内存池-nginx内存池设计解析
什么是内存池?
场景
一般服务器接受到请求后,都会执行相对应的业务逻辑。大多数场景下都会用到malloc进行内存分配。如下图:
但是当服务器的请求量上来以后,频繁的调用malloc,会出现2个问题,第一性能下降,还有就是内存碎片化严重,可能会导致内存吃紧。

这里可能有人说了,malloc而已,有啥好担心的,而且是标准库提供的函数,性能应该不是很差。其实malloc就是一个通用的“大众货”,什么场景下都可以用,但是什么场景下都可以用就意味着什么场景下都不会有很高的性能。
malloc性能不高的原因一在于其没有为特定场景做优化,除此之外还在于malloc看似简单,但是其调用过程是很复杂的,一次malloc的调用过程可以需要经过操作系统的配合才能完成。那么调用malloc时底层都发生了什么呢?简单来说会有这样典型的几个步骤:
- malloc开始搜索空闲内存块,如果能找到一块大小合适的就分配出去
- 如果malloc找不到一块合适的空闲内存,那么调用brk等系统调用扩大堆区从而获得更多的空闲内存
- malloc调用sbrk/brk/mmap后开始转入内核态,此时操作系统中的虚拟内存系统开始工作,扩大进程的堆区,注意额外扩大的这一部分内存仅仅是虚拟内存,操作系统并没有为此分配真正的物理内存
- brk执行结束后返回到malloc,从内核态切换到用户态,malloc找到一块合适的空闲内存后返回
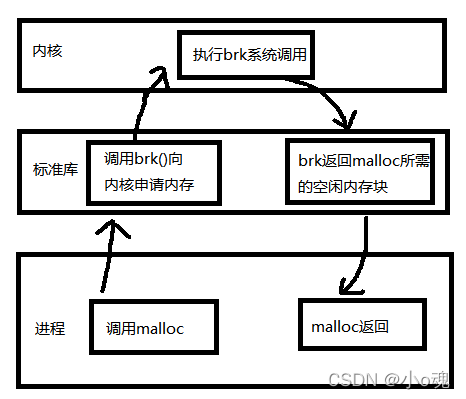
从上面可以看到,malloc的调用还是比较复杂的,如果大量的数据请求进来,导致频繁的调用malloc,必然会影响到性能。
Malloc实现
malloc 的实现主要有三大实现。
- ptmalloc:glibc 的实现。
- tcmalloc:Google 的实现。
- jemalloc:Facebook 的实现。
下面是来自网上的三种 malloc 的比较图,tcmalloc 和 jemalloc 性能差不多,ptmalloc 的性能不如两者,我们可以根据需要选用更适合的 malloc,如 redis 和 mysl 都可以指定使用哪个malloc。至于三者的实现和差异,可以网上查阅。

- 作为基础库的ptmalloc是最为稳定的内存管理器,无论在什么环境下都能适应,但是分配效率相对较低。
- tcmalloc针对多核情况有所优化,性能有所提高,但是内存占用稍高,大内存分配容易出现CPU飙升。
- jemalloc的内存占用更高,但是在多核多线程下的表现也最为优异。
在什么情况下我们应该考虑好内存分配如何管理:
- 多核多线程的情况下,内存管理需要考虑:内存分配加锁、异步内存释放、多线程之间的内存共享、线程的生命周期;
- 内存当作磁盘使用的情况下,需要考虑内存分配和释放的效率,是使用内存管理库还是应该自己进行大对象大内存的管理(在搜索以及推荐系统中尤为突出)。
解决:
引入内存池。虽然标准库的实现在操作系统内存管理的基础上再加了一层内存管理,但应用程序通常也会实现自己特定的内存池,如为了引用计数或者专门用于小对象分配。
所谓的内存池就是在给定的内存buffer上建立内存管理机制,根据用户需求从该buffer上分配内存或者将已经分配的内存释放回buffer中。尽量减少内存碎片,平均效率高于C语言的malloc和free。它是一个组件,做出来以后,有一套api,供开发者使用。
这里需要补充一点,上面也说了,malloc是定位通用性的,通用性的内存分配器设计实现往往比较复杂,但是内存池技术就不一样了,内存池技术专用于某个特定场景,以此优化程序性能,但内存池技术的通用性一般是比较差的,在一种场景下有很高性能的内存池基本上没有办法在其它场景也能获得高性能甚至根本就不能用于其它场景,这就是内存池这种技术的定位。需要针对不同的场景,制定不同的内存池策略。

设计思路
一个组件一般由以下几个要点组成:
- 宏定义
- 相关结构体
- 对应的函数,api,供别人使用
- 测试代码、案例代码
然后我们该如何分配管理这个内存呢?一般分2部分:
- 小块内存 < 4k
- 大块内存 > 4k
结构定义
这里有同学可能会问了,这个大小块是如何区分的呢?因为内存一个页的大小是4k。
根据这个思路,我们可以按4k为1小块,进行提前分配,用链表组织在一起。大块内存按需分配。
这样我们就可以设计出小块的结构体结构
// 小块内存 大小=4k
struct mp_node_s {
unsigned char *last; // 指向当前可用内存的位置
unsigned char *end; // 小块内存的结束位置
struct mp_node_s *next; // 指向下一个小块内存
size_t failed; //
};
小块内存我们已经有了思路,那么我们思考一下什么时候会需要用到大块内存?当服务器需要接收\发送 文件、视频、资源的时候,会需要先将资源加载到内存然后发出,这时我们就需要用到大块内存了。
大块(>4k的内存)该如何组织呢?

