大数据Flink电商实时数仓实战项目流程全解(五)
前提概要:之前我们已经实现了动态分流,即通过TableProcessFunction1类把维度数据和事实数据进行了分流处理,接下来就是把数据写入Hbase表和Kafka主题表中:
hbaseDS.addSink(new DimSink());
kafkaDS.addSink(kafkaSink);
此时的动态分流后的2种数据类型大致为:
在代码注释种我已经详尽地介绍了输出数据的情况和代码逻辑,接下来我会以代码编写逻辑思路为主要讲解路线,可以参考代码逻辑来看;
维度表和事实表动态写入
Hbase动态写入
怎么去编写这个DimSink类呢?首先我们需要通过Phoenix来与Hbase建立联系,之前我们已经通过循环遍历配置表来完成Hbase对应的建表操作了,所以此时我们已经可以通过Phoenix的Sql语法来完成数据插入操作了;
所以这里我们应该先获取到要插入的表名,然后整理成对应的Sql语句,具体句法类似upsert into 表空间.表名(列名…) values (值…);
但有一点要注意一下:
if(jsonObj.getString("type").equals("update")){
DimUtil.deleteCached(tableName,dataJsonObj.getString("id"));
}
//这一段代码的作用是在后续Hbase表数据查询优化过程种起作用的,在这部分内容里面可以先忽略不管;
其他代码内容主要就是Phoenix的链接、Sql语句的生成以及upsert语句编写;
Kafka动态写入
回到之前我们写过的MyKafkaUtil的工具类中,当时我们的Producer对象是这么生成的:
//封装FlinkKafkaProducer
public static FlinkKafkaProducer<String> getKafkaSink(String topic) {
//返回的就是kafka的producer对象;
return new FlinkKafkaProducer<String>(KAFKA_SERVER, topic, new SimpleStringSchema());
}
这段代码的topic对象在方法的参数中就已经确定了,但是我们在这里的kafka主题表不止一个,如果要把所有的kafka主题数据都写入进去,我们只能根据配置表中对应的kafka主题,有多少个主题就生成多少个Producer对象,但即使是这样,如果业务中有了新的事实数据类型,需要一个新的kafka主题,那我们这里还必须停止集群,重新添加新的Producer对象生成代码,这明显是不合理的;所以,这里我们采用另外一种创建方式:
//这种生成的FlinkKafkaProducer可以支持多个topic的情形;
public static <T> FlinkKafkaProducer<T> getKafkaSinkBySchema(KafkaSerializationSchema<T> kafkaSerializationSchema) {
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,KAFKA_SERVER);
//设置生产数据的超时时间
props.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,15*60*1000+"");
//可以往默认的topic发送,也可以指定topic;
//KafkaSerializationSchema 序列化的类型;
//props 生产者配置信息;
//FlinkKafkaProducer.Semantic 语义,指定精准一致性;
//这样写可以发往多个主题;
return new FlinkKafkaProducer<T>(DEFAULT_TOPIC, kafkaSerializationSchema, props, FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
生成的FlinkKafkaProducer对象可以动态的选择kafka主题名,所以接下来我们拉看看这个Prodecer对象是如何实现动态写入kafka主题数据的:
FlinkKafkaProducer<JSONObject> kafkaSink = MyKafkaUtil.getKafkaSinkBySchema(
new KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("kafka序列化");
}
//核心方法,每一条数据的序列化;
@Override
//这里的两个byte[], byte[]分别指代K,V;只不过这里没用K,只用了V;注意:K不是这里的topic,topic不传输;
//K(即Topic的作用是为了帮助分配到不同的主题中)
public ProducerRecord<byte[], byte[]> serialize(JSONObject jsonObj, @Nullable Long timestamp) {
String sinkTopic = jsonObj.getString("sink_table");
JSONObject dataJsonObj = jsonObj.getJSONObject("data");
//两个参数分别表示:主题名和数据值;
//序列化的意义就是把数据转化为字节数组,所以这里的value转化为Byte类型来做;主题找到位置即可,不用序列化;
return new ProducerRecord<>(sinkTopic,dataJsonObj.toString().getBytes());
}
}
);
//在ProducerRecord方法中,通过获取数据流中的sinkTable(记住此时数据流已经是主题数据了),来动态的传入sinkTopic;
到此为止,分流数据保存到Hbase和Kafka中的操作就全部完成了;
总结:
1 接收 Kafka 数据,转换过后再过滤空值数据
对 Maxwell 抓取数据进行 ETL,有用的部分保留,没用的过滤掉
2 实现动态分流功能(重难点)
由于MaxWell是把全部数据统一写入一个Topic中, 这样显然不利于日后的数据处理。所以需要把各个表拆开处理。但是由于每个表有不同的特点,有些表是维度表,有些表是事实表,有的表既是事实表在某种情况下也是维度表。
在实时计算中一般把维度数据写入存储容器,一般是方便通过主键查询的数据库比如HBase,Redis,MySQL 等。一般把事实数据写入流中,进行进一步处理,最终形成宽表。但是这里用Redis的话会对内存要求非常高,所以这里采用HBase来存储维度数据;
但是作为Flink实时计算任务,如何得知哪些表是维度表,哪些是事实表呢?而这些表又应该采集哪些字段呢?
