时间序列数据处理01——可视化与预处理
1.关于时间戳与时间戳序列
-
时间戳: 时间戳通常指的是一个特定时间点距离某个固定时间点(通常是1970年1月1日午夜,也称为UNIX纪元)经过的秒数。这是一个单一的时间点,表示为一个数字。时间戳是一种表示时间的标准方式,用于在计算机系统中存储和处理时间。
-
时间戳序列: 时间戳序列是由一系列按照时间顺序排列的时间戳组成的数据集合。它表示在一段时间内观察到或记录到的多个时间点。时间戳序列通常用于描述时间序列数据,其中每个时间戳对应一个特定的观测值。时间戳序列可以是均匀间隔的,例如每小时采集一次,也可以是不均匀间隔的,取决于数据的性质。
例如,在时间戳序列中,你可能有一个表示每小时温度的时间戳序列。每个时间戳对应一个小时的温度测量值。这个序列是按照时间顺序组织的,因为温度的变化通常是与时间相关的。
1.1 Timestamp类创建时间戳对象
总的来说,时间戳是一个特定时间点的表示,而时间戳序列是多个时间戳按照时间顺序组成的数据序列,通常用于描述随时间变化的观测值。
例子:
使用 Pandas 库中的 Timestamp 类创建一个表示特定日期的时间戳对象:
Timestamp是 Pandas 中用于表示时间戳的类。'2014-06-01'是一个日期字符串,它告诉Timestamp类要创建一个表示 '2014-06-01' 这一日期的时间戳对象。
你可以使用这个时间戳对象进行各种时间相关的操作,比如计算两个时间戳之间的差异、提取日期的各个部分(年、月、日等),以及与其他 Pandas 时间序列数据进行操作等。
下面是一个简单的例子,演示如何使用这个时间戳对象:
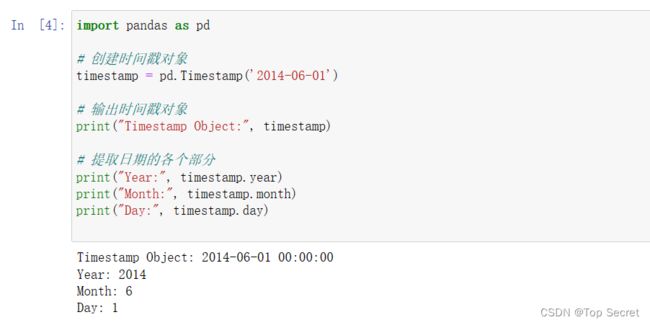
import pandas as pd
# 创建时间戳对象
timestamp = pd.Timestamp('2014-06-01')
# 输出时间戳对象
print("Timestamp Object:", timestamp)
# 提取日期的各个部分
print("Year:", timestamp.year)
print("Month:", timestamp.month)
print("Day:", timestamp.day)
2.时间周期
Period 类创建一个表示特定月份的时间周期对象
Period是 Pandas 中用于表示时间周期的类。'2014-06'是一个日期字符串,它告诉Period类要创建一个表示 '2014-06' 这个月份的时间周期对象。
与 Timestamp 不同,Period 更侧重于表示时间的一个范围,通常用于处理时间周期性的数据。你可以使用这个时间周期对象进行一些时间周期相关的操作,比如计算两个时间周期之间的差异、将时间周期转换为具体的日期范围等。
下面是一个简单的例子,演示如何使用这个时间周期对象:
3. DatetimeIndex 和 PeriodIndex
DatetimeIndex 和 PeriodIndex 是 Pandas 中两种不同的时间索引类型,用于处理时间序列数据的不同方面。
DatetimeIndex:
DatetimeIndex用于表示时间序列数据中的时间点,即时间戳。- 每个元素都是一个具体的时间点,精确到纳秒级别。
- 适用于需要对数据进行高精度时间戳索引的场景,如秒级、毫秒级的时间序列数据。
import pandas as pd