大块的内存我们也是用链表串起来。同时,我们不进行提前预分配,并且用完大块内存,回收的时候不进行释放,用完还在链表中,以供以后使用。当需要大块的内存时,先在大块链表中寻找空闲内存,如果没有,就进行临时分配。
// 大块内存 大小>4k
struct mp_large_s {
struct mp_large_s *next; // 指向下一个大块内存
void *alloc; // 分配内存的指针
};现在大小块内存结构体算是定义完了,我们还需要一个管理器(调度器),来统一管理大小块内存。
// 内存池管理器
struct mp_pool_s {
size_t max; // 大小块区分阈值,这里是4k大小
struct mp_node_s *current; // 当前可用小块内存
struct mp_large_s *large; // 大块内存链表头
struct mp_node_s head[0]; // 柔性数组,在这里相当于是当前小块内存的标签,=小块内存节点的头节点
};Api设计
// 创建内存池
struct mp_pool_s *mp_create_pool(size_t size);
// 销毁内存池
void mp_destory_pool(struct mp_pool_s *pool);
// 分配内存,内存对齐
void *mp_alloc(struct mp_pool_s *pool, size_t size);
// 分配内存,内存不对齐
void *mp_nalloc(struct mp_pool_s *pool, size_t size);
// 分配并初始化内存为0
void *mp_calloc(struct mp_pool_s *pool, size_t size);
// 释放内存
void mp_free(struct mp_pool_s *pool, void *p);
整体流程
代码详讲
生成内存池-mp_create_pool
struct mp_pool_s *mp_create_pool(size_t size) {
struct mp_pool_s *p;
// 这里不使用malloc分配内存,是因为malloc适用于分配小内存,分配大内存容易出错
// posix_memalign这个函数是linux系统提供,linux在内核对也有2种内存分配管理机制,对应着malloc和posix_memalign
// 另外,管理器和第一个小内存块保存在一起,这么做是为了尽量保证不要出现内存碎片化的情况出现,因为内存池就是为了不要出现内存碎片
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s));
if (ret) {
return NULL;
}
// 小块最大只能是4k大小(一页)
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;
p->large = NULL;
p->head->last = (unsigned char *)p + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
return p;
}分配完内存结构如下:
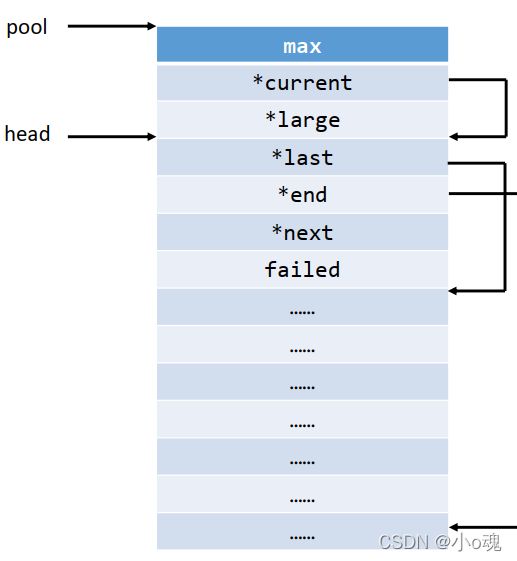
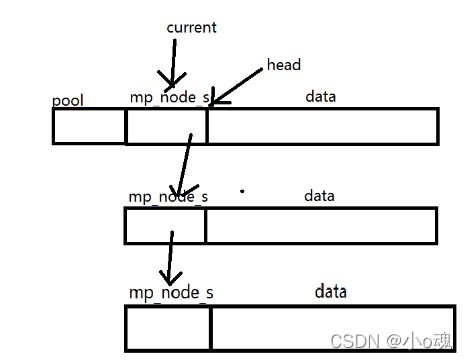
这里有个难点,我个人是觉得比较难理解的,就是这个"p->head",这里nginx用到了柔性数组来表达小块内存的头节点,个人感觉这里其实可以换成指针,更容易理解。如果有不理解的同学,可以看一下上图的内存结构,感觉这里用柔性数组,就是为了少4个字节而已(指向小块内存头节点的指针)
销毁内存池-mp_destory_pool
void mp_destory_pool(struct mp_pool_s *pool) {
struct mp_node_s *h, *n;
struct mp_large_s *l;
// 先释放大块
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
}
}
// 释放小块
h = pool->head->next;
while (h) {
n = h->next;
free(h);
h = n;
}
free(pool);
}分配内存(内存对齐)-mp_alloc
void *mp_alloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
// 判断大小块
if (size <= pool->max) {
// p = 当前小块
p = pool->current;
// 遍历小块内存链表
do {
// 内存对齐
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
} while (p);
// 如果没有小块内存可分配,就再生成一个小块内存,从其中分配内存
return mp_alloc_block(pool, size);
}
// 如果属于大块内存,则分配大块内存
return mp_alloc_large(pool, size);
}这里的逻辑可以梳理一下:
- 判断当前欲分配的内存是在小块内存还是在大块内存
- 如果是小块内存,
- 遍历小块内存链表,找到合适的分配位置
- 找到合适的小块内存,获取它的结尾指针,分配内存
- 如果是大块内存,先找一下是否存在空闲大块内存,有则复用,没有则创建
申请小块内存-mp_alloc_block
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *h = pool->head; // 获取小块内存头节点
size_t psize = (size_t)(h->end - (unsigned char *)h); // 获取小块内存的大小
int ret = posix_memalign((void **)&m, MP_ALIGNMENT, psize); // 分配内存
if (ret) return NULL;
