提取微信聊天记录详细教程
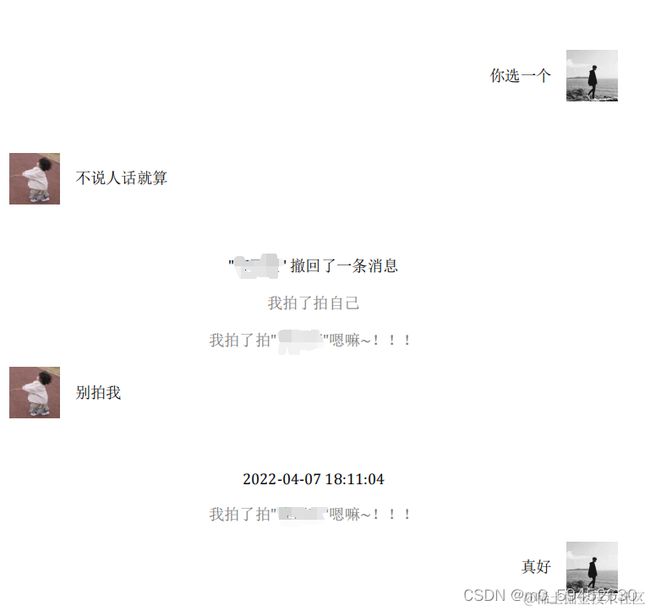
效果展示
导出内容:文字、图片、撤回消息、表情包、拍一拍、回复
导出格式:txt,docx,PDF



一、下载模拟器导入聊天记录到模拟器里
这里以夜神模拟器(支持root的模拟器都行)为例
在模拟器里安装微信并登录,然后在电脑上登录微信。

选择恢复聊天记录到手机,选择你导出的联系人到模拟器里,确保模拟器里的微信可以查看到聊天记录
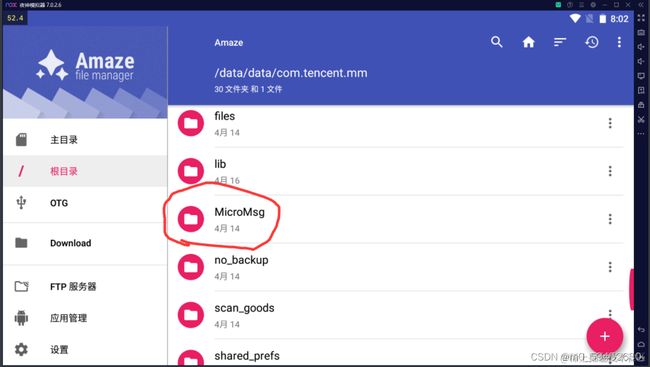
完成之后打开夜神模拟器,找到Amaze

选择根目录,找到./data/data/com.tencent.mm/MicroMsg

将这个文件夹复制到共享文件夹中
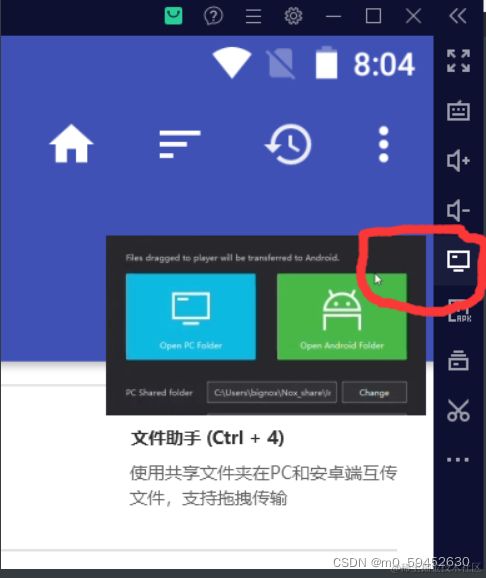
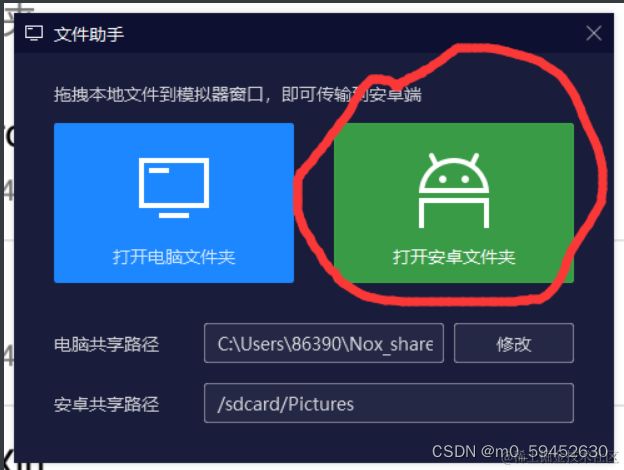
共享文件夹在上面可以看到,按照图片操作进行复制粘贴

