ShardingSphere-JDBC 的4种分片策略
目录
- 一、标准分片策略
-
- 1)使用场景
- 2)配置
- 3)精确查询分库分表策略
- 4)范围查询分库分表策略
- 二、复合分片策略
-
- 1)使用场景
- 2)配置
- 3)代码实践
- 4)需注意的点
- 三、行表达式分片策略
-
- 1)使用场景
- 2)代码实践
- 四、Hint分片策略
-
- 1)使用场景
- 2)配置
- 3)未解决问题
不到万不得已也不会采取分库分表策略,这无疑增添了复杂度,但是当单表数据超过500万,分库分表无疑也是最好的选择。至于如何查询?这就涉及到了分片策略,四种分片策略满足了平时日常的查询处理需求。
- standard (标准分片策略)
- complex (复合分片策略)
- inline (行表达式分片策略)
- hint (Hint分片策略)
一、标准分片策略
1)使用场景
SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 操作符,都可以应用此分片策略。
2)配置
StandardShardingStrategy它只支持对单个分片健(字段)为依据的分库分表,并提供了两种分片算法 PreciseShardingAlgorithm(精准分片)和 RangeShardingAlgorithm(范围分片)。
首先我们也是配置application.properties
###配置分表策略
spring.shardingsphere.sharding.tables.course.table-strategy.standard.sharding-column=id
#范围查询策略
spring.shardingsphere.sharding.tables.course.table-strategy.standard.range-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyRangeTableShardingAlgorithm
#精确查询策略
spring.shardingsphere.sharding.tables.course.table-strategy.standard.precise-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyPreciseTableShardingAlgorithm
###配置分库策略
spring.shardingsphere.sharding.tables.course.database-strategy.standard.sharding-column=id
#范围查询策略
spring.shardingsphere.sharding.tables.course.database-strategy.standard.range-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyRangeDBShardingAlgorithm
#精确查询策略
spring.shardingsphere.sharding.tables.course.database-strategy.standard.precise-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyPreciseDBShardingAlgorithm
3)精确查询分库分表策略
#分表-精确查询策略
spring.shardingsphere.sharding.tables.course.table-strategy.standard.precise-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyPreciseTableShardingAlgorithm
#分库-精确查询策略
spring.shardingsphere.sharding.tables.course.database-strategy.standard.precise-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyPreciseDBShardingAlgorithm
实现精准分库分表都是implements PreciseShardingAlgorithm并重写doSharding方法,自行配置分库分表算法。
/**
* @description:自定义标准分表策略
* @author: huoyajing
* @time: 2021/12/17 4:40 下午
*/
public class MyPreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* 实现SQL如此:select * from course where id=? or id in(?,?)
*
* @param collection 所有分片库的集合
* @param preciseShardingValue 分片属性
* private final String logicTableName; 逻辑表
* private final String columnName; 分片键(字段)
* private final T value; 从 SQL 中解析出的分片健的值
* @return
*/
@Override
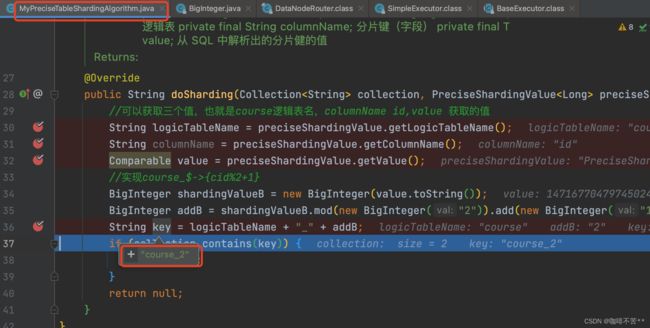
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//可以获取三个值,也就是course逻辑表名,columnName id,value 获取的值
String logicTableName = preciseShardingValue.getLogicTableName();
String columnName = preciseShardingValue.getColumnName();
Comparable value = preciseShardingValue.getValue();
//实现course_$->{cid%2+1}
BigInteger shardingValueB = (BigInteger) value;
BigInteger addB = shardingValueB.mod(new BigInteger("2")).add(new BigInteger("1"));
String key = logicTableName + "_" + addB;
if (collection.contains(key)) {
return key;
}
return null;
}
}
如上是我实现的分表算法,采用的依旧是除余的方式来分发数据。对于分库逻辑也可以根据开发者想要的逻辑实现,本篇则不做详细说明。
配置完成之后我们就可以操作准确查询功能了。比如:
select * from course where id=?