struct mp_node_s *p, *new_node, *current;
new_node = (struct mp_node_s*)m; // 新分配的小块内存指针
new_node->end = m + psize; // 设置小块内存的结束地址
new_node->next = NULL;
new_node->failed = 0;
m += sizeof(struct mp_node_s); // 小块内存start指针
m = mp_align_ptr(m, MP_ALIGNMENT); // 分配内存,内存对齐
new_node->last = m + size; // 设置结尾位置,这里设置的结尾表达的的意思是,从新的小块内存中分配了内存
current = pool->current; // 获取当前小块内存
for (p = current; p->next; p = p->next) { // 寻找小块内存最后一个节点
if (p->failed++ > 4) { // 优化搜寻小块内存的速度,如果一个节点被4次跳过,说明这个节点可用内存很小了,通过设置新的current节点,优化搜索可用小块内存的时间
current = p->next;
}
}
p->next = new_node; // 将新的小块内存加入到链表结尾
pool->current = current ? current : new_node;
return m;
}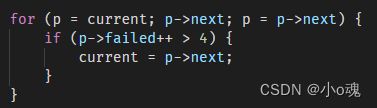
有小伙伴很疑惑,这里的代码时什么?为什么p->failed++ > 4就要设置新的小块内存头,这里我也是思考许久,我认为nginx是为了优化搜寻小块内存的速度,如果申请内存时,一个小块内存节点被4次跳过,说明这个节点可用内存很小了,已经没有被搜索的必要了,通过设置新的current节点,优化搜索可用小块内存的时间。在后面释放内存的代码种,也可以知道,小块内存是无法被释放的,只能在销毁内存池时释放,具体为什么要这么做,最后再做一个分析。
申请大块内存-mp_alloc_large
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void *p;
int ret = posix_memalign(&p, alignment, size); // 生成大块内存
if (ret == NULL) return NULL;
size_t n = 0;
struct mp_large_s *large;
for (large = pool->large; large; large = large->next) {
if (large->alloc == NULL) {
large->alloc = p;
return p;
}
if (n ++ > 3) break;
}
large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
return NULL;
}
large->alloc = p; // 头插法,新的大块内存被放在节点头
large->next = pool->large;
pool->large = large;
return p;
}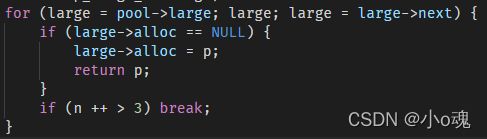
这里的代码页很有意思,这里只搜索前4个大块内存节点是否可以被重新复用,思考了很久。感觉这里应该是因为nginx的特殊场景特殊适配,一切为了性能。因为,大块内存插入链表采用的时头插法,这么的话,前4个节点,可以理解为最近分配的4个节点。在nginx的场景中,大块内存一般用于资源读取与发送,所以一般都是快进快出,类似栈一样,所以前4个节点的最有可能被优先释放。所以只搜索前4个节点。
释放节点-mp_free
void mp_free(struct mp_pool_s *pool, void *p) {
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (p == l->alloc) {
free(l->alloc);
l->alloc = NULL;
return ;
}
}
}这里可以看出,释放内存的话,只会释放大块内存,小块内存只能在销毁内存池的的时候释放。这里有小伙伴可能会问了,为什么只销毁大块内存,而不销毁小块内存。这里个人感觉,nginx还是为了性能和实现简单考虑。在nginx的场景中,小块内存的生存周期,从一个请求进来到服务端发送回复报文截止。在请求结束后会调用销毁/重置内存池。如果要释放在小块内存中申请的内存,实现过于复杂,且没有这个必要,因为一个请求的生命周期一般很短而且申请小块内存会频繁被使用。所以没必要去释放小块内存,nginx这种特殊场景就要特殊适配,也符合我们前面说的,引入内存池就是为了特殊场景特殊处理,达到性能最优化。
整体代码
#include
#include
#include
#include
#include
#define MP_ALIGNMENT 32
#define MP_PAGE_SIZE 4096
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1)
#define mp_align(n, alignment) (((n)+(alignment-1)) & ~(alignment-1))
#define mp_align_ptr(p, alignment) (void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))
// 大块内存 大小>4k
struct mp_large_s {
struct mp_large_s *next; // 指向下一个大块内存
void *alloc; // 分配内存的指针
};
// 小块内存 大小=4k
struct mp_node_s {
unsigned char *last; // 指向当前可用内存的位置
unsigned char *end; // 小块内存的结束位置
