BF算法
假设我们要从下面的主串S="goodgoogle"中,找到T="google"这个子串的位置。我们通常需要下面的步骤。
-
主串S第一位开始,S与T前三个字母都匹配成功,但S第四个字母是d而T的是g。第一位匹配失败。如图所示,其中竖直连线表示相等,闪电状弯折连线表示不等。
假设我们要从下面的主串S="goodgoogle"中,找到T="google"这个子串的位置。我们通常需要下面的步骤。
主串S第一位开始,S与T前三个字母都匹配成功,但S第四个字母是d而T的是g。第一位匹配失败。如图所示,其中竖直连线表示相等,闪电状弯折连线表示不等。


主串S第三位开始,主串S首字母是o,要匹配的T首字母是g,匹配失败,如图所示。

主串S第四位开始,主串S首字母是d,要匹配的T首字母是g,匹配失败,如图所示。

主串S第五位开始,S与T,6个字母全匹配,匹配成功,如图所示。

简单的说,就是对主串的每一个字符作为子串开头,与要匹配的字符串进行匹配。对主串做大循环,每个字符开头做T的长度的小循环,直到匹配成功或全部遍历完成为止。
那就是一开始就区配成功,比如“googlegood”中去找“google”,时间复杂度为O(1)。稍差一些,如果像刚才例子中第二、三、四位一样,每次都是首字母就不匹配,那么对T串的循环就不必进行了,比如“abcdef-google”中去找“google”。那么时间复杂度为O(n+m),其中n为主串长度,m为要匹配的子串长度。根据等概率原则,平均是(n+m)/2次查找,时间复杂度为O(n+m)。
就是每次不成功的匹配都发生在串T的最后一个字符。举一个很极端的例子。主串为S="00000000000000000000000000000000000000000000000001",而要匹配的子串为T="0000000001",前者是有49个“0”和1个“1”的主串,后者是9个“0”和1个“1”的子串。在匹配时,每次都得将T中字符循环到最后一位才发现:哦,原来它们是不匹配的。这样等于T串需要在S串的前40个位置都需要判断10次,并得出不匹配的结论,如图所示。

直到最后第41个位置,因为全部匹配相等,所以不需要再继续进行下去,如图5-6-7所示。如果最终没有可匹配的子串,比如是T="0000000002",到了第41位置判断不匹配后同样不需要继续比对下去。因此最坏情况的时间复杂度为O((n-m+1)*m)。

#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 40 /* 存储空间初始分配量 */
typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 */
typedef int ElemType; /* ElemType类型根据实际情况而定,这里假设为int */
typedef char String[MAXSIZE+1]; /* 0号单元存放串的长度 */
生成一个其值等于chars的串T
// 生成一个其值等于chars的串T
Status StrAssign(String T,char *chars)
{
int i;
if(strlen(chars) > MAXSIZE)
return ERROR;
else
{
T[0] = strlen(chars);
for(i = 1;i <= T[0];i++)
T[i] =* (chars + i - 1);
return OK;
}
}
清空一个串
Status ClearString(String S)
{
S[0] = 0;/* 令串长为零 */
return OK;
}
BF算法思路
思路:
分别利用计数指针i和j指示主串S和模式T中当前正待比较的字符位置,i初值为pos,j的初值为1;
如果2个串均为比较到串尾,即i和j均小于等于S和T的长度时, 则循环执行以下的操作:
如果j > T.length, 说明模式T中的每个字符串依次和主串S找中的一个连续字符序列相等,则匹配成功,返回和模式T中第一个字符的字符在主串S中的序号(i-T.length);否则匹配失败,返回0;
代码实现
int Index_BF(String S, String T,int pos){
//i用于主串S中当前位置下标值,若pos不为1,则从pos位置开始匹配
int i = pos;
//j用于子串T中当前位置下标值
int j = 1;
//若i小于S的长度并且j小于T的长度时,循环继续
while (i <= S[0] && j <= T[0]) {
//比较的2个字母相等,则继续比较
if (S[i] == T[j]) {
i++;
j++;
} else
{
//不相等,则指针后退重新匹配
//i 退回到上次匹配的首位的下一位;
//加1,因为是子串的首位是1开始计算;
//再加1的元素,从上次匹配的首位的下一位;
i = i-j+2;
//j 退回到子串T的首位
j = 1;
}
}
//如果j>T[0],则找到了匹配模式
if (j > T[0]) {
//i母串遍历的位置 - 模式字符串长度 = index 位置
return i - T[0];
}else{
return -1;
}
}
RK算法算是BF算法的变种,前人已经为我们想到了新的办法,那可不可以把我们的子串转换成哈希值来比较呢?
将不同的字符组合能够通过某种公式的计算映射成不同的数字!
例如:比较 “abc” 与 “cde” ; 比较 123 与 456; 是一样的吗?
RK算法的核心思想就是设计一个尽可能完善的哈希算法,将我们的子串转换成哈希值来进行比较。
为了让大家知道接下来推演过程, 以数字为例,会更容易让大家理 解, 它的全集是 {0,1,2,3,4,5,6,7,8,9}. d = 10; 模式串p = 123, 主串s = 65127451234