我们可以将上面的内容放到某一个地方,集中配置。这样的配置不适合写在配置文件中,因为业务端随着需求变化每增加一张表,就要修改配置重启计算程序。所以这里需要一种动态配置方案,把这种配置长期保存起来,一旦配置有变化,实时计算可以自动感知。这种可以有两个方案实现:
➢ 一种是用Zookeeper存储,通过Watch感知数据变化。
➢ 另一种是用mysql数据库存储,周期性的同步。
这里选择第二种方案,主要是mysql对于配置数据初始化和维护管理,用sql都比较方便,虽然周期性操作时效性差一点,但是配置变化并不频繁。
//在当前项目中,选择的是通过自己来维护配置信息表,而在实际项目中往往是通过web页面的方式来维护;
//举例说明:实际业务发生了一个事件:数据库的品牌表中添加了一个新的品牌,相当于往base_trademark表中添加了一条记录,binlog会将这条记录保存下来,Maxwell会监听到binlog的变化,然后将发生变化的这条记录以json的形式发给kafka(ods_base_db_m);BaseDBApp从kafaka的od_base_db_m中读取到这条记录,然后从MySql的配置表获取相关信息:
--维度数据 发送到HBase
--事实数据 发送到kafka的dwd层
3.配置phoenix和hbase的相关内容,创建对应的命名空间;(具体见PDF文件)
4 把分好的流保存到对应表、主题中
业务数据保存到 Kafka 的主题中
维度数据保存到 Hbase 的表中
/*
数据大概样式:
{"database":"gmall0709","table":"order_info","type":"update","ts":1626008658,"xid":254,"xoffset":4651,
"data":{"id":28993,"consignee":"蒋莲真","consignee_tel":"13494023727","total_amount":21996.00,
"order_status":"1001","user_id":438,"payment_way":null,"delivery_address":"第17大街第39号楼1单元977门",
"order_comment":"描述178284","out_trade_no":"352538349474172","trade_body":"十月稻田 长粒香大米 东北大米 东北香米 5kg等10件商品",
"create_time":"2021-07-11 21:04:17","operate_time":"2021-07-11 21:04:18","expire_time":"2021-07-11 21:19:17",
"process_status":null,"tracking_no":null,"parent_order_id":null,"img_url":"http://img.gmall.com/646283.jpg",
"province_id":29,"activity_reduce_amount":0.00,"coupon_reduce_amount":0.00,"original_total_amount":21989.00,
"feight_fee":7.00,"feight_fee_reduce":null,"refundable_time":null},
"old":{"operate_time":null}}
有些数据不全
*/
//数据中携带了表格的信息和type的信息,根据此可以去配置表中找到自己属于维度数据还是事实数据;
//log测试:
开启zk.sh、kk.sh、maxwell.sh、当前应用程序;再去开启业务数据jar包:
/opt/module/rt_dblog $java -jar gmall2020-mock-db-2020-11-27.jar
//查看mysql中是否接收到数据;
//配置信息表测试:
//测试,是否能读到刚才创建的table_process表的数据信息;
//手动添加一条数据,然后运行com.chenxu.gmall.realtime.utils.MyKafkaUtil;
//配置phoenix和HBase的API测试;
//开启zk、kk、hdfs、hbase、phoenix、maxwell、本应用程序,记得提前在gmall0709_realtime数据库中手动插入一条配置文件信息;
//此时phoenix会自动建表GMALL0709_REALTIME