# Creating a DatetimeIndex with timestamp data
dt_index = pd.DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03'], name='timestamp')
data = [1, 2, 3]
# Creating a DataFrame with DatetimeIndex
df_datetime = pd.DataFrame(data, index=dt_index, columns=['Value'])
# Displaying the DataFrame
print("DataFrame with DatetimeIndex:")
print(df_datetime)PeriodIndex:
PeriodIndex用于表示时间序列数据中的时间区间或周期。- 每个元素表示一个固定的时间段,可以是天、月、季度或年等。
- 适用于周期性数据,例如按月、季度或年度进行采样的数据。
总的来说,主要区别在于 DatetimeIndex 用于表示具体的时间点,而 PeriodIndex 用于表示时间区间或周期。选择使用哪种索引类型取决于你的数据的性质和需要进行的分析操作。如果你处理的是精确到时间点的数据,使用 DatetimeIndex 更为合适;如果你处理的是时间周期性的数据,使用 PeriodIndex 更为合适。
4. 转换为时间戳
在进行时间序列预测时,将时间数据转换为时间戳有几个重要的原因:
-
有序性: 时间戳表示时间的顺序,这对于时间序列数据非常重要。时间戳使得数据点按照时间的先后顺序排列,这有助于建立模型捕捉时间的趋势和模式。
-
特征提取: 时间戳可以用于提取各种有关时间的特征,如小时、星期几、季节等。这些特征可能对模型的性能有显著影响,因为时间序列数据通常包含随时间变化的模式和趋势。
-
数据对齐: 时间戳可以确保数据点在时间轴上对齐,这对于建立准确的时间序列模型至关重要。数据对齐可以帮助避免在模型中引入不准确的时间信息,确保模型在时间维度上的一致性。
-
模型输入: 大多数时间序列模型要求输入是有序的时间数据。将时间转换为时间戳使得数据能够被直接用于模型训练,而无需复杂的预处理。
-
趋势和季节性分析: 时间戳可以更方便地用于分析和识别时间序列数据中的趋势和季节性模式。这对于选择适当的模型和特征工程步骤非常重要。
总的来说,将时间数据转换为时间戳有助于提高模型对时间序列的理解和捕捉能力,从而提高预测的准确性。
5. 时间序列数据没有显式的时间列
5.1 将每行的行数视为数据的索引值(in csv)
如果你的时间序列数据没有显式的时间列,但每行的行数可以视为时间的索引值,你仍然可以尝试使用这个索引值来进行时间序列预测。在这种情况下,你可以把每行的行数当作时间步来处理,但请注意以下几点:
1. **建模时的注意事项**:
- 将每行的行数视为时间步,你可以使用该值作为特征输入到模型中。
- 在建模时,确保模型能够理解并利用这个时间步的信息。一些模型(例如循环神经网络)天然适合处理时间步,而其他模型可能需要更多的特征工程。
2. **缺点**:
- 缺点是,行数可能不能提供关于时间的其他有用信息,例如日期、季节、周期性等。这可能导致模型在捕捉时间相关性方面的能力受到限制。
下面是一个简单的示例,演示如何将行数用作时间步来进行时间序列预测:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