我们测试方法如下:
@Test
public void queryCourseById() {
QueryWrapper<Course> wrapper=new QueryWrapper<>();
wrapper.eq("id",1471677047974502401L);
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
断点调试我们可以定位到m2库的course_2表中

4)范围查询分库分表策略
#分表-范围查询策略
spring.shardingsphere.sharding.tables.course.table-strategy.standard.range-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyRangeTableShardingAlgorithm
#分库-范围查询策略
spring.shardingsphere.sharding.tables.course.database-strategy.standard.range-algorithm-class-name=com.huohuo.sharding.service.algorithm.MyRangeDBShardingAlgorithm
实现范围分库分表都是implements RangeShardingAlgorithm并重写doSharding方法,自行配置分库分表算法。
/**
* @description:自定义范围分表策略
* @author: huoyajing
* @time: 2021/12/17 4:40 下午
*/
public class MyRangeTableShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* 实现SQL如此:select * from course where id between 1 and 100
* @param collection 所有分片库的集合
* @param rangeShardingValue
* private final String logicTableName;
* private final String columnName;
* private final Range valueRange; lower和upper between and 的起始值
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
String logicTableName = rangeShardingValue.getLogicTableName();
//返回一个目的地,最终回到所有表身上
return Arrays.asList(logicTableName+"_1",logicTableName+"_2");
}
}
/**
* @description:自定义范围分库策略
* @author: huoyajing
* @time: 2021/12/17 4:40 下午
*/
public class MyRangeDBShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
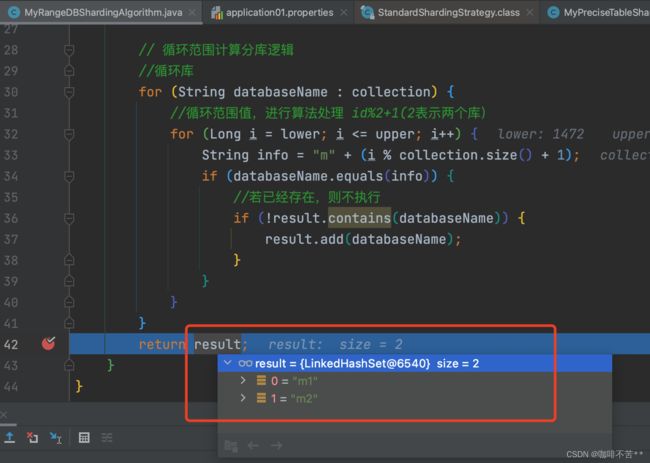
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
Set<String> result = new LinkedHashSet<>();
// 可以获取between and 的起始值
Long lower = rangeShardingValue.getValueRange().lowerEndpoint();
Long upper = rangeShardingValue.getValueRange().upperEndpoint();
String logicTableName = rangeShardingValue.getLogicTableName();
// 循环范围计算分库逻辑
//循环库
for (String databaseName : collection) {
//循环范围值,进行算法处理 id%2+1(2表示两个库)
for (Long i = lower; i <= upper; i++) {
String info = "m" + (i % collection.size() + 1);
if (databaseName.equals(info)) {
//若已经存在,则不执行
if (!result.contains(databaseName)) {
result.add(databaseName);
}
}
}
}
return result;
}
}
分库算法也是根据之前我配置的算法id%+1的方式来匹配库。分表也是如此,犹豫测试数据简单,所以用默认值处理了。
配置完成之后我们就可以操作了,比如between:
select * from course where id BETWEEN ? AND ?
我的测试库数据在m1 的course_1和m2的course_2中,1472-1478的数据分别都涉及到了。
select * from course where id BETWEEN 1472 and 1478 结果一共7条满足需求,涉及到了m1,m2库
```java
@Test
public void queryCourseRange(){
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.between("id",1472L,1478L);
List<Course> courses = courseMapper.selectList(wrapper);
courses.forEach(course -> System.out.println(course));
}
使用场景
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符,不同的是复合分片策略支持对多个分片健操作。
标准分片策略,我们只是根据一个字段来查询,也就是一个分片键。下边我们同时实现以id和type为条件来实现查询
2)配置
我们修改一下原配置,standard.sharding-column 切换成 complex.sharding-columns 复数,分片健上再加一个 user_id ,分片策略名变更为 complex ,complex.algorithm-class-name 替换成我们自定义的复合分片算法。
###配置分表策略
spring.shardingsphere.sharding.tables.course.table-strategy.complex.sharding-columns=sharding-column=id,type
#复合查询策略
spring.shardingsphere.sharding.tables.course.table-strategy.complex.algorithm-class-name=com.huohuo.sharding.service.algorithm.MyComplexTableShardingAlgorithm
###配置分库策略
spring.shardingsphere.sharding.tables.course.database-strategy.complex.sharding-columns=id,type
#范围查询策略
spring.shardingsphere.sharding.tables.course.database-strategy.complex.algorithm-class-name=com.huohuo.sharding.service.algorithm.MyComplexDBShardingAlgorithm
3)代码实践
/**
* @description:自定义复合分库策略
* @author: huoyajing
* @time: 2021/12/17 4:40 下午
*/
public class MyComplexDBShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
//需求上我们是根据id范围查询,根据type精确查询 所以
// id用getColumnNameAndRangeValuesMap