将’当前字母’ - ‘a’ = 数字
例如
a - a = 0;
b - a = 1;
c - a = 2;
d - a = 3;
e - a = 4;
...
小写字母之间存在的进制
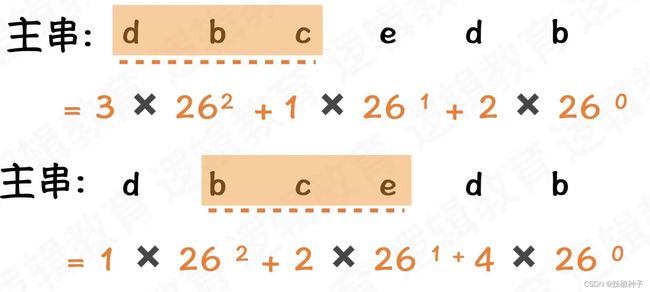
“ cba ” = ‘c’ * 26 26 + ‘b’ * 26 + ‘a’ * 1 = 2 * 26 * 26 + 1 26 + 0 * 1
= 1378
“ cba ” = c ✖ 262 + b ✖ 261 + a ✖260 = 2 ✖ 262 + 1 ✖ 261 + 0 ✖260
= 1352 + 26 + 0 = 1378
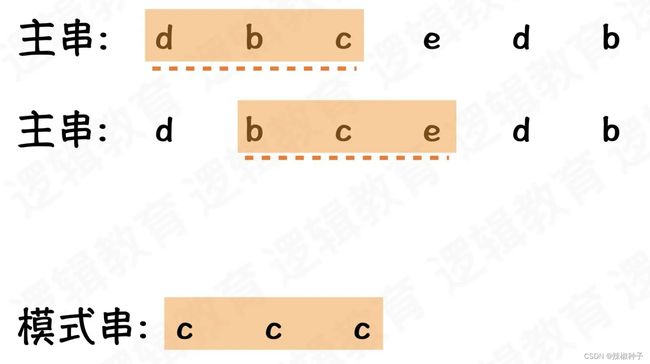
相邻的2个子串 s[i] 与 s[i+1] (i表示子串从主串中的起始位置,子串的长度 都为m). 对应的哈希值计算公式有交集. 也就说我们可以使用s[i-1]计算出s[i] 的哈希值;
以数字为例, 它的全集是 {0,1,2,3,4,5,6,7,8,9}. d = 10; 模式串p = 123, 主串s = 65127451234


s[i+1] 实现上是上一个s[i]去掉最高位数据,其余的m-1为字符乘以 d进制. 再加上最后一个为字符得到;

//d 表示进制
#define d 26
比较两个哈希值是否相等
//为了杜绝哈希冲突. 当前发现模式串和子串的HashValue 是一样的时候.还是需要二次确认2个字符串是否相等.
int isMatch(char *S, int i, char *P, int m)
{
int is, ip;
for(is=i, ip=0; is != m && ip != m; is++, ip++)
if(S[is] != P[ip])
return 0;
return 1;
}
算出d进制下的最高位
//算出最d进制下的最高位
//d^(m-1)位的值;
int getMaxValue(int m){
int h = 1;
for(int i = 0;i < m - 1;i++){
h = (h*d);
}
return h;
}
RK算法代码实现
/*
* 字符串匹配的RK算法
* Author:Rabin & Karp
* 若成功匹配返回主串中的偏移,否则返回-1
*/
int RK(char *S, char *P)
{
//1. n:主串长度, m:子串长度
int m = (int) strlen(P);
int n = (int) strlen(S);
printf("主串长度为:%d,子串长度为:%d\n",n,m);
//A.模式串的哈希值; St.主串分解子串的哈希值;
unsigned int A = 0;
unsigned int St = 0;
//2.求得子串与主串中0~m字符串的哈希值[计算子串与主串0-m的哈希值]
//循环[0,m)获取模式串A的HashValue以及主串第一个[0,m)的HashValue
//此时主串:"abcaadddabceeffccdd" 它的[0,2)是ab
//此时模式串:"cc"
//cc = 2 * 26^1 + 2 *26 ^0 = 52+2 = 54;
//ab = 0 * 26^1 + 1 *26^0 = 0+1 = 1;
for(int i = 0; i != m; i++){
//第一次 A = 0*26+2;
//第二次 A = 2*26+2;
A = (d*A + (P[i] - 'a'));
//第一次 st = 0*26+0
//第二次 st = 0*26+1
St = (d*St + (S[i] - 'a'));
}
//3. 获取d^m-1值(因为经常要用d^m-1进制值)
int hValue = getMaxValue(m);
//4.遍历[0,n-m], 判断模式串HashValue A是否和其他子串的HashValue 一致.
//不一致则继续求得下一个HashValue
//如果一致则进行二次确认判断,2个字符串是否真正相等.反正哈希值冲突导致错误
//注意细节:
//① 在进入循环时,就已经得到子串的哈希值以及主串的[0,m)的哈希值,可以直接进行第一轮比较;
//② 哈希值相等后,再次用字符串进行比较.防止哈希值冲突;
//③ 如果不相等,利用在循环之前已经计算好的st[0] 来计算后面的st[1];
//④ 在对比过程,并不是一次性把所有的主串子串都求解好Hash值. 而是是借助s[i]来求解s[i+1] . 简单说就是一边比较哈希值,一边计算哈希值;
for(int i = 0; i <= n-m; i++){
if(A == St)
if(isMatch(S,i,P,m))
//加1原因,从1开始数
return i+1;
St = ((St - hValue*(S[i]-'a'))*d + (S[i+m]-'a'));
}
return -1;
}
RK算法主要的解决思路就是在BF算法的基础上,将子串转换成哈希值来进行比较,它算是BF算法的升级版。