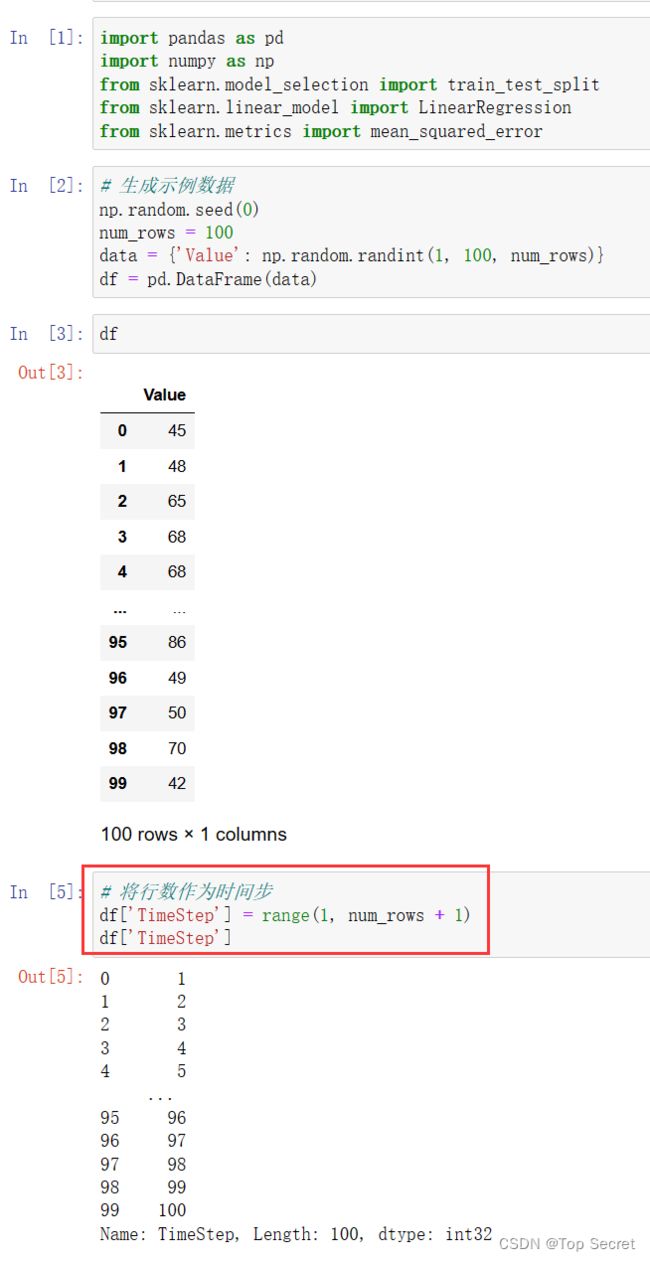
# 生成示例数据
np.random.seed(0)
num_rows = 100
data = {'Value': np.random.randint(1, 100, num_rows)}
df = pd.DataFrame(data)
# 将行数作为时间步
df['TimeStep'] = range(1, num_rows + 1)
# 划分训练集和测试集
train_df, test_df = train_test_split(df, test_size=0.2, shuffle=False)
# 使用线性回归进行预测
X_train, y_train = train_df[['TimeStep']], train_df['Value']
X_test, y_test = test_df[['TimeStep']], test_df['Value']
model = LinearRegression()
model.fit(X_train, y_train)
# 预测并评估模型
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')请注意,这只是一个简单的线性回归示例,实际上,你可能需要尝试更复杂的模型,特别是当数据中存在更丰富的时间相关性时。在处理实际问题时,还应该考虑其他可能的时间特征和模型选择。
演示:

对于导入的CSV文件,如何将其行数做成一列显式的索引列?
在Pandas中,你可以使用`reset_index`方法将DataFrame的行数做成一列显式的索引列。下面是一个简单的示例:
假设你有一个名为`data.csv`的CSV文件,你可以使用以下代码:
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
# 将行数做成一列显式的索引列
df['Index_Column'] = df.index
# 或者,如果你想将行数作为新的默认索引,可以使用以下方法
# df.reset_index(drop=True, inplace=True)
# 显示修改后的DataFrame
print(df.head())
这样,你的DataFrame将包含一个名为`Index_Column`的列,其中包含每行的行数作为显式的索引列。当然,你可以将这一列命名为任何你喜欢的名称。
将做成的显式索引列置于该CSV文件中的第一列:
如果你想将显式索引列置于CSV文件中的第一列,你可以使用Pandas的`to_csv`方法,并设置`index`参数为`False`,以防止默认的索引列被写入文件。然后,你可以使用`insert`方法将新的索引列插入到DataFrame的第一列。以下是一个示例:
import pandas as pd
# 读取CSV文件
df = pd.read_csv('data.csv')
# 将行数做成一列显式的索引列
df.insert(0, 'Index_Column', df.index)
# 保存修改后的DataFrame到CSV文件,不包含默认索引列
df.to_csv('modified_data.csv', index=False)
这将在当前工作目录下创建一个名为`modified_data.csv`的文件,其中包含新的显式索引列作为第一列。确保替换文件名和路径以适应你的实际需求。