// type用getColumnNameAndShardingValuesMap ,数据库type值是奇偶分表,实际项目中如何使用后期再说
Range<Long> idRange = complexKeysShardingValue.getColumnNameAndRangeValuesMap().get("id");
//返回collection的原因是可以是等号,当然也可以是in那就是多个值了
Collection<Long> typeCol = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("type");
//可以拿到id的上限和下限
Long lowerVal = idRange.lowerEndpoint();
Long upperVal = idRange.upperEndpoint();
List<String> res = new ArrayList<>();
for (Long type : typeCol) {
BigInteger bigInteger = BigInteger.valueOf(type);
//查询的type为5,是奇数,在m1库course_1表中
BigInteger target = bigInteger.mod(new BigInteger("2"));
//库是m
res.add("m" + target);
}
return res;
}
}
/**
* @description:自定义复合分表策略
* @author: huoyajing
* @time: 2021/12/17 4:40 下午
*/
public class MyComplexTableShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
//需求上我们是根据id范围查询,根据type精确查询 所以
// id用getColumnNameAndRangeValuesMap
// type用getColumnNameAndShardingValuesMap ,数据库type值是奇偶分表,实际项目中如何使用后期再说
Range<Long> idRange = complexKeysShardingValue.getColumnNameAndRangeValuesMap().get("id");
Collection<Long> typeCol = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("type");
List<String> res = new ArrayList<>();
for (Long type : typeCol) {
BigInteger bigInteger = BigInteger.valueOf(type);
BigInteger target = bigInteger.mod(new BigInteger("2"));
res.add(complexKeysShardingValue.getLogicTableName() + "_" + target);
}
return res;
}
}
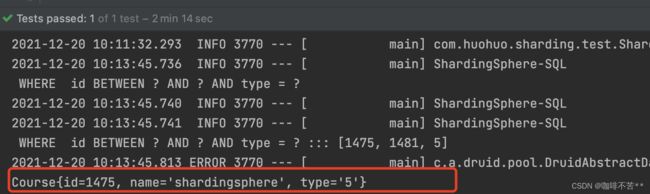
通过断点可得如上获取信息为m1,course_1,结果则是一条记录
4)需注意的点
我们本次测试使用了两个字段,id和type;需要注意的就是复合使用分片键的时候,两个类型必须保持一致。
三、行表达式分片策略
1)使用场景
行表达式分片策略(InlineShardingStrategy),在配置中使用 Groovy 表达式,提供对 SQL语句中的 = 和 IN 的分片操作支持,它只支持单分片健。
行表达式分片策略适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是几种分片策略中最为简单的。
它的配置相当简洁,这种分片策略利用inline.algorithm-expression书写表达式。
2)代码实践
上篇博客有做详细实践inline分片策略实践
四、Hint分片策略
1)使用场景
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
比如我依旧是查询所有数据,但是此次查询我只是想查询固定的库或者固定的表,该如何实现呢?
当然如果仅仅是查询固定库,这里其实就是一个多数据源的问题,可以借助第三方包来实现多数据源,也可以通过Hint分片策略实现,这里我们就通过这个场景来介绍下Hint分片策略的使用。
2)配置
###配置分表策略
#Hint查询策略
spring.shardingsphere.sharding.tables.course.table-strategy.hint.algorithm-class-name=com.huohuo.sharding.service.algorithm.MyHintTableShardingAlgorithm
###配置分库策略
#Hint查询策略
spring.shardingsphere.sharding.tables.course.database-strategy.hint.algorithm-class-name=com.huohuo.sharding.service.algorithm.MyHintDBShardingAlgorithm
/**
* @description:自定义Hint分表策略
* @author: huoyajing
* @time: 2021/12/17 4:40 下午
*/
public class MyHintDBShardingAlgorithm implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {
// m_1 在测试类中传入了对应的值,我只想查询m1库中的数据
String key = hintShardingValue.getLogicTableName() + "_" + hintShardingValue.getValues().toArray()[0];
if (collection.contains(key)) {
return Arrays.asList(key);
}
return null;
}
}
/**
* @description:自定义Hint分表策略
* @author: huoyajing
* @time: 2021/12/17 4:40 下午
*/
public class MyHintTableShardingAlgorithm implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {
// course_1 在测试类中传入了对应的值,我只想查询course_1中的数据
String key = hintShardingValue.getLogicTableName() + "_" + hintShardingValue.getValues().toArray()[0];
if (collection.contains(key)) {
return Arrays.asList(key);
}
return null;
}
}
HintManager有两个设置参数,通过字面意思可以晓得是对表或库的配置。

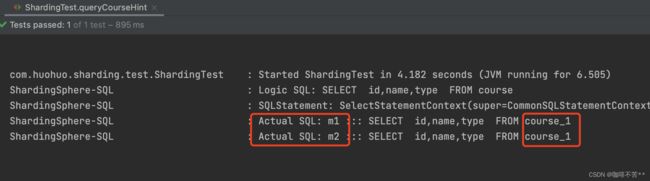
我引入了测试方法,要求查询结果只是通过course_1查询,看最终结果符合了我们的查询条件。
@Test
public void queryCourseHint() {
HintManager.clear();
HintManager hintManager = HintManager.getInstance();
// hintManager.addDatabaseShardingValue("m",1);
hintManager.addTableShardingValue("course", 1);
List<Course> courses = courseMapper.selectList(null);
courses.forEach(course -> System.out.println(course));
hintManager.close();
}
3)未解决问题
addDatabaseShardingValue 使用此参数想配置想查询的库但是未生效
大家有想法可以帮忙提出来,后期会继续实践。