//手动修改gmall0709数据库中base_trademark表的数据,应该会给出类似下面的输出;
//维度>>>>:2> {"database":"gmall0709","xid":18593,"data":{"id":17},"commit":true,"sink_table":"DIM_BASE_TRADEMARK","type":"insert","table":"base_trademark","ts":1626230909}
//hbase中不会接收到具体数据;
//再把刚才配置表中的sink_type改为kafka,把sink_table改为first
//此时Map会重新读取这条新的配置信息,加入到内存中,数据也会输出到kafka中;
//重启应用程序,会出现类似下面的输出:
//事实>>>>:4> {"database":"gmall0709","xid":19366,"data":{"id":19},"commit":true,"sink_table":"first","type":"insert","table":"base_trademark","ts":1626231206}
//但是kafka中不会接收到数据;
//所以接下来要做的,就是把对应的维度数据再保存到hbase表中,把事实数据输出到kafka中;
//测试TODO6 newSink函数,维度数据是否会存入对应HBase表中;
//启动zk、kk、hdfs、hbase、maxwell、phoenix、应用程序;
//手动修改刚才的配置表信息,改回hbase和DIM_BASE_TRADEMARK;
//再去base_trademark表中添加一下数据;
//输出一条信息如下:
//维度>>>>:2> {"database":"gmall0709","xid":30932,"data":{"tm_name":"20","id":20},"commit":true,"sink_table":"DIM_BASE_TRADEMARK","type":"insert","table":"base_trademark","ts":1626240730}
//向Phoenix插入数据的SQL:upsert into GMALL0709_REALTIME.DIM_BASE_TRADEMARK(tm_name,id) values ('20','20')
//在phoenix中查询数据是否插入:
//select * from GMALL0709_REALTIME.DIM_BASE_TRADEMARK;
//测试
//启动 hdfs、zk、kafka、Maxwell、hbase,kafka的dwd_order_info主题消费
//向 gmall2021_realtime 数据库的 table_process 表中插入测试数据
//比如:对应数据为:order_info insert kafka dwd_order_info id,consignee,consignee_tel,total_count,order_status,user_id,payment_way,delivery_address,order_comment,out_trade_no,trade_body,create_time,operate_time,expire_time,process_status,tracking_no,parent_order_id,img_url,province_id,activity_reduce_amount,coupon_reduce_amount,original_total_amount,feight_fee,feight_fee_reduce,refundable_time id
//运行 idea 中的 BaseDBApp
//运行 rt_dblog 下的 jar 包,模拟生成数据
//查看控制台输出以及在配置表中配置的 kafka 主题名消费情况(kafka中消费的都是订单数据)
//此时还可以再增加base_trademark表中的数据,看看控制台会不会输出维度表的信息,再去phoenix中查看是否有数据:
//select * from GMALL0709_REALTIME.DIM_BASE_TRADEMARK;
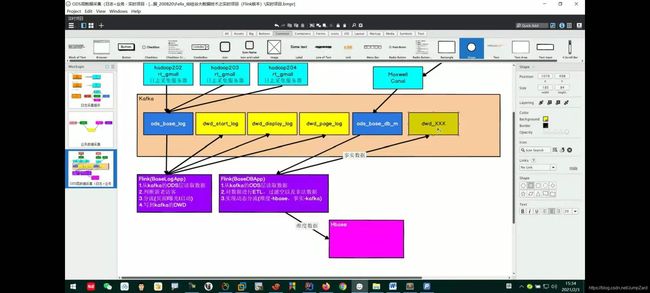
流程图总结如下所示:(要注意,这里具体维度数据和事实数据怎么用还没有实现,只是做了一个简单的表测试)