struct mp_node_s *next; // 指向下一个小块内存
size_t failed; //
};
// 内存池管理器
struct mp_pool_s {
size_t max; // 大小块区分阈值,这里是4k大小
struct mp_node_s *current; // 当前可用小块内存
struct mp_large_s *large; // 大块内存链表头
struct mp_node_s head[0]; // 柔性数组,在这里相当于是当前小块内存的标签
};
// 创建内存池
struct mp_pool_s *mp_create_pool(size_t size);
// 销毁内存池
void mp_destory_pool(struct mp_pool_s *pool);
// 分配内存,内存对齐
void *mp_alloc(struct mp_pool_s *pool, size_t size);
// 分配内存,内存不对齐
void *mp_nalloc(struct mp_pool_s *pool, size_t size);
// 分配并初始化内存为0
void *mp_calloc(struct mp_pool_s *pool, size_t size);
// 释放内存
void mp_free(struct mp_pool_s *pool, void *p);
struct mp_pool_s *mp_create_pool(size_t size) {
struct mp_pool_s *p;
// 这里不使用malloc分配内存,是因为malloc适用于分配小内存,分配大内存容易出错
// posix_memalign这个函数是linux系统提供,linux在内核对也有2种内存分配管理机制,对应着malloc和posix_memalign
// 另外,管理器和第一个小内存块保存在一起,这么做是为了尽量保证不要出现内存碎片化的情况出现,因为内存池就是为了不要出现内存碎片
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s));
if (ret) {
return NULL;
}
// 小块最大只能是4k大小(一页)
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;
p->large = NULL;
p->head->last = (unsigned char *)p + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
return p;
}
void mp_destory_pool(struct mp_pool_s *pool) {
struct mp_node_s *h, *n;
struct mp_large_s *l;
// 先释放大块
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
}
}
// 释放小块
h = pool->head->next;
while (h) {
n = h->next;
free(h);
h = n;
}
free(pool);
}
void mp_reset_pool(struct mp_pool_s *pool) {
struct mp_node_s *h;
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
}
}
pool->large = NULL;
for (h = pool->head; h; h = h->next) {
h->last = (unsigned char *)h + sizeof(struct mp_node_s);
}
}
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *h = pool->head; // 获取小块内存头节点
size_t psize = (size_t)(h->end - (unsigned char *)h); // 获取小块内存的大小
int ret = posix_memalign((void **)&m, MP_ALIGNMENT, psize); // 分配内存
if (ret) return NULL;
struct mp_node_s *p, *new_node, *current;
new_node = (struct mp_node_s*)m; // 新分配的小块内存指针
new_node->end = m + psize; // 设置小块内存的结束地址
new_node->next = NULL;
new_node->failed = 0;
m += sizeof(struct mp_node_s); // 小块内存start指针
m = mp_align_ptr(m, MP_ALIGNMENT); // 分配内存,内存对齐
new_node->last = m + size; // 设置结尾位置,这里设置的结尾表达的的意思是,从新的小块内存中分配了内存
current = pool->current; // 获取当前小块内存
for (p = current; p->next; p = p->next) { // 寻找小块内存最后一个节点
if (p->failed++ > 4) { // 优化搜寻小块内存的速度,如果一个节点被4次跳过,说明这个节点可用内存很小了,通过设置新的current节点,优化搜索可用小块内存的时间
current = p->next;
}
}
p->next = new_node; // 将新的小块内存加入到链表结尾
pool->current = current ? current : new_node;
return m;
}
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void *p;
int ret = posix_memalign(&p, alignment, size); // 生成大块内存