然后再将下面这个文件(auth_info_key_prefs.xml)复制到共享文件夹中(文件目录://data/data/com.tencent.mm/shared_prefs)

复制完成之后到电脑的文件管理器查看共享文件夹


提取成功,第一步搞定
二、破译密码
文件夹里面会有一个以很长一串数字或者一些字母组成命名的文件夹(也可能有多个。不同的文件夹名代表不同的qq,如果你用不同的qq登陆过微信,每个qq会产生一个新乱码文件夹,保险起见,可以都备份上)把此文件夹备份出来,文件夹里还有个systeminfo.cfg文件可以不用备份

在这个名字很长的文件夹下将这三个文件提取出来,avatar(存储了用户的头像数据),image2(存储了聊天的图片数据)EnMicroMsg.db(存储了所有的聊天记录)

微信数据库EnMicroMsg.db的加密方式,把IMEI和auth_uin组合得到一起md5加密,取加密后的前7位(小写)
IMEI提取:打开夜神模拟器,右上角找到设置,进入手机设置,查看IMEI值

auth_uin提取方式,用记事本打开上面得到的xml文件, 在线加密网站:MD5在线加密/解密/破解—MD5在线 (sojson.com) 经过MD5加密后输出的字符串取前7位(小写) 将EnMicroMsg.db用sqlcipher.exe打开输入密码试试能不能打开 不能的话 用 IMEI = ‘1234567890ABCDEF’ 再试试 打开之后显示这个界面,点击Browse Data可以查看每个数据表的信息 pandas库,安装失败自行百度,网上很多教程 docx库 requests库 docxcompose库 rcontant.py message.py to_docx.py 扫描最下方的二维码就能全部领取,如果图片失效点击蓝色字体便可跳转哦~点这里哦 好啦今天的分享就到这里结束了,快乐的时光总是短暂呢,想学习更多课程的小伙伴不要着急,有更多惊喜哦~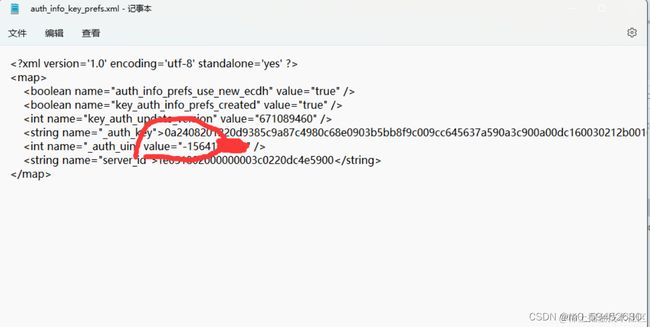
被加密字符串就是: 351564524987328-15641****
微信所有聊天记录都在message表里,所有联系人都在rcontact表里,userinfo里存储个人信息,把这三个表导出为csv文件,分别命名为message.csv和rcontact.csv,userinfo.csv
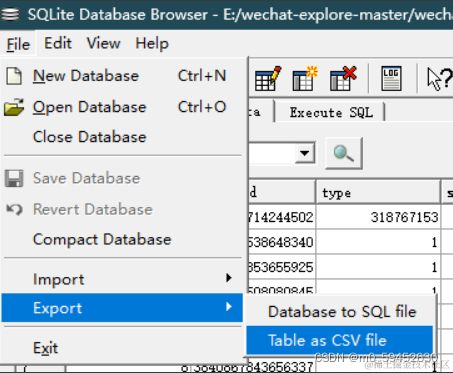
将导出的所有表都放在db_tables文件夹里(自己新建)
直接导出的csv文件在python读写会出现异常,所以先在Excel里打开csv文件再另存为xlsx文件(或者用记事本更改编码方式为utf-8)放到db_tables文件夹里三、解析数据
0、模块安装(不会安装的话自行百度)
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install docxcompose -i https://pypi.tuna.tsinghua.edu.cn/simple
1、把三个xlsx文件解析成新的csv文件(rcontact.py和message.py)
#-*- coding : utf-8-*-
# coding:unicode_escape
'''
#! 本文件功能
#! 1、将rcontact.xlsx转化成new_rcontact.csv
#! 2、获取联系人的wxid
#! 另外两个文件都会使用此模块
'''
import os
import pandas as pd
filename = ''
if isExists := os.path.exists('./db_tables/rcontact.xlsx'):
isExists = os.path.exists('./db_tables/new_rcontact.csv')
if not isExists:
filename = './db_tables/rcontact.xlsx'
df = pd.read_excel(filename)
df.to_csv('./db_tables/new_rcontact.csv')
print("new_rcontact.csv 导出成功")
filename = './db_tables/new_rcontact.csv'
else:
print('rcontact.xlsx not exits')
print("请将数据库里的rcontact表导出\n命名为:rcontact.csv")
print("用Excel把文件导出为xlsx格式放到此目录下")
'''获取指定备注名的wxid'''
def get_one_wxid(conRemark):
if not filename:
print("联系人csv文件不存在")
else:
df = pd.read_csv(filename)
for row_index, row in df.iterrows():
if row['conRemark'] == conRemark :
wxid = row['username']
print(conRemark,wxid)
return wxid
'''获取自己的wxid'''
def get_self_wxid():
isExists = os.path.exists('./db_tables/userinfo.xlsx')
if not isExists:
print('userinfo.xlsx not exits')
print("请将数据库里的userinfo表导出\n命名为:userinfo.csv")
print("用Excel把文件导出为同名xlsx格式放到此目录下")
else:
isExists = os.path.exists('./db_tables/new_userinfo.csv')
if not isExists:
filename = './db_tables/userinfo.xlsx'
df = pd.read_excel(filename)
df.to_csv('./db_tables/new_userinfo.csv')
print("new_userinfo.csv 导出成功")
filename = './db_tables/new_userinfo.csv'
if isExists := os.path.exists(filename):
