Swin-Transformer 在图像识别中的应用
1. 卷积神经网络简单介绍
图像识别任务主要利用神经网络对图像进行特征提取,最后通过全连接层将特征和分类个数进行映射。传统的网络是利用线性网络对图像进行分类,然而图像信息是二维的,一般来说,图像像素点和周围邻域像素点相关。而线性分类网络将图像强行展平成一维,不仅仅忽略了图像的空间信息,而全连接层会大大增加网络的参数
为了更好把握图像像素的空间信息,提出了 CNN 卷积神经网络,利用卷积核(滤波器)对图像进行窗口化类似处理,这样可以更好的把握图像的空间信息。
CNN 卷积神经网络一般处理流程,将图像的宽高缩减,增加图像的channel 信息。这是因为我们往往更在乎图像的语义信息,所以正常神经网络都是将图像 size 缩半,channel 翻倍,一个通道提取一个语义,尺寸缩半是因为最大池化层之类的操作,可以增加网络的抗干扰能力。例如经典的VGG 网络就是每一层特征图size减半,channel 翻倍

2. Transformer 介绍
Transformer 是在自然语言处理(NLP)任务中提出的,之前的时序网络(RNN)不能并行化,计算N+1的数据,需要计算N的数据。因此,Transformer应运而生了。
图像处理中,如果将图像划分为一个个patch,这样Transformer就能向处理自然语言那样处理图像
Transformer 与 CNN 相比:
- CNN 网络有个关键的问题就是卷积核size 的设定,大的kernel size 可以拥有更好的感受野,把握更多图像的全局信息。但是size过大,网络的参数就会增加。后来VGG网络的提出,连续3*3卷积可以代替更大的卷积核,所以后面的网络均采用3*3卷积核。
参考资料:pytorch 搭建 VGG 网络
- Transformer 是基于全局处理的,可以把握图像的全局信息,因此理论上Transformer 有比CNN更好的特征提取能力
Trasnformer 的 self-attention 和 multi-head self-attention
self-attention 部分:
这里计算Q和K的相似度,得到的值类似于权重,然后和V相乘

Q和K的相似度,点乘出的 α
这里是Q和每一个K匹配,计算公式如下 ,例如q1和k1 = 1*1+2*1 / 根号 2 = 3/1.414= 2.12 。q1和k2的相似度,1*0+2*1 /根号2 = 2/1.414 = 1.41

q2和k1、k2的计算一样,这里利用矩阵计算,所以Transformer可以并行化计算
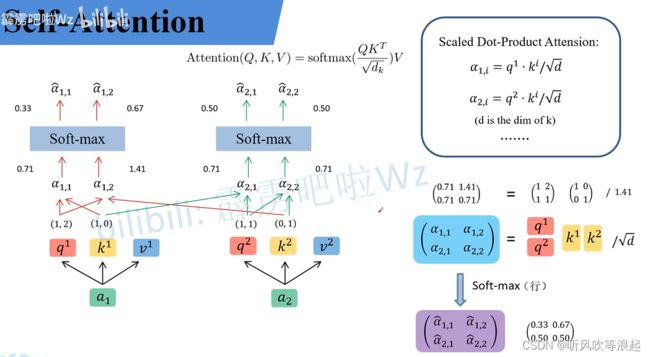
计算权重和V的值


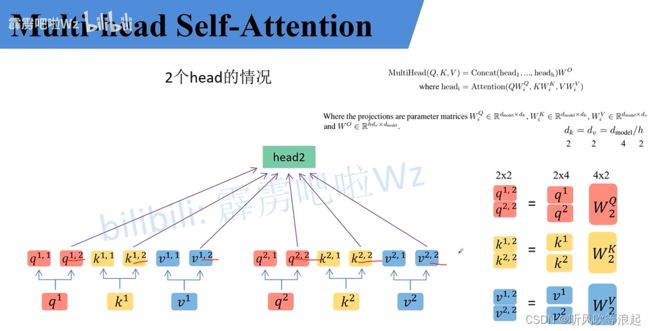
multi-head self-attention:(MSA)
将数据均分成不同head