if (ret == NULL) return NULL;
size_t n = 0;
struct mp_large_s *large;
for (large = pool->large; large; large = large->next) {
if (large->alloc == NULL) {
large->alloc = p;
return p;
}
if (n ++ > 3) break;
}
large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
return NULL;
}
large->alloc = p; // 头插法
large->next = pool->large;
pool->large = large;
return p;
}
void *mp_memalign(struct mp_pool_s *pool, size_t size, size_t alignment) {
void *p;
int ret = posix_memalign(&p, alignment, size);
if (ret) {
return NULL;
}
struct mp_large_s *large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
return NULL;
}
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
void *mp_alloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
// 判断大小块
if (size <= pool->max) {
// p = 当前小块
p = pool->current;
// 遍历小块内存链表
do {
// 内存对齐
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
} while (p);
// 如果没有小块内存可分配,就再生成一个小块内存,从其中分配内存
return mp_alloc_block(pool, size);
}
// 如果属于大块内存,则分配大块内存
return mp_alloc_large(pool, size);
}
void *mp_nalloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = p->last;
if ((size_t)(p->end - m) >= size) {
p->last = m+size;
return m;
}
p = p->next;
} while (p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}
void *mp_calloc(struct mp_pool_s *pool, size_t size) {
void *p = mp_alloc(pool, size);
if (p) {
memset(p, 0, size);
}
return p;
}
void mp_free(struct mp_pool_s *pool, void *p) {
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (p == l->alloc) {
free(l->alloc);
l->alloc = NULL;
return ;
}
}
}
int main(int argc, char *argv[]) {
int size = 1 << 12;
struct mp_pool_s *p = mp_create_pool(size);
int i = 0;
for (i = 0;i < 10;i ++) {
void *mp = mp_alloc(p, 512);
// mp_free(mp);
}
//printf("mp_create_pool: %ld\n", p->max);
printf("mp_align(123, 32): %d, mp_align(17, 32): %d\n", mp_align(24, 32), mp_align(17, 32));
//printf("mp_align_ptr(p->current, 32): %lx, p->current: %lx, mp_align(p->large, 32): %lx, p->large: %lx\n", mp_align_ptr(p->current, 32), p->current, mp_align_ptr(p->large, 32), p->large);
int j = 0;
for (i = 0;i < 5;i ++) {
char *pp = mp_calloc(p, 32);
for (j = 0;j < 32;j ++) {
if (pp[j]) {
printf("calloc wrong\n");
}
printf("calloc success\n");
}
}
//printf("mp_reset_pool\n");
for (i = 0;i < 5;i ++) {
void *l = mp_alloc(p, 8192);
mp_free(p, l);
}
mp_reset_pool(p);
//printf("mp_destory_pool\n");
for (i = 0;i < 58;i ++) {
mp_alloc(p, 256);
}
mp_destory_pool(p);
return 0;
}
总结
总体来说,nginx的内存池,只适用nginx的请求场景。根据请求的特性,开发了简单的内存池组件从而提升性能。 这里肯定有很多小伙伴会疑惑,引入内存池真正目的是什么,看了代码感觉也没有那么神奇。说白了,内存池就是要根据特殊场景,特殊适配,减少内存碎片,减少malloc次数,从而整体提升性能。
这里再推荐2个内存池,比较通用的。一个是JeMalloc,另一个是Tcmalloc,有兴趣的小伙伴可以看看。