df = pd.read_csv(filename)
print(df)
for row_index, row in df.iterrows():
if 'wxid' in row['value']:
print("self_wxid =",row['value'])
return row['value']
else:
print("new_userinfo.csv文件不存在")
if __name__ == '__main__':
conRemark = '张三' #!备注名
filename = './db_tables/rcontact.csv'
get_one_wxid(conRemark)
get_self_wxid()
import pandas as pd
import os
import sys
import io
'''这个是自定义包'''
import rcontact
columns = ['msgId','msgSvrId','type','status','isSend','isShowTimer','createTime','talker','content','imgPath',
'reserved','lvbuffer','transContent','transBrandWording','talkerId',
'bizClientMsgId','bizChatId','bizChatUserId','msgSeq','flag','solitaireFoldInfo','historyId'
]
'''筛选一下文件头,其他好像没用'''
new_columns = ['createTime','isSend','talker','content','imgPath','reserved','talkerId','type','status']
Type = {
'1':'文字',
'3':'图片',
'43':'视频',
'-1879048185':'微信运动排行榜',
'5':'',
'47':'表情包',
'268445456':'撤回的消息',
'34':'语音',
'419430449':'转账',
'50':'语音电话',
'10000':'领取红包',
'10000':'消息已发出,但被对方拒收了。',
'822083633':'回复消息',
'922746929':'拍一拍',
'1090519089':'发送文件',
'318767153':'付款成功',
'436207665':'发红包',
}
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
'''判断路径是否存在,不存在则新建文件夹'''
def mkdir(path):
path = path.strip()
path = path.rstrip("\")
if os.path.exists(path):
return False
os.makedirs(path)
return True
mkdir('.//db_tables')
'''
# ! 把原表处理一下过滤掉不必要的信息
# ! 作用不大可以忽略
'''
def read_all_data():
pdata = pd.read_csv('./db_tables/new_message.csv')
# del pdata['1']
print(pdata)
# pdata.to_csv('./db_tables/5.csv')
# msgId,msgSvrId,type,status,isSend
new = pd.DataFrame()
new.insert(0,'createTime',pdata['createTime'])
new.insert(1,'isSend',pdata['isSend'])
new.insert(2,'talker',pdata['talker'])
new.insert(3,'content',pdata['content'])
new.insert(4,'imgPath',pdata['imgPath'])
new.insert(5,'reserved',pdata['reserved'])
new.insert(6,'talkerId',pdata['talkerId'])
new.insert(7,'type',pdata['type'])
new.insert(8,'status',pdata['status'])
new.to_csv('./db_tables/simple_new_message.csv',index=False)
print("数据筛选成功!!!")
'''
#! 根据备注导出某个人的全部聊天信息
'''
def read_one_data(conRemark):
isExist = os.path.exists('./db_tables/simple_new_message.csv')
if not isExist:
print("simple_new_message.csv不存在\n请先执行上一个函数")
return
pdata = pd.read_csv('./db_tables/simple_new_message.csv')
print(pdata)
print("漫长的等待!!!")
wxid = rcontact.get_one_wxid(conRemark)
new_data = pd.DataFrame(columns=new_columns)
'''筛选出目标聊天记录'''
for row_index,row in pdata.iterrows():
if(row['talker']==wxid):
new_data.loc[len(new_data.index)] = list(row)
# print(new_data)
'''导入到新文件中'''
new_data.to_csv(f'./db_tables/{conRemark}.csv', index=False)
print(f"导出{conRemark}的聊天数据成功!!!")
''' 把时间数据转化成字符串防止数据舍入'''
def data_to_string():
isExist = os.path.exists('./db_tables/message.xlsx')
if not isExist:
print("message.xlsx不存在,请在将数据库里的message表导出成csv文件")
print("命名为message.csv,然后用Excel打开文件另存为message.xlsx")
print("放入./db_tables文件夹中")
return False
else:
isExist = os.path.exists('./db_tables/new_message.csv')
if not isExist:
df = pd.read_excel('./db_tables/message.xlsx')
df['createTime'].to_string()
print(df)
df.to_csv('./db_tables/new_message.csv')
else:
print("new_message.csv已就绪即将进行数据处理")
return True
if __name__ == '__main__':
# time_d()
# read_all_data()
# data_to_string()
status = data_to_string()
if status:
'''把message转化成csv'''
read_all_data()
'''输入备注名导出联系人的聊天信息'''
conRemark = '张三'
read_one_data(conRemark)
2、导出聊天记录(源代码)
import hashlib
import os
import re
import threading
import time
import docx
import pandas as pd
import requests
from docx import shared
from docx.enum.table import WD_ALIGN_VERTICAL
from docx.enum.text import WD_COLOR_INDEX, WD_PARAGRAPH_ALIGNMENT
from docxcompose.composer import Composer
import rcontact
conRemark = '张三'
self_wxid = rcontact.get_self_wxid()
ta_wxid = rcontact.get_one_wxid(conRemark)
'''
#! 创建emoji目录,存放emoji文件
'''
def mkdir(path):
path = path.strip()
path = path.rstrip("\")
if os.path.exists(path):
return False
os.makedirs(path)
return True
mkdir('.//emoji')
mkdir('.//db_tables')
'''
#! 将wxid使用MD5编码加密
#! 加密结果是用户头像路径
'''
def avatar_md5(wxid):
m = hashlib.md5()
# 参数必须是byte类型,否则报Unicode-objects must be encoded before hashing错误
m.update(bytes(wxid.encode('utf-8')))
return m.hexdigest()
'''
#! 获取头像文件完整路径
'''
def get_avator(wxid):
avatar = avatar_md5(wxid)
avatar_path = r"./avatar/"`在这里插入代码片`
path = avatar_path + avatar[:2] + '/' + avatar[2:4]
for root, dirs, files in os.walk(path):
for file in files:
if avatar in file:
avatar = file
break
return path + '/'+avatar
self_avator = get_avator(self_wxid)
ta_avator = get_avator(ta_wxid)
img_self = open(self_avator, 'rb')
img_ta = open(ta_avator, 'rb')
'''
#! 下载emoji文件
#!
#!
'''
def download_emoji(content, img_path):
try:
url = content.split('cdnurl = "')[1].split('"')[0]
url = ':'.join(url.split('*#*'))
if 'amp;' in url:
url = ''.join(url.split('amp;'))
print('emoji downloading!!!')
resp = requests.get(url)
with open(f'./emoji/{img_path}', 'wb') as f:
f.write(resp.content)
except Exception:
print("emoji download error")
'''
#! 将字符串类型的时间戳转换成日期
#! 返回格式化的时间字符串
#! %Y-%m-%d %H:%M:%S
'''
def time_format(timestamp):
timestamp = timestamp[:-5]
timestamp = float(timestamp + '.' + timestamp[-5:2])
time_tuple = time.localtime(timestamp)
return time.strftime("%Y-%m-%d %H:%M:%S", time_tuple)
'''
#! 判断两次聊天时间是不是大于五分钟
#! 若大于五分钟则显示时间
#! 否则不显示
'''
def IS_5_min(last_m, now_m):
last_m = last_m[:-5]
last_m = float(last_m + '.' + last_m[-5:2])
now_m = now_m[:-5]
now_m = float(now_m + '.' + now_m[-5:2])
'''两次聊天记录时间差,单位是秒'''
time_sub = now_m - last_m
return time_sub >= 300
def judge_type(Type):
pass