2.1 Vision Transformer
将图像划分为不同的patch,输入Transformer 网络

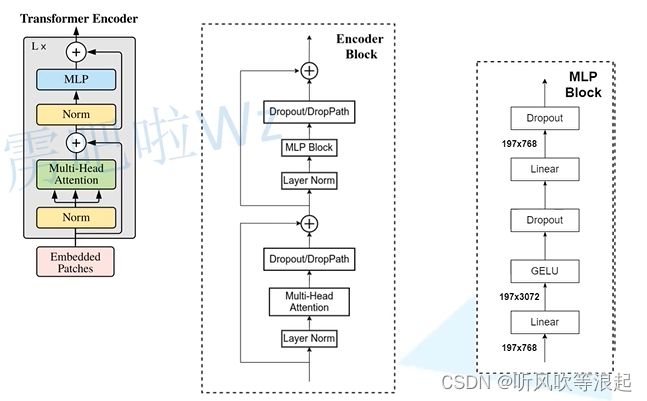
Transformer Encoder结构:
不同patch的相似度

Vision Transformer分类项目:Vision Transformer 网络对花数据集的分类
2.2 Swin Transformer
swin Transformer 和 vision Transformer 区别:
- swin Transformer 有层次结构,4、8、16倍下采样
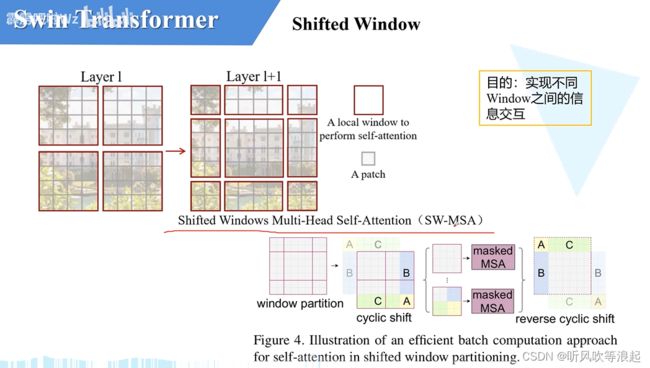
- swin Transformer 窗口分割
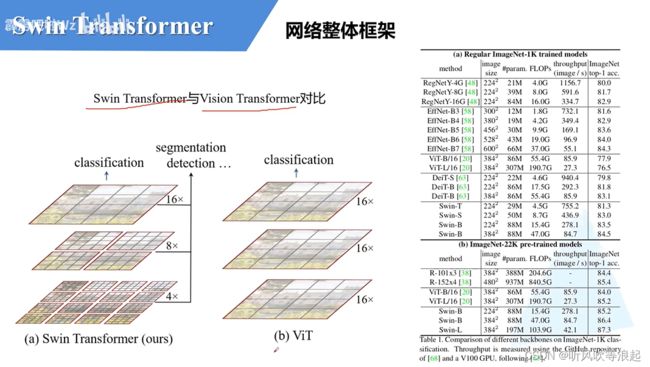
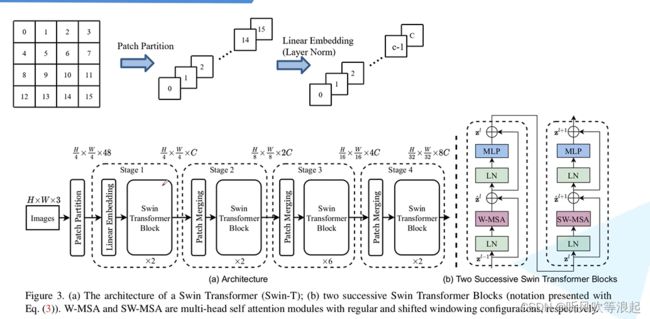
Swin Transformer 网络框架:
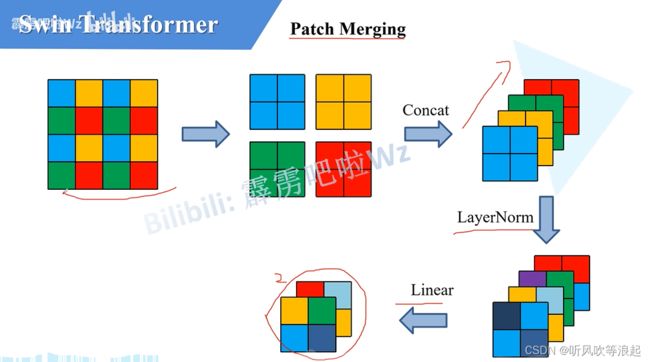
关于patch merging部分:就是将图像size减半,通道翻倍
W-MSA模块:

shifted window:
3. Swin-Transformer 使用
代码下载:Swin-Transformer 迁移学习对数据集花的分类

如果需要更换数据集的话,将data删除,然后将自己的数据集按照data下面摆放即可

训练过程的超参数可以不做更改,分类的个数由代码生成,不需要自行更改!
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=32)
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--lrf', type=float, default=0.1)
parser.add_argument('--freeze-layers', type=bool, default=True) # 是否冻结权重
训练结果:测试集的精度接近 98%,效果很棒了

测试集的混淆矩阵:
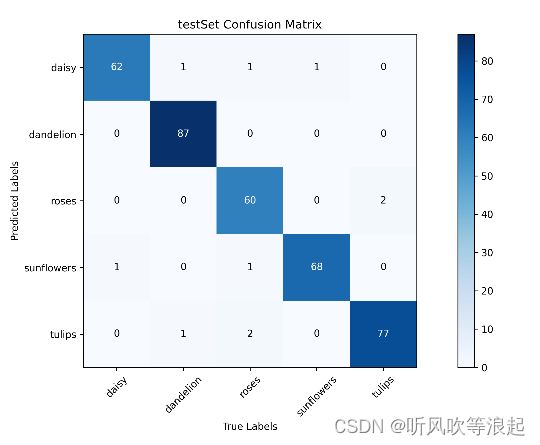
测试结果为: