受客户端的命令请求,传递Server 端的结果信息等。线程管理模块则负责管理维护这些连接线程。包括线程的创建,线程的
cache 等。
SQL Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
Parser: 解析器
SQL命令传递到解析器的时候会被解析器验证和解析。
主要功能:
a . 将SQL语句进行语义和语法的分析,分解成数据结构,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。
b. 如果在分解过程中遇到错误,那么就说明这个sql语句是不合理的。
Optimizer: 查询优化器
SQL语句在查询之前会使用查询优化器对查询进行优化。
explain语句查看的SQL语句执行计划,就是由查询优化器生成的。
Cache和Buffffer: 查询缓存
他的主要功能是将客户端提交给MySQL的 select请求的返回结果集 cache 到内存中,与该 query 的一个 hash 值 做一个对应。该 Query 所取数据的基表发生任何数据的变化之后, MySQL 会自动使该query 的Cache 失效。在读写比例非常高的应用系统中, Query Cache 对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
Pluggable Storage Engines:存储引擎
与其他数据库例如Oracle 和SQL Server等数据库中只有一种存储引擎不同的是,MySQL有一个被称为“Pluggable Storage Engine Architecture”(可插拔的存储引擎架构)的特性,也就意味着MySQL数据库提供了多种存储引擎。
而且存储引擎是针对表的,用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。也就是说,同一数据库不同的表可以选择不同的存储引擎
creat table xxx()engine=InnoDB/Memory/MyISAM
简而言之,存储引擎就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
MySQL存储引擎种类

MyISAM:高速引擎,拥有较高的插入,查询速度,但不支持事务
InnoDB :5.5版本后MySQL的默认数据库,支持事务和行级锁定,比MyISAM处理速度稍慢
ISAM :MyISAM的前身,MySQL5.0以后不再默认安装
MRG_MyISAM:(MERGE) 将多个表联合成一个表使用,在超大规模数据存储时很有用
Memory: 内存存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。只在内存上保存数据,意味着数据可能会丢失
Falcon :一种新的存储引擎,支持事物处理,传言可能是InnoDB的替代者
Archive: 将数据压缩后进行存储,非常适合存储大量的独立的,作为历史记 录的数据,但是只能进行插入和查询操作
CSV :CSV 存储引擎是基于 CSV 格式文件存储数据(应用于跨平台的数据交换)
- 简版执行流程图

- 详细执行过程