'''
#! 创建一个1*2表格
#! isSend = 1 (0,0)存聊天内容,(0,1)存头像
#! isSend = 0 (0,0)存头像,(0,1)存聊天内容
#! 返回聊天内容的坐标
'''
# img_self = open('1.jpg', 'rb')
# img_ta = open('0.jpg', 'rb')
def create_table(doc,isSend):
table = doc.add_table(rows=1, cols=2, style='Normal Table')
table.cell(0, 1).height = shared.Inches(0.5)
table.cell(0, 0).height = shared.Inches(0.5)
# img_1 = '1.jpg'
# img_0 = '0.jpg'
global img_self
global img_ta
text_size = 1
if isSend:
'''表格右对齐'''
table.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
avatar = table.cell(0, 1).paragraphs[0].add_run()
'''插入头像,设置头像宽度'''
avatar.add_picture(img_self, width=shared.Inches(0.5))
'''设置单元格宽度跟头像一致'''
table.cell(0, 1).width = shared.Inches(0.5)
content_cell = table.cell(0, 0)
'''聊天内容右对齐'''
content_cell.paragraphs[0].paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
else:
avatar = table.cell(0, 0).paragraphs[0].add_run()
avatar.add_picture(img_ta, width=shared.Inches(0.5))
'''设置单元格宽度'''
table.cell(0, 0).width = shared.Inches(0.5)
content_cell = table.cell(0, 1)
'''聊天内容垂直居中对齐'''
content_cell.vertical_alignment = WD_ALIGN_VERTICAL.CENTER
return content_cell
'''
#! 将文字聊天记录写入文件
#! isSend表示是谁发送的信息
#! isSend = 0 表示是对方发的信息,内容左对齐
#! isSend = 1 表示是自己发的信息,内容右对齐
'''
def text(doc,isSend, message, status):
if status == 5:
message += '(未发出) '
content_cell = create_table(doc,isSend)
content_cell.paragraphs[0].add_run(message)
content_cell.paragraphs[0].font_size = shared.Inches(0.5)
if isSend:
p = content_cell.paragraphs[0]
p.paragraph_format.alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT
doc.add_paragraph()
'''
#! 插入聊天图片
#! isSend = 1 只有缩略图
#! isSend = 0 有原图
'''
def image(doc,isSend, Type, content, imgPath):
content = create_table(doc,isSend)
run = content.paragraphs[0].add_run()
imgPath = imgPath.split('//th_')[-1]
if Type == 3:
Path = f'.//image2//{imgPath[:2]}//{imgPath[2:4]}'
elif Type == 47:
Path = './emoji'
for root, dirs, files in os.walk(Path):
for file in files:
if isSend:
if imgPath + 'hd' in file:
imgPath = file
try:
run.add_picture(f'{Path}/{imgPath}', height=shared.Inches(2))
doc.add_paragraph()
except Exception:
print("Error!image")
return
elif imgPath in file:
imgPath = file
break
try:
run.add_picture(f'{Path}/{imgPath}', height=shared.Inches(2))
doc.add_paragraph()
except Exception:
print("Error!image")
# run.add_picture(f'{Path}/{imgPath}', height=shared.Inches(2))
'''
#! 添加表情包
'''
def emoji(doc,isSend, content, imgPath):
try:
path = f'.//emoji//{imgPath}'
is_Exist = os.path.exists(path)
if not is_Exist:
'''表情包不存在,则下载表情包到emoji文件夹中'''
download_emoji(content, imgPath)
image(doc,isSend, Type=47, content=content, imgPath=imgPath)
except Exception:
print("can't find emoji!")
'''
#! 添加微信文件
'''
def wx_file(doc,isSend, content, status):
pattern = re.compile(r"3、源码文件及附件
